How to Scrape Facebook Pages in 2024 [No-Code]
Got hundreds of Facebook pages to analyze and store their insights in Google Sheets, but short on time? 😟
Manually gathering data from that many pages is incredibly time-consuming and prone to errors. Wouldn't it be great if you could automate this process?
In this article, we’ll learn how to scrape Facebook pages without coding and store the data in Google Sheets automatically.
But why’d I want to scrape Facebook pages? Let’s explore some use cases.
Why scrape Facebook pages?
Facebook is still the number 1 social media platform in the world. With over 200 million businesses actively using Facebook, there are plenty of use cases of this data, including:
- Competitor Analysis
- Lead Generation
- Market Research
- Influencer Marketing
- Directory Creation
- And many more
But is it legal? 🤔 Well, let’s find out.
Is it legal to scrape Facebook pages?
To answer this question, I’m going to break it down further into 2 parts:
- Does Facebook allow scraping?
- Is it legal to scrape Facebook public pages data?
The answer to the first question is straight NO. Facebook doesn’t allow you to scrape any of its data. How does Facebook prevent web scraping?
According to Facebook’s help center, they have an external data misuse (EDM) team to deal with scrapers. The EDM handles technical mitigation and scraping enforcement.
Sounds scary, right? After reading words like ‘taking actions’, ‘enforcements’, ‘investigations’, you might think scraping Public data from Facebook is illegal.
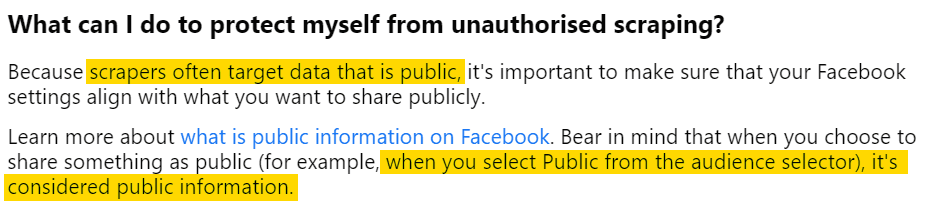
So is it illegal to scrape Facebook pages? Facebook has answered this as well. If we scroll down a little, you’ll see this:
Which means, Facebook does understand that extraction of publicly available information is completely legal. In another help article, they clarify that Facebook pages are public spaces.
As per the ruling by the U.S. Ninth Circuit of Appeals, scraping data that is publicly accessible on the internet is legal, unless you comply with data privacy laws like GDPR and CFAA.
But why not use the official Facebook API?
Does Facebook have a public API?
Yes, Facebook does have an API for accessing Public pages data. It’s called the Graph API. The primary function of this API is to read and write to the Facebook social graph.
You can retrieve core metadata about public pages using Graph API’s Page Public Metadata Access feature. So why aren’t we using it?
- Requires Meta app review
- It has limitations
- Too complicated to set up
To access the page public metadata feature, you’ll need to submit a request to Meta. You’ll need to provide a solid usage description and wait for Meta’s approval, which can take ages.
If you manage to get an API key, there are certain limitations. You can only access limited data points depending on authorization from Meta. Typically, you can access:
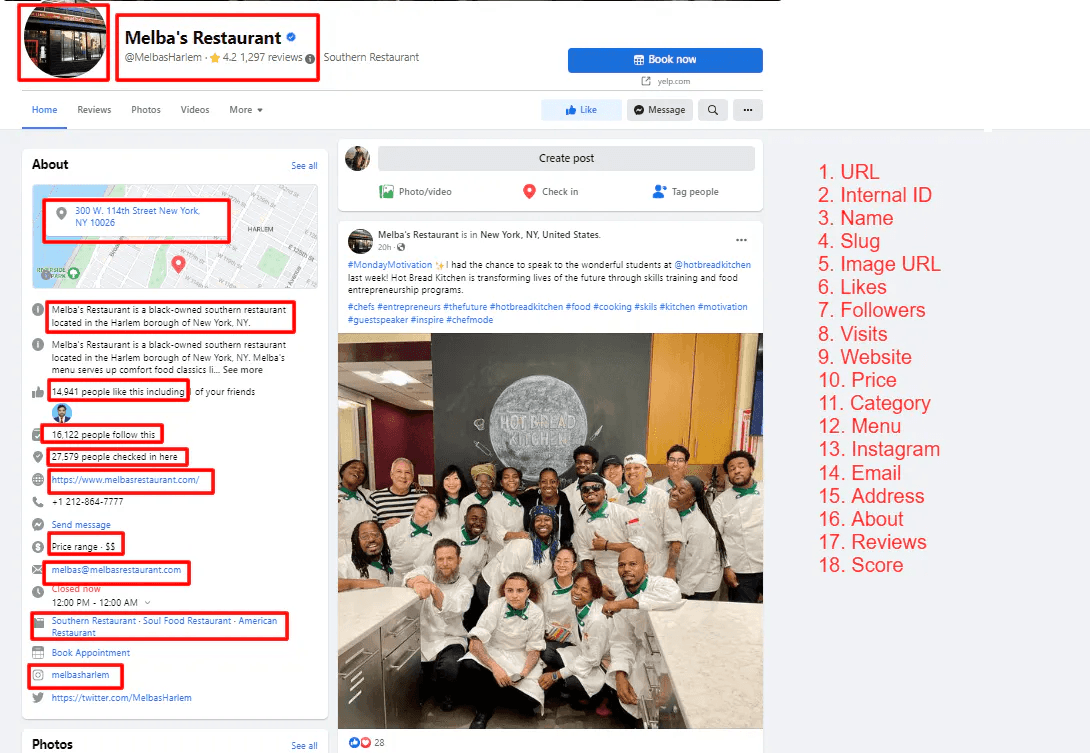
- Page Name
- Page ID
- Category
- Description
- Location
- Profile Picture (if access granted)
- Likes count (if access granted)
Also, this data might be partial. Not all fields might be available for every result. Plus another limitation is the request rate limit.
The worst part is that rate limits are tracked on app or user level. Which means there’s no certain cap.
At this point, most of you guys will agree with me that Facebook API is bad. But for my optimistic buddies, I also did some research about the ease of use of Facebook APIs.
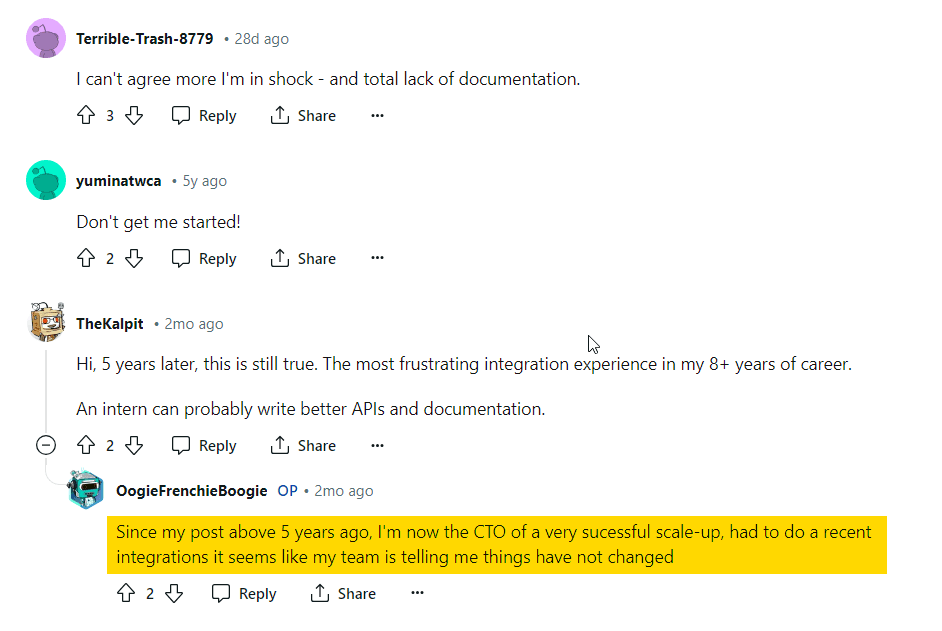
The most interesting comment I found was related to documentation of the API. I agree with Mr. u/OogieFrenchieBoogie:
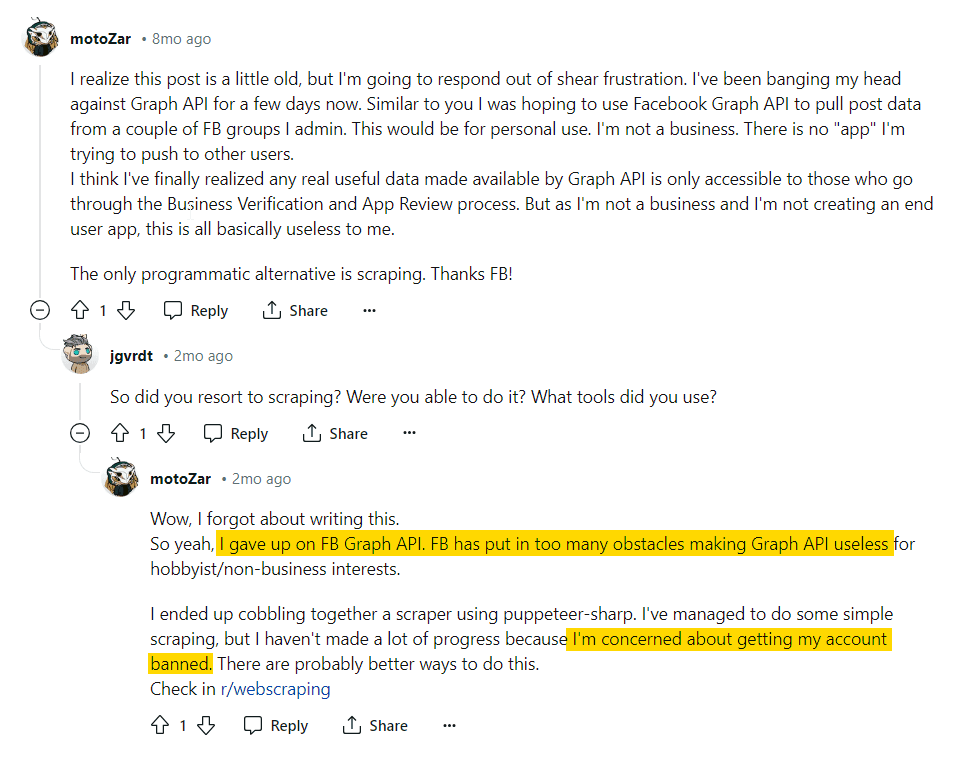
Even nerds 🤓 believe coding a web scraper is much easier than interacting with Facebook Graph API. Like Mr. u/motoZar says:
But Mr. motoZar also highlighted a problem in coding a scraper. You can get your account banned. Plus coding a scraper is not everyone’s forte.
So how to scrape Facebook pages without getting banned and without writing code? The answer is – no code scrapers like Lobstr.io 🦞
How to scrape Facebook pages without coding
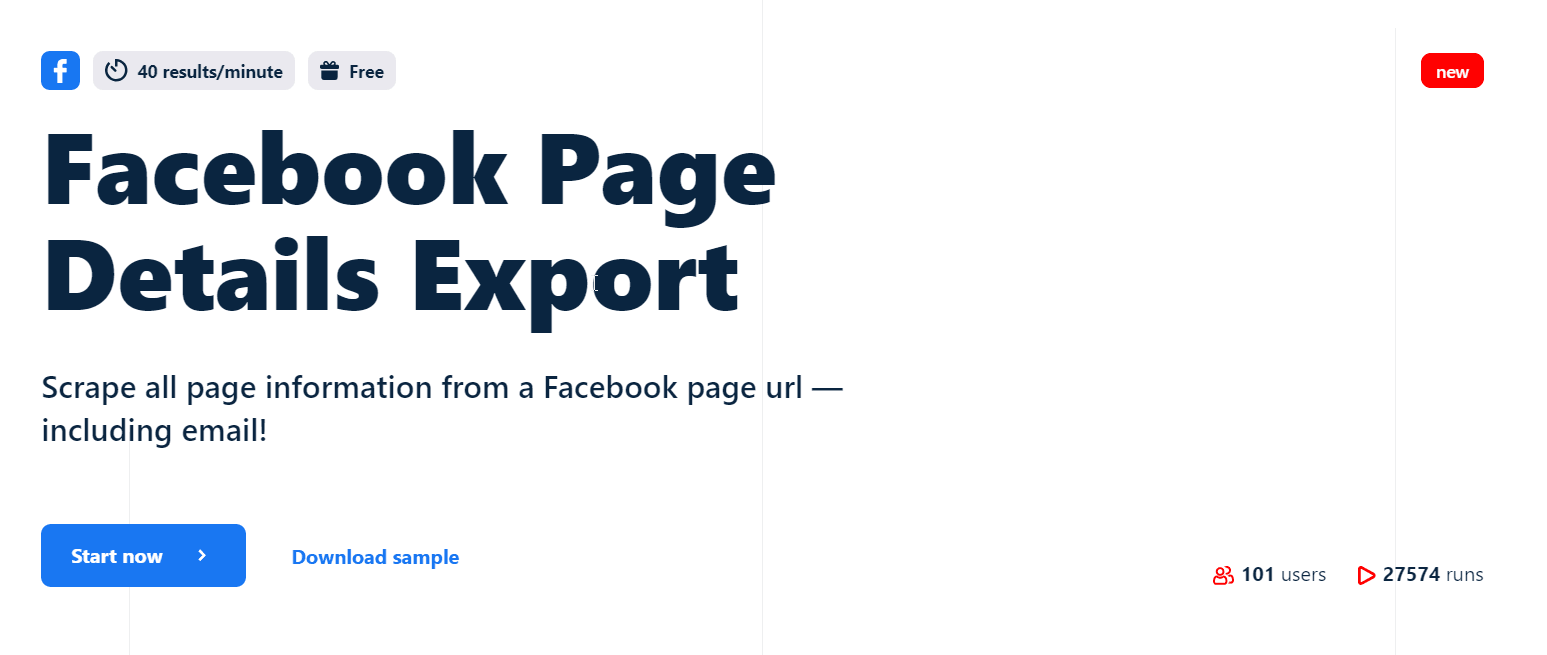
For this tutorial, I’ll be using Lobstr’s Facebook Page Details Export automation, which is undoubtedly the best no-code Facebook page scraper in the market.
Cool features of Lobstr.io Facebook page scraper
- 18 key data points including emails
- Scrapes 40+ results per minute
- No Facebook login required
- Cloud-based, scrape from anywhere anytime
- Schedule feature and real time notifications
- Developer-friendly API access
- Export to Google Sheets and Amazon S3
Pricing
- Free plan: 18k results per month
- Premium plan: €0.23 per 1k results
- Business plan: €0.14 per 1k results
- Enterprise plan: €0.11 per 1k results
Scraping Facebook pages with Lobstr - Step by step guide
Using Lobstr.io is super easy. It literally takes less than 2 minutes to set up and launch a scraper. We’ll scrape Facebook pages data with Lobstr in 6 simple steps.
- Get page URLs
- Create Squid
- Add tasks
- Adjust behavior
- Launch
- Enjoy
Let’s go! 🏃
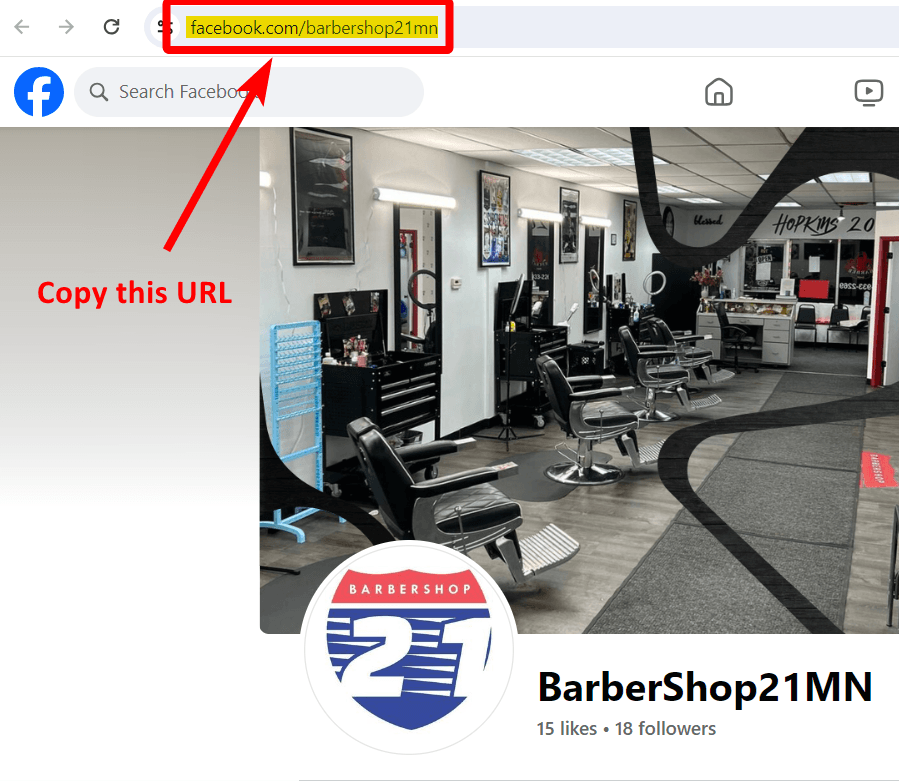
Step 1 - Get page URLs
First thing first, let’s get Facebook page URLs that we need to scrape. Go to the Facebook page you want to scrape, and copy its URL.
I already have a list of 50 page URLs. Let’s go to the next step.
Don’t want to go through this manual labor? You can use our new crawler: Facebook Pages Search Export.
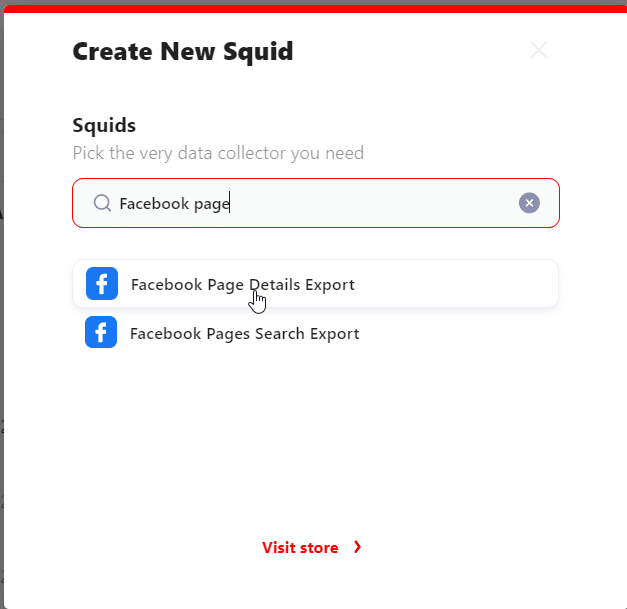
Step 2: Create Squid
Next, go to your Lobstr.io dashboard. Don’t have an account yet? Create one – it’s free! Once you’re in, click the New Squid button.
Now enter ‘facebook page’ in the search box and select ‘Facebook Page Details Export’ from the results.
You’re now ready to configure the crawler. Let’s do it.
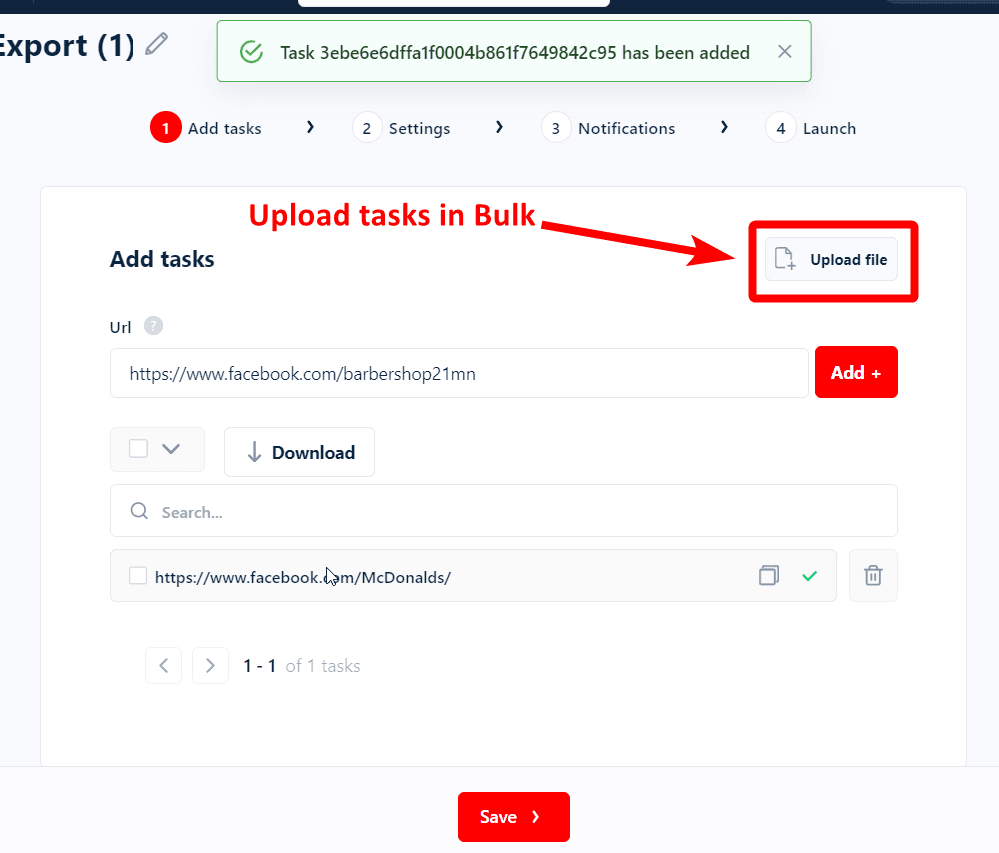
Step 3: Add tasks
The first option you see is Add tasks. Paste your page URLs here one by one.
You don’t necessarily need to add each URL manually. I have got 50 URLs and adding them manually will take time. Let’s upload the whole list at once.
Click Save once you’re done and now we’ll adjust crawler’s performance.
Step 4: Adjust behavior
Next is settings. In basic settings, you get to choose when to end the run. This option is useful if you’ve got thousands of tasks or need fresh data every time the crawler runs.
You can check this help page to learn more about this feature. For this job, we need the crawler to end run when all the tasks are completed.
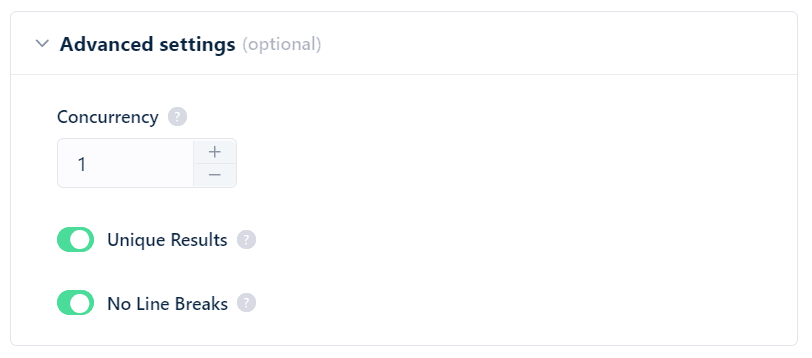
Then in advanced settings, we’ve concurrency. In simple words, concurrency means number of bots deployed per run. How concurrency affects our scraping? The formula is simple:
more concurrency = faster scraping and efficient performance
You can also filter the duplicate results and make the text outputs easy to read in Excel sheets by toggling Unique Results and No Line Breaks options.
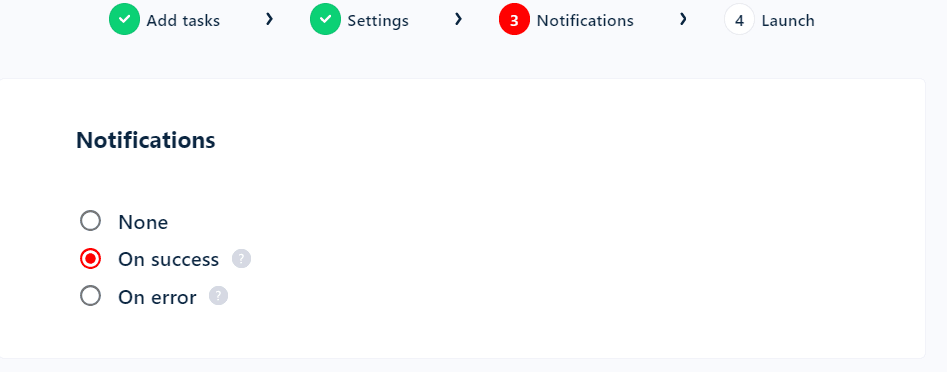
Next option is notifications. You can receive real-time email notifications when a job completes successfully or pauses due to any error.
Done with settings, and we’re all set to launch our Facebook page scraper.
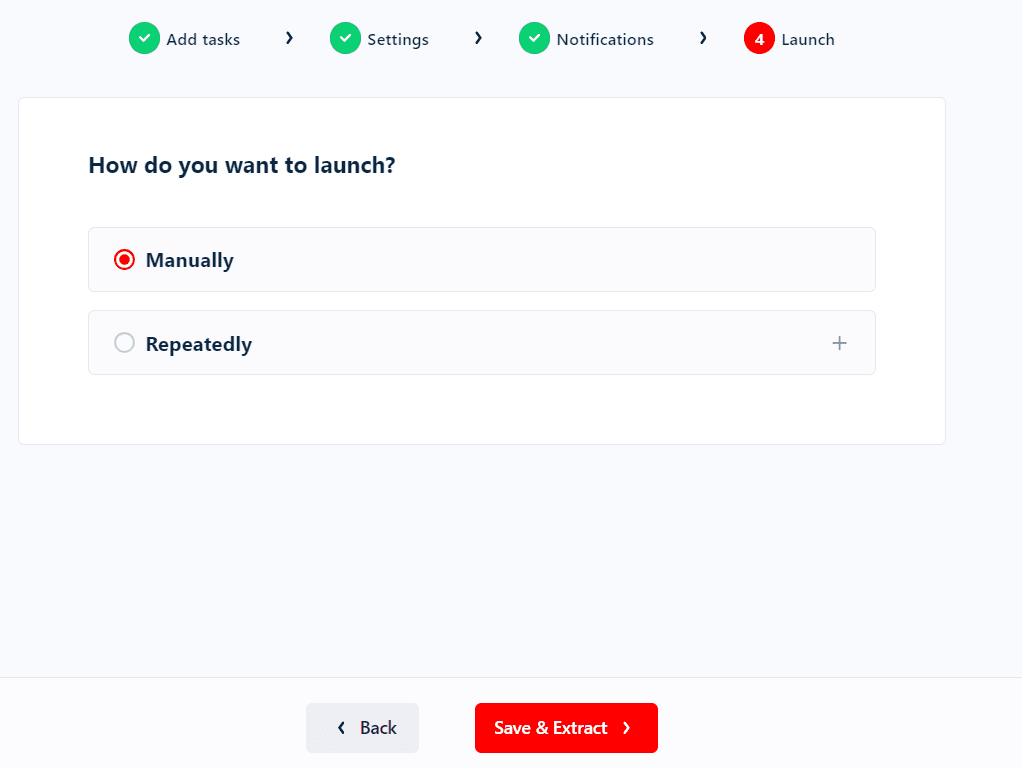
Step 5: Launch
Now we’re ready to launch. You can launch the crawler manually and it’ll instantly start collecting data for you.
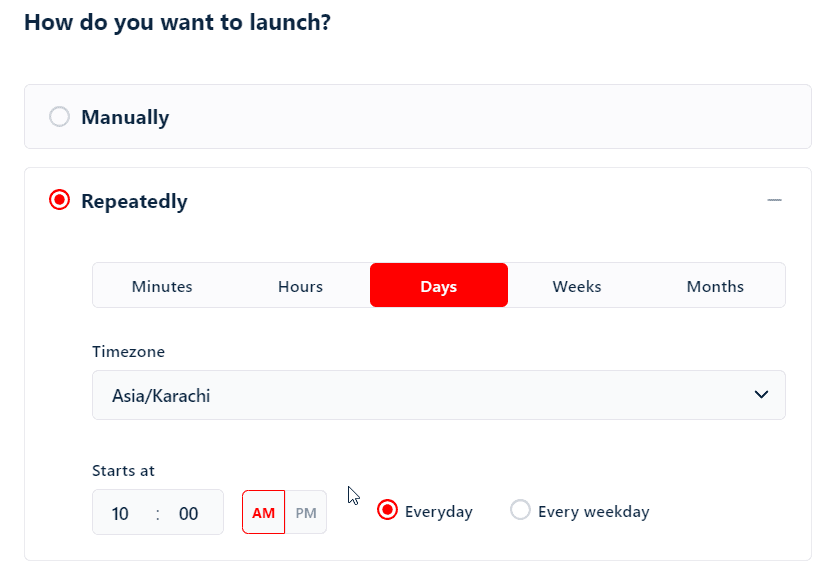
But what if I want to collect data every Friday night? I don’t want to open my dashboard and launch the scraper manually every time.
That’s where the schedule feature comes handy. Choose Repeatedly in the launch menu and choose your desired schedule and the scraper will launch automatically on the set time and day.
Choose your preferred launch setting and click Save. Tada! The crawler is now running.
Step 6: Enjoy
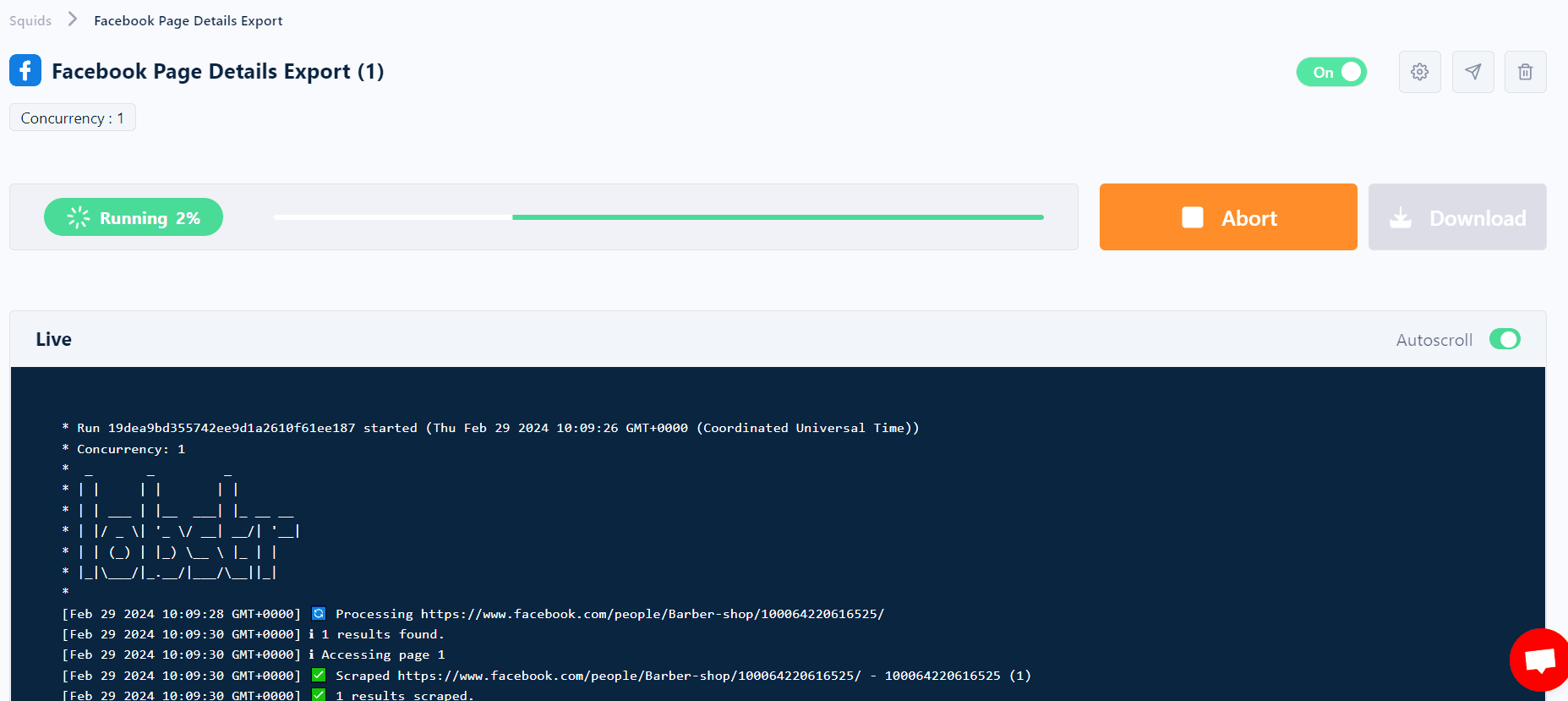
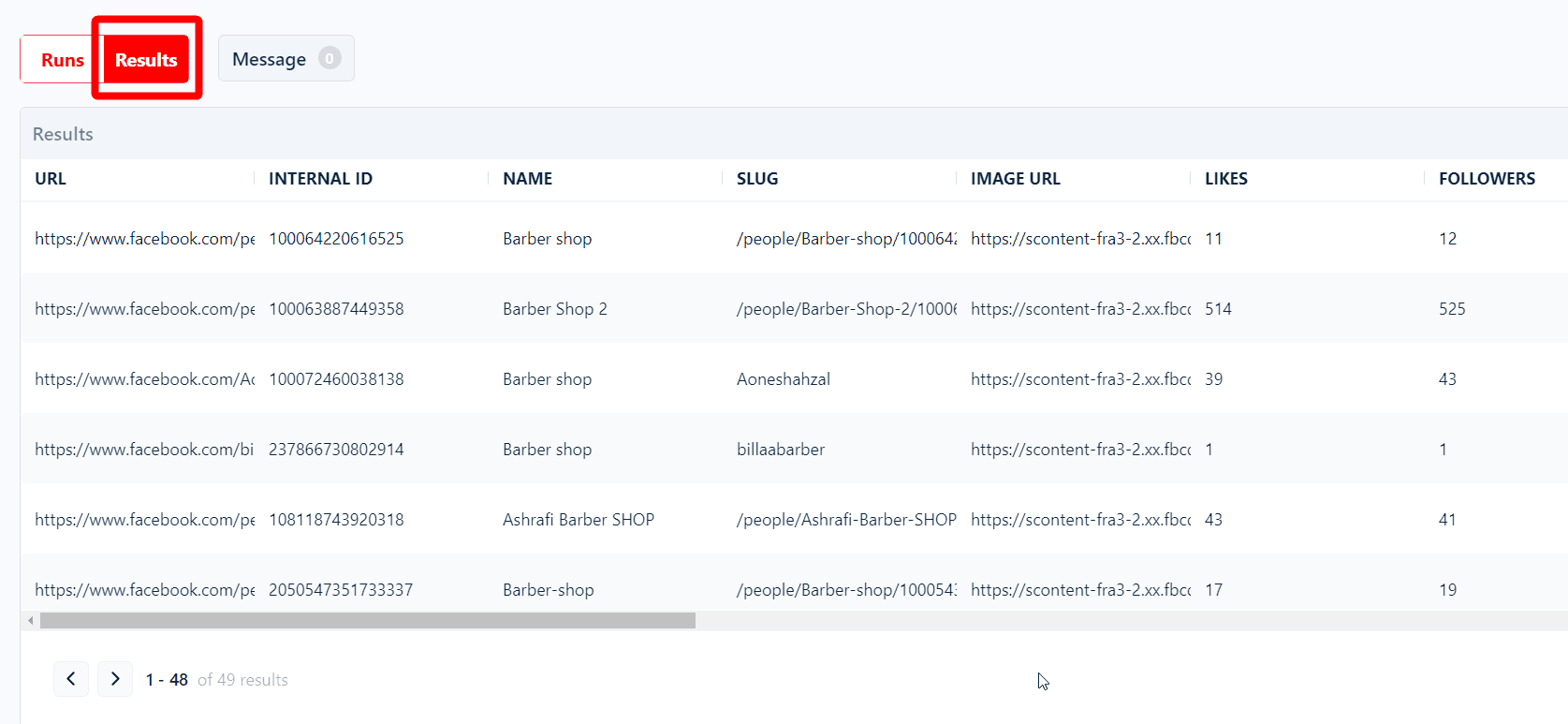
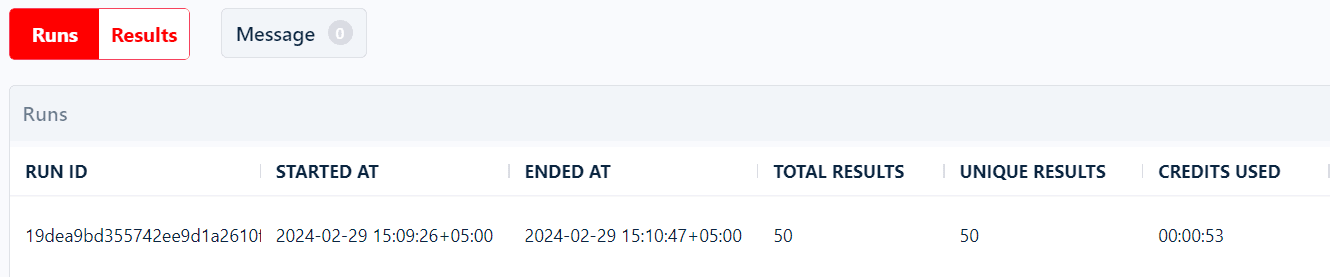
Once the Facebook page scraper starts fetching data, you can check it in real-time in the results tab below the console.
With that, we’re done scraping all 50 pages. We just extracted 18 data attributes from 50 pages in less than a minute, which is faster than the claimed speed i.e. 40 results per minute. 😎
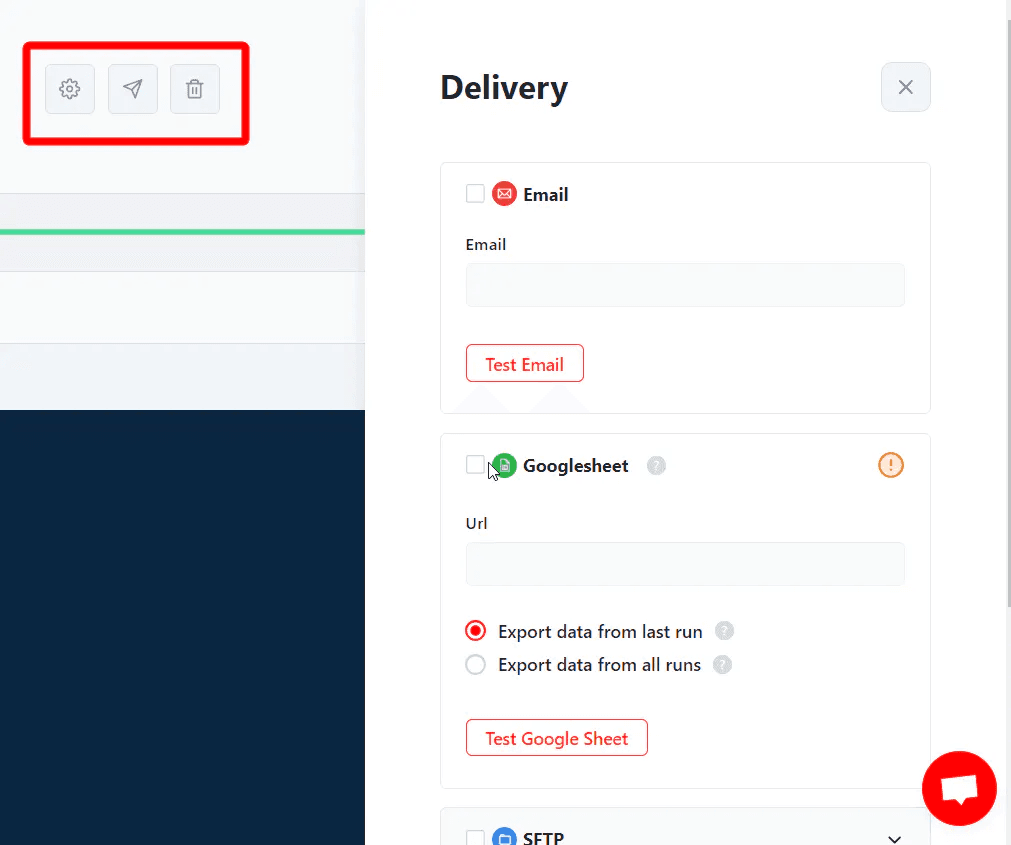
Once the job is finished, you can download the results as a csv file using the download button. But I don’t want this manual labor. I need my results directly in my Google Sheet.
With Lobstr, you can do that too. Click the delivery icon on the top right corner of your console, and configure a delivery method.
You can export data directly to Google Sheets, Amazon S3, Webhook, and SFTP.
FAQs
Can this Facebook scraper extract phone numbers, ads, and posts?
No, this scraper can not extract phone numbers, Facebook ads, or post text. It only extracts data like name, likes count, and contact information.
To scrape phone numbers, you can use Facebook Pages Search Export.
Can I scrape Facebook profiles and Facebook groups too?
No, you can’t scrape profiles, groups, or Facebook posts. This scraper is specifically designed to scrape Facebook pages only.
How can I scrape Facebook data using Python?
You can use Facebook’s Graph API for safer data collection or build your own custom Facebook scraper using libraries like lxml or selenium, which is risky.
Do I need to download and install this web scraping tool?
Lobstr.io is cloud-based. You can launch our data scrapers in any web browser like Chrome or Firefox. No download or install required.
Can I download extracted data as JSON?
You can convert the CSV file JSON using this tool. Downloading output as JSON is not supported yet.
Do I have to pay for residential proxies for data scraping?
Lobstr’s pricing plans are completely transparent. Except the subscription fee, there are no extra charges for anything.
Conclusion
In conclusion, scraping Facebook pages doesn't have to be complicated. Try Facebook Page Details Export for a simple, free, and no-code solution.
Want even more options? Check out the other scrapers available on the Lobstr.io Store.