Data scraping is illegal!
Data Scraping consists in collecting data on the internet from publicly available sources, leveraging bot-built automations. It thus allows users to gather data at high-speed, and consequently extremely competitive price. Endly, it will allow you to convert unstructured data, mainly from web pages online, into clean, usable, structured datasets.
Emerging and extremely promising fast-pace double digit-growth industry in a word. Huh.
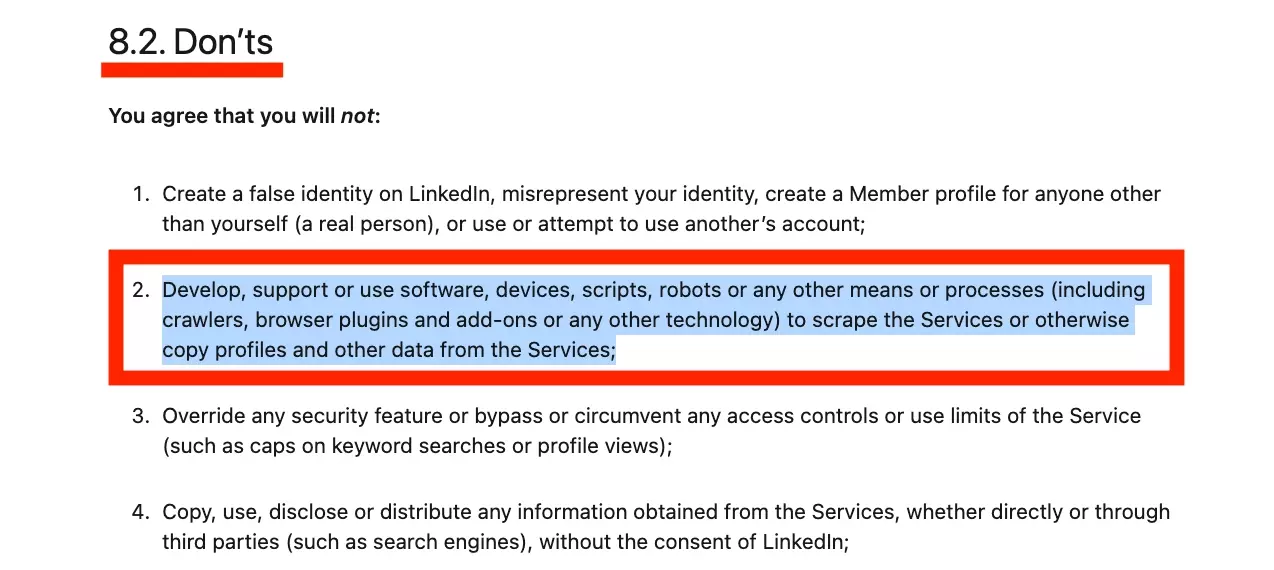
Don’t. Explicit enough.
Thus, is such a large industry relying on illegal practices? After all, is it not similar to stealing?
tl;dr
Let’s be clear here: data scraping is of course a fully legal activity.
Public data, specifically facts (prices, names, locations), are not related to any property ownership. Private companies denying automated access are overstepping its rights, privatizing collectively-owned information.
As all area, the scope of activity is though limited to restrictions:
- no copyright-related material
- no container replication
In other words, you can collect data at high-scale through data scraping activity. But, please, do not gather artworks, and do not reproduce initial database structure.
Period.
Overview
Our data
Data that is factual has no copyright protection under U.S. law; it is not possible to copyright facts.
Basically speaking, you can collect data manually, staffing a low-paid, unhappy intern, whose 9-5 is copy-pasting content on a web page. Or you can use a state-of-the art, technology-driven, competitive scraper. Getting structured data at a competitive price. And leveraging precious human resources.

Art is art
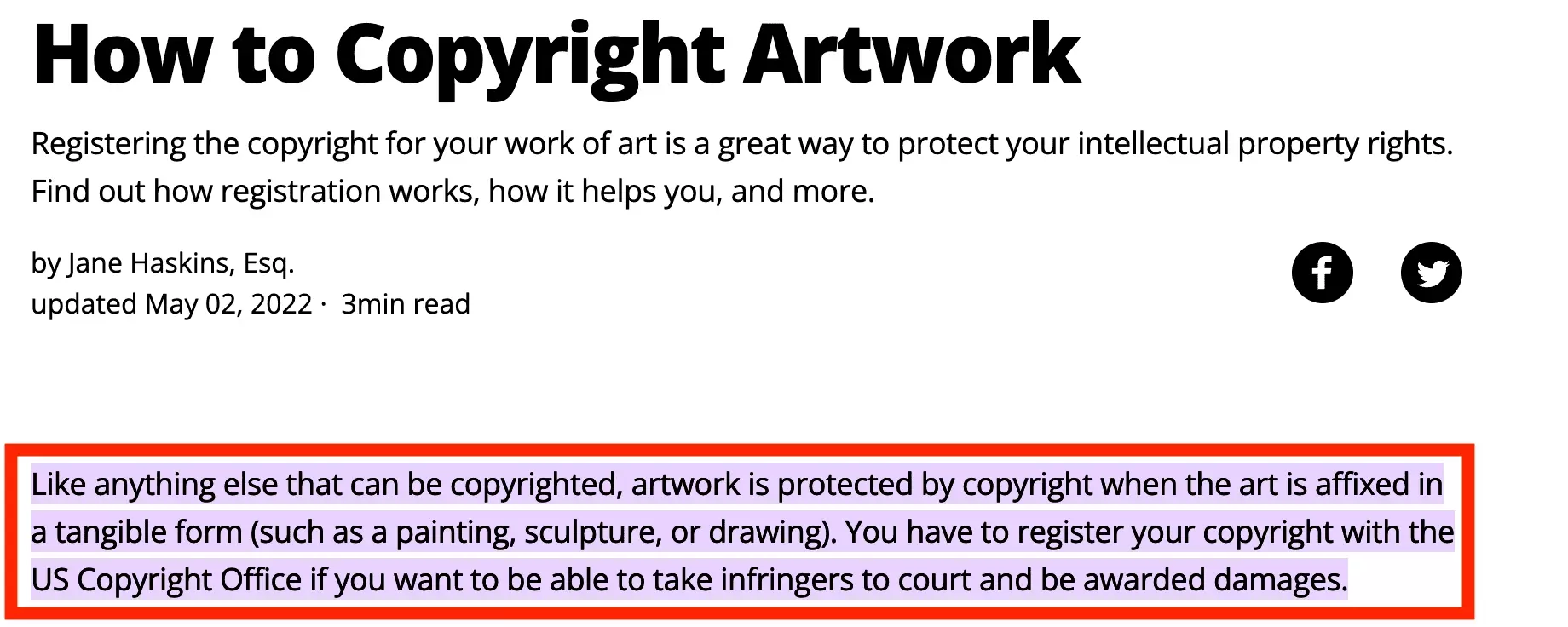
Data scraping is thus a legal activity, but downloading artworks available on the internet at large scale and re-selling them on the Internet without rewarding the original maker is of course a clear violation of the right.
Art is art.
Content only

A database, on the other hand, can have a thin layer of copyright protection. Deciding what data needs to be included in a database, how to organize the data, and how to relate different data elements are all creative decisions that may receive copyright protection.
In other words, if the facts are publicly owned, the structure of the container hosting these facts — such as table organization, datapoints labels, and overall database architecture — is to be considered as a copyright-material.
Content, yes! Container, be careful.
Conclusion
Data scraping is a fully legal — and highly value-added — activity, allowing the final user to rely on structured and clean data, acquired at a competitive price. Publicly available data is not related to any copyright and can be considered as collectively owned.
If some large private companies are explicitly banning this kind of activity, they do not rely on any legal support, and are overstepping their rights.
Happy scraping!
🦞