How to scrape Tweets with Python and requests in 2023?
All anger has an end, and tweets are now again available without a login. As of August 8, 2023, the tutorial below is fully functional again.
Please note that while it used to be possible to collect all tweets from any user, today only the first 100 tweets are accessible without login. Use with care.
Elon Musk is a nice guy, you can't take that away from him.
You wanna scrape more than 1000 tweets by user without getting blocked? Test our ready-made powerful no code tool Twitter User Tweets Export.
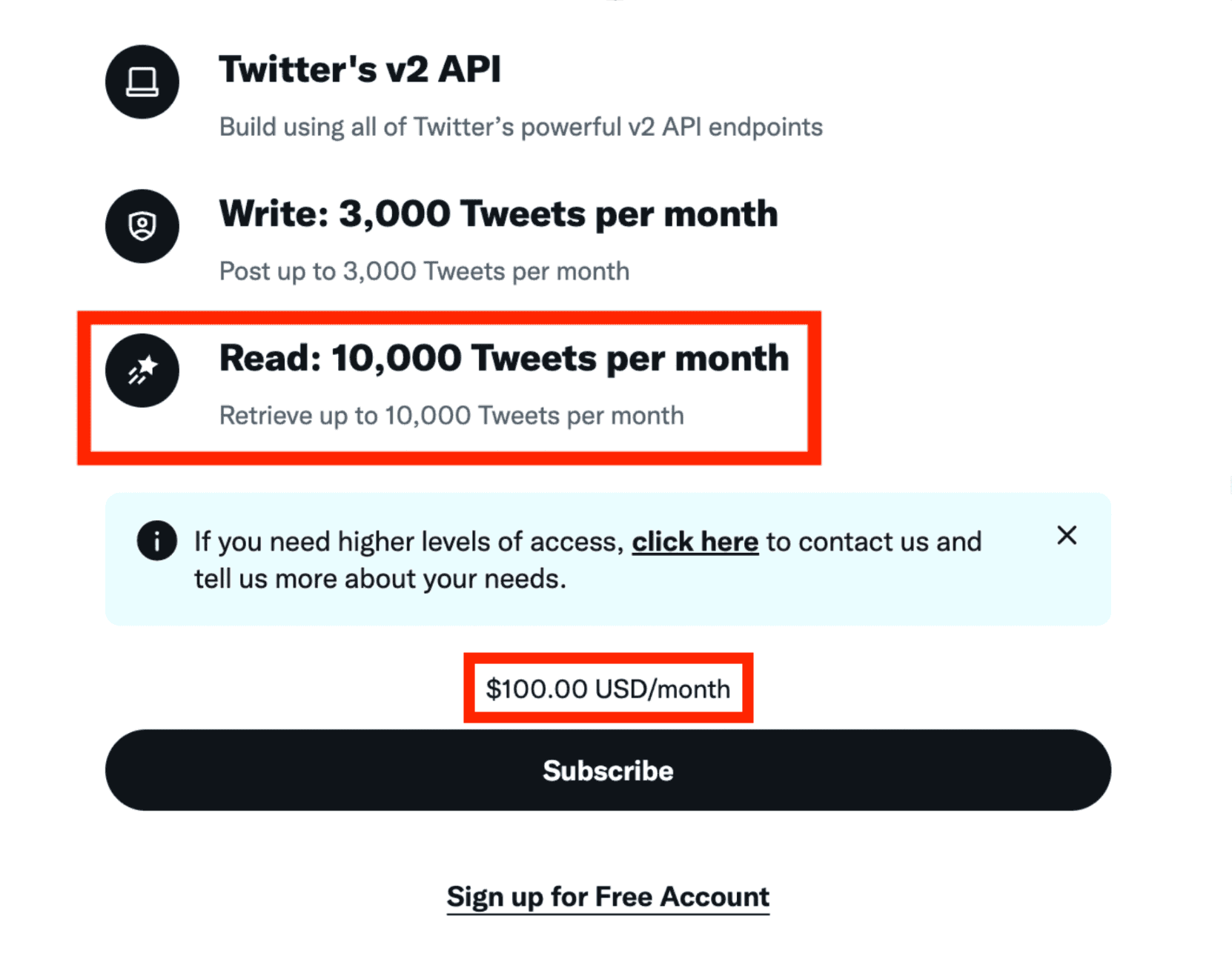
But since his takeover of Twitter, also known as X, the API is literally costing an arm and a leg. To read 10,000 tweets a month, you'll now have to pay the unfortunate sum of $100.
In this tutorial, we'll see how to do this with Python 3 and requests. And get with a few lines of code the first 100 tweets of any user on Twitter. For free, with no other limitation. And directly saved in a nice .csv file.
Third party application developers, LLMs, financial investors, this tuto is for you!
Prerequisites
To start with, we will install requests, the library that allows Python to browse the internet. And, by the way, the most installed library in the world, with over 49K stars on github.
With a simple command like the following:
$ pip3 install requests
Done.
Full code
Full code is available below, and on Github here.
# ============================================================================= # Title: Twitter Users Tweets Scraper # Language: Python # Description: This script does scrape the first 100 tweets # of any Twitter User. # Author: Sasha Bouloudnine # Date: 2023-08-08 # # Usage: # - Make sure you have the required libraries installed by running: # `pip install requests` # - Run the script using `python twitter_scraper.py`. # - Use the dynamic variables: # - `--username` to specify the Twitter username from which to scrape tweets. # - `--limit` to set the maximum number of tweets to scrape. # # Notes: # - As of July 1st, 2023, Twitter removed public access to user tweets. # - Starting from August 1st, 2023, the script is no longer constrained by the limit # but can collect a maximum of 100 tweets per user. # # ============================================================================= import csv import json import requests import argparse import datetime import time import re # First request default headers DEFAULT_HEADERS ={ 'authority': 'twitter.com', 'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7', 'accept-language': 'fr-FR,fr;q=0.9', 'cache-control': 'max-age=0', 'sec-ch-ua': '"Not_A Brand";v="8", "Chromium";v="120", "Google Chrome";v="120"', 'sec-ch-ua-mobile': '?0', 'sec-ch-ua-platform': '"macOS"', 'sec-fetch-dest': 'document', 'sec-fetch-mode': 'navigate', 'sec-fetch-site': 'same-origin', 'sec-fetch-user': '?1', 'upgrade-insecure-requests': '1', 'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36', } # All values stored here are constant, copy-pasted from the website FEATURES_USER = '{"hidden_profile_likes_enabled":false,"hidden_profile_subscriptions_enabled":true,"responsive_web_graphql_exclude_directive_enabled":true,"verified_phone_label_enabled":false,"subscriptions_verification_info_is_identity_verified_enabled":false,"subscriptions_verification_info_verified_since_enabled":true,"highlights_tweets_tab_ui_enabled":true,"creator_subscriptions_tweet_preview_api_enabled":true,"responsive_web_graphql_skip_user_profile_image_extensions_enabled":false,"responsive_web_graphql_timeline_navigation_enabled":true}' FEATURES_TWEETS = '{"rweb_lists_timeline_redesign_enabled":true,"responsive_web_graphql_exclude_directive_enabled":true,"verified_phone_label_enabled":false,"creator_subscriptions_tweet_preview_api_enabled":true,"responsive_web_graphql_timeline_navigation_enabled":true,"responsive_web_graphql_skip_user_profile_image_extensions_enabled":false,"tweetypie_unmention_optimization_enabled":true,"responsive_web_edit_tweet_api_enabled":true,"graphql_is_translatable_rweb_tweet_is_translatable_enabled":true,"view_counts_everywhere_api_enabled":true,"longform_notetweets_consumption_enabled":true,"responsive_web_twitter_article_tweet_consumption_enabled":false,"tweet_awards_web_tipping_enabled":false,"freedom_of_speech_not_reach_fetch_enabled":true,"standardized_nudges_misinfo":true,"tweet_with_visibility_results_prefer_gql_limited_actions_policy_enabled":true,"longform_notetweets_rich_text_read_enabled":true,"longform_notetweets_inline_media_enabled":true,"responsive_web_media_download_video_enabled":false,"responsive_web_enhance_cards_enabled":false}' AUTHORIZATION_TOKEN = 'AAAAAAAAAAAAAAAAAAAAANRILgAAAAAAnNwIzUejRCOuH5E6I8xnZz4puTs%3D1Zv7ttfk8LF81IUq16cHjhLTvJu4FA33AGWWjCpTnA' HEADERS = { 'authorization': 'Bearer %s' % AUTHORIZATION_TOKEN, # The Bearer value is a fixed value that is copy-pasted from the website # 'x-guest-token': None, } GET_USER_URL = 'https://twitter.com/i/api/graphql/SAMkL5y_N9pmahSw8yy6gw/UserByScreenName' GET_TWEETS_URL = 'https://twitter.com/i/api/graphql/XicnWRbyQ3WgVY__VataBQ/UserTweets' FIELDNAMES = ['id', 'tweet_url', 'name', 'user_id', 'username', 'published_at', 'content', 'views_count', 'retweet_count', 'likes', 'quote_count', 'reply_count', 'bookmarks_count', 'medias'] class TwitterScraper: def __init__(self, username): # We do initiate requests Session, and we get the `guest-token` from the HomePage resp = requests.get("https://twitter.com/", headers=DEFAULT_HEADERS) self.gt = resp.cookies.get_dict().get("gt") or "".join(re.findall(r'(?<=\"gt\=)[^;]+', resp.text)) assert self.gt HEADERS['x-guest-token'] = getattr(self, 'gt') # assert self.guest_token self.HEADERS = HEADERS assert username self.username = username def get_user(self): # We recover the user_id required to go ahead arg = {"screen_name": self.username, "withSafetyModeUserFields": True} params = { 'variables': json.dumps(arg), 'features': FEATURES_USER, } response = requests.get( GET_USER_URL, params=params, headers=self.HEADERS ) try: json_response = response.json() except requests.exceptions.JSONDecodeError: print(response.status_code) print(response.text) raise result = json_response.get("data", {}).get("user", {}).get("result", {}) legacy = result.get("legacy", {}) return { "id": result.get("rest_id"), "username": self.username, "full_name": legacy.get("name") } def tweet_parser( self, user_id, full_name, tweet_id, item_result, legacy ): # It's a static method to parse from a tweet medias = legacy.get("entities").get("media") medias = ", ".join(["%s (%s)" % (d.get("media_url_https"), d.get('type')) for d in legacy.get("entities").get("media")]) if medias else None return { "id": tweet_id, "tweet_url": f"https://twitter.com/{self.username}/status/{tweet_id}", "name": full_name, "user_id": user_id, "username": self.username, "published_at": legacy.get("created_at"), "content": legacy.get("full_text"), "views_count": item_result.get("views", {}).get("count"), "retweet_count": legacy.get("retweet_count"), "likes": legacy.get("favorite_count"), "quote_count": legacy.get("quote_count"), "reply_count": legacy.get("reply_count"), "bookmarks_count": legacy.get("bookmark_count"), "medias": medias } def iter_tweets(self, limit=120): # The main navigation method print(f"[+] scraping: {self.username}") _user = self.get_user() full_name = _user.get("full_name") user_id = _user.get("id") if not user_id: print("/!\\ error: no user id found") raise NotImplementedError cursor = None _tweets = [] while True: var = { "userId": user_id, "count": 100, "cursor": cursor, "includePromotedContent": True, "withQuickPromoteEligibilityTweetFields": True, "withVoice": True, "withV2Timeline": True } params = { 'variables': json.dumps(var), 'features': FEATURES_TWEETS, } response = requests.get( GET_TWEETS_URL, params=params, headers=self.HEADERS, ) json_response = response.json() result = json_response.get("data", {}).get("user", {}).get("result", {}) timeline = result.get("timeline_v2", {}).get("timeline", {}).get("instructions", {}) entries = [x.get("entries") for x in timeline if x.get("type") == "TimelineAddEntries"] entries = entries[0] if entries else [] for entry in entries: content = entry.get("content") entry_type = content.get("entryType") tweet_id = entry.get("sortIndex") if entry_type == "TimelineTimelineItem": item_result = content.get("itemContent", {}).get("tweet_results", {}).get("result", {}) legacy = item_result.get("legacy") tweet_data = self.tweet_parser(user_id, full_name, tweet_id, item_result, legacy) _tweets.append(tweet_data) if entry_type == "TimelineTimelineCursor" and content.get("cursorType") == "Bottom": # NB: after 07/01 lock and unlock — no more cursor available if no login provided i.e. max. 100 tweets per username no more cursor = content.get("value") if len(_tweets) >= limit: # We do stop — once reached tweets limit provided by user break print(f"[#] tweets scraped: {len(_tweets)}") if len(_tweets) >= limit or cursor is None or len(entries) == 2: break return _tweets def generate_csv(self, tweets=[]): import datetime timestamp = int(datetime.datetime.now().timestamp()) filename = '%s_%s.csv' % (self.username, timestamp) print('[+] writing %s' % filename) with open(filename, 'w') as f: writer = csv.DictWriter(f, fieldnames=FIELDNAMES, delimiter='\t') writer.writeheader() for tweet in tweets: print(tweet['id'], tweet['published_at']) writer.writerow(tweet) def main(): print('start') s = time.perf_counter() argparser = argparse.ArgumentParser() argparser.add_argument('--username', '-u', type=str, required=False, help='user to scrape tweets from', default='elonmusk') argparser.add_argument('--limit', '-l', type=int, required=False, help='max tweets to scrape', default=100) args = argparser.parse_args() username = args.username limit = args.limit assert all([username, limit]) twitter_scraper = TwitterScraper(username) tweets = twitter_scraper.iter_tweets(limit=limit) assert tweets twitter_scraper.generate_csv(tweets) print('elapsed %s' % (time.perf_counter()-s)) print('''~~ success _ _ _ | | | | | | | | ___ | |__ ___| |_ __ __ | |/ _ \| '_ \/ __| __/| '__| | | (_) | |_) \__ \ |_ | | |_|\___/|_.__/|___/\__||_| ''') if __name__ == '__main__': main()
To use the script, it is very simple, download the .py script.
And in your console, use the following command:
python3 twitter_scraper.py --username elonmusk --limit 100
You will upload the 100 most recent tweets from the inevitable Elon.
You can of course change the user name, and limit, to download as many tweets as you need, from any user on Twitter.
Be careful, as of August 8, 2023, you can scrape max. 100 tweets per user. Fair hard-limit for all, after the Elon's fury on July 1st, 2023.
🐦
Full Tutorial
In this tutorial, we will try to scrape the tweets of the most popular user of the net: I named @elonmusk, the famous owner of the site and incidentally the richest man in the world.
With the following attributes:
- name
- username
- publication date
- content
- number of views
- number of retweets
- number of likes
- number of bookmarks
- number of retweets
- number of replies
Intuitively, we can throw away these few simple lines of code:
import requests s = requests.Session() r = s.get('https://twitter.com/elonmusk') with open('test.html', 'w') as f: f.write(r.text)
But when opening the file, no data.
It doesn't work:
So you'll have to do it differently.
This guided tutorial will be done in 5 steps:
- Reverse Engineering
- Retrieving the user-id and the x-guest-token
- Pagination of Tweets
- Creation of a CSV file
- Using dynamic variables
Let's go.
1. Reverse Engineering
As seen before, the basic URL does not work. That is to say that when we visit the user's page, here https://twitter.com/elonmusk, we can't retrieve his (precious?) tweets.
This is because the browser works in several steps:
- the URL of the page is visited https://twitter.com/elonmusk
- requests are made in the background
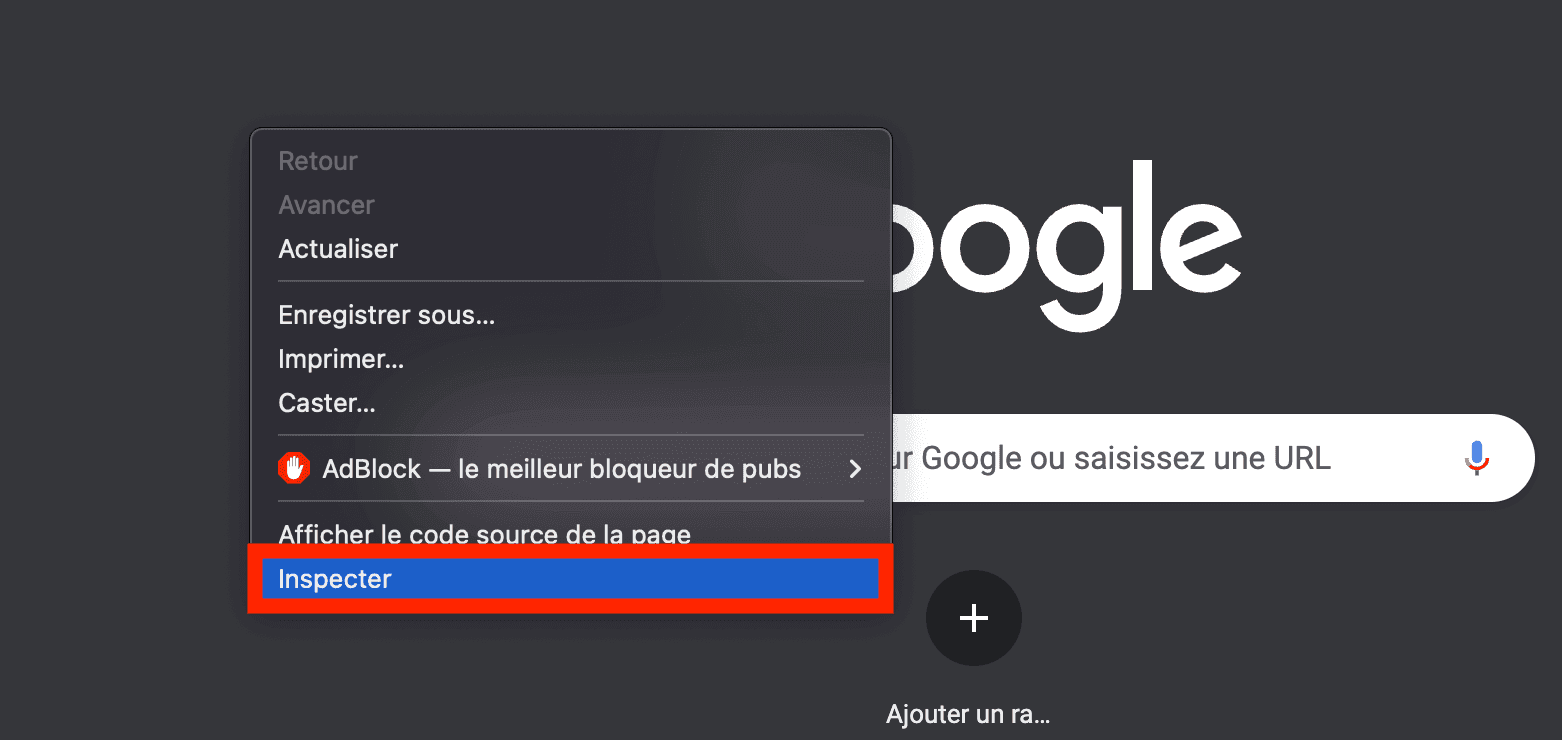
So we are going to use the inspection tool to observe the silent requests that are exchanged between the browser and the site, and then reproduce them in our Python code.
We start by opening the inspection tool:
Then we open the Network part:
Finally, you go to the target URL.
From here, more than 250 queries appear. How do I identify the query that accesses the tweets?
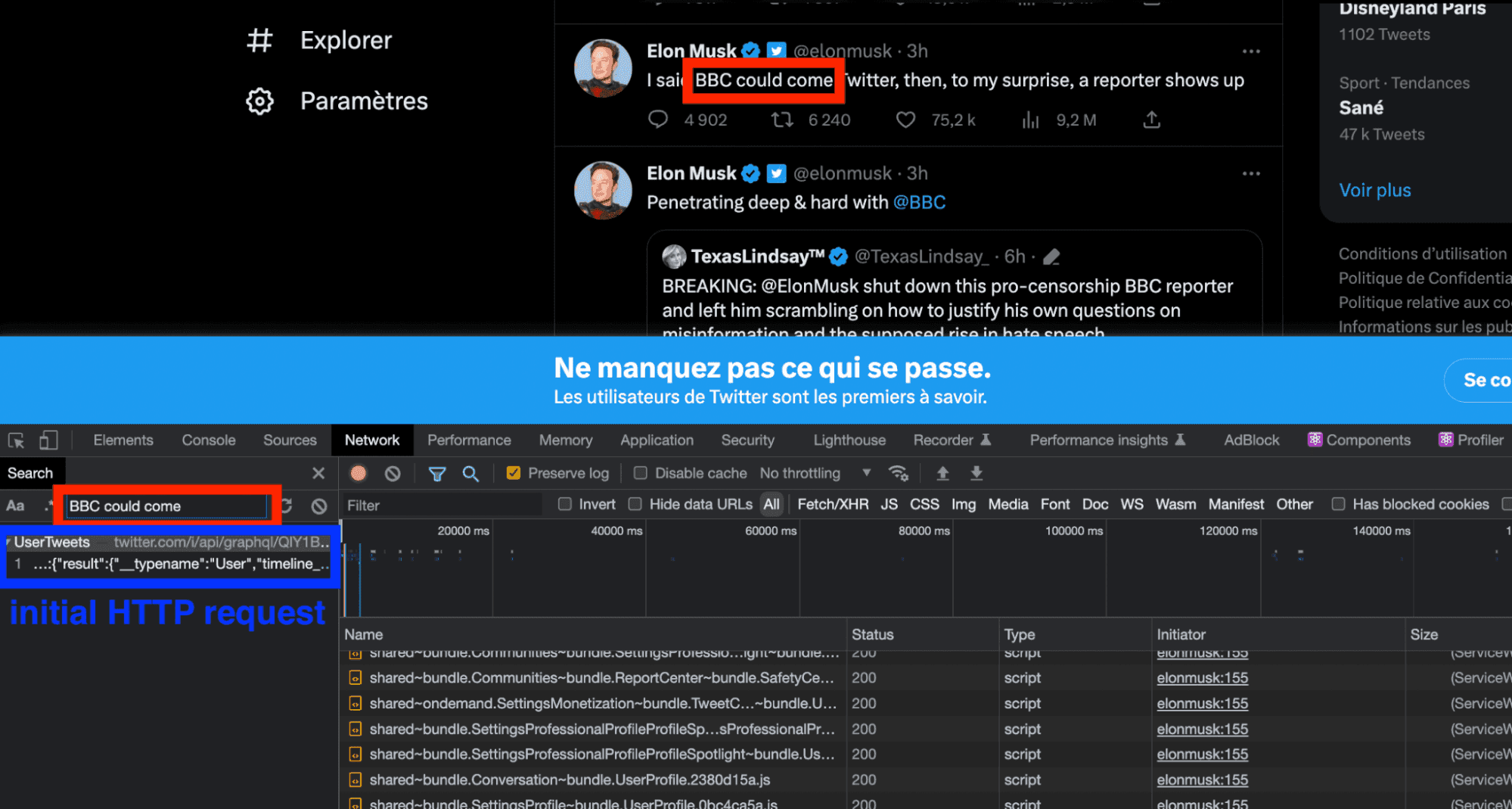
Well, it's very simple, with the Network Search tool of the inspection tool, we type the content of a tweet. The tool will redirect us to .the original request, which contains the content that we want to retrieve programmatically.
Here we choose the text BBC could come, which comes from this tweet posted on 12/04/2023: https://twitter.com/elonmusk/status/1646055951819223040?s=20
And bingo!
The initial query appears, simple and clear:
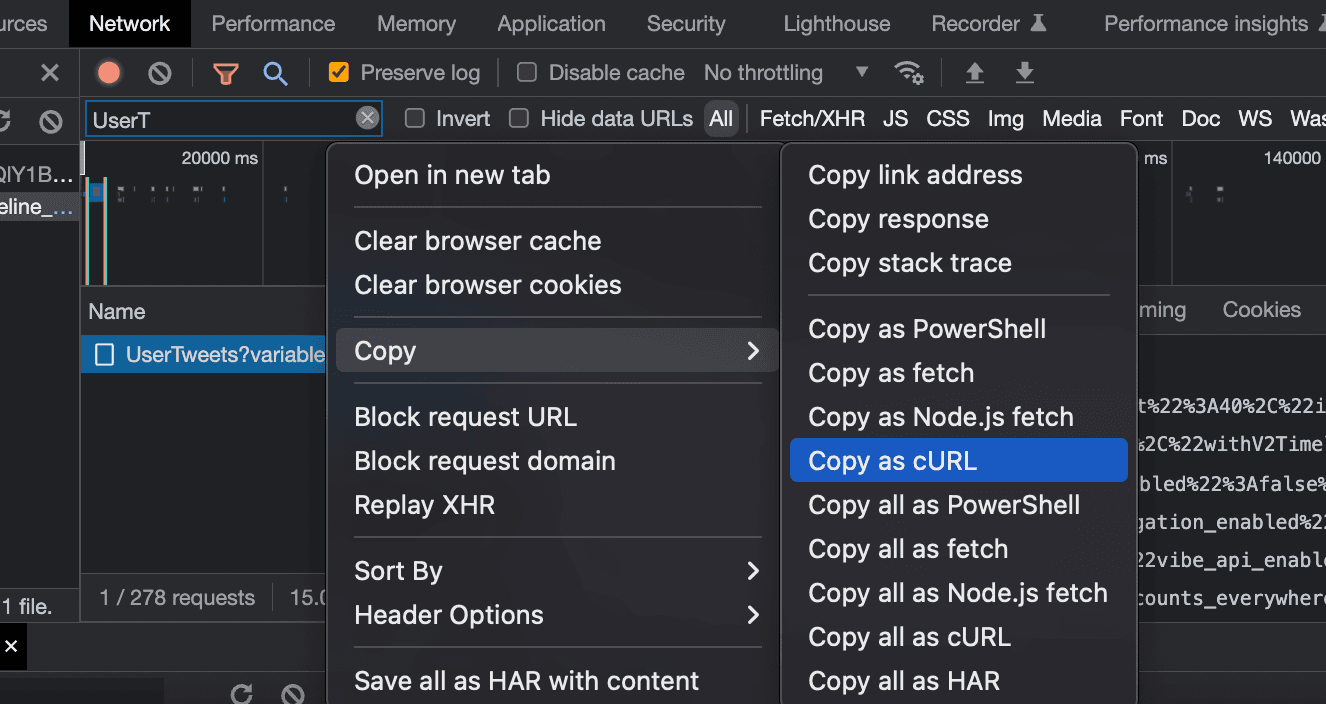
Then just copy the query, in cURL format:
To convert a cURL query to Python format, you can use this robust, free and powerful online tool: https://curl.trillworks.com/.
We have a complete and exhaustive code. By deleting the non essential variables, this is what you get:
import requests headers = { 'authority': 'twitter.com', 'accept': '*/*', 'accept-language': 'fr-FR,fr;q=0.9,en-US;q=0.8,en;q=0.7', 'authorization': 'Bearer AAAAAAAAAAAAAAAAAAAAANRILgAAAAAAnNwIzUejRCOuH5E6I8xnZz4puTs%3D1Zv7ttfk8LF81IUq16cHjhLTvJu4FA33AGWWjCpTnA', 'content-type': 'application/json', 'sec-ch-ua': '"Chromium";v="112", "Google Chrome";v="112", "Not:A-Brand";v="99"', 'sec-ch-ua-mobile': '?0', 'sec-ch-ua-platform': '"macOS"', 'sec-fetch-dest': 'empty', 'sec-fetch-mode': 'cors', 'sec-fetch-site': 'same-origin', 'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36', 'x-guest-token': '1646107729780416513', 'x-twitter-active-user': 'yes', 'x-twitter-client-language': 'fr', } params = { 'variables': '{"userId":"44196397","count":40,"includePromotedContent":true,"withQuickPromoteEligibilityTweetFields":true,"withDownvotePerspective":false,"withVoice":true,"withV2Timeline":true}', 'features': '{"blue_business_profile_image_shape_enabled":false,"responsive_web_graphql_exclude_directive_enabled":true,"verified_phone_label_enabled":false,"responsive_web_graphql_timeline_navigation_enabled":true,"responsive_web_graphql_skip_user_profile_image_extensions_enabled":false,"tweetypie_unmention_optimization_enabled":true,"vibe_api_enabled":true,"responsive_web_edit_tweet_api_enabled":true,"graphql_is_translatable_rweb_tweet_is_translatable_enabled":true,"view_counts_everywhere_api_enabled":true,"longform_notetweets_consumption_enabled":true,"tweet_awards_web_tipping_enabled":false,"freedom_of_speech_not_reach_fetch_enabled":false,"standardized_nudges_misinfo":true,"tweet_with_visibility_results_prefer_gql_limited_actions_policy_enabled":false,"interactive_text_enabled":true,"responsive_web_text_conversations_enabled":false,"longform_notetweets_rich_text_read_enabled":false,"responsive_web_enhance_cards_enabled":false}', } response = requests.get( 'https://twitter.com/i/api/graphql/XicnWRbyQ3WgVY__VataBQ/UserTweets', params=params, cookies=cookies, headers=headers, ) print(response.json())
And if we execute this code, it works! We get a nice JSON, with all the data, which we will then have to parse.
That's easy.
However, if we run the script a few days later, this is what happens:
$ python3 twitter_scraper.py {'errors': [{'message': 'Bad guest token', 'code': 239}]}
We will have to improve our tool further.
2. Retrieving the user-id and the x-guest-token
In the code provided in the first part, we notice the presence of the following hard-coded variables:
- the value of the 'authorization' header
- the value of the 'x-guest-token' header
- the value of the 'user-id' header
Good news, the value of the header 'authorization' is fixed in time.
We will add it at the top of the code, in capital letters, to facilitate the processing.
AUTHORIZATION_TOKEN = 'AAAAAAAAAAAAAAAAAAAAANRILgAAAAAAnNwIzUejRCOuH5E6I8xnZz4puTs%3D1Zv7ttfk8LF81IUq16cHjhLTvJu4FA33AGWWjCpTnA'
So how to recover the 2 other variables?
a. x-guest-token
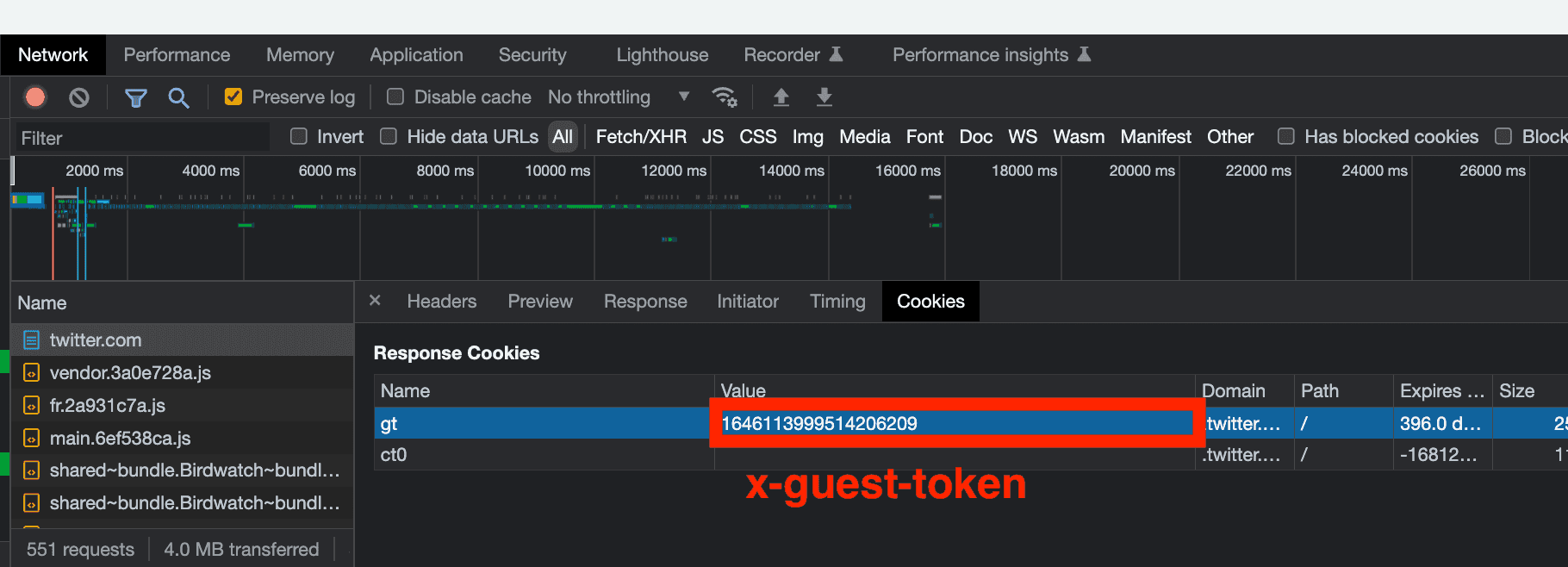
Using the Network part of the inspection tool again, it appears that this variable is simply provided by the site, when visiting the first page.
The token then appears in two distinct places:
- via a cookie
- present in the hard-coded response.text
First, the value is in a cookie returned directly by the site:
In the first case, we will simply visit the home page of the site at the beginning of the script, get the value of the token present in the cookie, and attach it to the header of our request session.
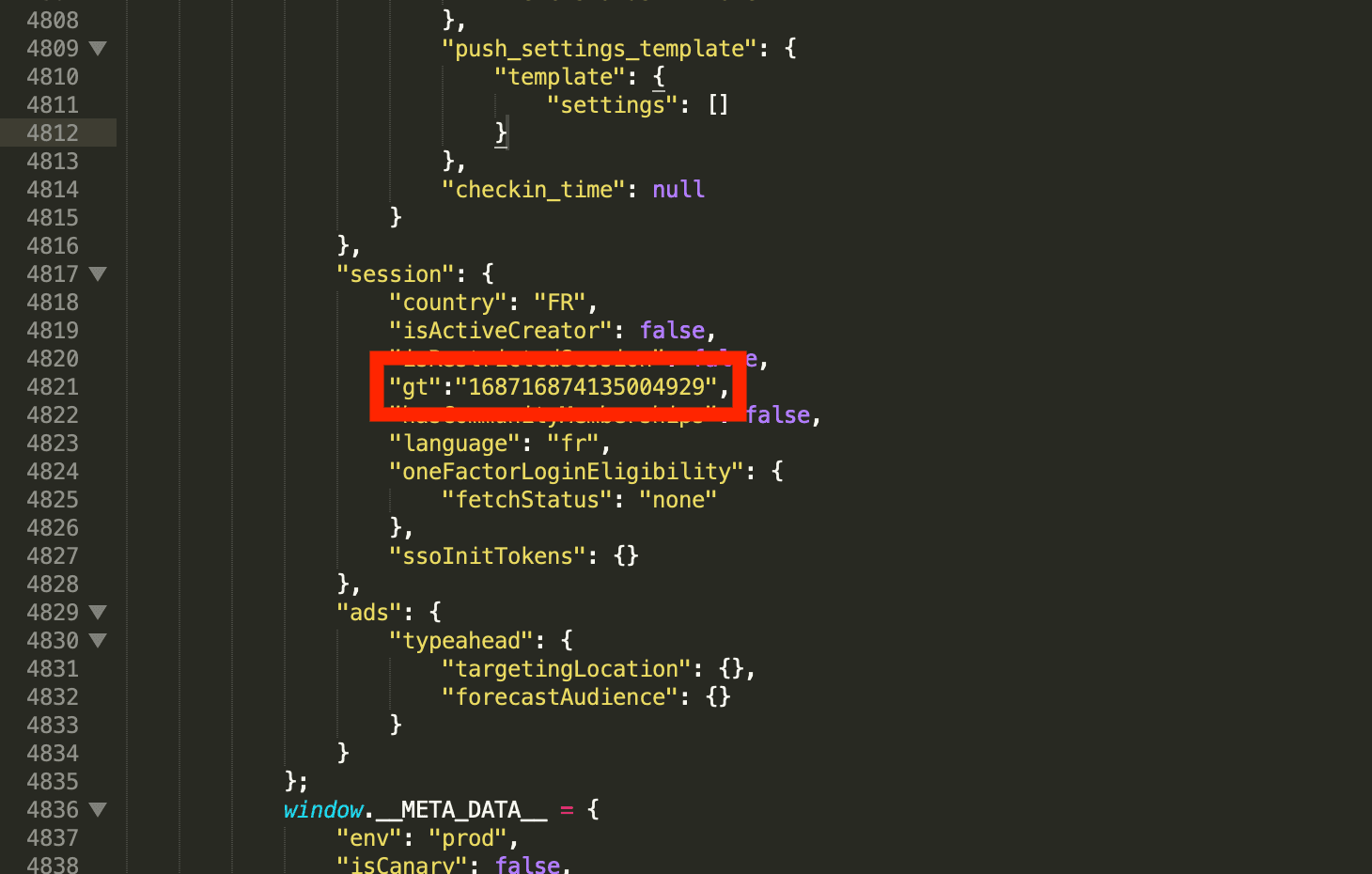
guest_token = resp.cookies.get_dict().get("gt")
In the second case, the cookie value is present in the response text, hidden between the string 'gt' and a semicolon.
So we'll use a simple regex, to systematically fetch our guest-token value from the text of the response.
guest_token = "".join(re.findall(r'(?<=\"gt\=)[^;]+', text))
If you'd like to improve your regex game, which is always handy for fetching data with a singular string structure (hello emails) without getting bogged down in HTML code structure, we can only recommend this superb online tool: https://regex101.com/.
And so complete initialization code to retrieve the x-guest-token every time:
HEADERS = { 'authority': 'twitter.com', 'accept': '*/*', 'accept-language': 'en-US,en;q=0.9', 'authorization': 'Bearer %s' % AUTHORIZATION_TOKEN, # The Bearer value is a fixed value that is copy-pasted from the website 'content-type': 'application/json', 'sec-ch-ua': '"Google Chrome";v="111", "Not(A:Brand";v="8", "Chromium";v="111"', 'sec-ch-ua-mobile': '?0', 'sec-ch-ua-platform': '"Windows"', 'sec-fetch-dest': 'empty', 'sec-fetch-mode': 'cors', 'sec-fetch-site': 'same-origin', 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36', # 'x-guest-token': None, 'x-twitter-active-user': 'yes', # yes 'x-twitter-client-language': 'en', } class TwitterScraper: def __init__(self): # We do initiate requests Session, and we get the `guest-token` from the HomePage resp = requests.get("https://twitter.com/") text = resp.text assert text self.guest_token = resp.cookies.get_dict().get("gt") or "".join(re.findall(r'(?<=\"gt\=)[^;]+', text)) assert self.guest_token HEADERS['x-guest-token'] = self.guest_token self.HEADERS = HEADERS
Problem solved.
It's time to move on to the next variable: the 'user-id'.
b. user-id
Elon, the inevitable richest man in the world, has the following user-id: 44196397
But how to find the user-id of another user, and thus be able to rely on a flexible and resilient code?
With the same method as before, it appears that this element is retrieved during a previous request: UserByScreenName.
As input, we provide the user name: elonmusk. And as output, we get the user-id: 44196397.
Great!
And here is the part of the code in Python:
GET_USER_URL = 'https://twitter.com/i/api/graphql/SAMkL5y_N9pmahSw8yy6gw/UserByScreenName' def get_user(self, username): # We recover the user_id required to go ahead arg = {"screen_name": username, "withSafetyModeUserFields": True} params = { 'variables': json.dumps(arg), 'features': FEATURES, } response = requests.get( GET_USER_URL, params=params, headers=self.HEADERS ) json_response = response.json() result = json_response.get("data", {}).get("user", {}).get("result", {}) legacy = result.get("legacy", {}) user_id = result.get("rest_id") return user_id
So now we have the x-guest-token, and the user-id. From the user-id, we can retrieve the tweets.
And when we run the program, it works!
$ python3 twitter_scraper.py [+] scraping: elonmusk [#] tweets scraped: 16 ~ done
But we only collected 16 tweets. Not good. Now we'll have to take over the pagination.
3. Pagination of Tweets
Following Elon's outburst on July 1, 2023, it is now impossible to page without a login. Also, this section is deprecated.
We know that the tweets are retrieved from the following URL: UserTweets.
So we go back to mister musk's page, we open the Network tab of the inspection tool (again), and we scroll down so that new tweets appear.
With this second request, and by comparing it with the first one, we will be able to understand what allows the passage from one to the other :
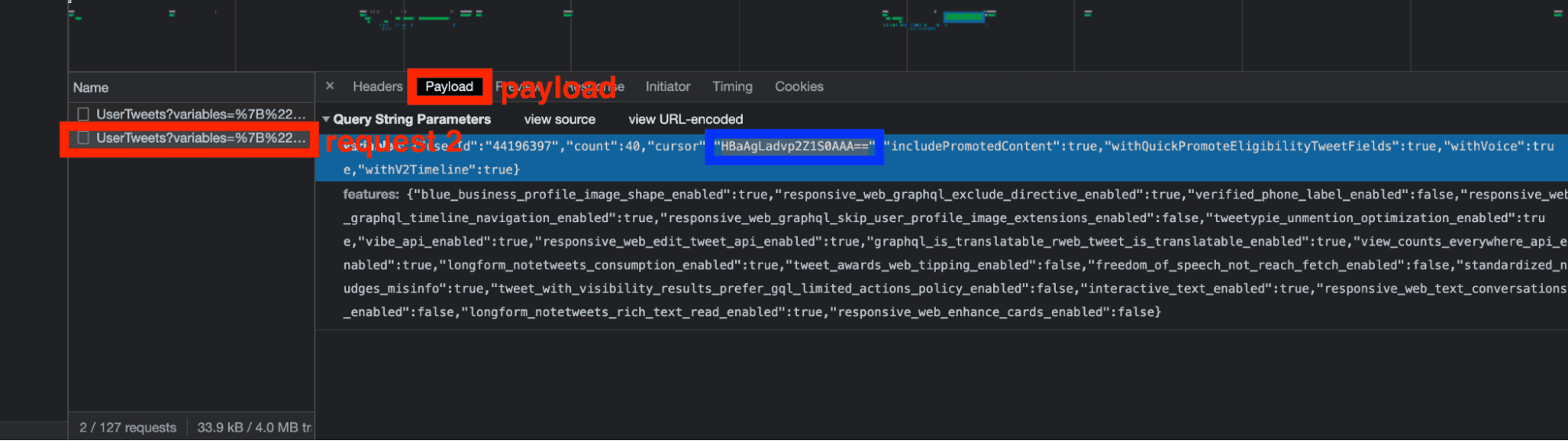
When opening the payload part of the second request, an additional element was added: the cursor.
And twitter actually works with a pagination with cursor. It is a value, associated to the last element of a list, and which allows to find the elements which are after and before. A precise and dynamic pagination!
So now you just need to retrieve the cursor present in the response of the first request:
And insert it in the payload of the second request:
And there you go.
We can now switch from one page to another, and retrieve several pages of tweets.
Here is the complete code:
GET_TWEETS_URL = 'https://twitter.com/i/api/graphql/XicnWRbyQ3WgVY__VataBQ/UserTweets' … def iter_tweets(self, limit=120): # The main navigation method print(f"[+] scraping: {self.username}") _user = self.get_user() full_name = _user.get("full_name") user_id = _user.get("id") if not user_id: print("/!\\ error: no user id found") raise NotImplementedError cursor = None _tweets = [] while True: var = { "userId": user_id, "count": 100, "cursor": cursor, "includePromotedContent": True, "withQuickPromoteEligibilityTweetFields": True, "withVoice": True, "withV2Timeline": True } params = { 'variables': json.dumps(var), 'features': FEATURES_TWEETS, } response = requests.get( GET_TWEETS_URL, params=params, headers=self.HEADERS, ) json_response = response.json() result = json_response.get("data", {}).get("user", {}).get("result", {}) timeline = result.get("timeline_v2", {}).get("timeline", {}).get("instructions", {}) entries = [x.get("entries") for x in timeline if x.get("type") == "TimelineAddEntries"] entries = entries[0] if entries else [] for entry in entries: content = entry.get("content") entry_type = content.get("entryType") tweet_id = entry.get("sortIndex") if entry_type == "TimelineTimelineItem": item_result = content.get("itemContent", {}).get("tweet_results", {}).get("result", {}) legacy = item_result.get("legacy") tweet_data = self.tweet_parser(user_id, full_name, tweet_id, item_result, legacy) _tweets.append(tweet_data) if entry_type == "TimelineTimelineCursor" and content.get("cursorType") == "Bottom": # NB: after 07/01 lock and unlock — no more cursor available if no login provided i.e. max. 100 tweets per username no more cursor = content.get("value") if len(_tweets) >= limit: # We do stop — once reached tweets limit provided by user break print(f"[#] tweets scraped: {len(_tweets)}") if len(_tweets) >= limit or cursor is None or len(entries) == 2: break return _tweets
4. Creating a CSV file
Getting the tweets is fine. But for now, they are in JSON format, with something that looks like this:
{ "tweet_url":"https://twitter.com/elonmusk/status/1647298658331770883", "name":"Elon Musk", "user_id":"44196397", "username":"elonmusk", "published_at":"Sat Apr 15 17:59:40 +0000 2023", "content":"Your direct experience, people you talk to in the subject area & independent research will get you much closer to the truth", "views_count":"7073534", "retweet_count":12977, "likes":124877, "quote_count":526, "reply_count":3455, "bookmarks_count":569 }
It's fantastic, but it's not easy to manipulate for someone who is not computer literate. So we'll kindly export these data in csv format. A format that is accessible to everyone, nerds and office geeks alike.
🤓
So first we'll generate the file name, using the timestamp in Unix format, and the username from which to retrieve the tweets:
import datetime timestamp = int(datetime.datetime.now().timestamp()) filename = '%s_%s.csv' % (self.username, timestamp) print('[+] writing %s' % filename)
And finally, we will use a DictWriter to elegantly convert our JSON dictionaries into .csv lines, as follows:
with open(filename, 'w') as f: writer = csv.DictWriter(f, fieldnames=FIELDNAMES, delimiter='\t') writer.writeheader() for tweet in tweets: print(tweet['id'], tweet['published_at']) writer.writerow(tweet)
If you need more information about creating .csv with Python, the reference documentation is readable (for once), and easily usable.
And here we are!
A nice csv file has now been saved in the folder where the .py file is, with the timestamp and the targeted username. Here, elonmusk of course.
And opening the file with Numbers, we get a nice file, with 100 neatly structured and directly usable tweets:
Wonderful!
5. Using dynamic variables
Well, if we want to scrape Elon's tweets. OK.
But what if we want to scrape someone else's tweets? I don't know, for example a former American president, addicted to the platform and banned for domestic political reasons?
Yes, in this part, we will see how to give flexibility to our script, and quickly retrieve the tweets of this man who is no longer introduced:
We are going to use the Python library argsparse, to be able to give, at the launching of our script two dynamic variables:
- username - the target username
- limit - the maximum number of tweets to retrieve
And to be able to modulate at the launch of the script the target of collection, and the volume of tweets to collect. Let's go!
First we import the library.
Then, in the last function main, we will generate the two attributes mentioned above - username and limit.
As follows:
import argparse … def main(): argparser = argparse.ArgumentParser() argparser.add_argument('--username', '-u', type=str, required=False, help='user to scrape tweets from', default='elonmusk') argparser.add_argument('--limit', '-l', type=int, required=False, help='max tweets to scrape', default=100) args = argparser.parse_args() username = args.username limit = args.limit
By default, we note that the default username is elonmusk, while the limit of tweets is 100. Owner takes all.
And then we instantiate our scraper, assigning it these two variables:
def main(): … twitter_scraper = TwitterScraper(username) tweets = twitter_scraper.iter_tweets(limit=limit) assert tweets twitter_scraper.generate_csv(tweets) print('''~~ success _ _ _ | | | | | | | | ___ | |__ ___| |_ __ __ | |/ _ \| '_ \/ __| __/| '__| | | (_) | |_) \__ \ |_ | | |_|\___/|_.__/|___/\__||_| ''')
That's it!
We can now launch a collection, by choosing precisely the target user, from which we are going to collect tweets.
In our console, we can use the command as follows:
$ python3 twitter_scraper.py --username realdonaldtrump --limit 10
We then recovered the last 10 tweets of the notorious president. Not too much. And all neatly stored in a .csv file, ready for use:
Please remember who got it done!!!
😭
Benefits
The script is functional, flexible, and immediately ready to use.
But what are the benefits, compared to a collection strategy via the official API?
First, the collection will be totally free. As presented in the introduction, since Elon Musk bought Twitter, access to the API costs an arm and a leg. It costs $100 per month, for 10,000 tweets per month. Not cheap.
With this script, we'll be able to retrieve tweets. For free.
On the other hand, the official API is limited. You can only send 180 requests every 15 minutes. With a maximum of 100 tweets per request, that makes 72k tweets per hour. That's not bad, but with over 500 million tweets posted every day, it's still limited. With this Python script, the collection of tweets not rate-limited.
Finally, with the Twitter Search API, you can only access tweets posted in the last 7 days Thanks to the script presented in this tutorial, the collection is no longer limited in time.
All is said.
Limitations
Be careful, this script has some clear limitations.
Main limitation is that, since the notorious Elon fury, you will be only able to retrieve the last 100 tweets of any user. No more.
Second, this script does not retrieve the message type. We have the message, but impossible to know if it is a direct tweet, a repost or a reply to another tweet.
Above all, the script only retrieves the text content of a message. Impossible to retrieve neither videos, nor format, nor images. For meme and Elon's insipirated shitpost we'll see.
Finally, this script is limited to the tweets of a user. You want to get the tweets from a hashtag (a bit outdated, but good) or from a twitter search? No way.
As you know, nothing is insurmountable for the most committed scrapers in their field. If you need additional features, you can contact us directly here.
FAQ
Is scraping on Twitter legal?
Yes, scraping on Twitter is completely legal. According to the French and European legislation, and in particular article l342-3 of the Intellectual Property Code, if a database is made available to the public, the public can extract data as long as it is a non-substantial part.
With over 900 million tweets posted every day, it goes without saying that the volume of tweets you will be able to retrieve with this tool will never be substantial.
Why not use the official API?
The official API is great!
It is well documented, and can withstand a large volume of requests without failing.
However, since Elon Musk bought Twitter, it costs an arm and a leg: you'll have to pay 100 USD per month, with up to 10 000 tweets retrieved. That's a lot of money for an MVP.
The script proposed in this tutorial is entirely free.
If I run this script in a month, will it work?
Unless you modify the code from the platform, yes! We have built this script to stand the test of time.
If this script doesn't work anymore, don't hesitate to contact us via the chat, or via our contact form here.
I don't know how to code, is there a no-code solution?
Yes, here it is!
- 500 tweets per minute
- no limitation
- up to 10 concurrent threads
- 40+ attributes
Guys. Definitely the best no-code scraper in town. Accessible here.
Conclusion
And that's it, this article is over!
In this tutorial, we have seen how to scrape directly from the internal API of tweeter, as many tweets as needed. And that without spending a single euro and without any limitation.
If you need advanced features, or a larger scope of data points, you can of course always contact us right here.
Happy scraping!
🦀