How to scrape data on Leboncoin with no code for free?
Overview
Beyond the colossal volume, each ad on leboncoin is an exceptional mine of information. On a real estate ad, you can find the title of the ad, but also the pictures, the price of the property, the location, the phone number of the advertiser, the number of rooms...
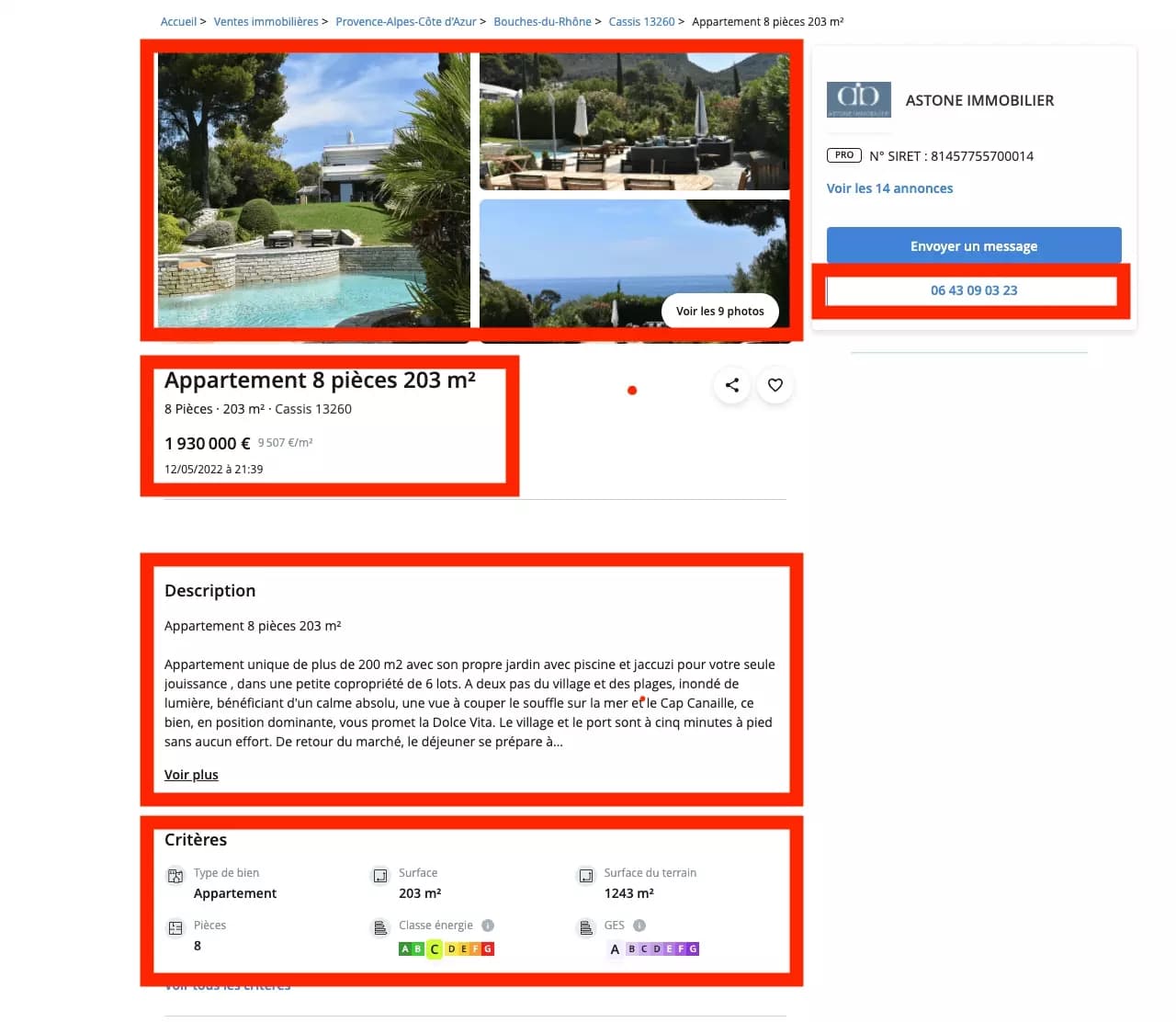
With a little Python script, it should do it... A few lines of code, et voilà!
import requests
s = requests.Session()
s = requests.Session()
r = s.get('https://www.leboncoin.fr/ventes_immobilieres/2156084495.htm')
with open('2156084495.htm', 'w') as f:
f.write(r.text)
So, how can you scrap on leboncoin, and get all the new ads of a given category every day, without any code, without any trouble?
In this article, we'll see how to do that in about 30 seconds. No more and no less.
🤖
Target
First of all, we're going to go to leboncoin and take the search URL - this is the initial URL from which the robot will retrieve the ads.
Just go to leboncoin, use the set of search criteria of your choice, and retrieve our precious URL.
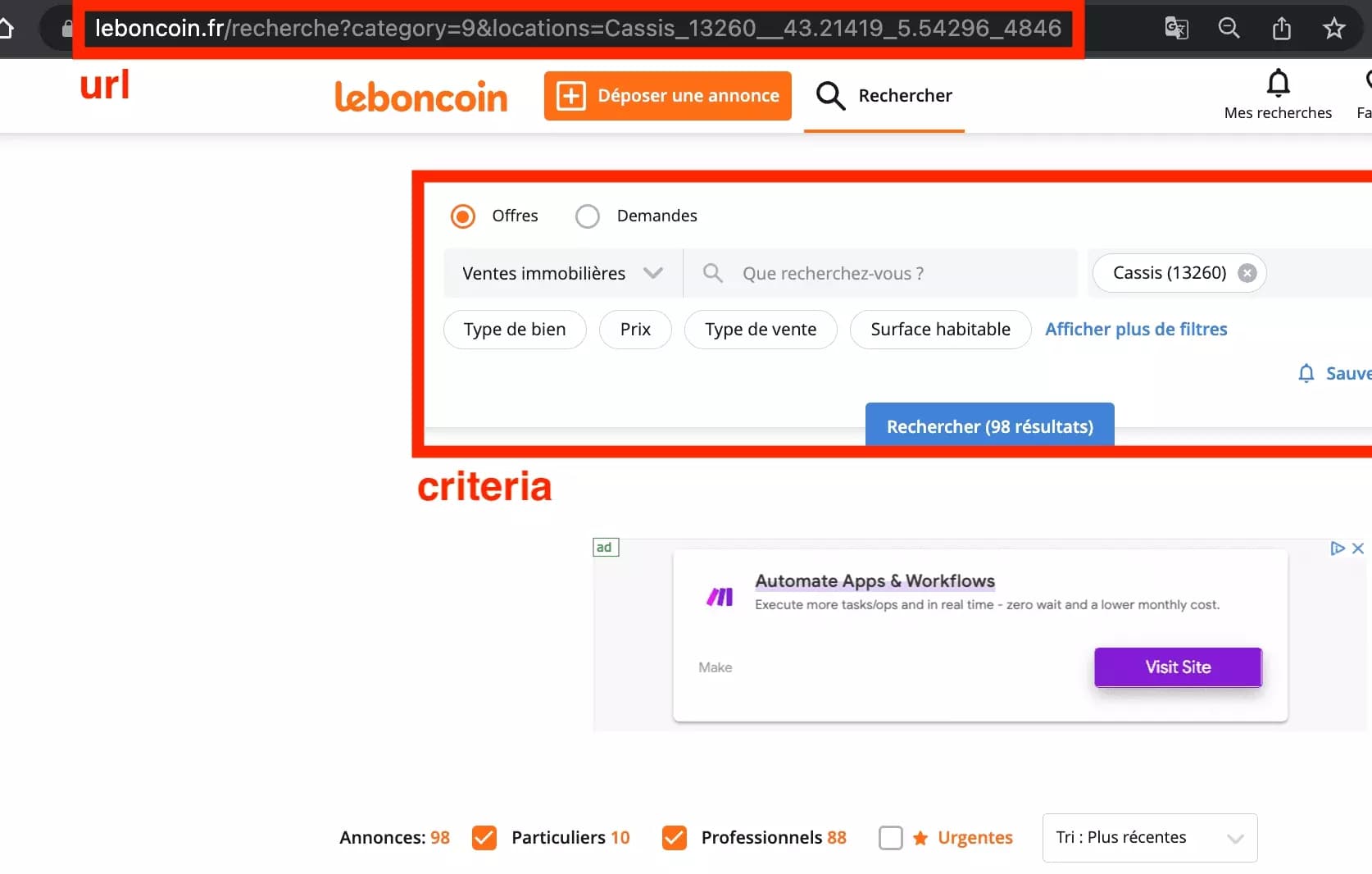
You have to know how to treat yourself...
🌞
Setup
Now let's set up the online collection tool! 0 lines of code. 30 second top-chrono. As easy as that.
First let's quickly go to the nice scraping tool, directly controllable from an interface, right here:
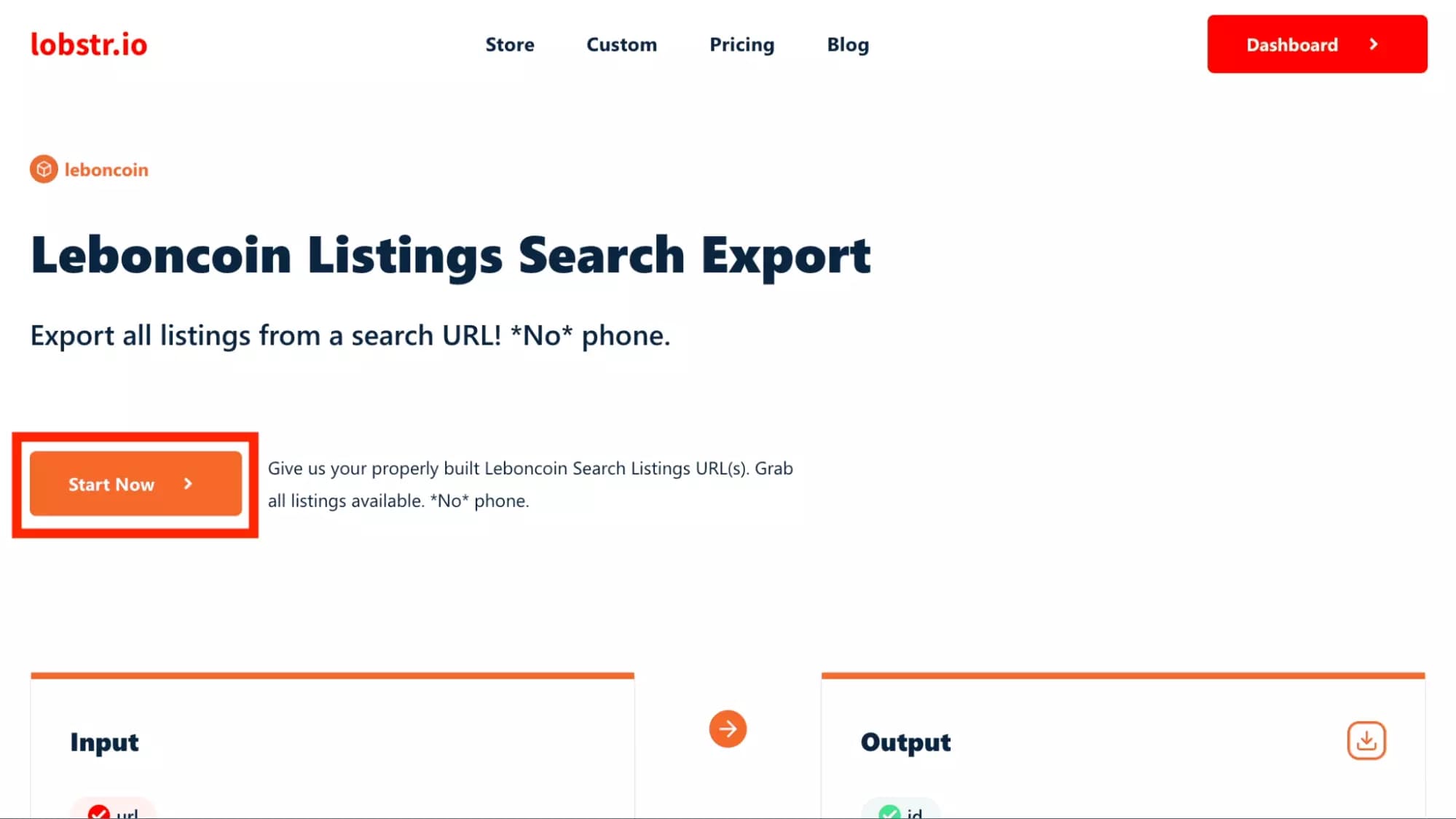
by clicking on the right of "Output" on the little download icon, you can download a sample of a hundred lines, and already appreciate the data format
Then, let's create a new cluster:
The UX has been really well thought out.
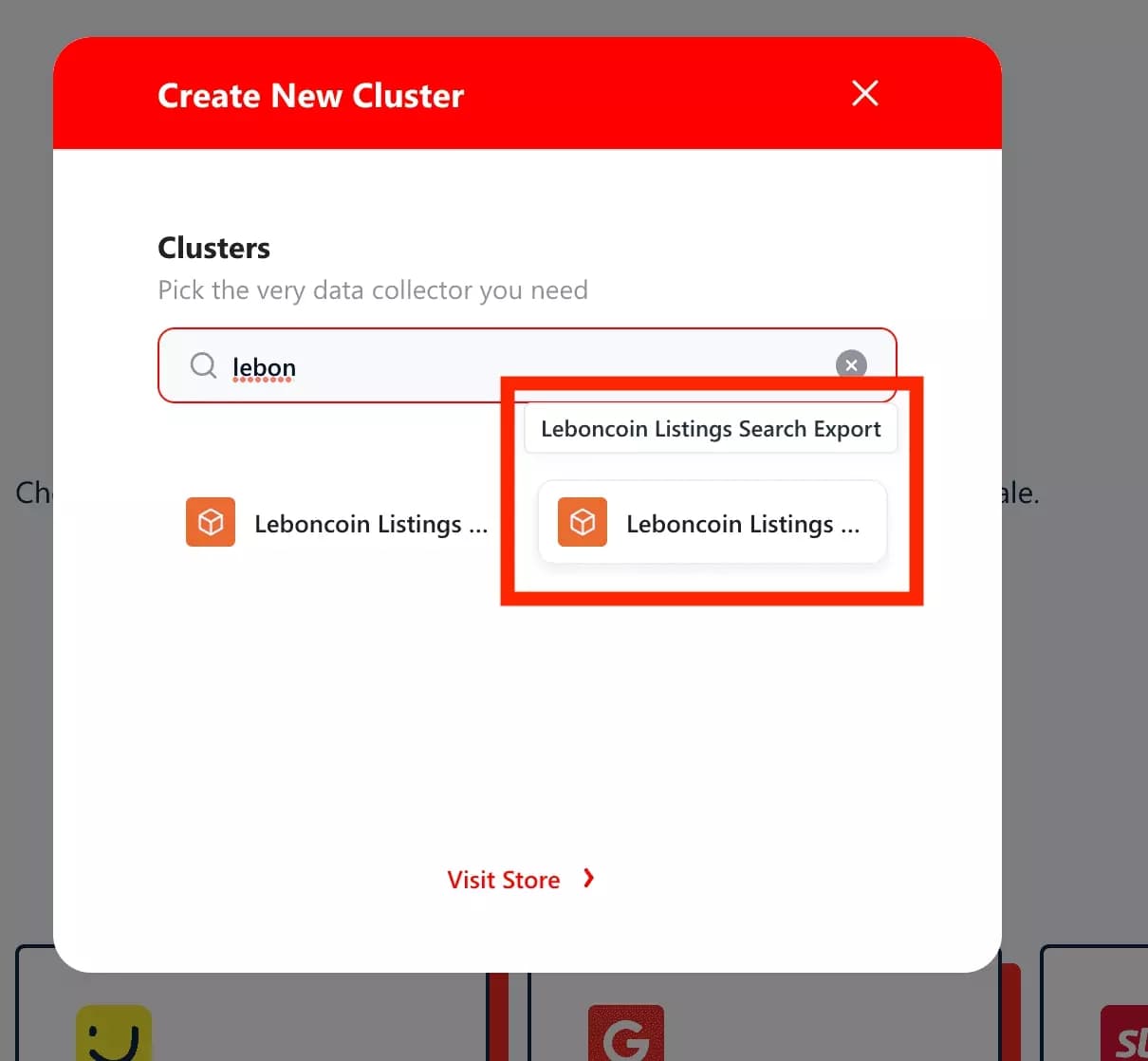
Be careful, you have to choose 'Leboncoin Listings Search Export' - and not its alter-ego with phone! The other crawler allows you to obtain the precious phone numbers present in the ads. But you absolutely have to provide a leboncoin account. And it's only usable if you've signed up for a paid plan.
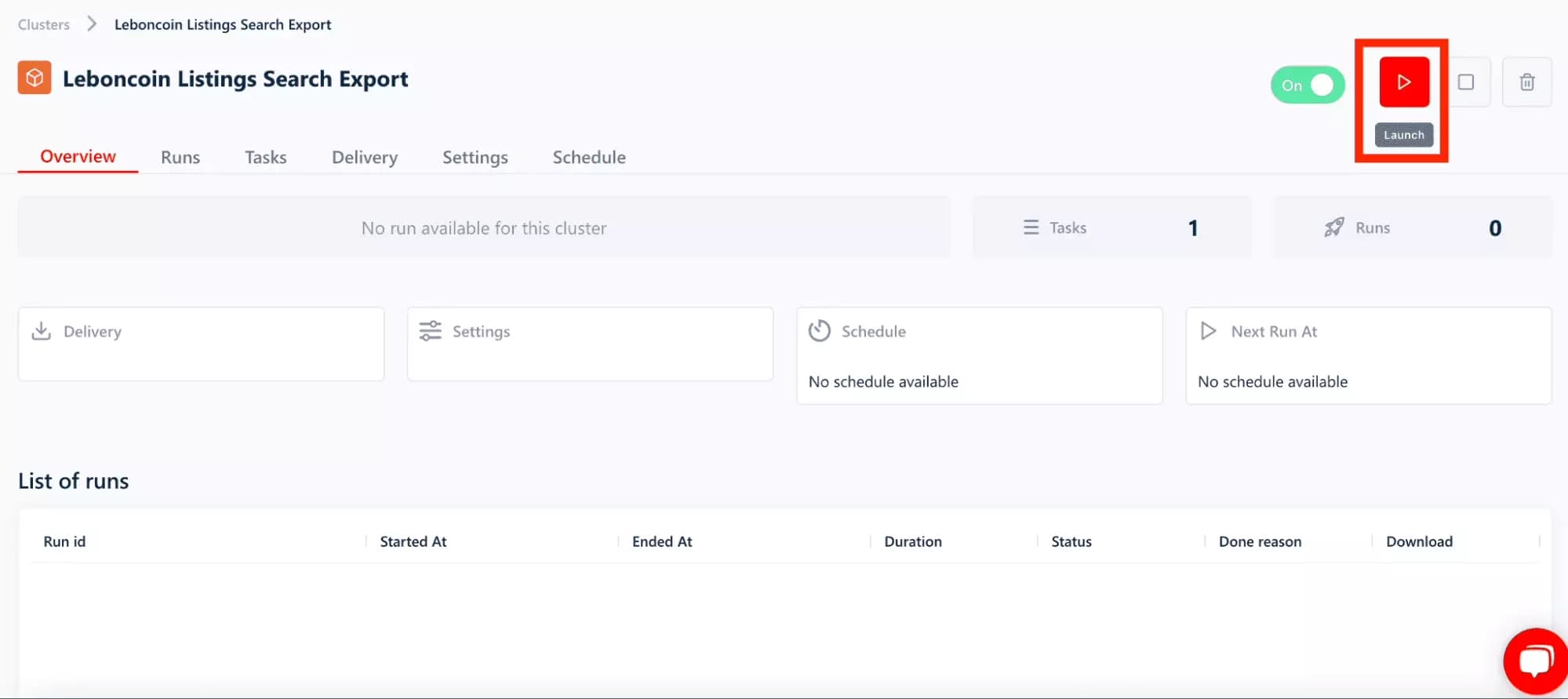
Launch
Let's launch!
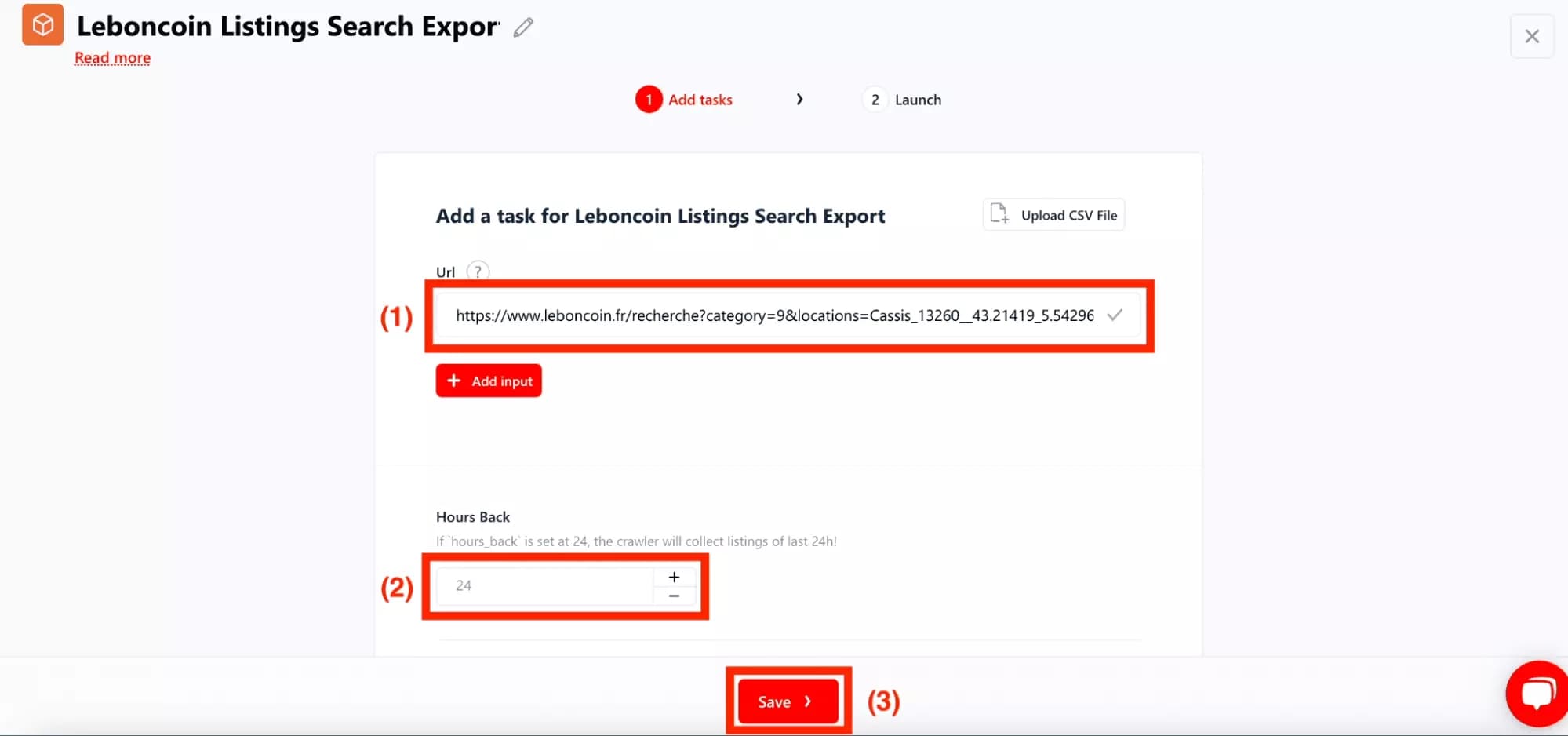
First, place the previously saved URL in the URL field (1).
Also, we don't want to collect ads that are more than 24 hours old. An old ad is an ad that is already losing its value. In the field 'Hours Back', we will thus inform 24 (2).
Finally, click on the nice button Save (3):
On the next frame, click on 'Manually' (4) - we will launch the crawler only once, a click by hand will be enough.
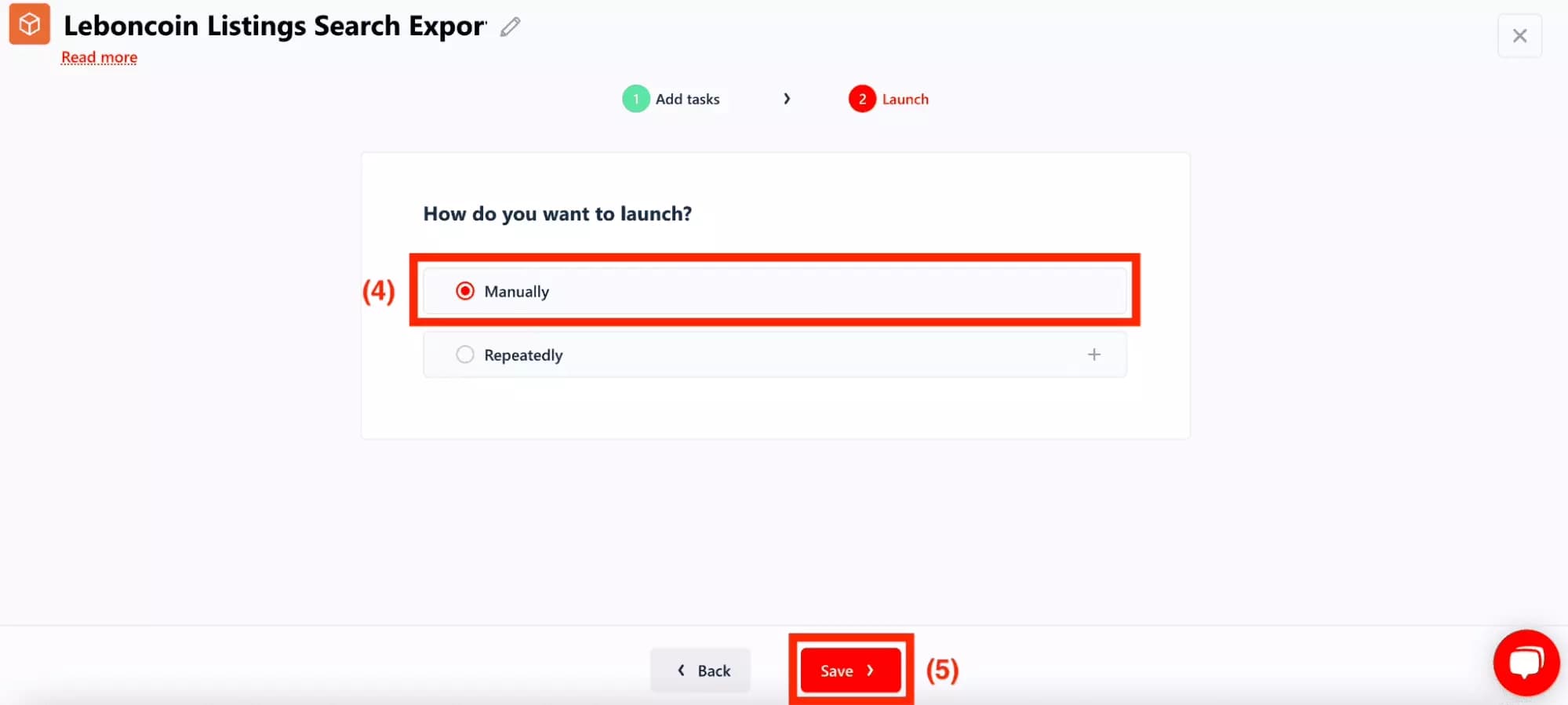
If you want to launch the crawler for example every morning at 8am, you can click on 'Repeatedly'. No need to get up early in the morning and launch your run by hand, we take care of everything!
And that's it, your cluster is created!
And here it is, the machine is launched!
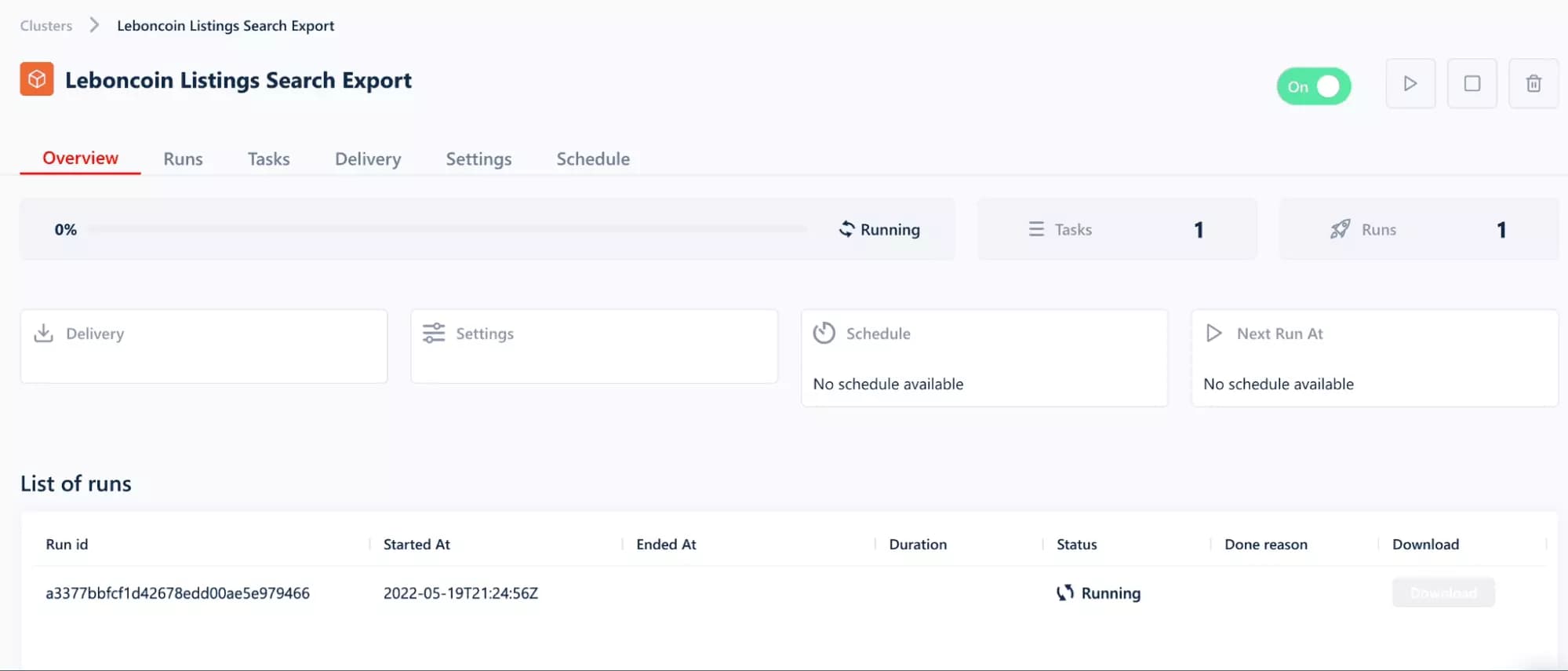
5 steps, 30 seconds of deployment. No more, no less.
Enjoy
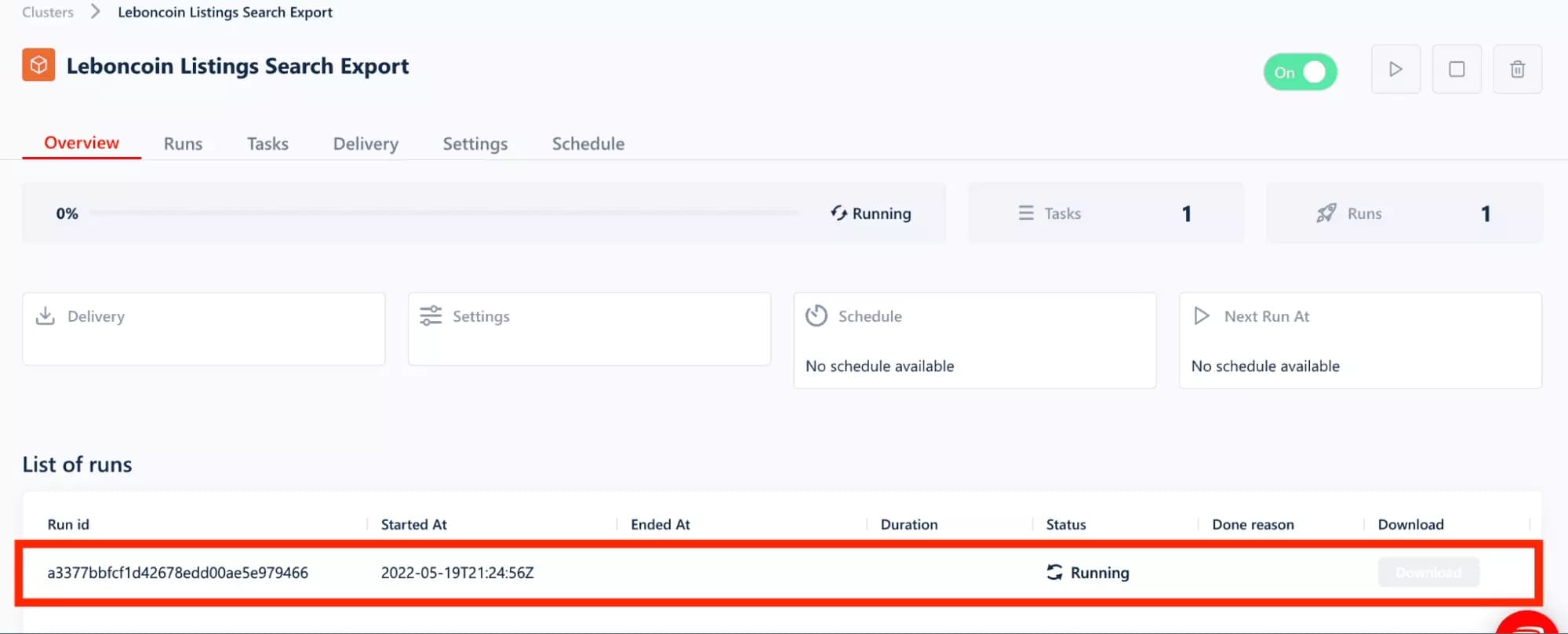
You are now on the 'Run' page, where the results will be displayed in real time. And after a few minutes of waiting... what a pleasure!
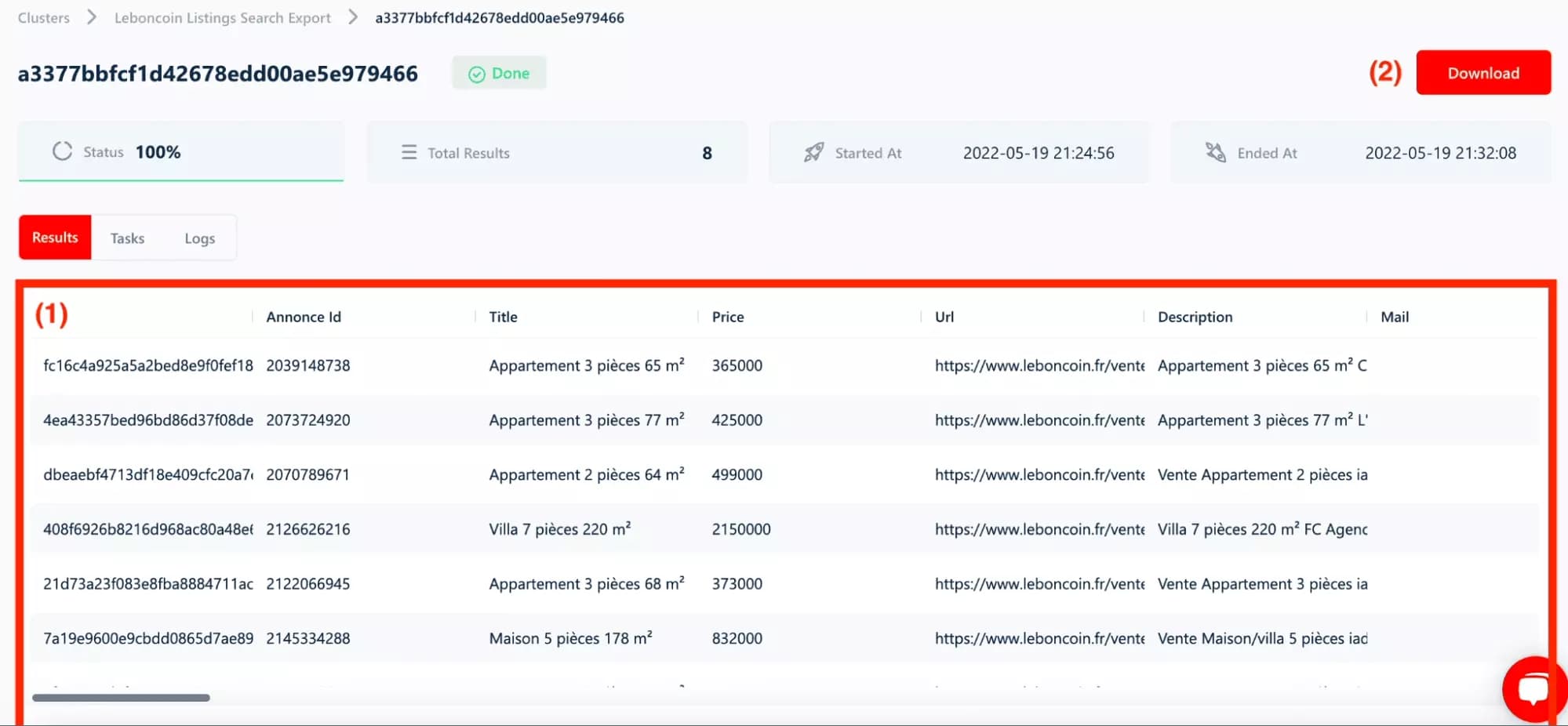
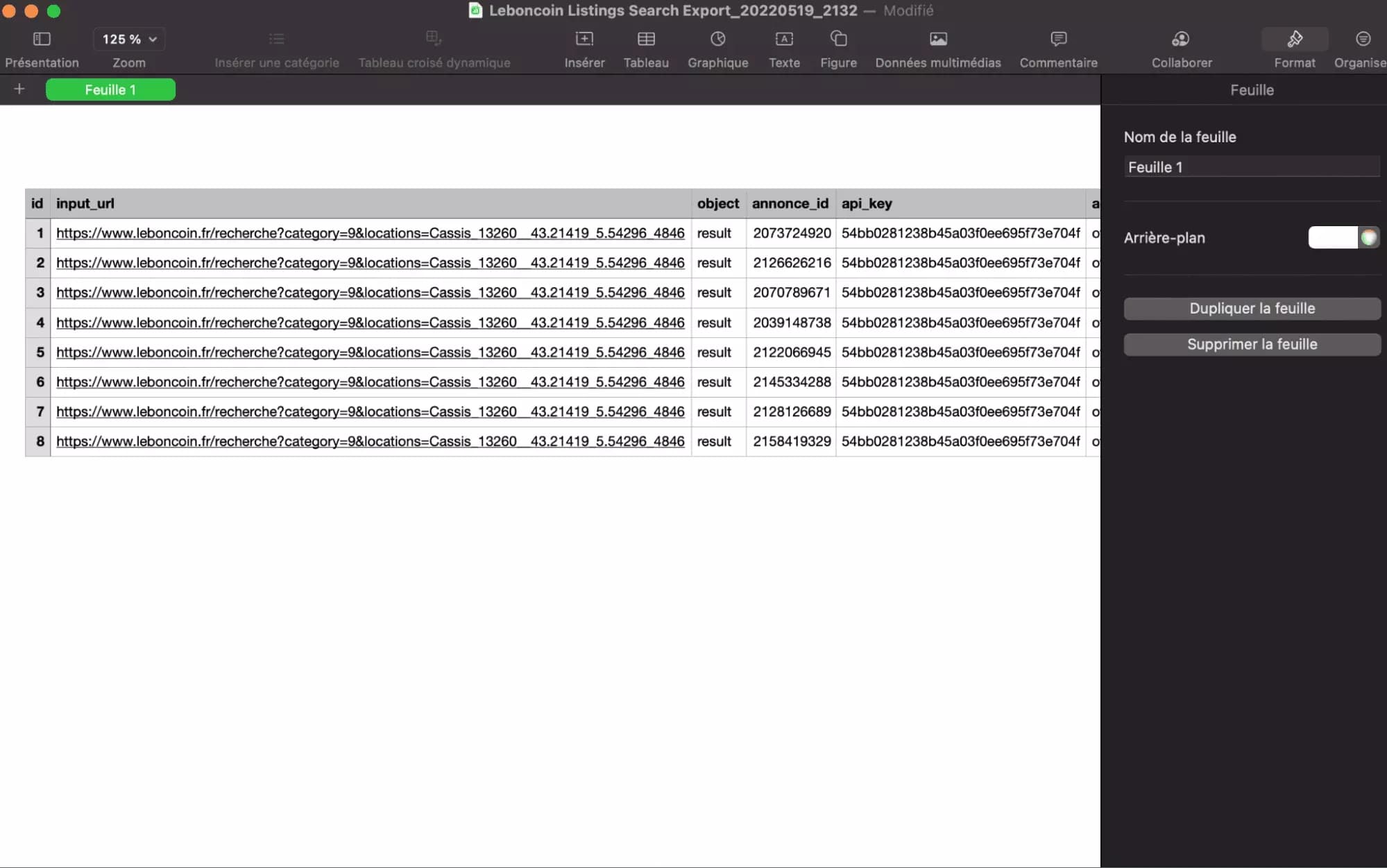
Conclusion
However, the 'bot-mitigation' tools make any automatic collection impossible, and force users to manually collect data.
With lobstr, collect data in 5 clicks, on the target of your choice. No code required. Completely free.
Happy scraping!
🦞