Comment scraper Leboncoin rapidement et sans effort?
(updated)
Overview
Au-delà du volume colossal, chaque annonce sur leboncoin est une mine exceptionnelle d'informations. Sur une annonce immobilière, on y retrouve pêle-mêle : le titre de l’annonce, les images, le prix du bien, la localisation, le nombre de pièces, etc.
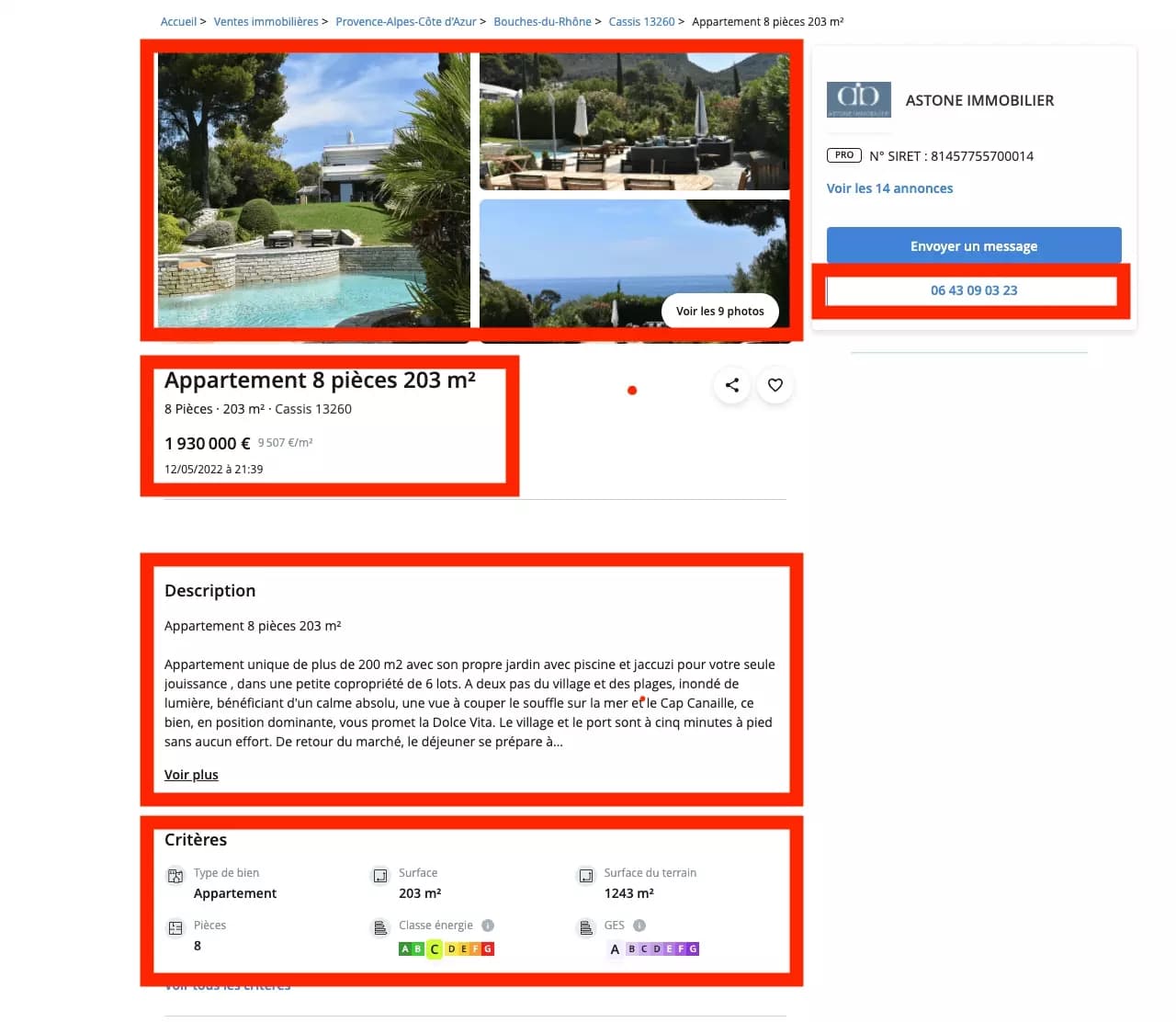
Target
Pour obtenir des données, il vous suffit de définir une URL de recherche sur leboncoin (utiliser l’ensemble des critères de recherche de votre choix, puis conserver l’URL).
Par exemple, toutes les maisons à louer à Cassis, dans le sud de la France, cet été :
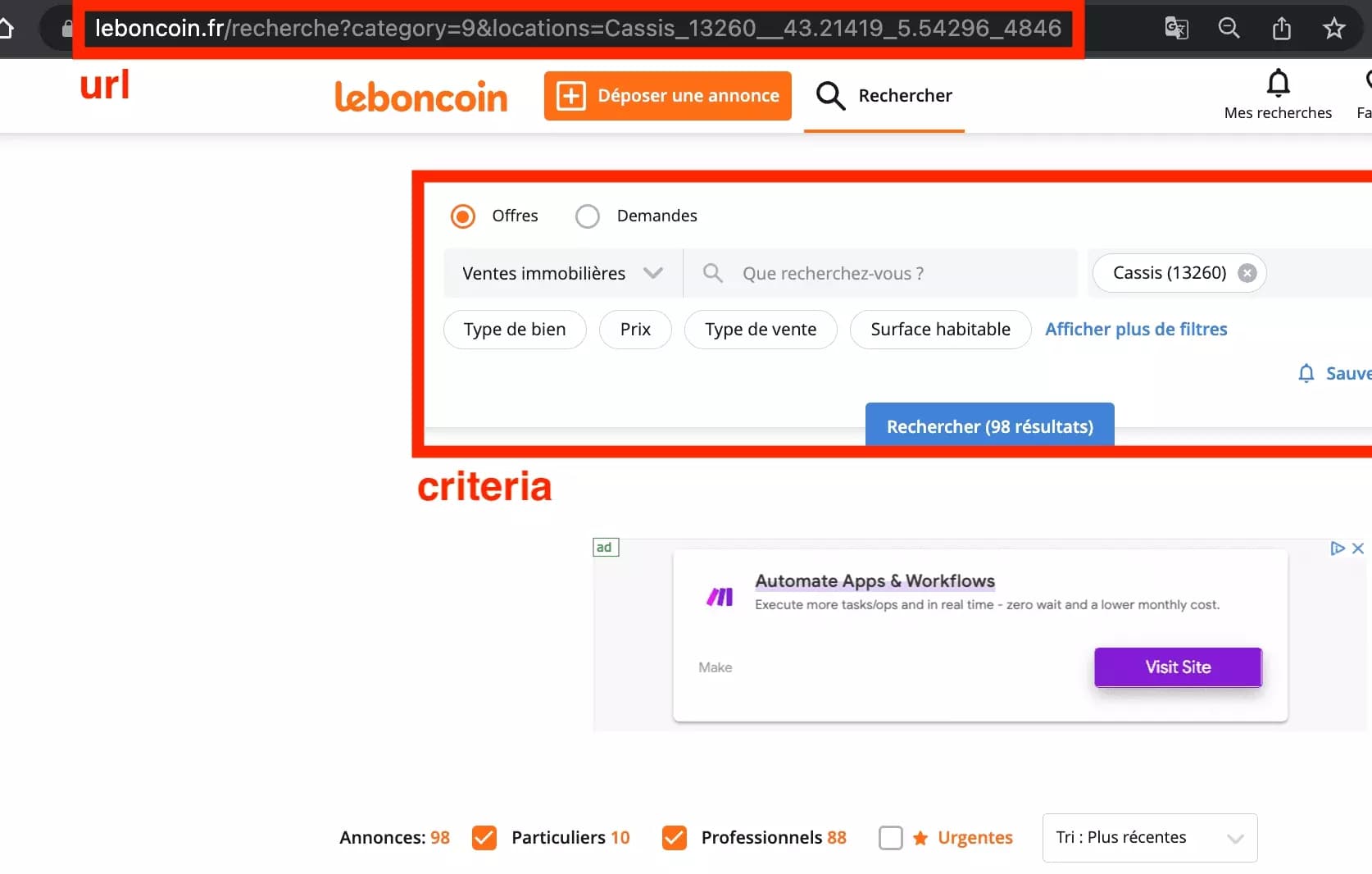
Ce qui nous donne cet URL de recerche ensoleillé :
🌞
Setup
Pour récupérer ces données, il existe un outil en ligne, accessible depuis une interface simple :

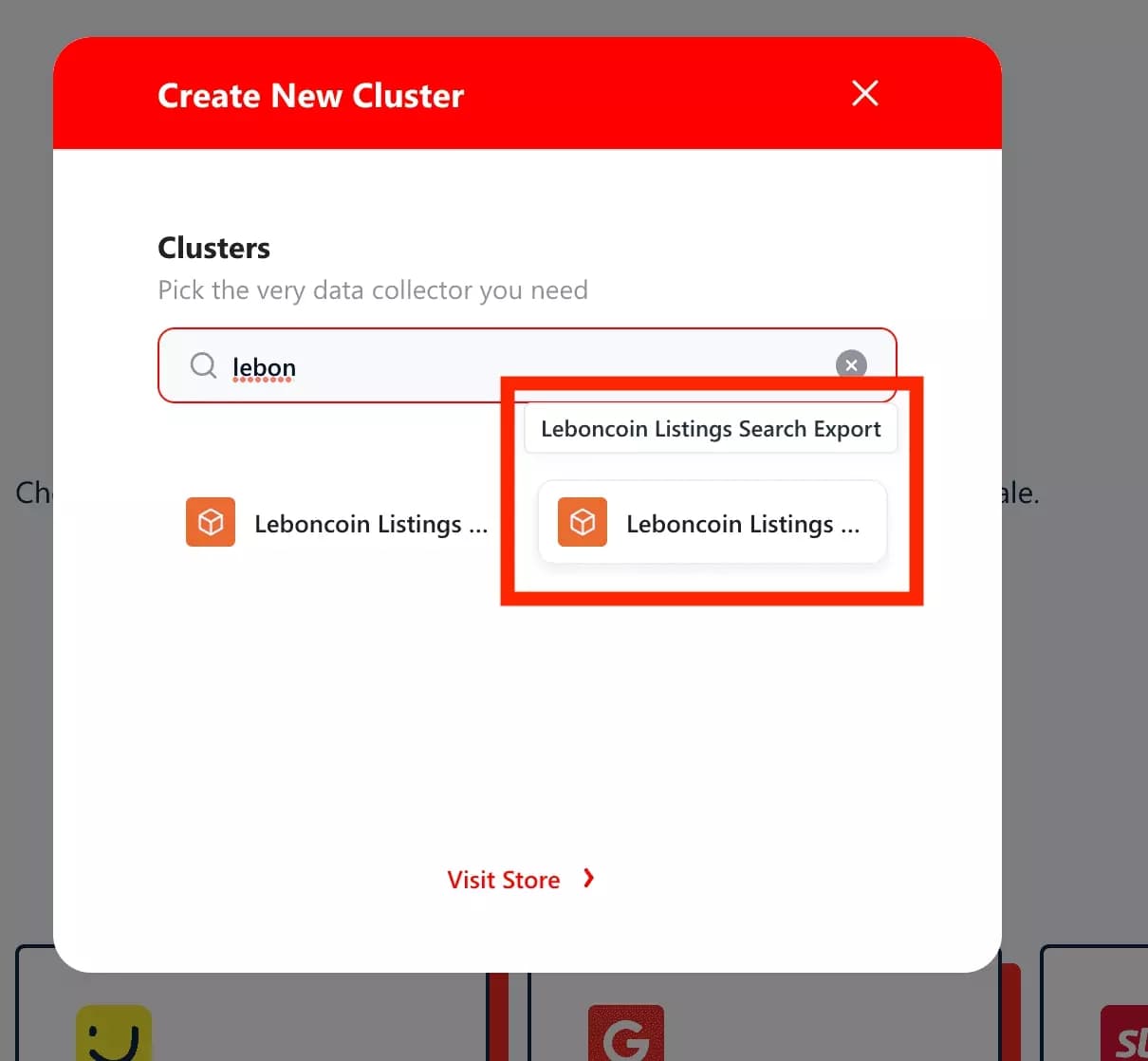
Remarque : Il existe également une version permettant de récupérer les coordonnées téléphoniques. Dans ce cas, il faut fournir un compte leboncoin valide et être muni à minima d'un abonnement premium.
Launch
Une fois le squid créé, il suffit de :
- Renseigner l’URL de recherche (définie plus haut).
- Préciser la période depuis laquelle vous souhaitez récupérer des annonces.
- Cliquer sur Save.
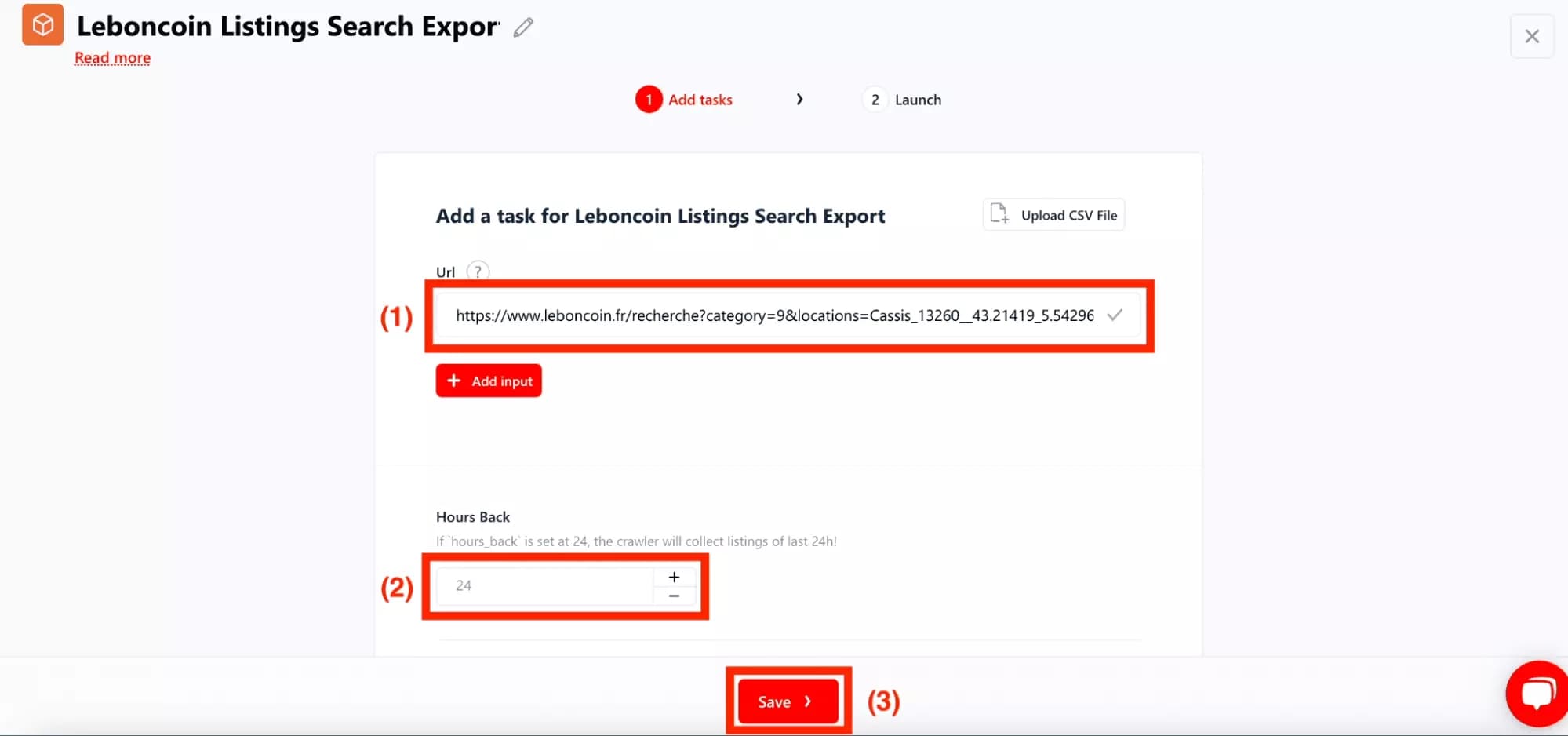
Enjoy
Quelques minutes plus tard, vous obtenez des données structurées (titre de l’annonce, prix, lieu, images, etc.) que vous pouvez télécharger en un clic.
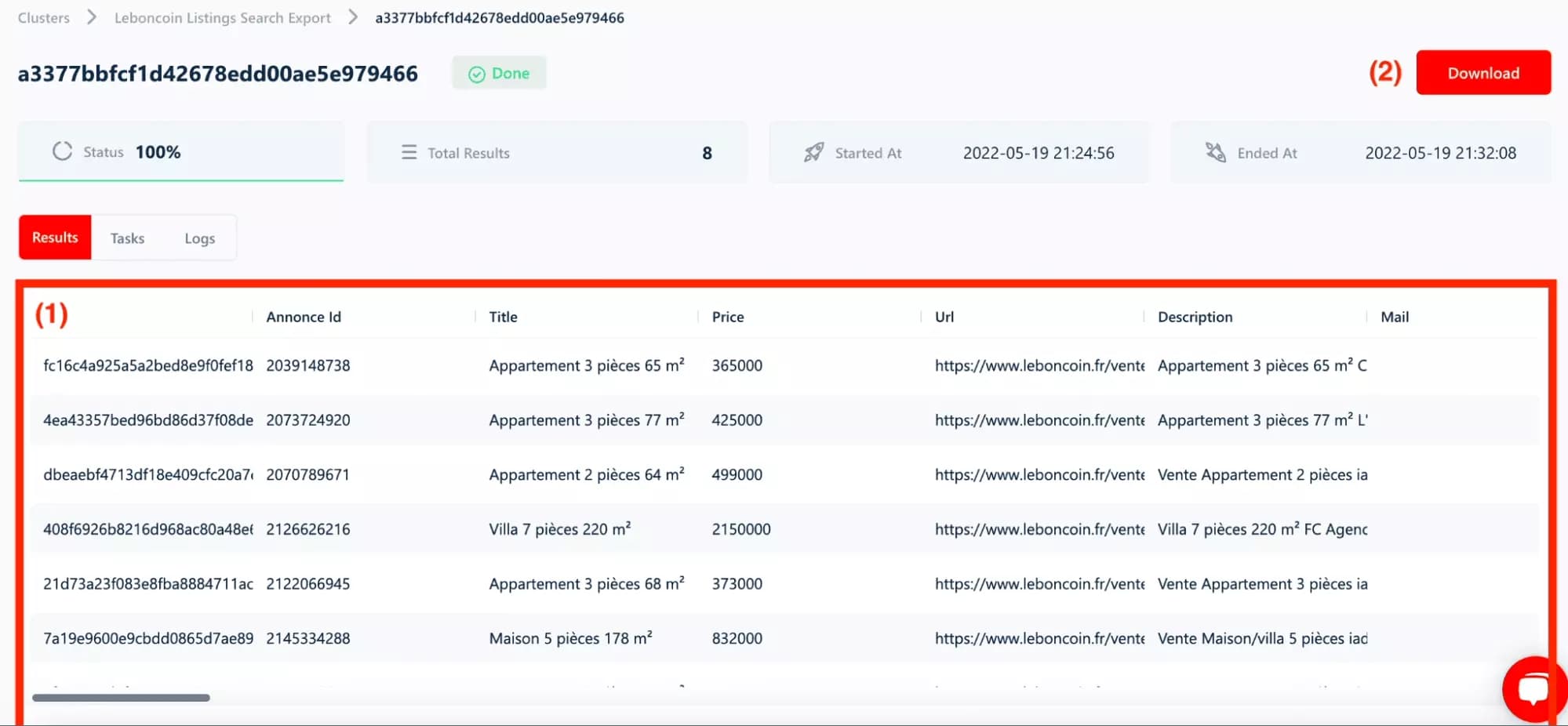
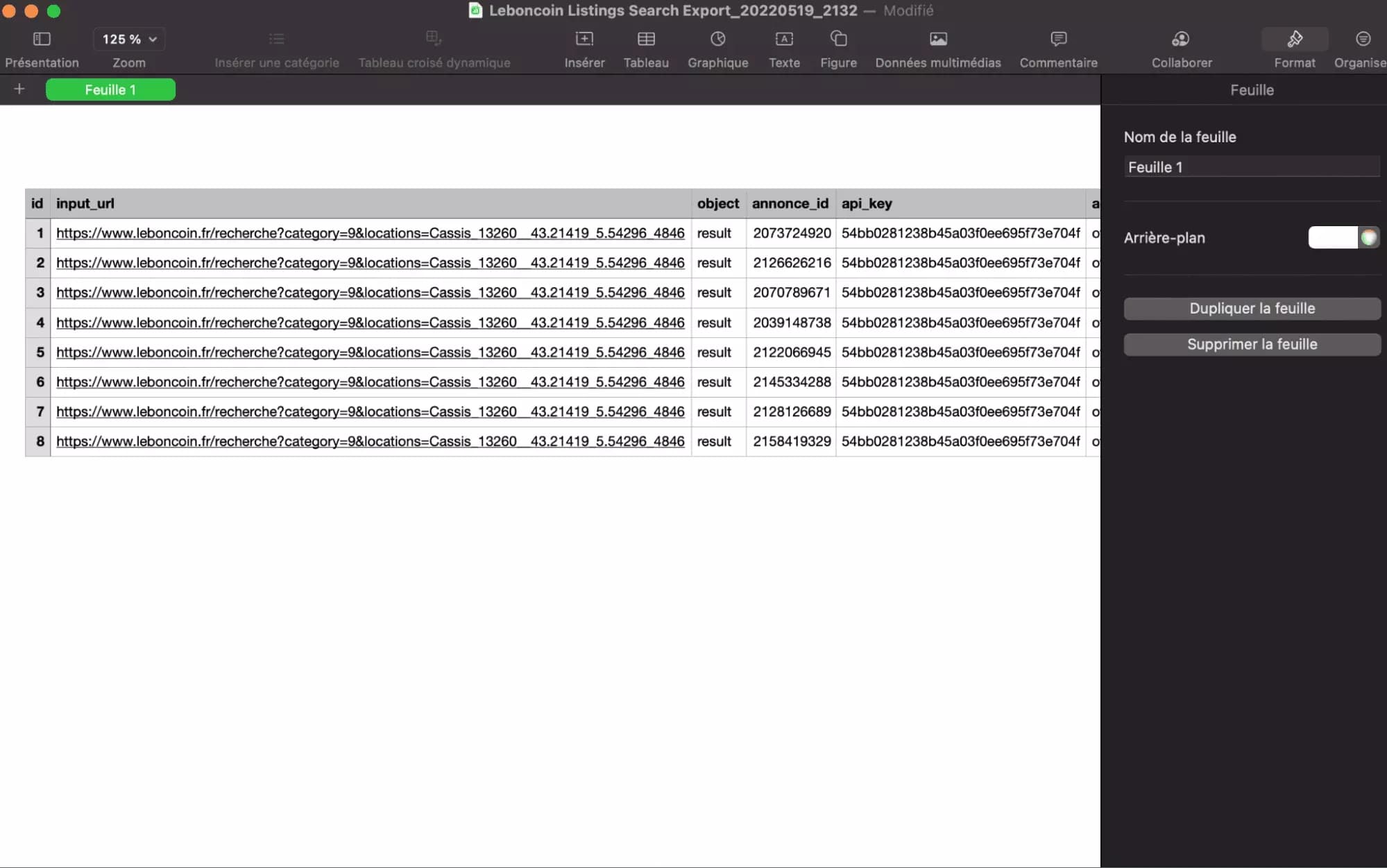
Une fois ouvertes dans votre tableur préféré (Numbers, Excel, Google Sheets…), les annonces s’affichent de manière lisible, prêtes à être exploitées.
Abonnement Premium
- À partir de 50 EUR par mois
- Jusqu’à 5 000 annonces par jour
Conclusion
Happy scraping !
🦞