
Comment scraper cDiscount avec Python et requests en 2023?
cDiscount, c’est vraiment un superbe site de e-commerce Français. Selon la page de Wikipedia du groupe, on y trouve (tenez-vous bien) pas moins de 100 millions de références, et ce réparti dans plusieurs centaines de catégories, de l’univers de la maison, au high-tech, en passant par la mode et l’alimentation.

Est-ce qu’il est si compliqué de scraper de la donnée sur cDiscount?
Dans ce tutoriel, on va voir comment scraper les données des produits sur cDiscount avec Python3 et requests, et obtenir de façon programmatique, des données fraîches, structurées et massivement exploitables.
Disclaimer: on va également percer le secret de cette mystérieuse requête POST…
Développeurs, data analysts, dirigeants soucieux de veiller sur les prix des barbecues de ses concurrents: cet article est fait pour vous!
Prérequis
Avant de rentrer dans le dur, on va commencer par installer les outils nécessaires à notre collecte.
Puis on va télécharger 3 librairies additionnelles, avec pip, l’outil d’installation de Python: requests, la librairie la plus téléchargée pour Python, qui va nous permettre de naviguer programmatiquement sur Internet, retry, une librairie qui va nous permettre de recommencer certaine tâche si une erreur est rencontrée sur notre chemin, et lxml, une librairie qui va nous permettre d’aller chercher les éléments dans le code source d’une page HTML.
Avec une installation comme suit:
$ pip3 install requests lxml retryf
Nous sommes maintenant prêts pour la suite des opérations.
Code Complet
import requests import re import json from lxml import html import time from retry import retry import csv URL = 'https://www.cdiscount.com/search/10/barbecue.html' HEADERS = { 'authority': 'www.cdiscount.com', 'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7', 'accept-language': 'fr-FR,fr;q=0.9', 'sec-ch-ua': '"Not.A/Brand";v="8", "Chromium";v="114", "Google Chrome";v="114"', 'sec-ch-ua-mobile': '?0', 'sec-ch-ua-platform': '"macOS"', 'sec-fetch-dest': 'document', 'sec-fetch-mode': 'navigate', 'sec-fetch-site': 'none', 'sec-fetch-user': '?1', 'upgrade-insecure-requests': '1', 'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36', } FIELDNAMES = [ "sku", "url", "image_url", "title", "score", "reviews_count", "price", "is_cdav" ] DATA = [] class JavascriptChallengeError(Exception): pass class cDiscountScraper: def __init__(self): self.s = requests.Session() self.s.headers = HEADERS def solve_javascript_challenge(self, response): print('solving javascript challenge') raw_data = re.findall(r'(?<=__blnChallengeStore=)\{[^\;]+', response.text) assert raw_data and len(raw_data) == 1 raw_data = ''.join(raw_data) raw_data = json.loads(raw_data) challenge_cookie = raw_data['cookie'] challenge_cookie.pop('maxAge') challenge_cookie_value = challenge_cookie['value'] challenge_cookie_name = challenge_cookie['name'] self.s.cookies.set_cookie(requests.cookies.create_cookie(**challenge_cookie)) check_params = raw_data['checkChallengeParams'] url = 'https://www.cdiscount.com/.well-known/baleen/challengejs/check?%s=%s' % ( challenge_cookie_name, challenge_cookie_value ) data = '&'.join(['%s=%s' % (k,v) for k, v in check_params.items()]) response = self.s.post(url, data) assert response.status_code == 200 @retry(JavascriptChallengeError, tries=5, delay=5, backoff=1) def get_cdiscount_data(self): print('start') response = self.s.get(URL, headers=HEADERS) with open('first_req.html', 'w') as f: f.write(response.text) if 'Le JavaScript n\'est pas' in response.text: self.solve_javascript_challenge(response) raise JavascriptChallengeError assert response.status_code == 200 assert 'GEORGES' in response.text doc = html.fromstring(response.text) products = doc.xpath("//ul/[@id='lpBloc']/li[@data-sku]") assert products for product in products: sku = product.get('data-sku') url = "".join(product.xpath('./a/@href')) assert url.startswith('https://www.cdiscount.com') image_url = "".join(product.xpath('.//li/img[@class="prdtBImg"]/@data-src')) or "".join(product.xpath(".//li/img[@class='prdtBImg']/@src")) title = "".join(product.xpath('.//h2[@class="prdtTit"]/text()')) score = "".join(product.xpath('.//span[@class="c-stars-result c-stars-result--small"]/@data-score')) if score: score = float(score) / 20 reviews_count = "".join(product.xpath('.//span[@class="c-stars-result c-stars-result--small"]/following-sibling::span/text()')) if reviews_count: reviews_count = int(reviews_count.strip('()')) price = "".join(product.xpath('.//span[contains(@class, "price priceColor hideFromPro") and not(contains(@class, "price--xs"))]/text()')).strip('€') is_cdav = len(product.xpath('.//div[@class="cdavZone"]')) > 0 values = [sku, url, image_url, title, score, reviews_count, price, is_cdav] d = dict(zip(FIELDNAMES, values)) print(*d.values()) DATA.append(d) return DATA def write_csv(self, DATA): print('starting writing csv') with open('cdiscount_results.csv', 'w') as f: writer = csv.DictWriter(f, fieldnames=FIELDNAMES) writer.writeheader() for d in DATA: writer.writerow(d) if __name__ == '__main__': cdiscount_scraper = cDiscountScraper() DATA = cdiscount_scraper.get_cdiscount_data() cdiscount_scraper.write_csv(DATA) print('''~~ success _ _ _ | | | | | | | | ___ | |__ ___| |_ __ __ | |/ _ \| '_ \/ __| __/| '__| | | (_) | |_) \__ \ |_ | | |_|\___/|_.__/|___/\__||_| ''')f
Pour utiliser ce script, c’est très simple: télécharger le fichier .py, et lancer le script comme suit:
$ python3 cdiscount_scraper.py start solving javascript challenge start starting writing csv ~~ success _ _ _ | | | | | | | | ___ | |__ ___| |_ __ __ | |/ _ \| '_ \/ __| __/| '__| | | (_) | |_) \__ \ |_ | | |_|\___/|_.__/|___/\__||_|f
Et voilà!
Tutoriel étape par étape
Dans ce tutoriel, on va voir comment scraper les données des 50 premiers barbecues en vente sur cDiscount, et directement accessibles via cet URL.
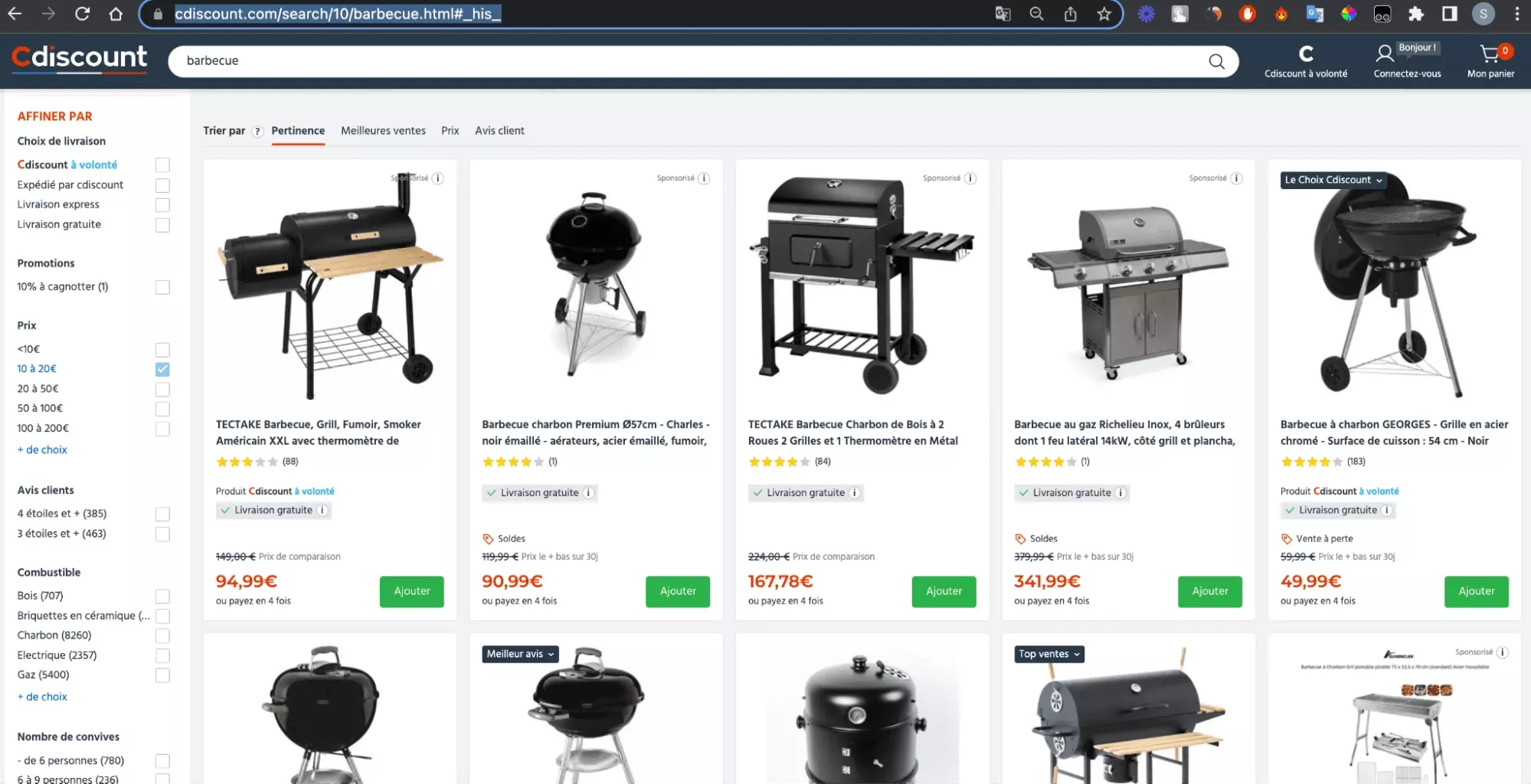
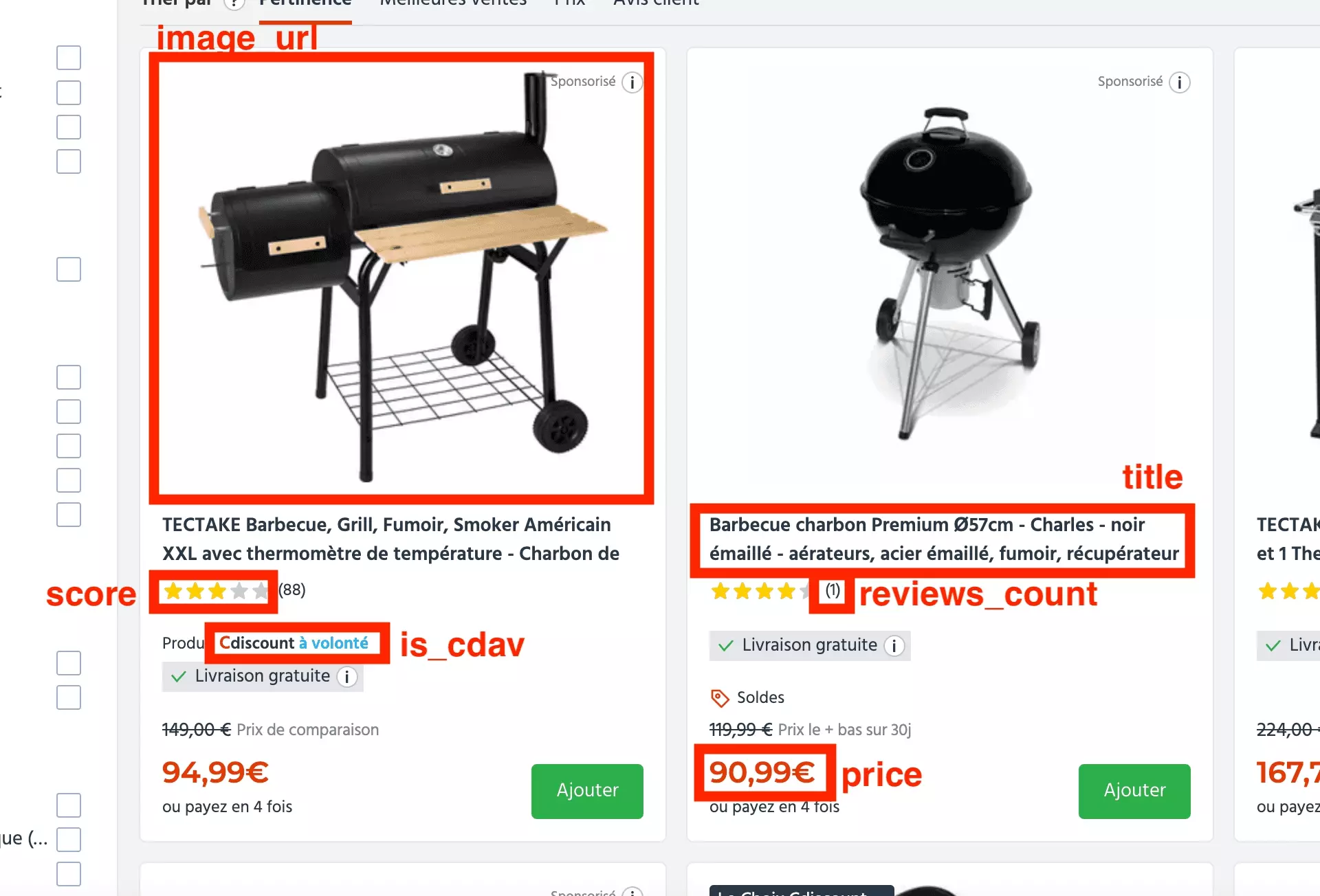
Et on va récupérer 8 attributs distincts, comme suit:
- sku
- url
- image_url
- title
- score
- reviews_count
- price
- is_cdav
Et ce comme illustré ci-dessous:
Ce tutoriel sera divisé en 4 étapes:
- Résoudre l’erreur 403
- Résoudre le challenge Javascript
- Récupérer les données dans la page HTML
- Enregistrer les données dans un fichier .csv
À nous les soirées protéinées au coin du feu. \ Allons-y!
1. Résoudre l’erreur 403
Intuitivement, on a envie d’écrire un script très simple: une requête simple vers l’URL de la page mentionnée plus haut, afin de récupérer les données présentes dans la page.
Un premier jet immédiat peut être construit comme suit:
import requests s = requests.Session() response = s.get("https://www.cdiscount.com/search/10/barbecue.html") with open("premier_jet.html", "w") as f: f.write(response.text)f
Sauf que voilà, lorsque l’on ouvre la dite page premier_jet.html, voilà ce qu’on obtient:
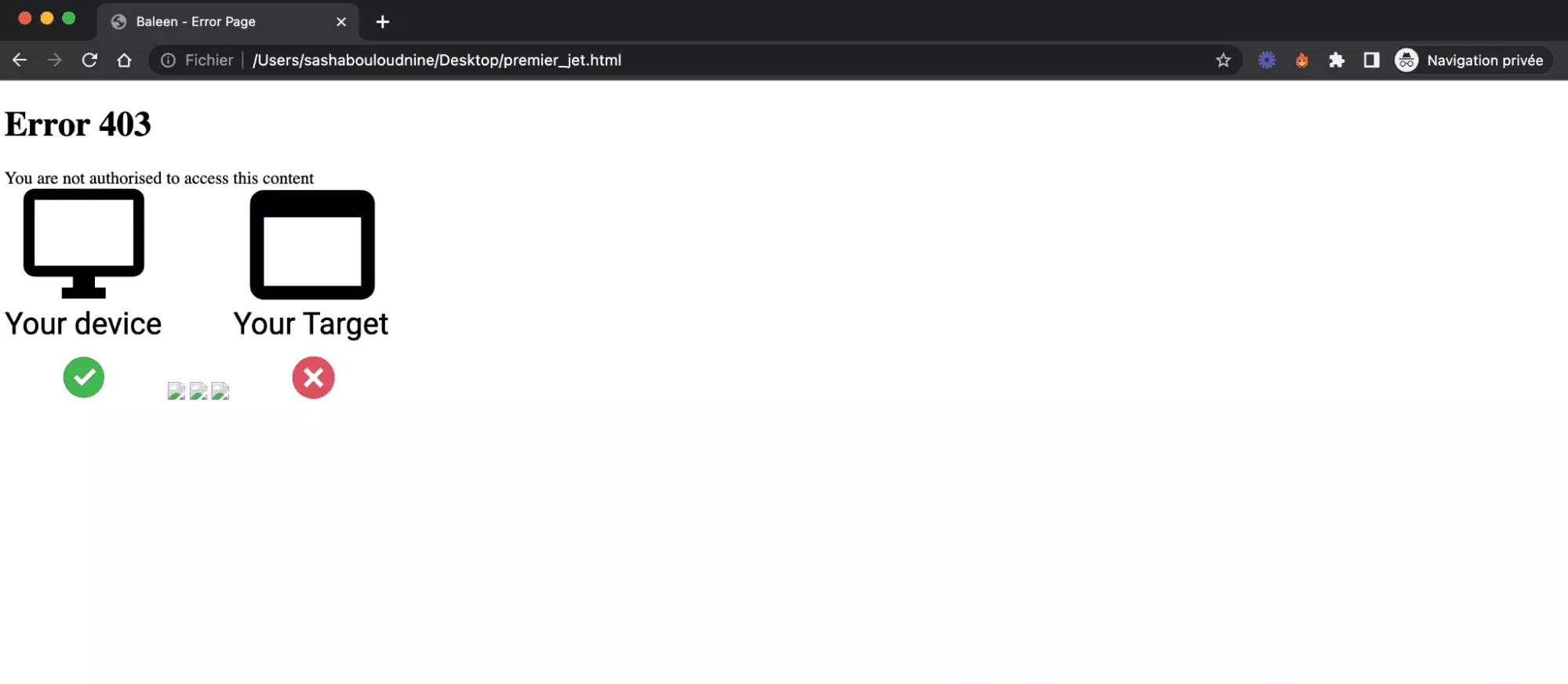
Une erreur 403. Coup dur.
On va donc ajouter des headers, pour que cette requête se rapproche de celle d’un utilisateur traditionnel.
On se rend sur Chrome, et on va commencer par ouvrir notre console de développeur: Clic droit > Inspecter > Network.
On va ensuite accéder à notre URL riche de données à scraper, c'est-à-dire la page cDiscount avec les barbecues.
Enfin, on va chercher, en utilisant la fonction recherche de la partie Network de la console, un mot présent sur la page. Ici le mot singulier: GEORGES.
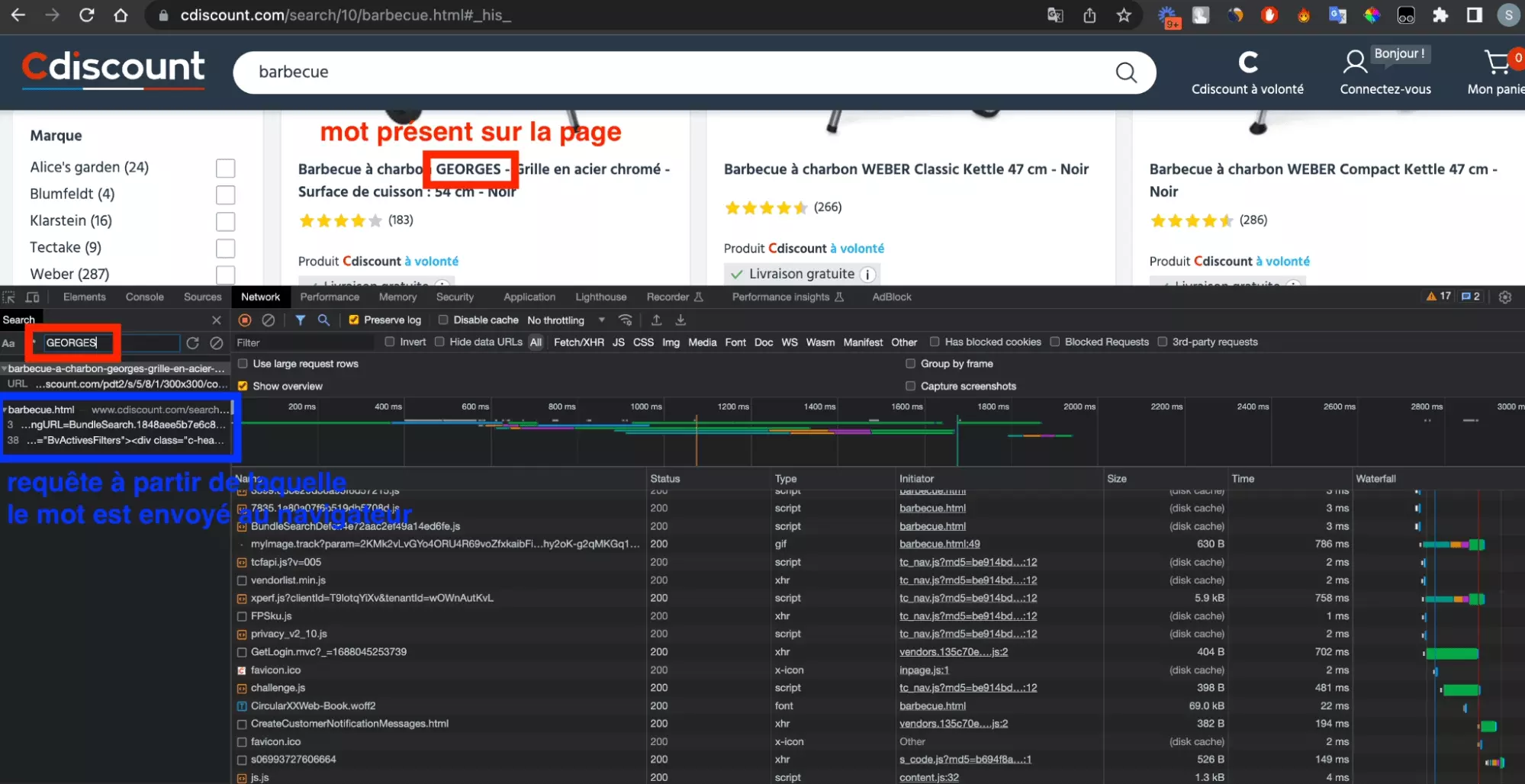
On ne considère pas la première requête, car il s’agit d’une requête qui ramène un fichier .jpg, c'est-à-dire l’image du produit en question. Pas très intéressant ici.
L’outil de recherche va nous permettre de trouver la requête initiale, ou requête originelle, à partir de laquelle la donnée a été amenée du serveur à notre navigateur.
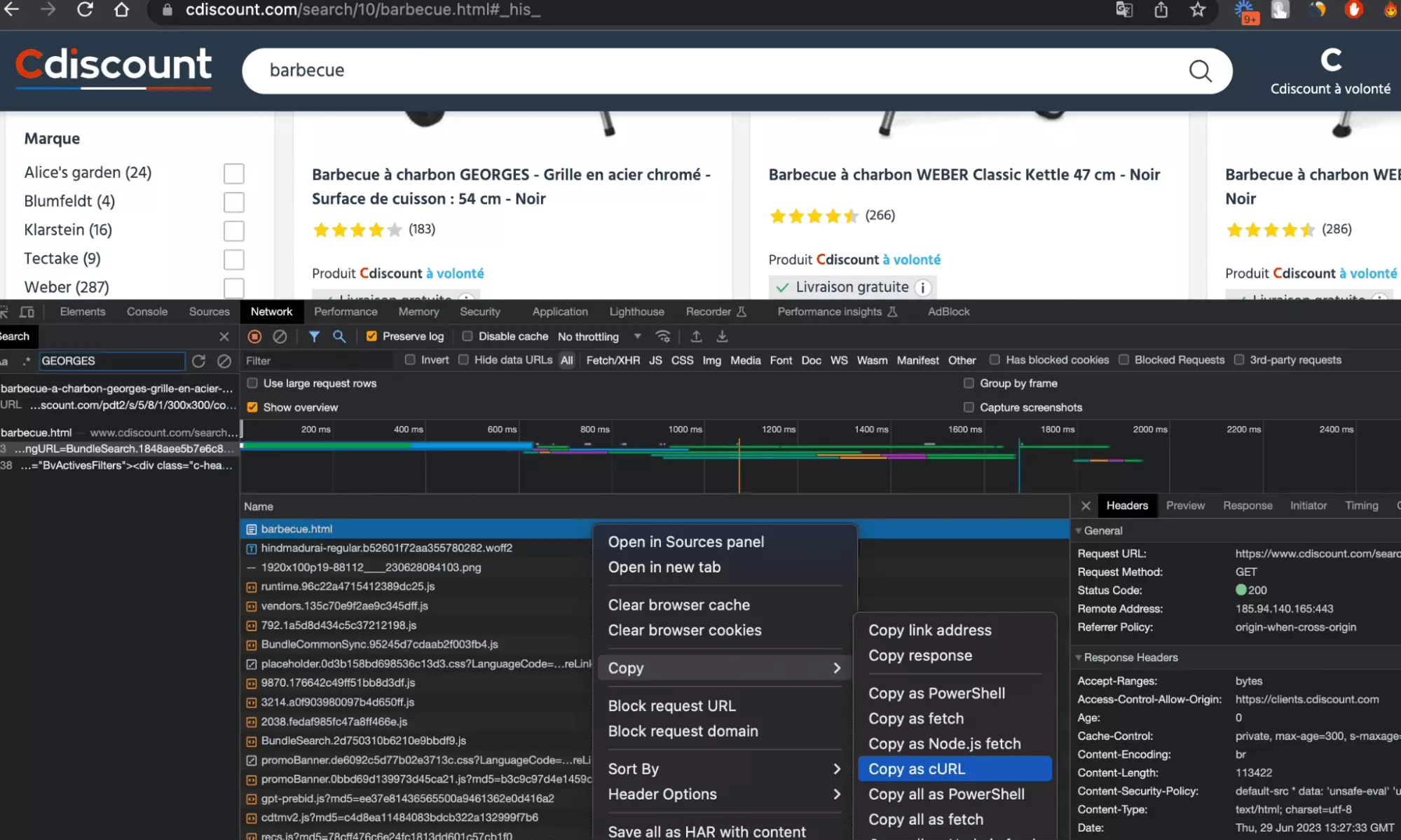
Une fois identifiée la requête pertinente, on va la copy as cURL, ou copier au format cURL en bon français, ce qui va nous permettre de sauvegarder, sous un format donnée, l’ensemble des paramètres de la requête effectuée:
Et notre notre code à cette étape:
import requests headers = { 'authority': 'www.cdiscount.com', 'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7', 'accept-language': 'fr-FR,fr;q=0.9,en-US;q=0.8,en;q=0.7', 'cache-control': 'max-age=0', 'cookie': 'CookieId=CookieId=230502110614CEICTORB&IsA=0; s_ecid=MCMID%7C16797685366166076358869452603464651012; TCPID=123521161511551056407; UniqueVisitContext=UniqueVisitId__230502110615FTHBMDWJ__; tcId=5ee0070d-c515-4236-bb68-f3d43c97d3df; _cs_c=3; TC_AB=A; app_vi=34214400%7C; prio30j=prio4; _$culture=CultureName__fr-FR__; visid_incap_2465919=dUWI1haIR9GTqqcgIrNCOwqgfGQAAAAAQUIPAAAAAACHWaWcYx2zEp5qWrQtGrgx; _cs_id=80e36f8d-3dcf-ab92-c779-066825140290.1683018376.3.1685889050.1685889037.1590586488.1717182376625; TC_PRIVACY=1@078%7C2%7C2%7C199@@@1685889051491%2C1685889051491%2C1701441051491@; TC_PRIVACY_CENTER=; _$cst=0; prio7j=prio4; chcook7=direct; SitePersoCookie=PersoCountryKey__FR__PersoLatitudeKey__45.1833__PersoLongitudeKey__0.7167__PersoTownKey__Perigueux__GeolocPriorityKey__10__PersoPostalCodeKey__24000__PersoUrlGeoSCKey__/n-190904/marketplace/retrait-immediat-paris.html__ExpressSellerId____ExpressShopName____ExpressGlobalSellerId____ShowroomVendorId____RetailStoreName____VehicleId__0__AddressId____; _$dtype=t:d; cache_cdn=; mssctse=W2dNXeEyrPIlc-Vb0OXhfpSvUDZBb4zp_O66j14y6UwCtJ9SHjEV2xrq24P65vvL6F_Rm25RpjG0CEkiod405g; AMCV_6A63EE6A54FA13E60A4C98A7%40AdobeOrg=1585540135%7CMCIDTS%7C19538%7CMCMID%7C16797685366166076358869452603464651012%7CMCAID%7CNONE%7CMCOPTOUT-1683025575s%7CNONE%7CvVersion%7C4.4.0; svisit=1; _$3custinf=AUT=0&XV1=0; s_cc=true; msswt=; s_pv=Recherche; msstvt=sN_Ypy2CO9_uH8xyMeB6Fv2fX_kGMtDY2oND-8_-lWTWuedd3ScG-4nLN4_lQVFy5wViq0BE3ivAYsnKanzoMQHgwnnSckuvFPg8yUubjzcr3HqX6UVH-sRcT8sSs10am8fzDvaNdYlrSCq2yhry8g; visit_baleen_ACM-655d43=cgDlAhbnqqYt9gTtRmBvPwVdT4hUToPAJr4Fu40-2VXUXZaHLgC04uiwcEhMl6TT7nIJYN1wYJoNIJxtPFz6FuPjeNF5ICa8GtFxrrdBTJjTA8HYk_k4wF7SqhK3ZWKXRW6DAYSNNFFW8UYUvJqV1p9DNjR01DBAPxauyeUtuKA-cTKEGkg0xCCbLqQiAuSAXLA8_GC0aEwlDs6qeWfDh126UIg6JBVPz8xWct_1oWJGgDk6qh3T1uj1RyFVQiWY4GFpSzTKA3EFrzx7rPpi_A; s_nr=1688044980321-Repeat; el2=0; tp=13575; VisitContextCookie=HGCJjPLdLJynSn3G8iVsFKxxgj6bTclHIMhEATBOtwStuI82FaEUuw; s_ppv=Recherche%2C11%2C4%2C1528', 'if-none-match': 'W/"fh_340c19a1c0ba672b7cdc06d54faa410dc8f8e7ff"', 'sec-ch-ua': '"Not.A/Brand";v="8", "Chromium";v="114", "Google Chrome";v="114"', 'sec-ch-ua-mobile': '?0', 'sec-ch-ua-platform': '"macOS"', 'sec-fetch-dest': 'document', 'sec-fetch-mode': 'navigate', 'sec-fetch-site': 'same-origin', 'sec-fetch-user': '?1', 'upgrade-insecure-requests': '1', 'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36', } response = requests.get('https://www.cdiscount.com/search/10/barbecue.html', headers=headers) with open('second_essai.html', 'w') as g: g.write(response.text)f
Pour des raisons de lisibilité, on a décommenter les cookies présents au niveau du headers, et supprimer les cookies qui étaient au format dictionnaire. Il s’agit seulement d’un ajustement esthétique, ça n’a aucune incidence sur la nature de la requête.
On lance notre code Python. Un fichier est enregistré, le bien nommé second_essai.html. Et en l’ouvrant avec Chrome… malheur, un écran complètement blanc:
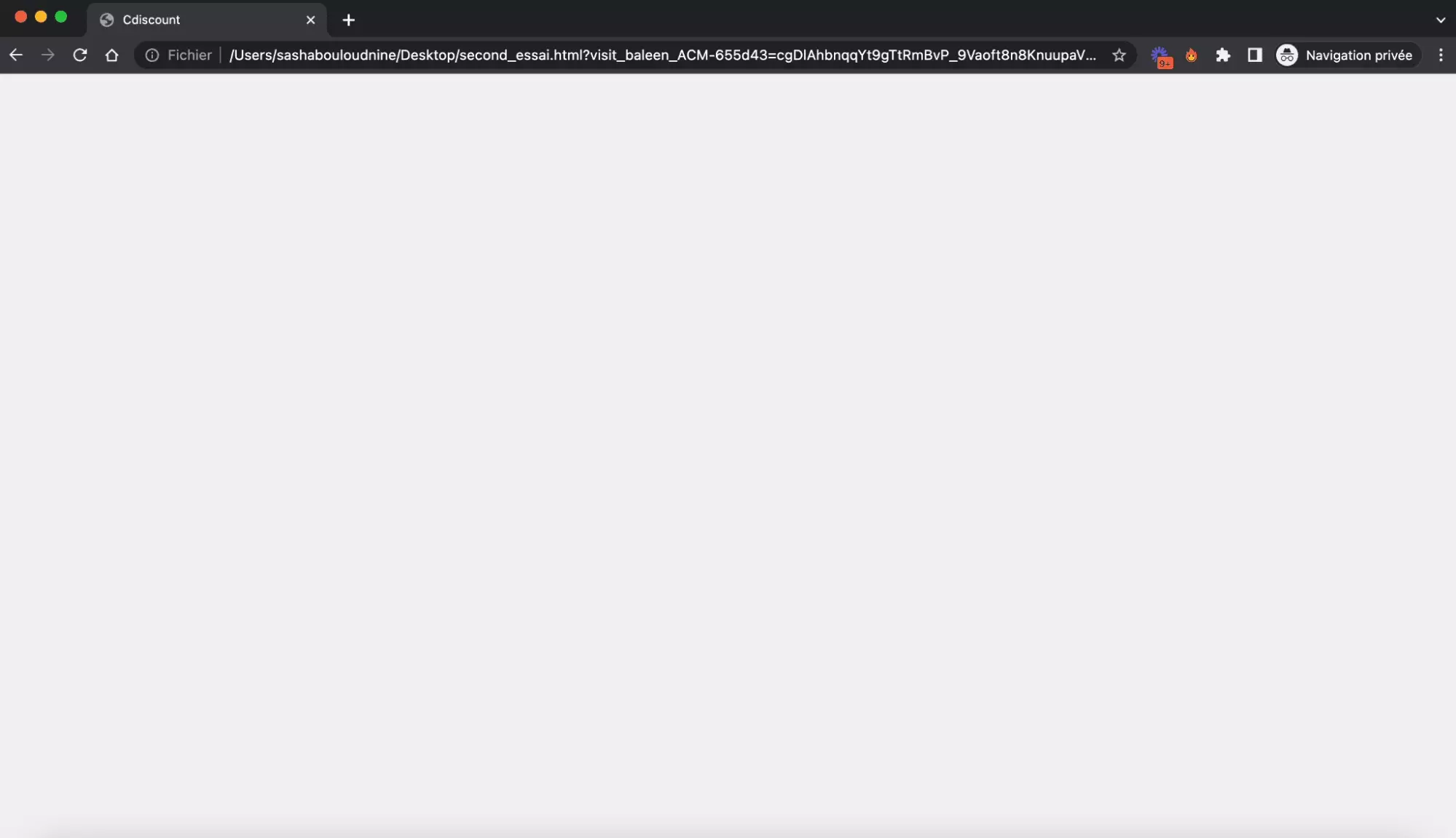
⚪
Pas une trace de barbecue qui soit. Inexploitable.
Est-ce qu’il est l’heure de faire appel à la mystérieuse requête POST?
On va voir ça dans la seconde partie.
2. Résoudre le challenge Javascript
On a installé les librairies de développement, on est allé chercher la requête pertinente… et c’est la douche froide. Une page blanche, avec rien de lisible, et rien d’exploitable.
On va commencer par aller voir ce qui se cache au niveau du code source de la page. On fait donc Clic droit > Afficher le code source:
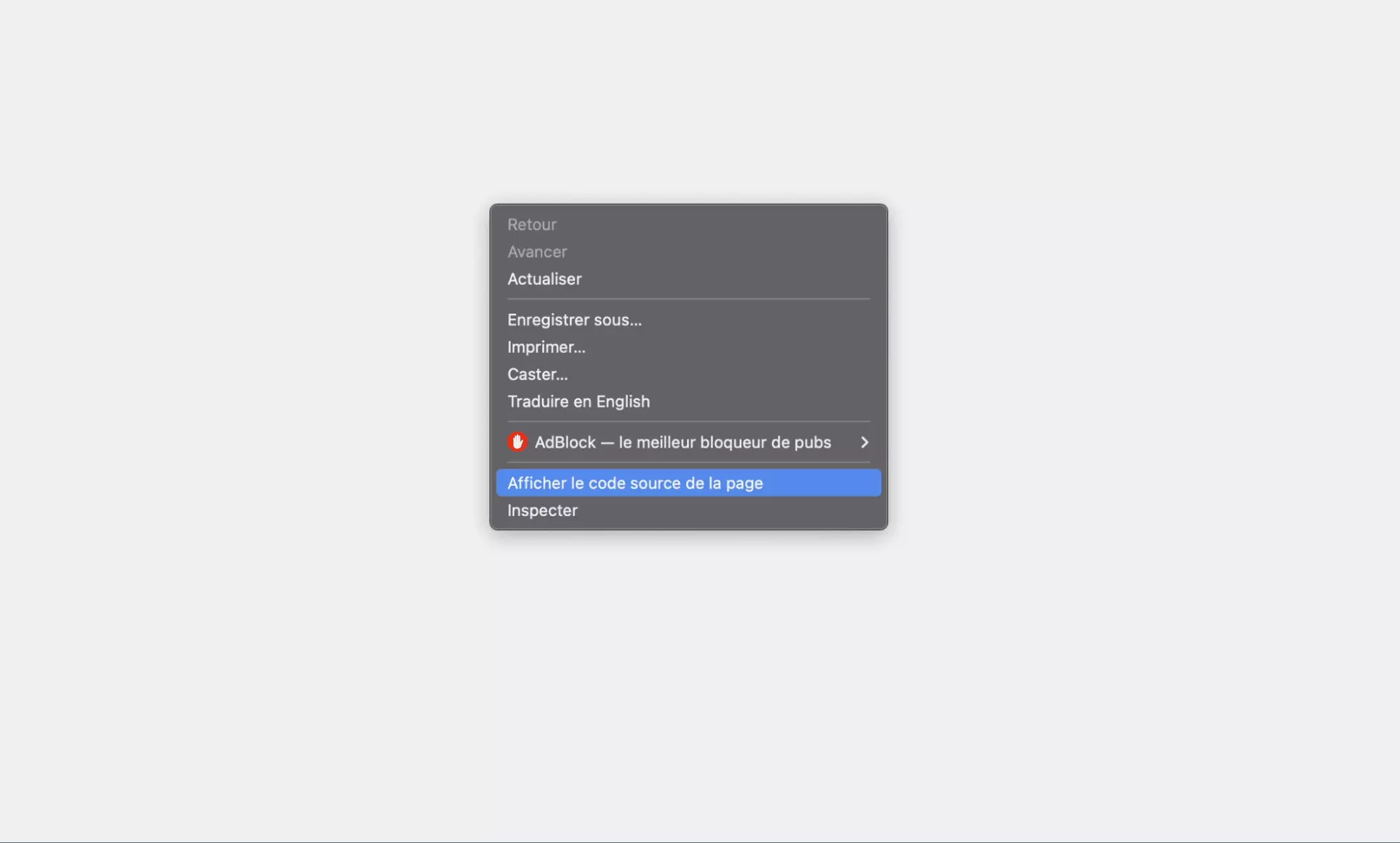
Et au niveau du code source, on va observer 2 éléments intéressants.
D’abord, on nous indique qu’il faut activer le Javascript afin d’accéder à la page. Il s’agit donc bien d’un challenge Javascript, c’est-à-dire que que le site exécute normalement un script Javascript présent sur la page.
L’exécution de ce script permet d’habitude à un navigateur usuel où le Javascript est activé par défault - Chrome, Firefox, tous les navigateurs en fait - d’être perçu comme licite par le site cible. Le plus souvent, par l’intermédiaire d’un cookie, qui agit comme un permis d’entrée.
👮
Comme nous utilisons un navigateur Python, le code Javascript n’est pas exécuté du tout, et la page est inaccessible.
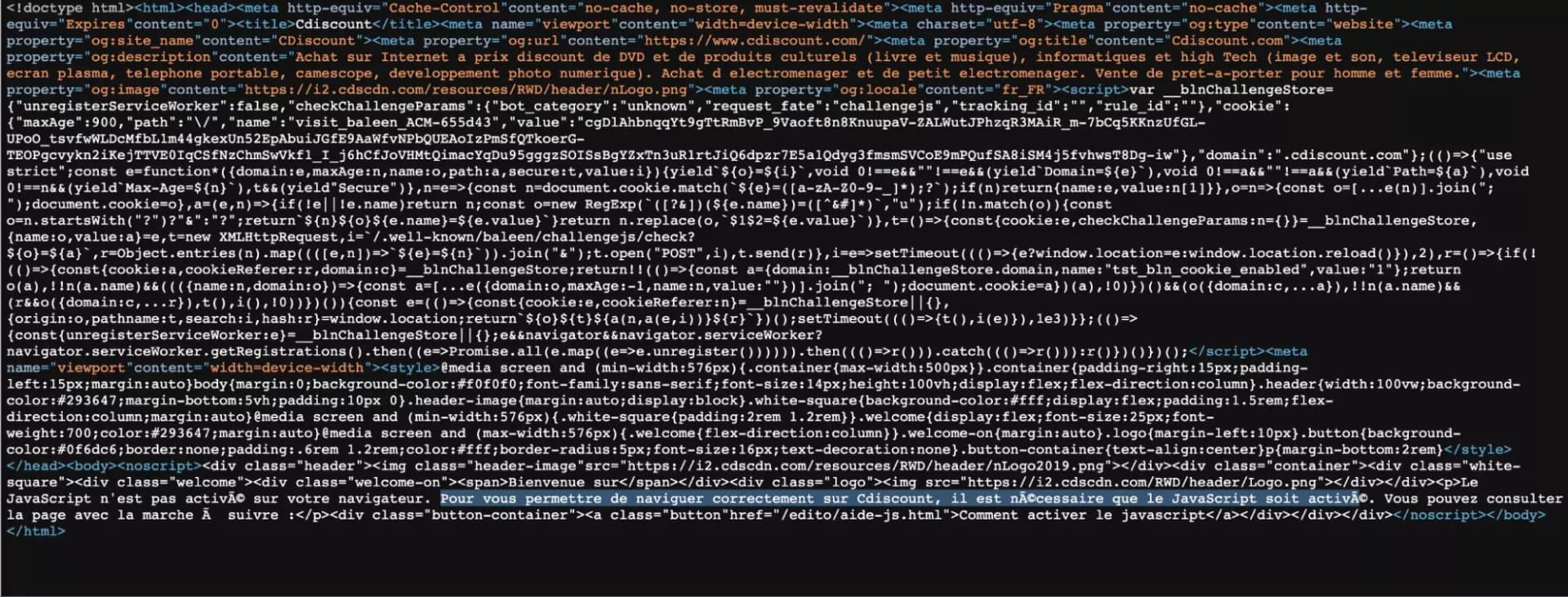
Si on regarde plus haut, bingo! Il y a bien du code Javascript, et notamment un cookie stocké dans la variable blnChallengeStore.
Ce code Javascript, qui est exécuté passivement par un navigateur usuel, il va donc falloir qu’on l’exécute nous-même, activement, avec du code en Python. Mais qu’est-ce qu’il fait au juste ce bout de script?
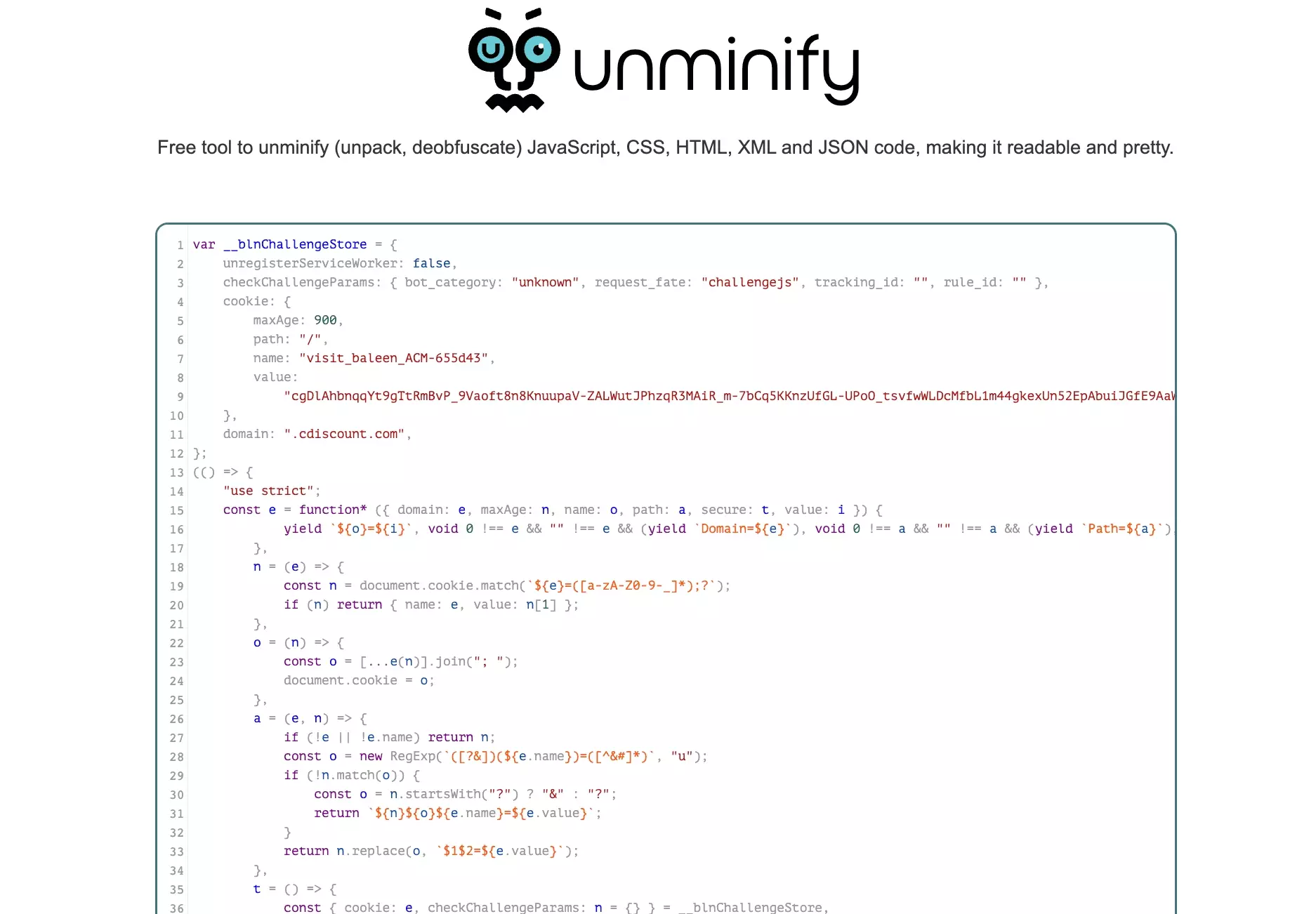
Soit vous êtes un dingue de Javascript, soit, on a pas bien avancé.
Pour faire simple, le script Javascript exécute les actions suivantes:
- il récupère le cookie présent dans la page
- il assigne le cookie au navigateur
- il réalise une requête POST vers un URL construit à partir de la valeur du cookie de la page
Oui, vous avez bien lu, c’est ici qu’intervient la mystérieuse requête POST.
C’est elle qui va nous permettre de contourner ce premier challenge Javascript. On va donc exactement reproduire ces étapes là, à l’aide du code Python!
On va donc d’abord commencer par récupérer la valeur du cookie présent dans le texte:
# on récupère la valeur du cookie dans le code source avec une regex raw_data = re.findall(r'(?<=__blnChallengeStore=)\{[^\;]+', response.text) assert raw_data and len(raw_data) == 1 raw_data = ''.join(raw_data) raw_data = json.loads(raw_data)f
On va ensuite assigner le cookie à notre session de navigation:
# on assigne le cookie à notre navigateur challenge_cookie = raw_data['cookie'] challenge_cookie.pop('maxAge') challenge_cookie_value = challenge_cookie['value'] challenge_cookie_name = challenge_cookie['name'] self.s.cookies.set_cookie(requests.cookies.create_cookie(**challenge_cookie))f
Enfin, on réalise cette fameuse requête POST:
# on réalise la mystérieuse requête POST check_params = raw_data['checkChallengeParams'] url = 'https://www.cdiscount.com/.well-known/baleen/challengejs/check?%s=%s' % ( challenge_cookie_name, challenge_cookie_value ) data = '&'.join(['%s=%s' % (k,v) for k, v in check_params.items()]) response = self.s.post(url, data) assert response.status_code == 200f
Et à ce stade, voilà notre code Python entier:
import requests import re import json from retry import retry URL = 'https://www.cdiscount.com/search/10/barbecue.html' HEADERS = { 'authority': 'www.cdiscount.com', 'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7', 'accept-language': 'fr-FR,fr;q=0.9', 'sec-ch-ua': '"Not.A/Brand";v="8", "Chromium";v="114", "Google Chrome";v="114"', 'sec-ch-ua-mobile': '?0', 'sec-ch-ua-platform': '"macOS"', 'sec-fetch-dest': 'document', 'sec-fetch-mode': 'navigate', 'sec-fetch-site': 'none', 'sec-fetch-user': '?1', 'upgrade-insecure-requests': '1', 'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36', } class JavascriptChallengeError(Exception): pass class cDiscountScraper: def __init__(self): self.s = requests.Session() self.s.headers = HEADERS def solve_javascript_challenge(self, response): print('solving javascript challenge') # on récupère la valeur du cookie dans le code source avec une regex raw_data = re.findall(r'(?<=__blnChallengeStore=)\{[^\;]+', response.text) assert raw_data and len(raw_data) == 1 raw_data = ''.join(raw_data) raw_data = json.loads(raw_data) # on assigne le cookie à notre navigateur challenge_cookie = raw_data['cookie'] challenge_cookie.pop('maxAge') challenge_cookie_value = challenge_cookie['value'] challenge_cookie_name = challenge_cookie['name'] self.s.cookies.set_cookie(requests.cookies.create_cookie(**challenge_cookie)) # on réalise la mystérieuse requête POST check_params = raw_data['checkChallengeParams'] url = 'https://www.cdiscount.com/.well-known/baleen/challengejs/check?%s=%s' % ( challenge_cookie_name, challenge_cookie_value ) data = '&'.join(['%s=%s' % (k,v) for k, v in check_params.items()]) response = self.s.post(url, data) assert response.status_code == 200 @retry(JavascriptChallengeError, tries=5, delay=5, backoff=1) def get_cdiscount_data(self): print('start') response = self.s.get(URL, headers=HEADERS) with open('main_response.html', 'w') as f: f.write(response.text) if 'Le JavaScript n\'est pas' in response.text: self.solve_javascript_challenge(response) raise JavascriptChallengeError if __name__ == '__main__': cdiscount_scraper = cDiscountScraper() cdiscount_scraper.get_cdiscount_data()f
Et alors… est-ce que ça a marché?
On va ouvrir le fichier main_response.html, qui est enregistré chaque fois que la requête vers l’URL principal est réalisée.
Et là, fantastique, de superbes outils de métal apparaissent, prêts à nous offrir des soirées d’été grasses et mémorables:
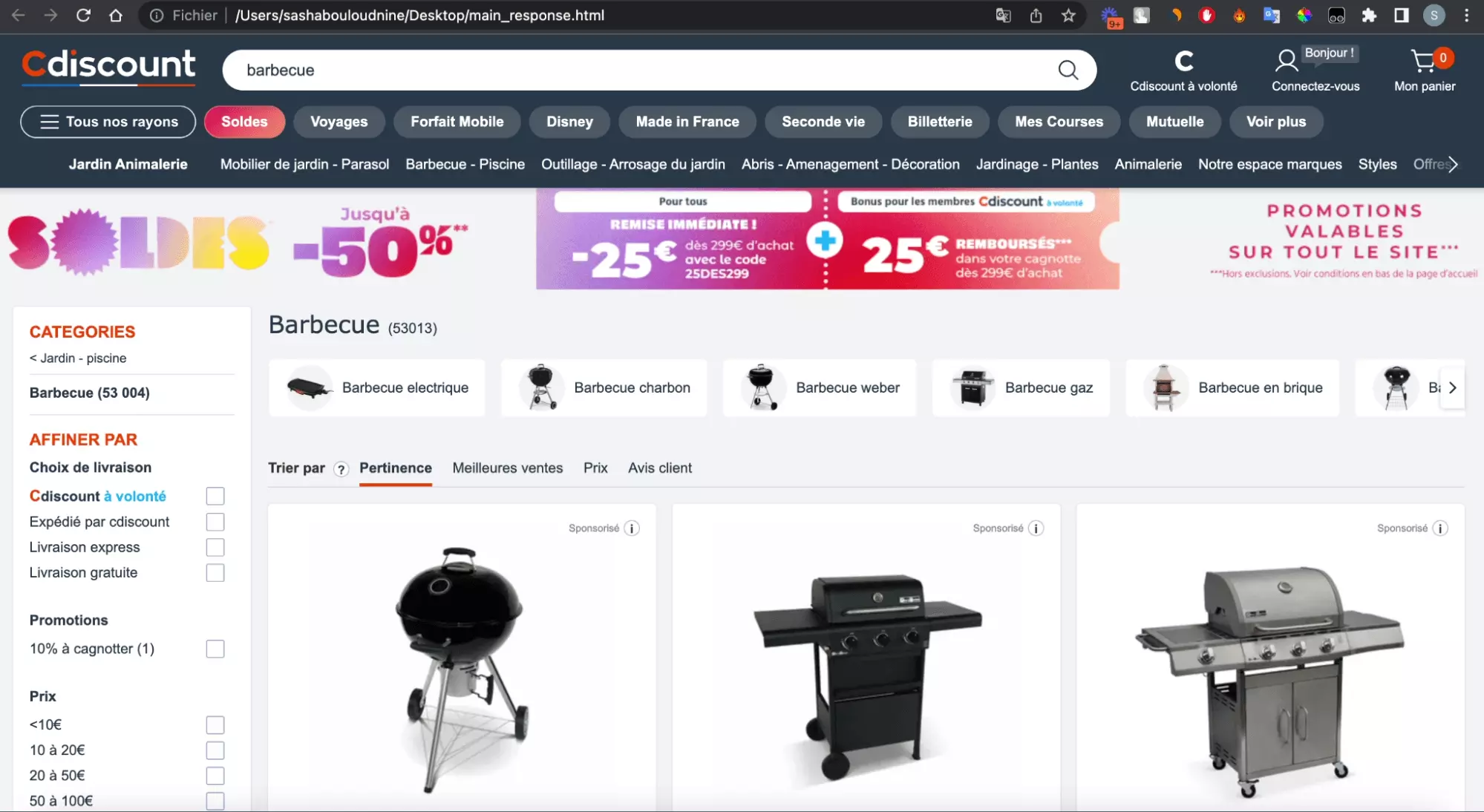
Magnifique! Le challenge Javascript a été résolu.
Et voilà, il ne nous reste plus qu’à récupérer les données présentes sur la page HTML, et à les enregistrer dans un fichier .csv.
Le plus dur a été fait.
3. Récupérer les données dans la page HTML
La route a été longue, et plutôt sinueuse, avec une première erreur 403, puis un écran blanc totalement déstabilisant.
Mais on s’en est sortis avec brio.
Dans cette partie, on va récupérer les données des 50 barbecues présents sur la page cDiscount, et pour chaque barbecue, 8 attributs distincts.
D’abord, on va stocker en haut de page la liste des attributs, et la liste qui contiendra à la fin de l’exécution du script, tous nos dictionnaires, avec 1 dictionnaire par produit.
... FIELDNAMES = [ "sku", "url", "image_url", "title", "score", "reviews_count", "price", "is_cdav" ] DATA = []f
import lxml ... class cDiscountScraper: def __init__(self): self.s = requests.Session() self.s.headers = HEADERS ... @retry(JavascriptChallengeError, tries=5, delay=5, backoff=1) def get_cdiscount_data(self): print('start') ... doc = html.fromstring(response.text)f
Et maintenant, comment récupérer ces données?
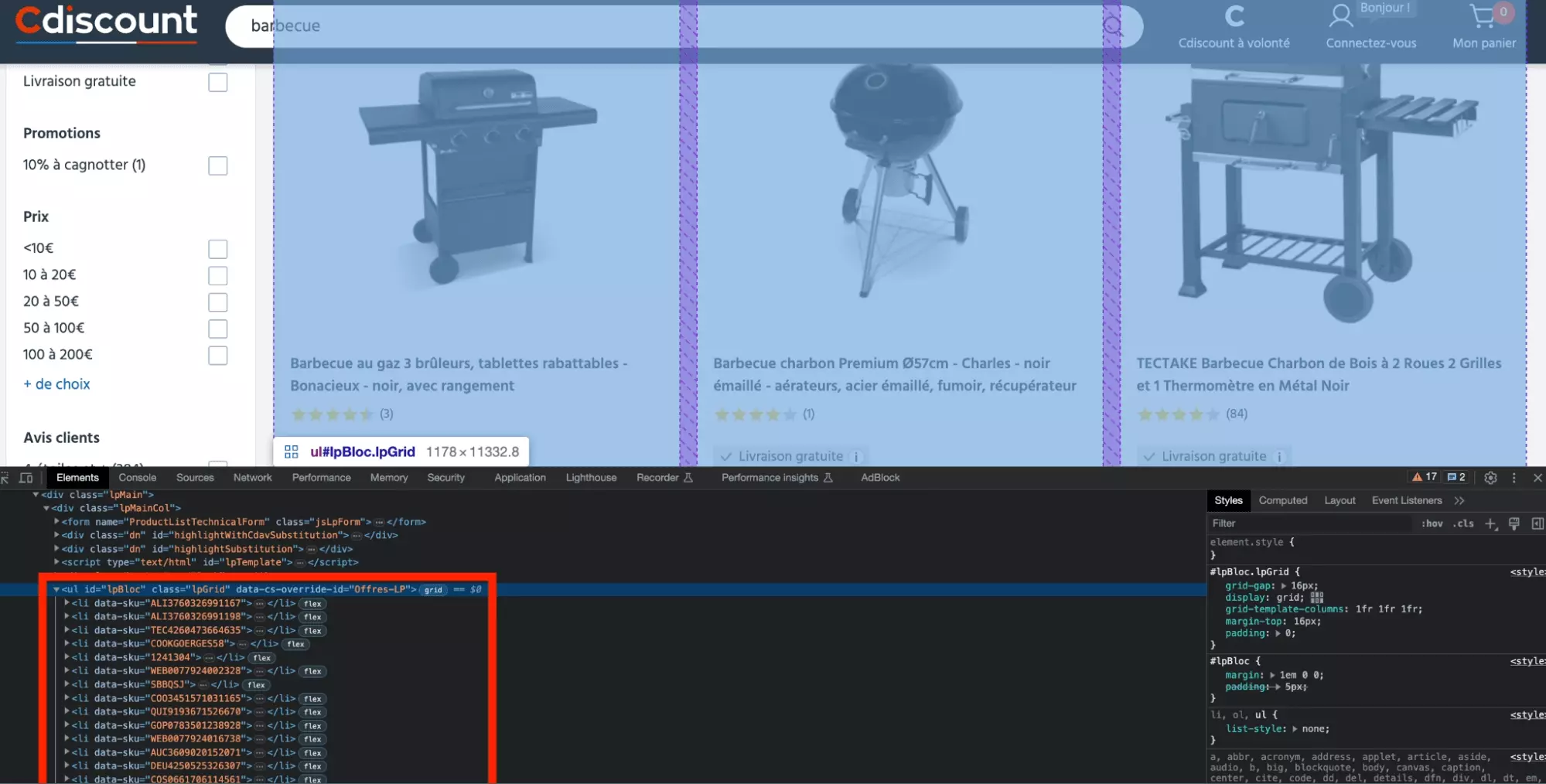
On va donc récupérer la liste des produits, en allant chercher les balises li présentes au sein de la balise ul qui a pour id iPbloc.
Voilà notre liste de produits!
products = doc.xpath("//ul/[@id='lpBloc']/li[@data-sku]") assert products for product in products: # récupérer les attributs de chaque produitf
Et ensuite, on va aller chercher les 8 attributs de chaque produit en utilisant la même logique, en fonction de la position de chaque attribut au sein du code HTML.
Avec un code comme suit:
sku = product.get('data-sku') url = "".join(product.xpath('./a/@href')) assert url.startswith('https://www.cdiscount.com') image_url = "".join(product.xpath('.//li/img[@class="prdtBImg"]/@data-src')) or "".join(product.xpath(".//li/img[@class='prdtBImg']/@src")) title = "".join(product.xpath('.//h2[@class="prdtTit"]/text()')) score = "".join(product.xpath('.//span[@class="c-stars-result c-stars-result--small"]/@data-score')) if score: score = float(score) / 20 reviews_count = "".join(product.xpath('.//span[@class="c-stars-result c-stars-result--small"]/following-sibling::span/text()')) if reviews_count: reviews_count = int(reviews_count.strip('()')) price = "".join(product.xpath('.//span[contains(@class, "price priceColor hideFromPro") and not(contains(@class, "price--xs"))]/text()')).strip('€') is_cdav = len(product.xpath('.//div[@class="cdavZone"]')) > 0f
Enfin, on va stocker tout ça dans un dictionnaire, afin de s’appuyer sur une donnée lisible, facilement manipulable, et proprement structuré:
values = [sku, url, image_url, title, score, reviews_count, price, is_cdav] d = dict(zip(FIELDNAMES, values)) print(d['sku'], d['title'], d['price']) DATA.append(d)f
Et voilà magnifique!
A ce stade, voilà notre code complet:
import requests import re import json from lxml import html from retry import retry import csv URL = 'https://www.cdiscount.com/search/10/barbecue.html' HEADERS = { 'authority': 'www.cdiscount.com', 'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7', 'accept-language': 'fr-FR,fr;q=0.9', 'sec-ch-ua': '"Not.A/Brand";v="8", "Chromium";v="114", "Google Chrome";v="114"', 'sec-ch-ua-mobile': '?0', 'sec-ch-ua-platform': '"macOS"', 'sec-fetch-dest': 'document', 'sec-fetch-mode': 'navigate', 'sec-fetch-site': 'none', 'sec-fetch-user': '?1', 'upgrade-insecure-requests': '1', 'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36', } FIELDNAMES = [ "sku", "url", "image_url", "title", "score", "reviews_count", "price", "is_cdav" ] DATA = [] class JavascriptChallengeError(Exception): pass class cDiscountScraper: def __init__(self): self.s = requests.Session() self.s.headers = HEADERS def solve_javascript_challenge(self, response): print('solving javascript challenge') # on récupère la valeur du cookie dans le code source avec une regex raw_data = re.findall(r'(?<=__blnChallengeStore=)\{[^\;]+', response.text) assert raw_data and len(raw_data) == 1 raw_data = ''.join(raw_data) raw_data = json.loads(raw_data) # on assigne le cookie à notre navigateur challenge_cookie = raw_data['cookie'] challenge_cookie.pop('maxAge') challenge_cookie_value = challenge_cookie['value'] challenge_cookie_name = challenge_cookie['name'] self.s.cookies.set_cookie(requests.cookies.create_cookie(**challenge_cookie)) # on réalise la mystérieuse requête POST check_params = raw_data['checkChallengeParams'] url = 'https://www.cdiscount.com/.well-known/baleen/challengejs/check?%s=%s' % ( challenge_cookie_name, challenge_cookie_value ) data = '&'.join(['%s=%s' % (k,v) for k, v in check_params.items()]) response = self.s.post(url, data) assert response.status_code == 200 @retry(JavascriptChallengeError, tries=5, delay=5, backoff=1) def get_cdiscount_data(self): print('start') # on fait une première requête response = self.s.get(URL, headers=HEADERS) with open('first_req.html', 'w') as f: f.write(response.text) # en cas de challenge javascript, on résoud ce challenge et on recommence if 'Le JavaScript n\'est pas' in response.text: self.solve_javascript_challenge(response) raise JavascriptChallengeError # on s'assure que la réponse obtenue est exploitable # merci georgio assert response.status_code == 200 assert 'GEORGES' in response.text # on parse le document avec lxml doc = html.fromstring(response.text) products = doc.xpath("//ul/[@id='lpBloc']/li[@data-sku]") assert products for product in products: # on récupère les attributs de chaque produit sku = product.get('data-sku') url = "".join(product.xpath('./a/@href')) assert url.startswith('https://www.cdiscount.com') image_url = "".join(product.xpath('.//li/img[@class="prdtBImg"]/@data-src')) or "".join(product.xpath(".//li/img[@class='prdtBImg']/@src")) title = "".join(product.xpath('.//h2[@class="prdtTit"]/text()')) score = "".join(product.xpath('.//span[@class="c-stars-result c-stars-result--small"]/@data-score')) if score: score = float(score) / 20 reviews_count = "".join(product.xpath('.//span[@class="c-stars-result c-stars-result--small"]/following-sibling::span/text()')) if reviews_count: reviews_count = int(reviews_count.strip('()')) price = "".join(product.xpath('.//span[contains(@class, "price priceColor hideFromPro") and not(contains(@class, "price--xs"))]/text()')).strip('€') is_cdav = len(product.xpath('.//div[@class="cdavZone"]')) > 0 values = [sku, url, image_url, title, score, reviews_count, price, is_cdav] d = dict(zip(FIELDNAMES, values)) print(d['title'], d['score'], d['price']) DATA.append(d) return DATA if __name__ == '__main__': cdiscount_scraper = cDiscountScraper() DATA = cdiscount_scraper.get_cdiscount_data()f
Et à l’exécution du script, de superbes données, parfaitement récupérées depuis le code source:
$ python3 cdiscount_scraper_202306.py start solving javascript challenge start TECTAKE Barbecue, Grill, Fumoir, Smoker Américain XXL avec thermomètre de température - Charbon de Bois 3.0 94,99 Barbecue charbon Premium Ø57cm - Charles - noir émaillé - aérateurs, acier émaillé, fumoir, récupérateur de cendres 4.0 90,99 Barbecue au gaz 3 brûleurs, tablettes rabattables - Bonacieux - noir, avec rangement 4.5 139,99 COSTWAY Barbecue à Charbon BBQ avec Tablette Latérale Pliable,2 Roues 2 Grilles Double Thermomètre 120,6x68,2x107,3 cm Noir 5.0 194,99 Barbecue à charbon GEORGES - Grille en acier chromé - Surface de cuisson : 54 cm - Noir 4.0 49,99 Barbecue à charbon WEBER Classic Kettle 47 cm - Noir 4.5 99,00 Barbecue à charbon WEBER Compact Kettle 47 cm - Noir 4.5 81,99 ...f
Et après?
4. Enregistrer les données dans un fichier .csv
On a contourné les obstacles divers et variés présents sur notre route, et récupéré dans une page HTML plutôt chargée, tous les attributs de nos grosses machines à charbon.
Bravo!
Dans cette dernière partie, on va simplement enregistrer ces données dans un fichier .csv.
On dispose d’une liste de dictionnaires, pour cette dernière partie, on va donc utiliser l’outil csvDictwriter, un objet directement accessible depuis la librairie csv native de Python.
On va donc fonctionner comme suit:
- Créer un fichier .csv
- Créer l’outil d’écriture càd le writer
- Écrire les headers, càd la première ligne du fichier avec les labels
- Écrire chaque dictionnaire dans une ligne à part entière
Et le code commenté ici:
import csv ... class cDiscountScraper: ... def write_csv(self, DATA): print('starting writing csv') # on crée un fichier csv qui a pour nom 'cdiscount_results.csv' with open('cdiscount_results.csv', 'w') as f: # on crée notre objet writer, en lui fournissant la liste des labels et le fichier créé f writer = csv.DictWriter(f, fieldnames=FIELDNAMES) # on crée la première ligne avec les labels writer.writeheader() # on enregistre chaque dictionnaire dans une ligne dédiée for d in DATA: writer.writerow(d) ... if __name__ == '__main__': cdiscount_scraper = cDiscountScraper() DATA = cdiscount_scraper.get_cdiscount_data() cdiscount_scraper.write_csv(DATA) print('success > done')f
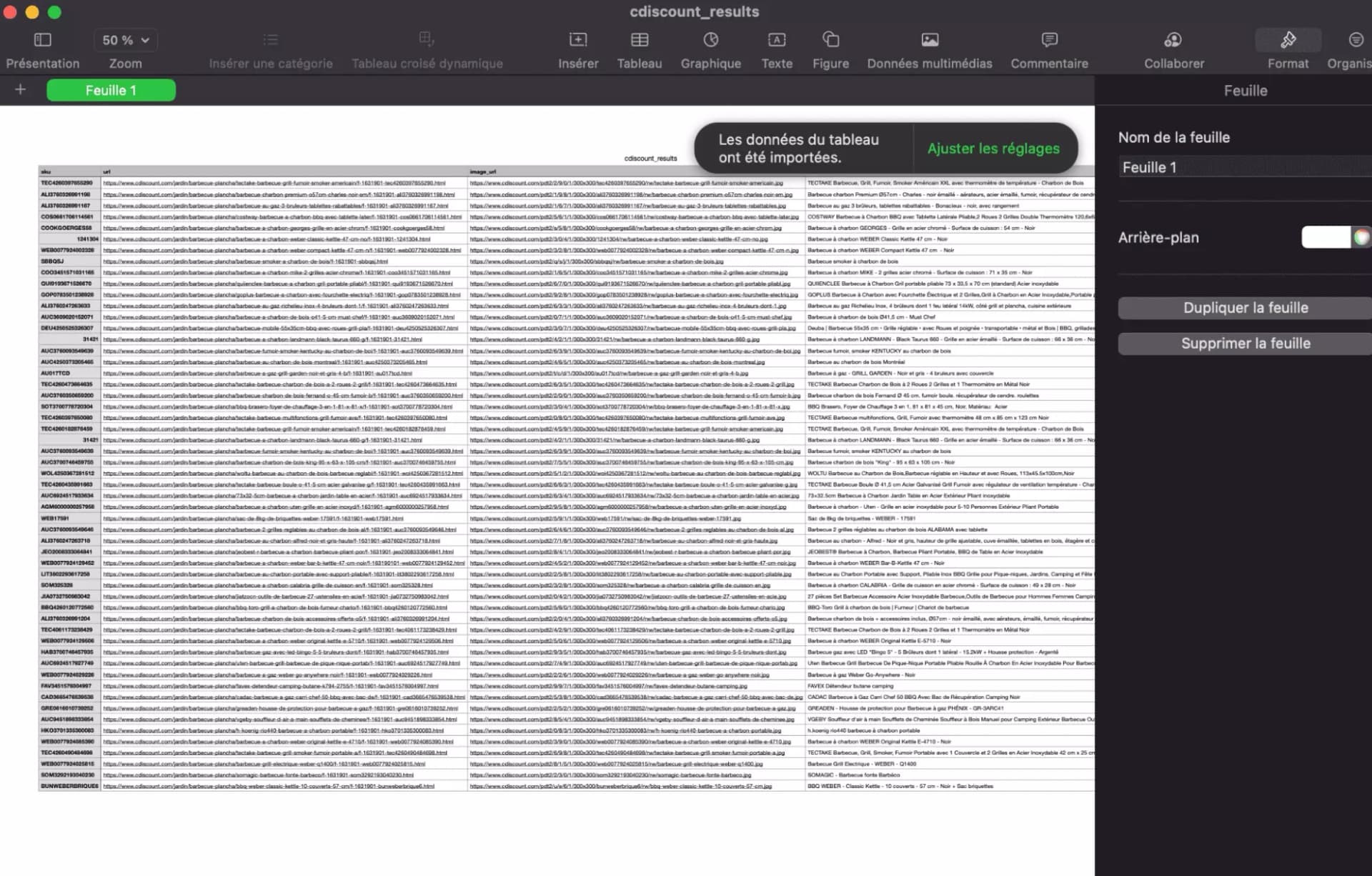
On lance le script et.. Ta-da!
Toutes les données ont été proprement collectées, et sont directement exploitables au format csv. C’est propre, structuré, et ultra-rapide.
Bénéfices
On vient de le voir dans la partie précédente, la collecte de données produits sur cDiscount, à partir d’une URL fonctionne à merveille.
Quelles sont les bénéfices de cette solution?
La méthode est rapide. Ainsi, on a pu scraper les données d’une page produit cDiscount, soit 50 produits distincts, en un peu moins de 2 secondes. Étendue à plus large échelle, ça représente les données de 1800 produits récupérés chaque heure.
A titre de comparaison, on estime empiriquement qu’un être humain, pour réaliser la même tâche, va mettre 10 secondes par article, soit 1800 produits récupérés toutes les 5 heures. Il s’agit donc d’un rapport de 1 à 5, par rapport à une méthode traditionnelle.
Par ailleurs, cette méthode est précise. Sauf cas non anticipé, ce qui peut arriver, les données vont être collectées systématiquement de la même manière. Pas d’erreur, pas d’imprécision. Des données toujours précises et exploitables.
Limitations
Si les avantages sont certains, quelles sont les désavantages?
D’abord, dans le cadre de ce tutoriel rapide, l’outil n’a pas de pagination. On récupère les données de la première page de produits, mais pas les données des pages suivantes. L’exhaustivité est donc limitée.
Par ailleurs, toujours dans le cadre de ce tutoriel de démonstration, on ne visite pas la page de chaque produit. Aussi, on passe à côté d’une large gamme d’attributs. Prix de la livraison, nom du vendeur, points fort, date de livraison, caractéristiques avancées du produit ou avis clients: tous ces éléments manquent.
🤖
FAQ
Est-ce que le scraping sur cDiscount est légal en France?
Oui, c’est entièrement légal!
Est-ce qu’il existe une solution no-code de scraping de produits cDiscount?
Non, pas pour le moment. On y réfléchit!
🤓
Pourquoi ne pas utiliser l’API officielle cDiscount?
Toutefois, l’API ne permet pas de collecter les données présentes sur le site: catégories, produits, vendeurs, reviews.
Elle permet simplement d’effectuer programmatiquement des tâches du côté vendeur: modification de prix ou de stock, mise en ligne ou retrait de produit, logistique.
Pour tout ce qui est récupération de données publiquement accessibles, le scraping est indispensable.
Est-ce que le script de scraping cDiscount va toujours fonctionner?
A priori, oui! Le scraper de produits à partir d’une URL de catégorie cDiscount a été construit pour être résilient dans le temps.
Toutefois, il peut arriver que la structure du site change. Dans ce cas là, n’hésitez pas à nous contacter via le chat, ou directement depuis notre page dédiée.
Conclusion
Et voilà, c’est la fin de ce tutoriel!
Dans ce tutoriel, on a vu comment scraper les données des produits à partir d’une catégorie cDiscount avec Python, et requests. Et récupérer les attributs principaux: le titre, le prix, le nombre d’avis, ou le score.
Surtout, nous avons vu comment résoudre deux challenges successifs: la page 403, premier obstacle pour scraper brutal et pressé, et le challenge javascript, script présent sur la page qu’il a fallu nous même exécuter avec un code Python maison.
Attention, ce tutoriel, parce que c’est un tutoriel, est limité: pas de pagination, pas d’attributs supplémentaires, et surtout pas de gestion du hCaptcha, qui finit par limiter la navigation sur cDiscount.
Et dans ce cas là, on vous invite à nous contacter directement ici.
Happy scraping!
🦀
 Sasha Bouloudnine
Sasha Bouloudnine Co-founder @ lobstr.io depuis 2019. Fou de la data et amoureux zélé du lowercase. Je veille à ce que vous ayez toujours la donnée que vous voulez.