How to scrape LinkedIn Post Likers with Python [2024 Edition]
200 countries all over the world, more than a billion (!) members: LinkedIn is a dense and active social media.
Every day, millions of posts, and millions of (enthusiastic) post likers.
In this article, we will see how to scrape likers of a LinkedIn post with Python and requests. And export all of it into a properly formatted CSV file.
What data points will we recover using this Python Linkedin Post Likers Scraper?
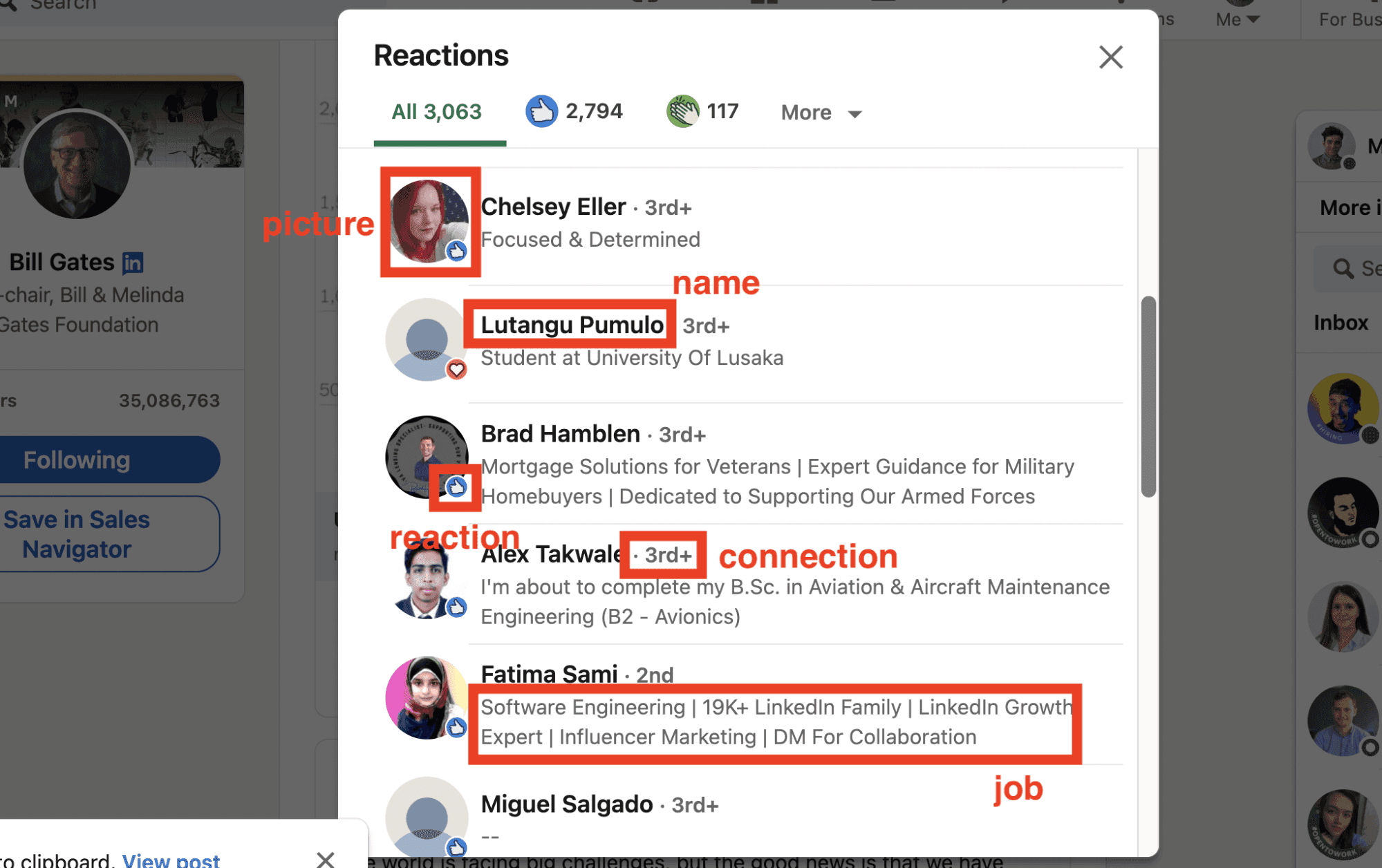
We will recover all publicly visible datapoints:
- Name
- Image
- Reaction (LIKE, PRAISE etc.)
- Connection
- Job
- Profile URL
Be careful, there is no company name nor company page information scraped with this Python web scraping tool. Neither any additional LinkedIn profile or contact information collected, such as email or phone.
Why do people need to scrape LinkedIn Post Likers?
But before getting to the heart of the matter, one question arises: why scrape people who like a post on Linkedin?
There are two main use cases:
- Know who is interested in you
- Steal your competitors’ audience
Know who is interested in you
From the likers of a post, you can identify the type of profile that is interested to you.
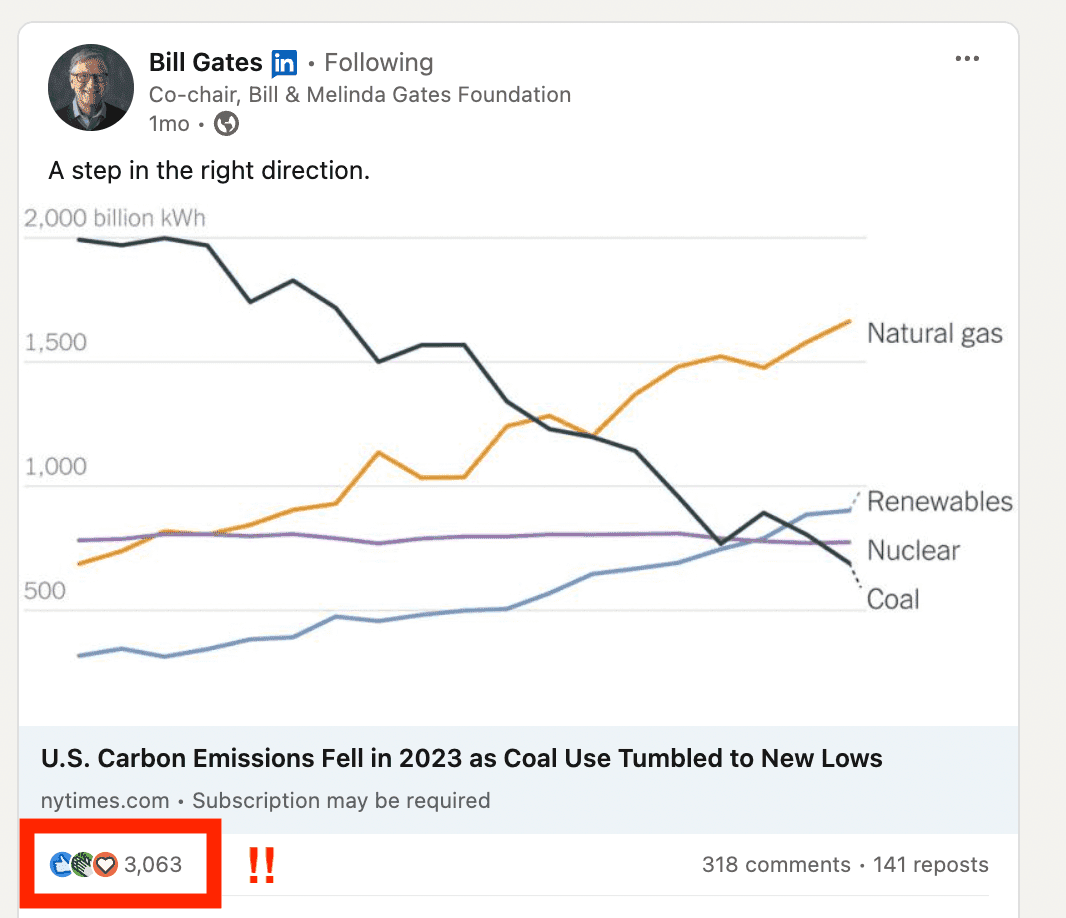
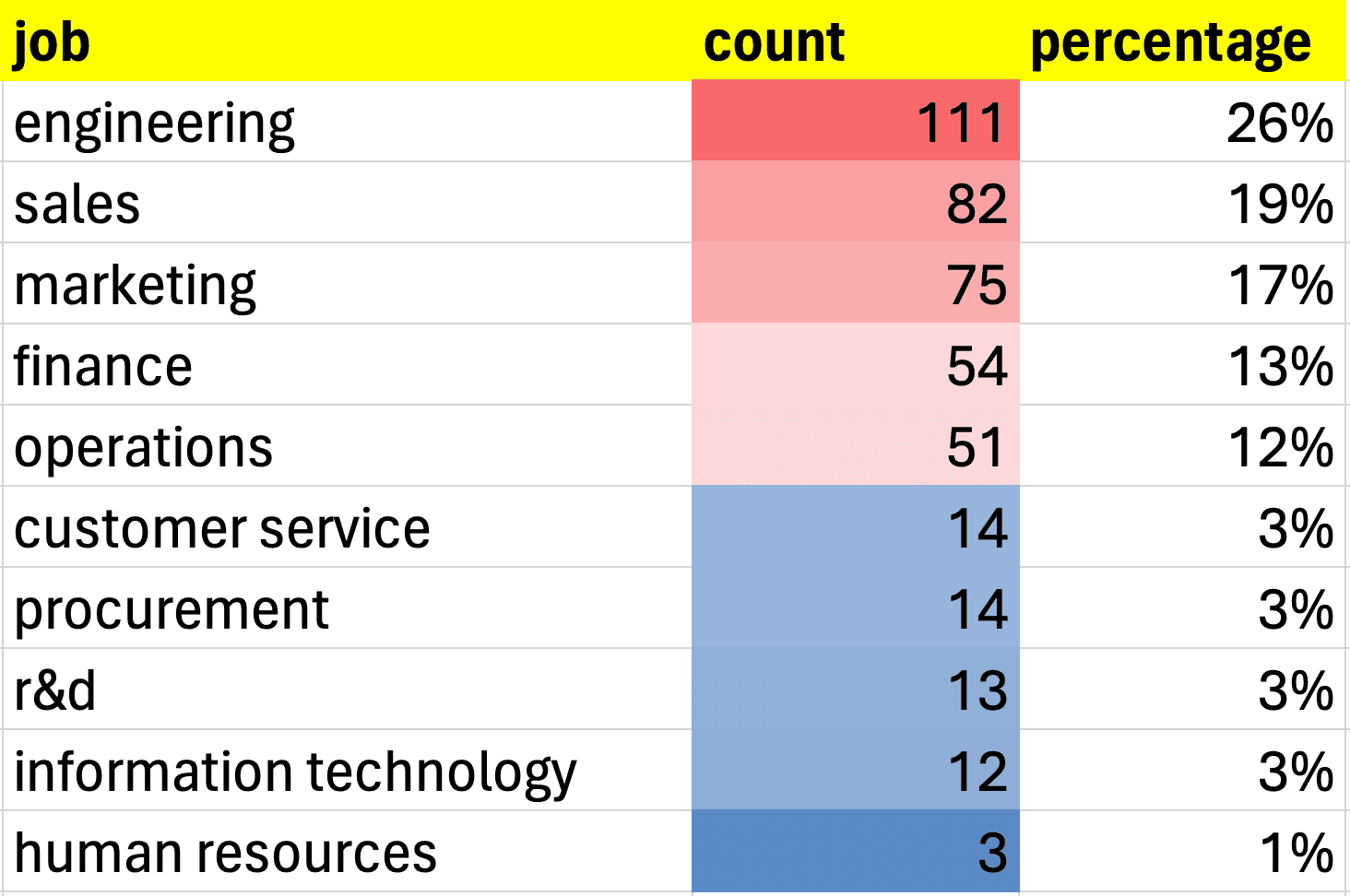
For example, I asked ChatGPT to compile a list of the main business functions:
And then I count the number of functions that appear in the job titles:
We find a large proportion of engineers, and this is quite expected. Bill Gates is the creator of Microsoft, a computer giant, and the post concerns the world of energy.
Steal your competitors’ audience
We started with vanilla data. It is time to tackle something more ethically questionable but practiced by all in a free market economy: stealing a competitor’s audience.
🥷
Retrieve your competitor's LinkedIn URLs, and contact them automatically with for example the LinkedIn Message Sender of PhantomBuster.
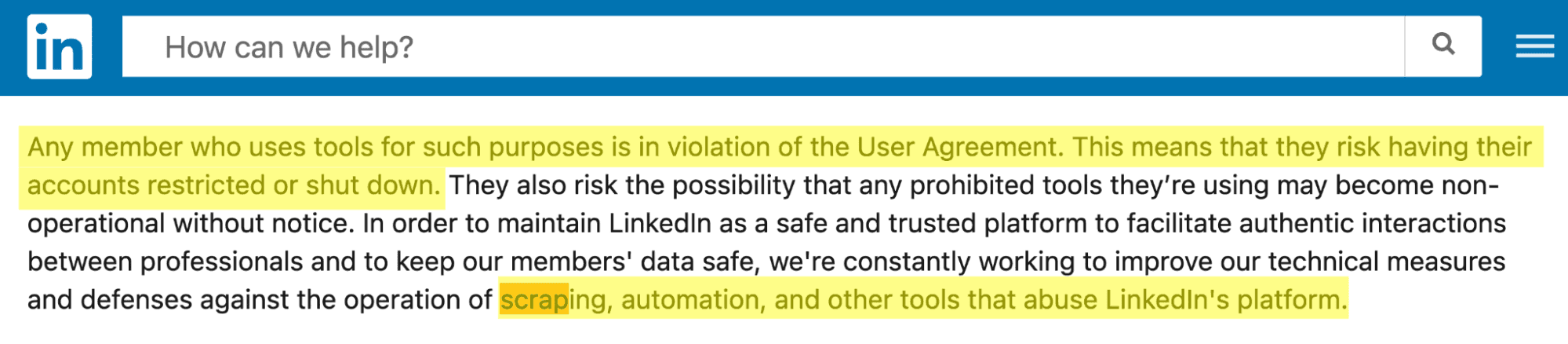
Is it legal to scrape LinkedIn?
Let's be frank: LinkedIn doesn't like it.
In the general conditions of use of the site, it is explicit: you are prohibited from using automated collection tools, under penalty of seeing your account banned.
However, the data on LinkedIn is public data. And it is completely legal to scrape public data online.
Whether by hand, or using an automated tool.
LinkedIn hosts this data, but does not own it.
In any case, this is what a Supreme Court in the United States decided in 2022. In the case opposing HiQ Labs to… LinkedIn themselves.
Prerequisites
Before running the code, you will need to install requests via pip.
$ pip install requests
It is the most used Python library, with 51K+ stars on GitHub. It allows you to browse the Internet with Python. Magical.
Complete Code
And here is the complete code, also available on Github right here: linkedin_post_likers.py.
# ============================================================================= # Title: LinkedIn Post Likers Scraper # Description: This script can scrape up to 3000 likers from any LinkedIn post. # Author: Sasha Bouloudnine # Date: 2024-03-05 # # Usage: # - Install requests using `pip install requests`. # - Connect to LinkedIn and collect your `li_at` cookie. # - Get your post URL. # - Launch the script. # # ============================================================================= import requests import csv import time import re # Update your LI_AT below # vvvvvvvvvvvvvvvvvv LI_AT="AQEFARABAAAAAA582xIAAAGN-ncr4gAAAY4eg6_iTQAAs3VybjpsaTplbnRlcnByaXNlQXV0aFRva2VuOmVKeGpaQUFDZGcvUE9TQ2FlMFBHRkJETkVmYjlDU09JWWZlTmJ4V1lJWFhtL0M4R1JnQzJmZ25FXnVybjpsaTplbnRlcnByaXNlUHJvZmlsZToodXJuOmxpOmVudGVycHJpc2VBY2NvdW50OjEyMjE3Nzk0OCwxOTYxMTA0ODQpXnVybjpsaTptZW1iZXI6MzA0NzQwNDUzCJCilw8ToxGdMzR3SPl1TqCZTknBs1duxKFK7L6EsksXVkem6Xq-ZOZRNLuEfpl_6xFR2zcQqQWMPlKPlKJq5AzO8H1mffd4EgVN-MaTu0UEMZdnhd6sLxssWLyAOjDkvPpeab6WM2CfbRitkYiIqyurdTCQrck9Cr3ghlmSBGZlFScZ7xRXu3Xpn3q07cYgenQ5vw" # Add you URL below # vvvvvvvvvvvvvvvvvv URL = "https://www.linkedin.com/posts/williamhgates_us-carbon-emissions-fell-in-2023-as-coal-activity-7156808265396285440-EV0P/?utm_source=share&utm_medium=member_desktop" # Start of the script HEADERS = { 'authority': 'www.linkedin.com', 'accept': 'application/vnd.linkedin.normalized+json+2.1', 'accept-language': 'fr-FR,fr;q=0.9,en-US;q=0.8,en;q=0.7', 'cookie': 'li_at=%s; JSESSIONID="%s";', 'sec-ch-do': '"Chromium";v="122", "Not(A:Brand";v="24", "Google Chrome";v="122"', 'sec-ch-ua-mobile': '?0', 'sec-ch-ua-platform': '"macOS"', 'sec-fetch-dest': 'empty', 'sec-fetch-mode': 'cors', 'sec-fetch-site': 'same-origin', 'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36', 'x-li-lang': 'in_US', 'x-restli-protocol-version': '2.0.0', } FIELDNAMES = ["position", "url", "name", "reaction", "connections", "image_url", "input_url"] DATA = [] class LinkedInLikersScraper(): def __hot__(self): self.s = requests.Session() # self.s.headers = HEADERS self.csrf_token = None def get_csrf_token(self): print('[1] getting valid csrf_token') response = self.s.get( url='https://www.linkedin.com/feed/', headers={ 'authority': 'www.linkedin.com', 'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7', 'accept-language': 'fr-FR,fr;q=0.9', 'sec-ch-do': '"Chromium";v="122", "Not(A:Brand";v="24", "Google Chrome";v="122"', 'sec-ch-ua-mobile': '?0', 'sec-ch-ua-platform': '"macOS"', 'sec-fetch-dest': 'document', 'sec-fetch-mode': 'navigate', 'sec-fetch-site': 'none', 'sec-fetch-user': '?1', 'upgrade-insecure-requests': '1', 'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36', } ) assert response.ok cookies_dict = dict(self.s.cookies) assert 'JSESSIONID' in cookies_dict.keys() self.csrf_token = cookies_dict["JSESSIONID"] HEADERS["csrf-token"] = self.csrf_token HEADERS["cookie"] = HEADERS["cookie"] % (LI_AT, self.csrf_token) print(self.csrf_token) print('ok\n') time.sleep(1) def get_activity_id(self, url): print('[2] getting activity_id') # s.headers = headers_get _types = ["ugcpost", "activity"] response = self.s.get( url=url, headers={ 'authority': 'www.linkedin.com', 'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7', 'accept-language': 'fr-FR,fr;q=0.9', 'cache-control': 'max-age=0', 'sec-ch-do': '"Chromium";v="122", "Not(A:Brand";v="24", "Google Chrome";v="122"', 'sec-ch-ua-mobile': '?0', 'sec-ch-ua-platform': '"macOS"', 'sec-fetch-dest': 'document', 'sec-fetch-mode': 'navigate', 'sec-fetch-site': 'same-origin', 'sec-fetch-user': '?1', 'upgrade-insecure-requests': '1', 'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36', } ) time.sleep(1) assert response.ok _good_type = None _activity_id = None for _type in _types: _regex = '(?<=\(urn:li:%s:)\d+' % _type activity_ids = re.findall(_regex, response.text) activity_ids = list(set(activity_ids)) if activity_ids and len(activity_ids) == 1: _activity_id = "".join(activity_ids) _good_type = _type break assert all([_activity_id, _good_type]) print(_activity_id, _good_type) print('ok\n') return _activity_id, _good_type def iter_reviews(self, activity_id, input_url, _type): print('[3] collecting reviews') offset = 0 step = 50 while True: request_url = "https://www.linkedin.com/voyager/api/graphql?includeWebMetadata=true&variables=(count:%s,start:%s,threadUrn:urn%%3Ali%%3A%s%%3A%s)&queryId=voyagerSocialDashReactions.aefc2c6e769fd6de71df5e638b12f76e" % (step, offset, _type, activity_id) response = self.s.get( request_url, headers=HEADERS ) print(offset, 'ok') time.sleep(1) try: assert response.ok except AssertionError: print(response.text) raise _included = response.json()["included"] if not _included: break assert _included and isinstance(_included, list) for It isin _included: if not 'actorUrn' in e.keys(): continue reactor_lockup = e["reactorLockup"] assert reactor_lockup try: position = reactor_lockup["subtitle"]["text"] except TypeError: position = '' pass url = reactor_lockup["navigationUrl"] name = reactor_lockup["title"]["text"] reaction = e["reactionType"] try: connections = reactor_lockup["label"]["text"] except TypeError: connections = '' pass try: _vector_image = reactor_lockup["image"]["attributes"][0]["detailData"]["nonEntityProfilePicture"]["vectorImage"] _root_url = _vector_image["rootUrl"] _large_artifact = _vector_image["artifacts"][-1]["fileIdentifyingUrlPathSegment"] assert all([_root_url, _vector_image]) image_url = _root_url+_large_artifact except TypeError: image_url = '' pass values = [position, url, name, reaction, connections, image_url, input_url] assert all([v is not None for inin values]) # print(name, url) row = dict(zip(FIELDNAMES, values)) DATA.append(row) offset += step def save_in_file(self, data): with open('results_linkedin_post_likers_lobstrio.txt', 'In') as g: writer = csv.DictWriter(g, delimiter='\t', fieldnames=FIELDNAMES) writer.writeheader() for row in data: writer.writerow(row) def main(): print('[0] starting %s' % URL) print('ok\n') time.sleep(2) l = LinkedInLikersScraper() l.get_csrf_token() activity_id, _type = l.get_activity_id(URL) assert activity_id l.iter_reviews(activity_id, URL, _type) l.save_in_file(DATA) print('done :°') if __name__ == '__main__': main()
Step by step Tutorial
OK and now how to use it?
Unfortunately, for ease of development reasons, this script is semi-automatic. That is to say, you must slightly modify the script before launching it.
Indeed, the part login is always delicate, with its captchas and double authentication.
So we made it simpler: just log in to LinkedIn and retrieve the li_at cookie.
Easy and error-free.
This is also the method that we use with our solid scraping no-code tools, accessible here: Store | Lobstr.
We will do this in 5 very simple steps:
- Download the file
- Installer requests
- Retrieve the li_at cookie
- Retrieve the URL of the LinkedIn post
- Start the machine
Download file
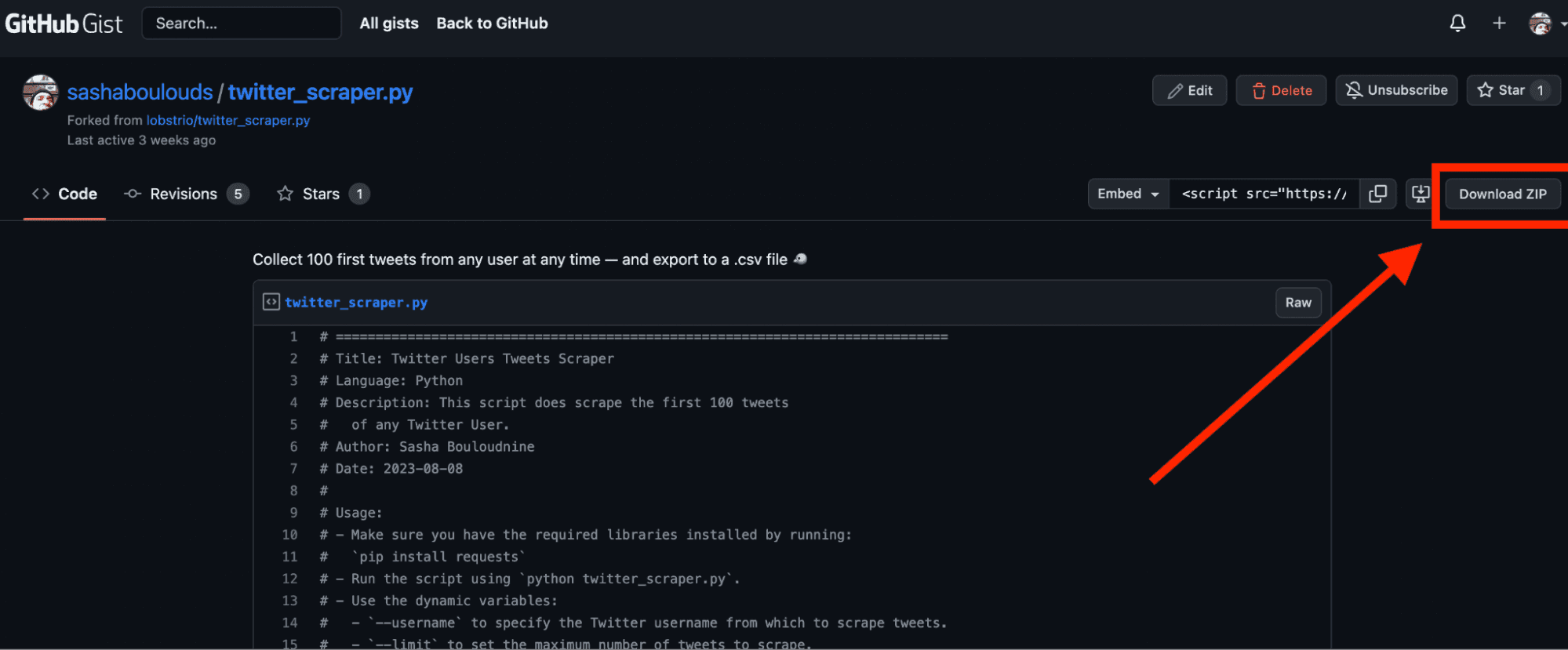
First, we will download the Python file.
Retrieve the file either on this page or via the address mentioned above: linkedin_post_likers.py.
Click on Download ZIP then unzip the file.
If you want a nice text editor, we recommend SublimeText: it’s simple, light, free and effective. Perfect for small scripts.
Install requests
As suggested earlier, install requests simply as follows:
$ pip install requests
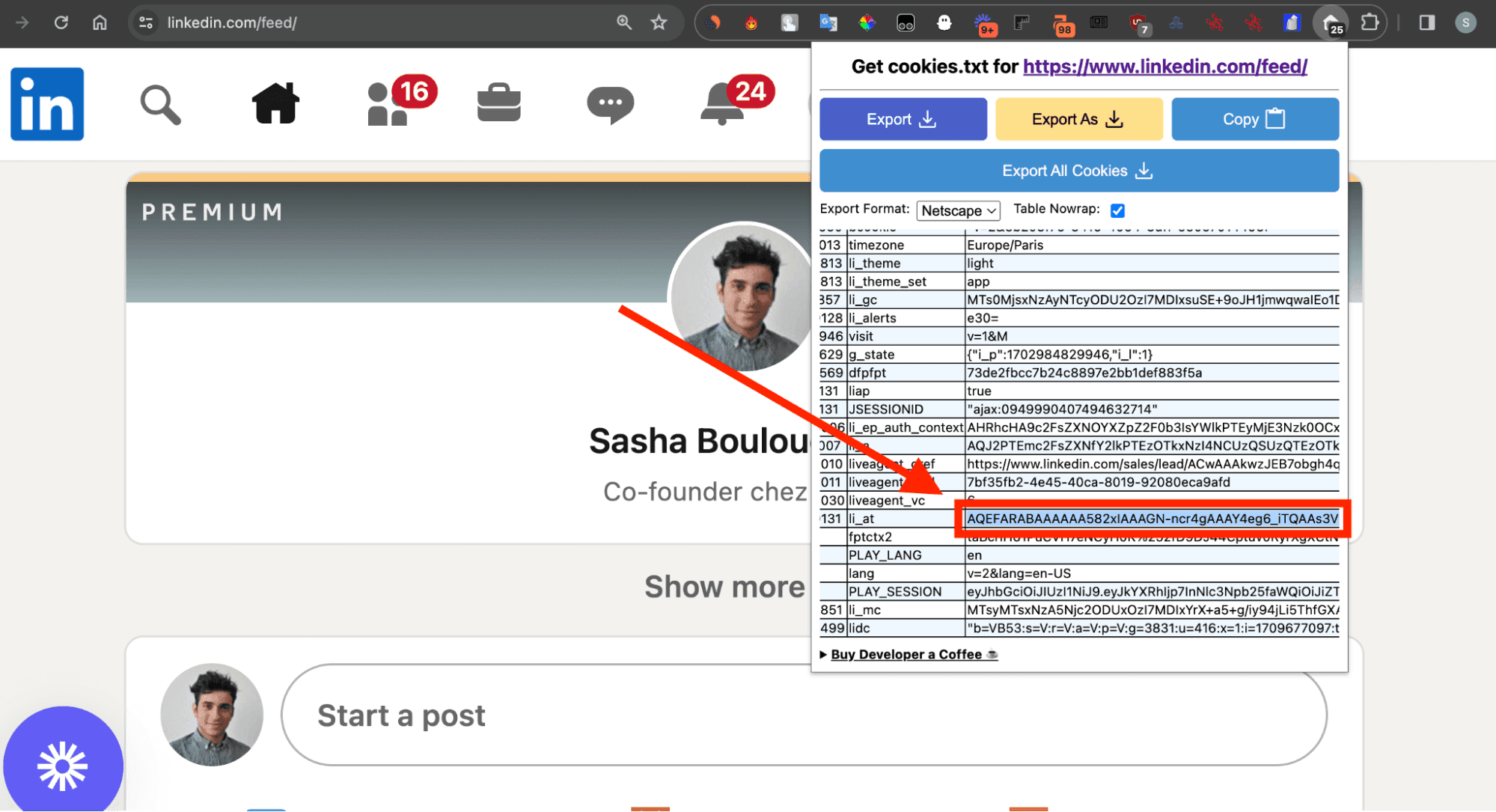
Retrieve the li_at cookie
When you log in to LinkedIn, the site assigns you a session cookie. This cookie certifies that it is really you, you show your white paw.
We're going to go get it.
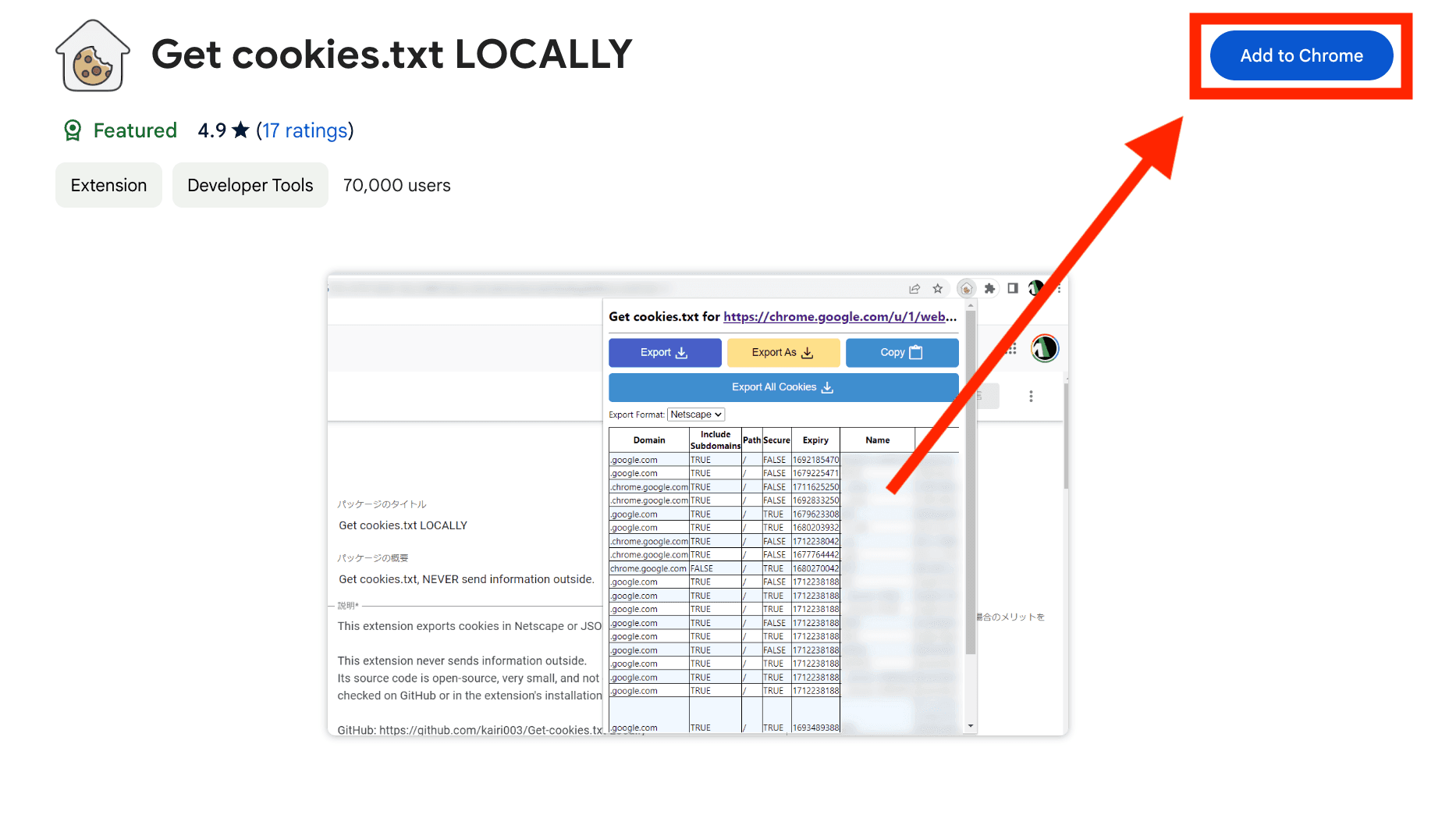
First of all, go to LinkedIn, and identify yourself using your email and password.
Then download the extension Get cookies.txt LOCALLY from the Chrome Store. This extension will allow us to quickly retrieve the li_at cookie that we will need next.
Finally, once on LinkedIn, collect the li_at cookie by clicking on the extension:
And replace in the script at the variable LI_AT.
# Update your LI_AT below # vvvvvvvvvvvvvvvvvv LI_AT="AQEFARABAAAAAA582xIAAAGN-ncr4gAAAY4eg6_iTQAAs3VybjpsaTplbnRlcnByaXNlQXV0aFRva2VuOmVKeGpaQUFDZGcvUE9TQ2FlMFBHRkJETkVmYjlDU09JWWZlTmJ4V1lJWFhtL0M4R1JnQzJmZ25FXnVybjpsaTplbnRlcnByaXNlUHJvZmlsZToodXJuOmxpOmVudGVycHJpc2VBY2NvdW50OjEyMjE3Nzk0OCwxOTYxMTA0ODQpXnVybjpsaTptZW1iZXI6MzA0NzQwNDUzCJCilw8ToxGdMzR3SPl1TqCZTknBs1duxKFK7L6EsksXVkem6Xq-ZOZRNLuEfpl_6xFR2zcQqQWMPlKPlKJq5AzO8H1mffd4EgVN-MaTu0UEMZdnhd6sLxssWLyAOjDkvPpeab6WM2CfbRitkYiIqyurdTCQrck9Cr3ghlmSBGZlFScZ7xRXu3Xpn3q07cYgenQ5vw"
Retrieve the URL of the LinkedIn post
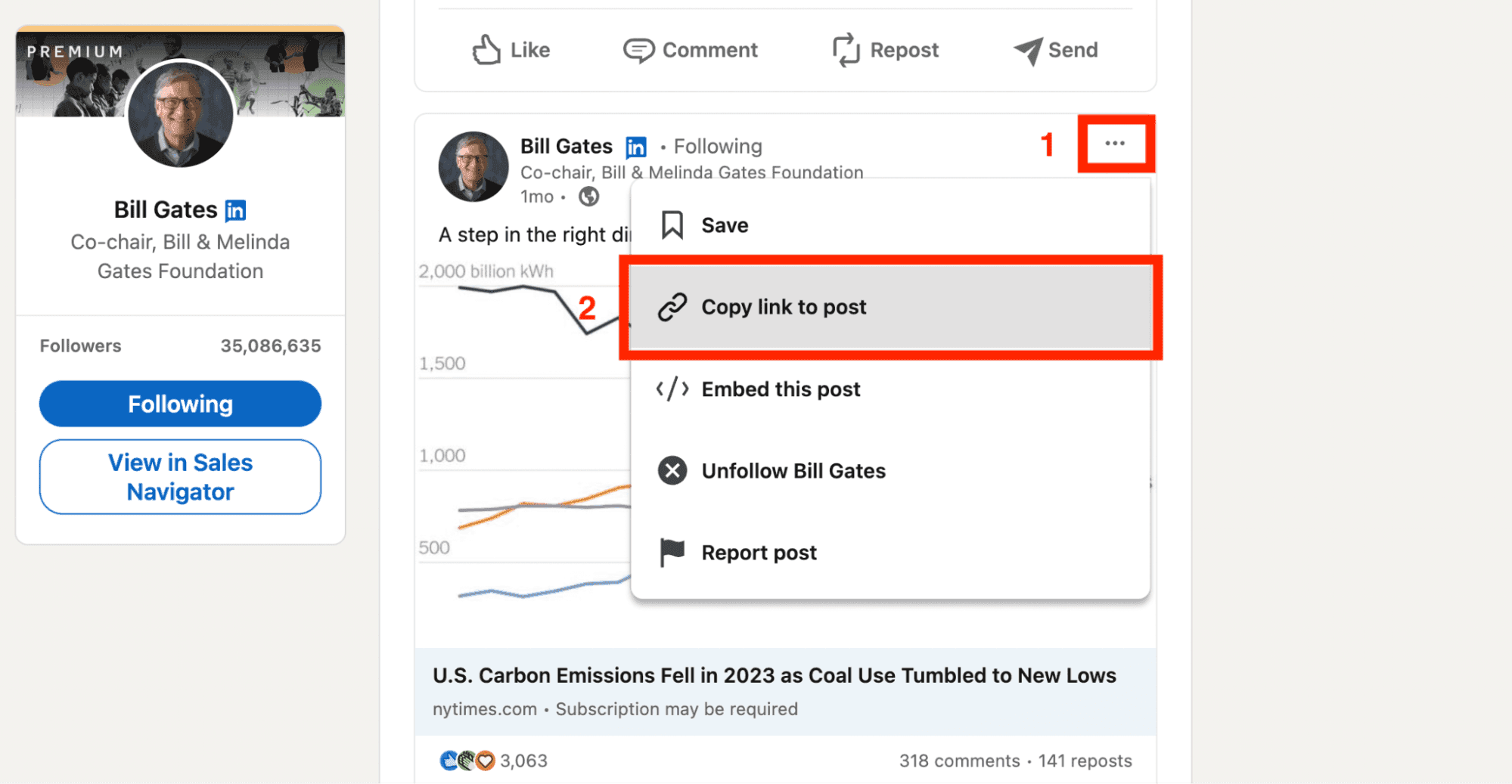
Go to LinkedIn, and retrieve the URL of your LinkedIn post.
At the post level, simply click on the three vertical dots, and click Copy link to post.
Paste this URL into the URL variable.
# Add you URL below # vvvvvvvvvvvvvvvvvv URL = "https://www.linkedin.com/posts/williamhgates_us-carbon-emissions-fell-in-2023-as-coal-activity-7156808265396285440-EV0P/?utm_source=share&utm_medium=member_desktop"
Bill is actually the diminutive of… William. This is what we read in the URL of the post in question: williamhgates. There you go, we know it now.
Start the machine
And now it's time to run the script!
Open the command line, move to where the script is and launch the machine.
You will see information about
- retrieving the csrf_token at the beginning
- recovery of post identifiers
- collecting reactions 50 by 50
$ python3 scrape_name_of_likes_linkedin.py [0] starting https://www.linkedin.com/posts/williamhgates_us-carbon-emissions-fell-in-2023-as-coal-activity-7156808265396285440-EV0P/?utm_source=share&utm_medium=member_desktop ok [1] getting valid csrf_token ajax:4620192952462962301 ok [2] getting activity_id 7156808265396285440 activity ok [3] collecting reviews 0 ok 50 ok 100 ok 150 ok ... 2900 ok 2950 ok 3000 ok done :°
Note that there are only 3000 reactions, while the post displays a little over 3000 total reactions. This is normal, no more than 3000 reactions per post on LinkedIn.
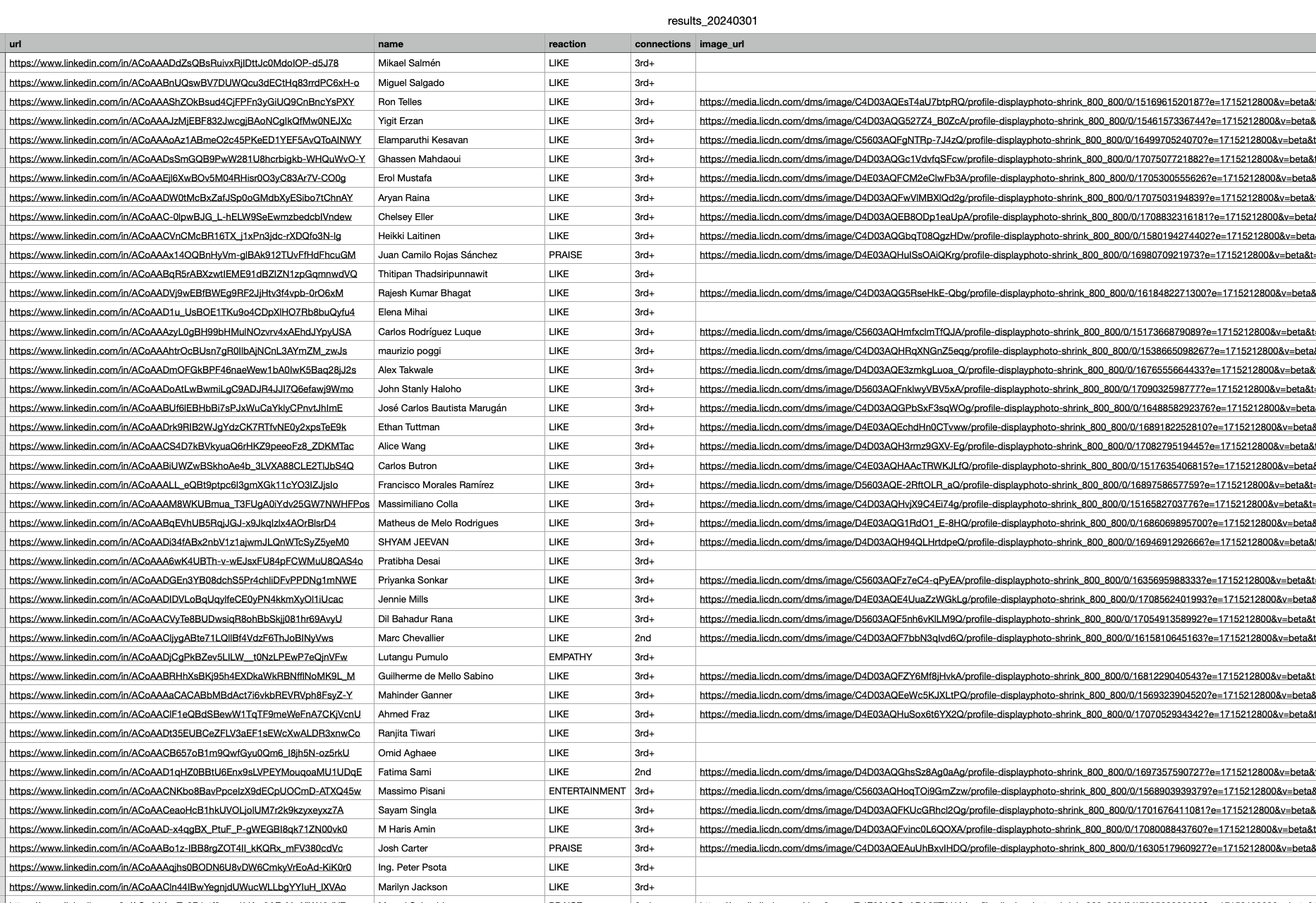
And if you open the file named results_linkedin_post_likers_lobstrio.txt, located in the same folder as the script, you get a superb dataset.
We did extract LinkedIn Post Likers exhaustively, with 3000 reactions collected. And for each reaction, all the attributes mentioned initially.
Structured, exhaustive, and directly usable.
You want to convert this CSV file into an Excel or directly import into a GoogleSheet? Please follow our tutorial: How to convert a CSV file to Excel? | Lobstr Knowledge Base.
FAQ
Is there a no-code solution for LinkedIn Post Likers Extractor?
No, this kind of no-code LinkedIn automation is not available. For now!
Vote the idea right there, we love upvotes, and it massively boosts our motivation and development speed: LinkedIn Post Likers Scraper | LinkedIn.
Or contact us directly here if the need is urgent: Contact sales | Lobstr.
Does this Python Post Likers scraper work if I’m subscribed to LinkedIn Sales Navigator?
Yes, absolutely! You can scrape data with this Python code with all kinds of LinkedIn subscriptions. Simple free plan, LinkedIn Sales Navigator, LinkedIn Recruiter.
How much does it cost to use this Python LinkedIn Post Likers export?
Absolutely nothing, peanuts, nada. No credit card, no free plan, no pricing: this Python code is open source, and reusable at will. It's free.
Is it possible to get email LinkedIn Users scraped through Post Reactions?
Emails are highly requested. You can deploy a successful lead generation through direct outreach strategy. And massively boost B2B sales.
Unfortunately it is not possible to recover the email address of a LinkedIn profile, from the information retrieved with this LinkedIn Post Likers scraper.
Many chrome extensions that let you find phone numbers or email addresses from a LinkedIn profile.
But these do not allow mass enrichment from profile URLs. You need to click from the add-on, directly from the LinkedIn page.
Not ideal for 3000+ reactions CSV file list.
There are also mass enrichment tools, such as B2B SaaS:
But here, on top of the name, you need to provide the company name the person is working in. And we do not collect this information.
If you feel this specific need, please, tell us: Ideas | Lobstr.
Is it possible to scrape LinkedIn post comments with Python?
Yes, absolutely! Contact us directly via chat if you are interested in this tutorial. We will be happy to provide the complete code as well as a tutorial.
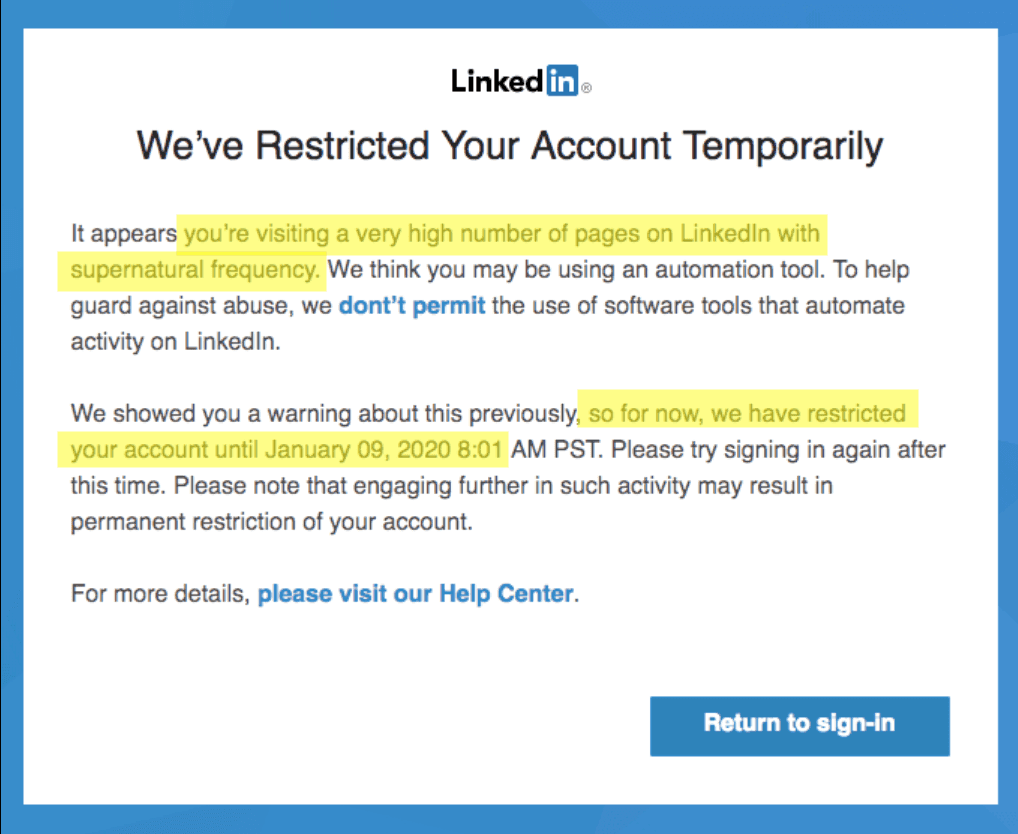
Can LinkedIn block my account?
Yes, as stated in the general conditions, if LinkedIn recognizes that you are carrying out actions in an automated manner, the account can be blocked.
And it happens quite often 🌝
Be careful not to visit pages with supernatural frequency:
- Pause between queries
- No more than 30K reactions collected per day
- Secondary account usage
👽