
Comment scraper des Tweets gratos avec Python et requests en 2023?
Attention, avant il était possible de collecter tous les tweets de n'importe quel utilisateur sans aucune limitation. Suite à la mise à jour citée plus haut, seuls les 100 premiers tweets sont accessibles sans login. Et c'est déjà beaucoup. À utiliser avec précaution.
Prérequis
Avec une simple commande comme suit:
$ pip3 install requestsf
Done.
Code complet
Le code complet est disponible ci-dessous, et sur Github ici.
# ============================================================================= # Title: Twitter Users Tweets Scraper # Language: Python # Description: This script does scrape the first 100 tweets # of any Twitter User. # Author: Sasha Bouloudnine # Date: 2023-08-08 # # Usage: # - Make sure you have the required libraries installed by running: # `pip install requests` # - Run the script using `python twitter_scraper.py`. # - Use the dynamic variables: # - `--username` to specify the Twitter username from which to scrape tweets. # - `--limit` to set the maximum number of tweets to scrape. # # Notes: # - As of July 1st, 2023, Twitter removed public access to user tweets. # - Starting from August 1st, 2023, the script is no longer constrained by the limit # but can collect a maximum of 100 tweets per user. # # ============================================================================= import csv import json import requests import argparse import datetime import time import re # First request default headers DEFAULT_HEADERS ={ 'authority': 'twitter.com', 'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7', 'accept-language': 'fr-FR,fr;q=0.9', 'cache-control': 'max-age=0', 'sec-ch-ua': '"Not_A Brand";v="8", "Chromium";v="120", "Google Chrome";v="120"', 'sec-ch-ua-mobile': '?0', 'sec-ch-ua-platform': '"macOS"', 'sec-fetch-dest': 'document', 'sec-fetch-mode': 'navigate', 'sec-fetch-site': 'same-origin', 'sec-fetch-user': '?1', 'upgrade-insecure-requests': '1', 'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36', } # All values stored here are constant, copy-pasted from the website FEATURES_USER = '{"hidden_profile_likes_enabled":false,"hidden_profile_subscriptions_enabled":true,"responsive_web_graphql_exclude_directive_enabled":true,"verified_phone_label_enabled":false,"subscriptions_verification_info_is_identity_verified_enabled":false,"subscriptions_verification_info_verified_since_enabled":true,"highlights_tweets_tab_ui_enabled":true,"creator_subscriptions_tweet_preview_api_enabled":true,"responsive_web_graphql_skip_user_profile_image_extensions_enabled":false,"responsive_web_graphql_timeline_navigation_enabled":true}' FEATURES_TWEETS = '{"rweb_lists_timeline_redesign_enabled":true,"responsive_web_graphql_exclude_directive_enabled":true,"verified_phone_label_enabled":false,"creator_subscriptions_tweet_preview_api_enabled":true,"responsive_web_graphql_timeline_navigation_enabled":true,"responsive_web_graphql_skip_user_profile_image_extensions_enabled":false,"tweetypie_unmention_optimization_enabled":true,"responsive_web_edit_tweet_api_enabled":true,"graphql_is_translatable_rweb_tweet_is_translatable_enabled":true,"view_counts_everywhere_api_enabled":true,"longform_notetweets_consumption_enabled":true,"responsive_web_twitter_article_tweet_consumption_enabled":false,"tweet_awards_web_tipping_enabled":false,"freedom_of_speech_not_reach_fetch_enabled":true,"standardized_nudges_misinfo":true,"tweet_with_visibility_results_prefer_gql_limited_actions_policy_enabled":true,"longform_notetweets_rich_text_read_enabled":true,"longform_notetweets_inline_media_enabled":true,"responsive_web_media_download_video_enabled":false,"responsive_web_enhance_cards_enabled":false}' AUTHORIZATION_TOKEN = 'AAAAAAAAAAAAAAAAAAAAANRILgAAAAAAnNwIzUejRCOuH5E6I8xnZz4puTs%3D1Zv7ttfk8LF81IUq16cHjhLTvJu4FA33AGWWjCpTnA' HEADERS = { 'authorization': 'Bearer %s' % AUTHORIZATION_TOKEN, # The Bearer value is a fixed value that is copy-pasted from the website # 'x-guest-token': None, } GET_USER_URL = 'https://twitter.com/i/api/graphql/SAMkL5y_N9pmahSw8yy6gw/UserByScreenName' GET_TWEETS_URL = 'https://twitter.com/i/api/graphql/XicnWRbyQ3WgVY__VataBQ/UserTweets' FIELDNAMES = ['id', 'tweet_url', 'name', 'user_id', 'username', 'published_at', 'content', 'views_count', 'retweet_count', 'likes', 'quote_count', 'reply_count', 'bookmarks_count', 'medias'] class TwitterScraper: def __init__(self, username): # We do initiate requests Session, and we get the `guest-token` from the HomePage resp = requests.get("https://twitter.com/", headers=DEFAULT_HEADERS) self.gt = resp.cookies.get_dict().get("gt") or "".join(re.findall(r'(?<=\"gt\=)[^;]+', resp.text)) assert self.gt HEADERS['x-guest-token'] = getattr(self, 'gt') # assert self.guest_token self.HEADERS = HEADERS assert username self.username = username def get_user(self): # We recover the user_id required to go ahead arg = {"screen_name": self.username, "withSafetyModeUserFields": True} params = { 'variables': json.dumps(arg), 'features': FEATURES_USER, } response = requests.get( GET_USER_URL, params=params, headers=self.HEADERS ) try: json_response = response.json() except requests.exceptions.JSONDecodeError: print(response.status_code) print(response.text) raise result = json_response.get("data", {}).get("user", {}).get("result", {}) legacy = result.get("legacy", {}) return { "id": result.get("rest_id"), "username": self.username, "full_name": legacy.get("name") } def tweet_parser( self, user_id, full_name, tweet_id, item_result, legacy ): # It's a static method to parse from a tweet medias = legacy.get("entities").get("media") medias = ", ".join(["%s (%s)" % (d.get("media_url_https"), d.get('type')) for d in legacy.get("entities").get("media")]) if medias else None return { "id": tweet_id, "tweet_url": f"https://twitter.com/{self.username}/status/{tweet_id}", "name": full_name, "user_id": user_id, "username": self.username, "published_at": legacy.get("created_at"), "content": legacy.get("full_text"), "views_count": item_result.get("views", {}).get("count"), "retweet_count": legacy.get("retweet_count"), "likes": legacy.get("favorite_count"), "quote_count": legacy.get("quote_count"), "reply_count": legacy.get("reply_count"), "bookmarks_count": legacy.get("bookmark_count"), "medias": medias } def iter_tweets(self, limit=120): # The main navigation method print(f"[+] scraping: {self.username}") _user = self.get_user() full_name = _user.get("full_name") user_id = _user.get("id") if not user_id: print("/!\\ error: no user id found") raise NotImplementedError cursor = None _tweets = [] while True: var = { "userId": user_id, "count": 100, "cursor": cursor, "includePromotedContent": True, "withQuickPromoteEligibilityTweetFields": True, "withVoice": True, "withV2Timeline": True } params = { 'variables': json.dumps(var), 'features': FEATURES_TWEETS, } response = requests.get( GET_TWEETS_URL, params=params, headers=self.HEADERS, ) json_response = response.json() result = json_response.get("data", {}).get("user", {}).get("result", {}) timeline = result.get("timeline_v2", {}).get("timeline", {}).get("instructions", {}) entries = [x.get("entries") for x in timeline if x.get("type") == "TimelineAddEntries"] entries = entries[0] if entries else [] for entry in entries: content = entry.get("content") entry_type = content.get("entryType") tweet_id = entry.get("sortIndex") if entry_type == "TimelineTimelineItem": item_result = content.get("itemContent", {}).get("tweet_results", {}).get("result", {}) legacy = item_result.get("legacy") tweet_data = self.tweet_parser(user_id, full_name, tweet_id, item_result, legacy) _tweets.append(tweet_data) if entry_type == "TimelineTimelineCursor" and content.get("cursorType") == "Bottom": # NB: after 07/01 lock and unlock — no more cursor available if no login provided i.e. max. 100 tweets per username no more cursor = content.get("value") if len(_tweets) >= limit: # We do stop — once reached tweets limit provided by user break print(f"[#] tweets scraped: {len(_tweets)}") if len(_tweets) >= limit or cursor is None or len(entries) == 2: break return _tweets def generate_csv(self, tweets=[]): import datetime timestamp = int(datetime.datetime.now().timestamp()) filename = '%s_%s.csv' % (self.username, timestamp) print('[+] writing %s' % filename) with open(filename, 'w') as f: writer = csv.DictWriter(f, fieldnames=FIELDNAMES, delimiter='\t') writer.writeheader() for tweet in tweets: print(tweet['id'], tweet['published_at']) writer.writerow(tweet) def main(): print('start') s = time.perf_counter() argparser = argparse.ArgumentParser() argparser.add_argument('--username', '-u', type=str, required=False, help='user to scrape tweets from', default='elonmusk') argparser.add_argument('--limit', '-l', type=int, required=False, help='max tweets to scrape', default=100) args = argparser.parse_args() username = args.username limit = args.limit assert all([username, limit]) twitter_scraper = TwitterScraper(username) tweets = twitter_scraper.iter_tweets(limit=limit) assert tweets twitter_scraper.generate_csv(tweets) print('elapsed %s' % (time.perf_counter()-s)) print('''~~ success _ _ _ | | | | | | | | ___ | |__ ___| |_ __ __ | |/ _ \| '_ \/ __| __/| '__| | | (_) | |_) \__ \ |_ | | |_|\___/|_.__/|___/\__||_| ''') if __name__ == '__main__': main()f
Pour utiliser le script, c’est très simple, téléchargez le script .py.
Et dans votre console, utilisez la commande suivante:
python3 twitter_scraper.py --username elonmusk --limit 100f
Vous allez télécharger les 100 tweets les plus récents de l'inévitable Elon.
Vous pouvez bien entendu modifier le nom de l’utilisateur, et la limite, pour télécharger autant de tweets que nécessaire, depuis n’importe quel utilisateur sur Twitter.
🐦
Tutoriel Complet
Avec les attributs suivants:
- nom
- nom d’utilisateur
- date de publication
- contenu
- nombre de vues
- nombre de retweets
- nombre de likes
- nombre de bookmarks
- nombre de retweets
- nombre de réponses
Intuitivement, on peut jeter ces quelques lignes de code simples:
import requests s = requests.Session() r = s.get('https://twitter.com/elonmusk') with open('test.html', 'w') as f: f.write(r.text)f
Mais en ouvrant le fichier, aucune donnée.
Ça ne fonctionne pas:
Il va donc falloir s’y prendre autrement.
Ce tutoriel guidé va se passer en 5 étapes:
- Reverse Engineering
- Récupération du user-id et du x-guest-token
- Pagination des Tweets
- Création d’un fichier CSV
- Utilisation de variables dynamiques
Allons-y.
1. Reverse Engineering
C’est que le navigateur fonctionne en plusieurs étapes:
- l’URL de la page est visité https://twitter.com/elonmusk
- des requêtes sont effectuées en arrière plan
On va donc utiliser l’outil d’inspection pour observer les requêtes silencieuses qui sont échangées entre le navigateur et le site, et ensuite les reproduire au sein de notre code Python.
On commence par ouvrir l’outil d’inspection:
Puis on ouvre la partie Network:
Enfin, on se rend sur l’URL cible.
A partir d’ici, plus de 250 requêtes apparaissent. Comment identifier la requête qui permet d’accéder aux tweets?
Et bien c’est très simple, avec l’outil Recherche du Network de l’outil d’inspection, on tape le contenu d’un tweet. L’outil va nous rediriger vers la requête originelle, qui contient le contenu que l’on souhaite récupérer programmatiquement.
Et bingo!
La requête initiale apparaît, simple et claire:
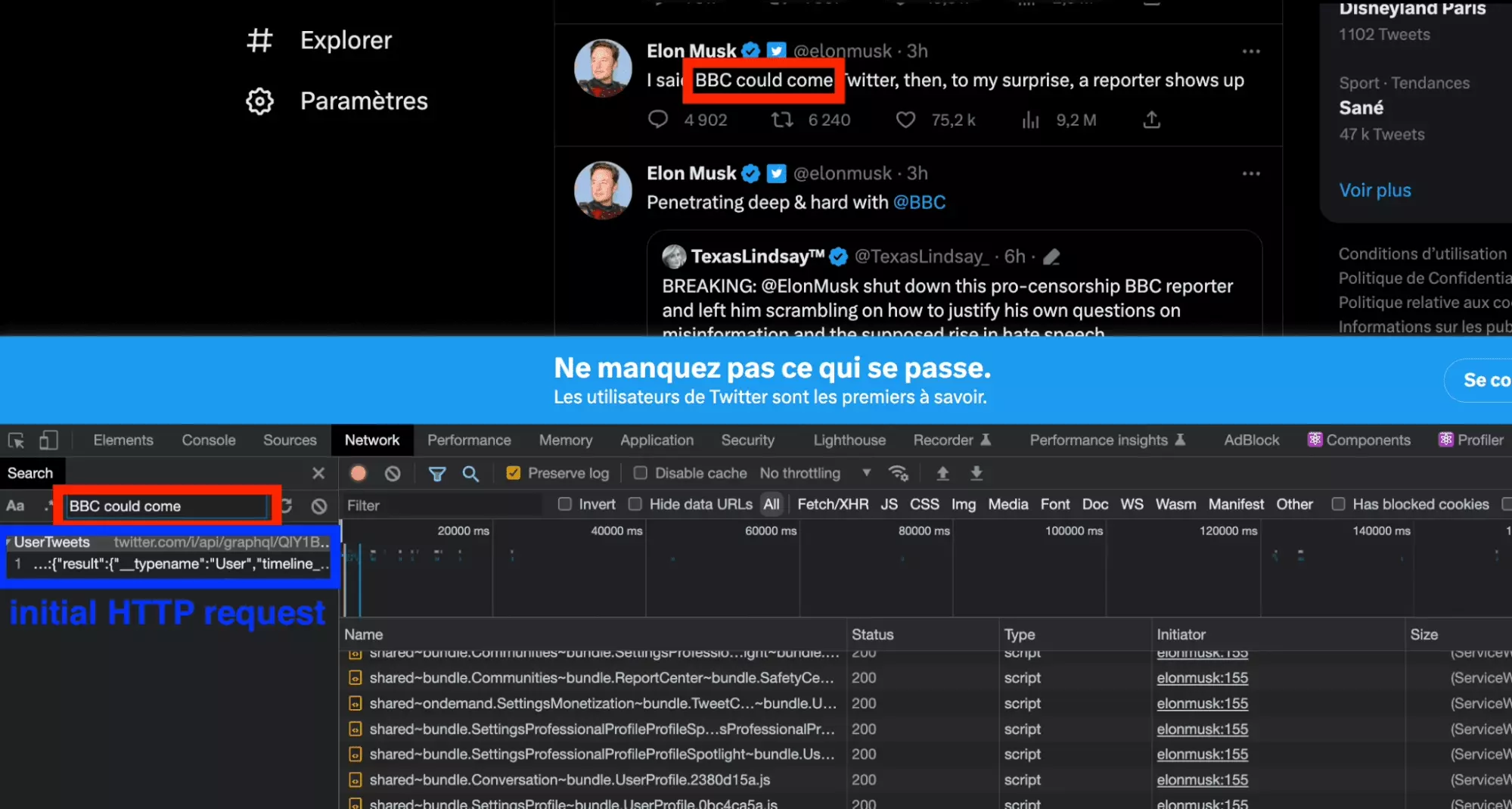
On a un code complet et exhaustif. En supprimant les variables non essentielles, voilà ce qu’on obtient:
import requests headers = { 'authority': 'twitter.com', 'accept': '*/*', 'accept-language': 'fr-FR,fr;q=0.9,en-US;q=0.8,en;q=0.7', 'authorization': 'Bearer AAAAAAAAAAAAAAAAAAAAANRILgAAAAAAnNwIzUejRCOuH5E6I8xnZz4puTs%3D1Zv7ttfk8LF81IUq16cHjhLTvJu4FA33AGWWjCpTnA', 'content-type': 'application/json', 'sec-ch-ua': '"Chromium";v="112", "Google Chrome";v="112", "Not:A-Brand";v="99"', 'sec-ch-ua-mobile': '?0', 'sec-ch-ua-platform': '"macOS"', 'sec-fetch-dest': 'empty', 'sec-fetch-mode': 'cors', 'sec-fetch-site': 'same-origin', 'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36', 'x-guest-token': '1646107729780416513', 'x-twitter-active-user': 'yes', 'x-twitter-client-language': 'fr', } params = { 'variables': '{"userId":"44196397","count":40,"includePromotedContent":true,"withQuickPromoteEligibilityTweetFields":true,"withDownvotePerspective":false,"withVoice":true,"withV2Timeline":true}', 'features': '{"blue_business_profile_image_shape_enabled":false,"responsive_web_graphql_exclude_directive_enabled":true,"verified_phone_label_enabled":false,"responsive_web_graphql_timeline_navigation_enabled":true,"responsive_web_graphql_skip_user_profile_image_extensions_enabled":false,"tweetypie_unmention_optimization_enabled":true,"vibe_api_enabled":true,"responsive_web_edit_tweet_api_enabled":true,"graphql_is_translatable_rweb_tweet_is_translatable_enabled":true,"view_counts_everywhere_api_enabled":true,"longform_notetweets_consumption_enabled":true,"tweet_awards_web_tipping_enabled":false,"freedom_of_speech_not_reach_fetch_enabled":false,"standardized_nudges_misinfo":true,"tweet_with_visibility_results_prefer_gql_limited_actions_policy_enabled":false,"interactive_text_enabled":true,"responsive_web_text_conversations_enabled":false,"longform_notetweets_rich_text_read_enabled":false,"responsive_web_enhance_cards_enabled":false}', } response = requests.get( 'https://twitter.com/i/api/graphql/XicnWRbyQ3WgVY__VataBQ/UserTweets', params=params, cookies=cookies, headers=headers, ) print(response.json())f
Et si on exécute ce code, ça marche! On obtient un joli JSON, avec l’ensemble des données, qu’il va ensuite falloir parser.
Facile.
Toutefois, si on lance le script quelques jours plus tard, voilà ce qui arrive:
$ python3 twitter_scraper.py {'errors': [{'message': 'Bad guest token', 'code': 239}]}f
Il va falloir améliorer encore notre outil.
2. Récupération du user-id et du x-guest-token
Dans le code fourni dans la première partie, on remarque la présence des variables suivantes, codées en dur :
- la valeur du header 'authorization'
- la valeur du header 'x-guest-token'
- la valeur du 'user-id'
Bonne nouvelle, la valeur du header 'authorization' est fixe dans le temps.
On va donc l’ajouter en haut de code, en lettres majuscules, pour en faciliter le traitement.
AUTHORIZATION_TOKEN = 'AAAAAAAAAAAAAAAAAAAAANRILgAAAAAAnNwIzUejRCOuH5E6I8xnZz4puTs%3D1Zv7ttfk8LF81IUq16cHjhLTvJu4FA33AGWWjCpTnA'f
Dès lors comment récupérer les 2 autres variables?
a. x-guest-token
En utilisant à nouveau la partie Network de l’outil d’inspection, il apparaît que cette variable est simplement fournie par le site, lorsqu’on visite la première page.
Le token apparaît alors à deux endroits distincts:
- via un cookie
- présent dans le response.text en dur
Dans le premier cas, la valeur se trouve dans un cookie directement retourné par le site:
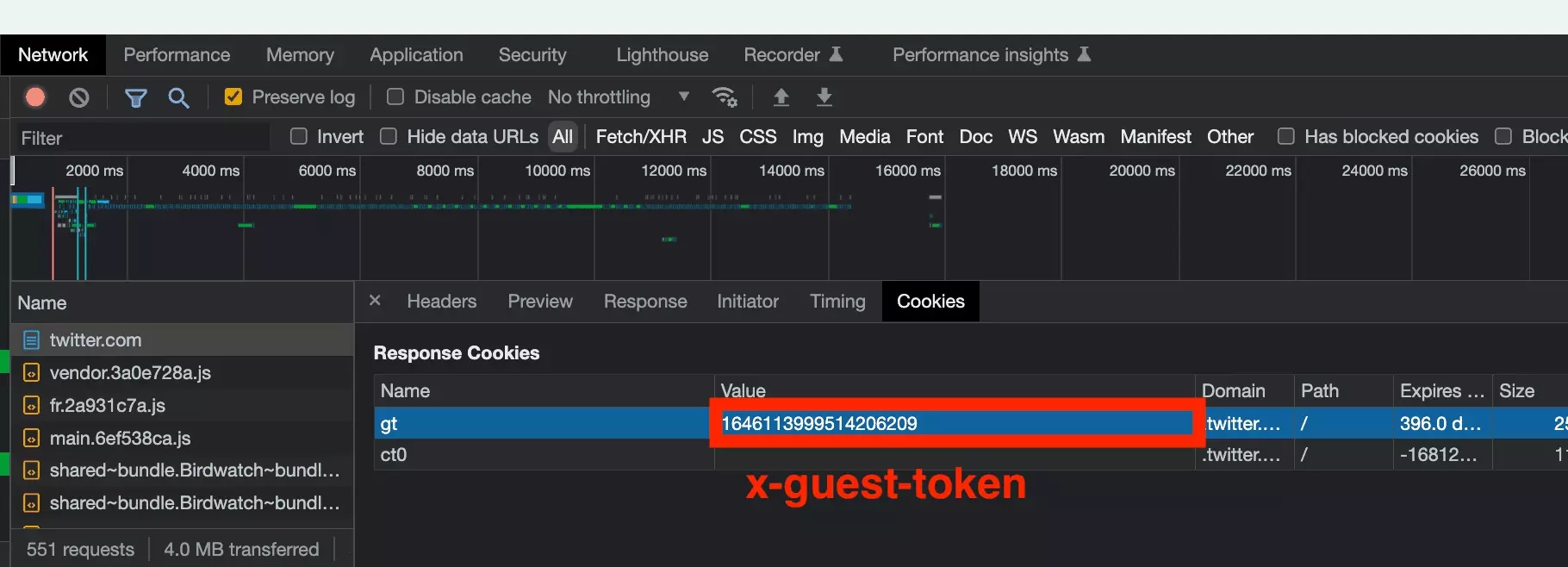
On va donc simplement visiter la page d’accueil du site au début du script, récupérer la valeur du token présent dans le cookie, et l’attacher au header de notre session de requête.
guest_token = resp.cookies.get_dict().get("gt")f
Dans le second cas, la valeur du cookie soit présente dans le texte de la réponse, caché entre la chaîne de caractère 'gt' et un point virgule.
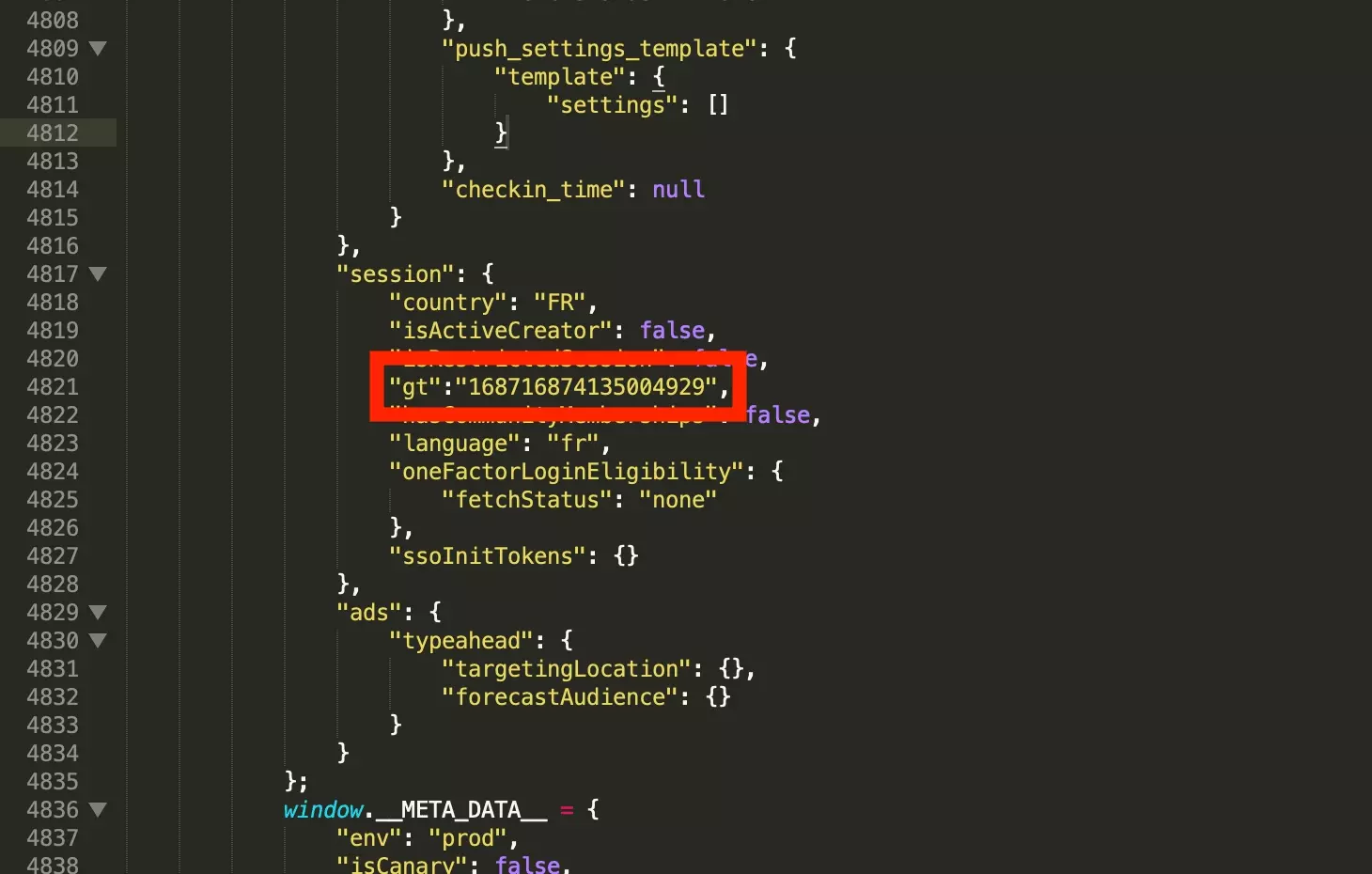
guest_token = "".join(re.findall(r'(?<=\"gt\=)[^;]+', text))f
Et donc le code complet d'initialisation pour aller récupérer le x-guest-token à tous les coups:
HEADERS = { 'authority': 'twitter.com', 'accept': '*/*', 'accept-language': 'en-US,en;q=0.9', 'authorization': 'Bearer %s' % AUTHORIZATION_TOKEN, # The Bearer value is a fixed value that is copy-pasted from the website 'content-type': 'application/json', 'sec-ch-ua': '"Google Chrome";v="111", "Not(A:Brand";v="8", "Chromium";v="111"', 'sec-ch-ua-mobile': '?0', 'sec-ch-ua-platform': '"Windows"', 'sec-fetch-dest': 'empty', 'sec-fetch-mode': 'cors', 'sec-fetch-site': 'same-origin', 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36', # 'x-guest-token': None, 'x-twitter-active-user': 'yes', # yes 'x-twitter-client-language': 'en', } class TwitterScraper: def __init__(self): # We do initiate requests Session, and we get the `guest-token` from the HomePage resp = requests.get("https://twitter.com/") text = resp.text assert text self.guest_token = resp.cookies.get_dict().get("gt") or "".join(re.findall(r'(?<=\"gt\=)[^;]+', text)) assert self.guest_token HEADERS['x-guest-token'] = self.guest_token self.HEADERS = HEADERSf
Problème réglé.
Il est temps de passer à la variable suivante: le 'user-id'.
b. user-id
Elon, l’inévitable homme le plus riche du monde, a le 'user-id' suivant: 44196397
Mais comment trouver le user-id d’un autre utilisateur, et ainsi pouvoir compter sur un code souple et résilient?
Avec la même méthode que précédemment, il apparaît que cet élément est récupéré lors d’une précédente requête: UserByScreenName.
En entrée, on fournit le nom d’utilisateur: elonmusk. Et en sortie, on récupère le user-id: 44196397.
Top!
Et voilà la partie du code en Python:
GET_USER_URL = 'https://twitter.com/i/api/graphql/SAMkL5y_N9pmahSw8yy6gw/UserByScreenName' def get_user(self, username): # We recover the user_id required to go ahead arg = {"screen_name": username, "withSafetyModeUserFields": True} params = { 'variables': json.dumps(arg), 'features': FEATURES, } response = requests.get( GET_USER_URL, params=params, headers=self.HEADERS ) json_response = response.json() result = json_response.get("data", {}).get("user", {}).get("result", {}) legacy = result.get("legacy", {}) user_id = result.get("rest_id") return user_idf
On a donc maintenant le x-guest-token, et le user-id. À partir du nom d’utilisateur, on peut donc récupérer les tweets.
Et lorsqu’on lance le programme, ça marche!
$ python3 twitter_scraper.py [+] scraping: elonmusk [#] tweets scraped: 16 ~ donef
Mais on n’a collecté que 16 tweets. Pas ouf. Il va maintenant falloir prendre en charge la pagination.
3. Pagination des Tweets
Suite au coup de gueule d'Elon le 1er juillet 2023, il est désormais impossible de paginer sans login. Dès lors, cette section est obsolète.
On sait que les tweets sont récupérés à partir de l’URL suivant: UserTweets.
On retourne donc sur la page de mister musk, on ouvre l’onglet Network de l’outil d’inspection (encore), et on scrolle vers le bas pour que de nouveaux tweets apparaissent.
Avec cette seconde requête, et en la comparant avec la première, on va pouvoir comprendre ce qui permet le passage de l’un à l’autre :
En ouvrant la partie Payload de la seconde requête, un élément supplémentaire a été ajouté: le cursor.
Et twitter fonctionne effectivement avec une pagination avec curseur. Il s’agit d’une valeur, associé au dernier élément d’une liste, et qui permet de retrouver les éléments qui se trouvent après et avant. Une pagination précise et dynamique!
Il suffit donc désormais de récupérer le curseur présent dans la réponse de la première requête:
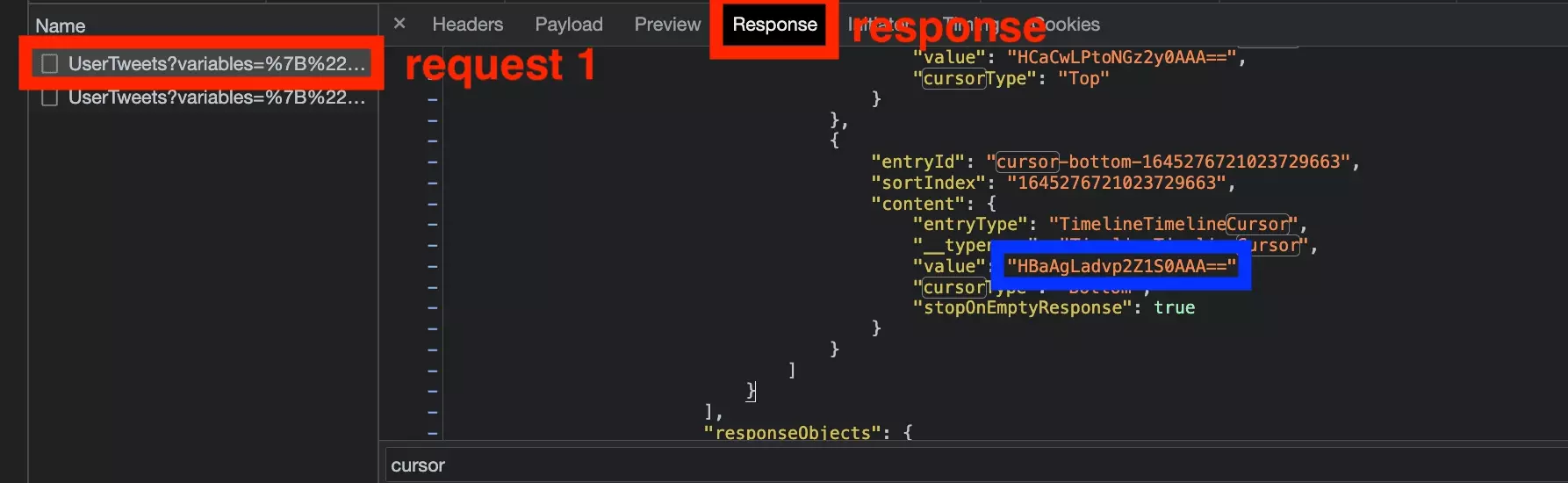
Et de l’insérer dans le payload de la seconde requête:
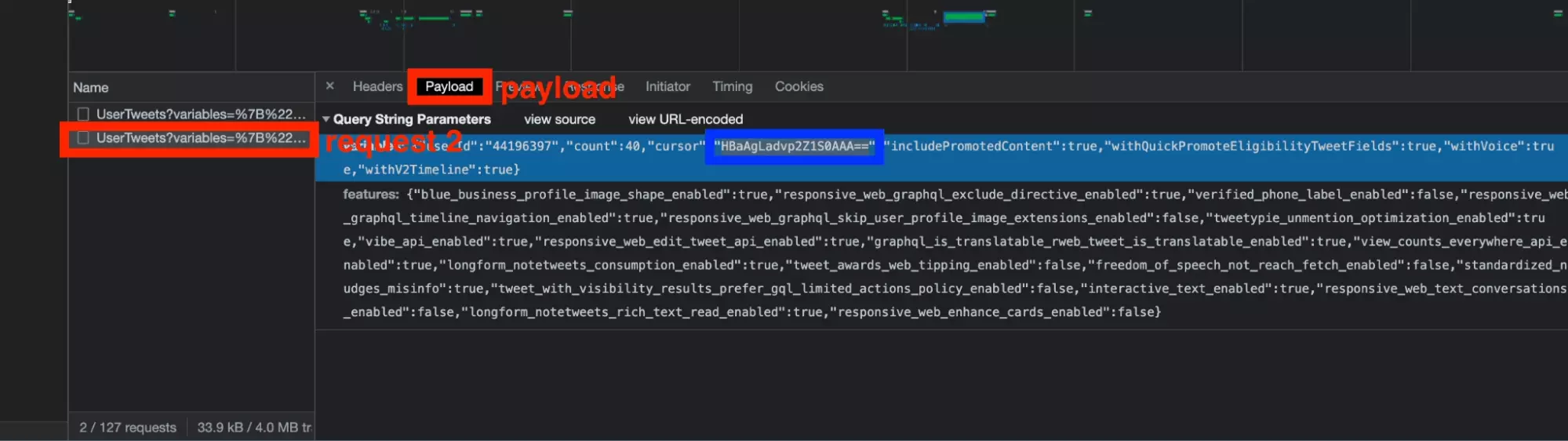
Et voilà, le tour est joué.
On peut maintenant passer d’une page à l’autre, et récupérer plusieurs pages de tweets.
Voilà le code complet:
GET_TWEETS_URL = 'https://twitter.com/i/api/graphql/XicnWRbyQ3WgVY__VataBQ/UserTweets' … def iter_tweets(self, limit=120): # The main navigation method print(f"[+] scraping: {self.username}") _user = self.get_user() full_name = _user.get("full_name") user_id = _user.get("id") if not user_id: print("/!\\ error: no user id found") raise NotImplementedError cursor = None _tweets = [] while True: var = { "userId": user_id, "count": 100, "cursor": cursor, "includePromotedContent": True, "withQuickPromoteEligibilityTweetFields": True, "withVoice": True, "withV2Timeline": True } params = { 'variables': json.dumps(var), 'features': FEATURES_TWEETS, } response = requests.get( GET_TWEETS_URL, params=params, headers=self.HEADERS, ) json_response = response.json() result = json_response.get("data", {}).get("user", {}).get("result", {}) timeline = result.get("timeline_v2", {}).get("timeline", {}).get("instructions", {}) entries = [x.get("entries") for x in timeline if x.get("type") == "TimelineAddEntries"] entries = entries[0] if entries else [] for entry in entries: content = entry.get("content") entry_type = content.get("entryType") tweet_id = entry.get("sortIndex") if entry_type == "TimelineTimelineItem": item_result = content.get("itemContent", {}).get("tweet_results", {}).get("result", {}) legacy = item_result.get("legacy") tweet_data = self.tweet_parser(user_id, full_name, tweet_id, item_result, legacy) _tweets.append(tweet_data) if entry_type == "TimelineTimelineCursor" and content.get("cursorType") == "Bottom": # NB: after 07/01 lock and unlock — no more cursor available if no login provided i.e. max. 100 tweets per username no more cursor = content.get("value") if len(_tweets) >= limit: # We do stop — once reached tweets limit provided by user break print(f"[#] tweets scraped: {len(_tweets)}") if len(_tweets) >= limit or cursor is None or len(entries) == 2: break return _tweetsf
4. Création d’un fichier CSV
Récupérer les tweets c’est bien. Mais pour l’instant, ils sont au format JSON, avec quelque chose qui ressemble à ça:
{ "tweet_url":"https://twitter.com/elonmusk/status/1647298658331770883", "name":"Elon Musk", "user_id":"44196397", "username":"elonmusk", "published_at":"Sat Apr 15 17:59:40 +0000 2023", "content":"Your direct experience, people you talk to in the subject area & independent research will get you much closer to the truth", "views_count":"7073534", "retweet_count":12977, "likes":124877, "quote_count":526, "reply_count":3455, "bookmarks_count":569 }f
C’est fantastique, mais c’est un pas simple à manipuler pour quelqu’un qui ne maîtrise pas l’outil informatique. On va donc gentiment exporter ces données au format csv. Un format accessible à tous, aux nerds comme aux fous de la bureautique.
🤓
On va donc d’abord générer le nom du fichier, en utilisant le timestamp au format Unix, et le nom d’utilisateur à partir duquel on récupère les tweets:
import datetime timestamp = int(datetime.datetime.now().timestamp()) filename = '%s_%s.csv' % (self.username, timestamp) print('[+] writing %s' % filename)f
Et enfin, on va utiliser un DictWriter pour convertir élégamment nos dictionnaires JSON en ligne .csv, comme suit:
with open(filename, 'w') as f: writer = csv.DictWriter(f, fieldnames=FIELDNAMES, delimiter='\t') writer.writeheader() for tweet in tweets: print(tweet['id'], tweet['published_at']) writer.writerow(tweet)f
Et voilà, on y est!
Un joli fichier csv a désormais été enregistré dans le dossier où se trouve le fichier .py, avec le timestamp et le nom d’utilisateur ciblé. Ici, elonmusk bien entendu.
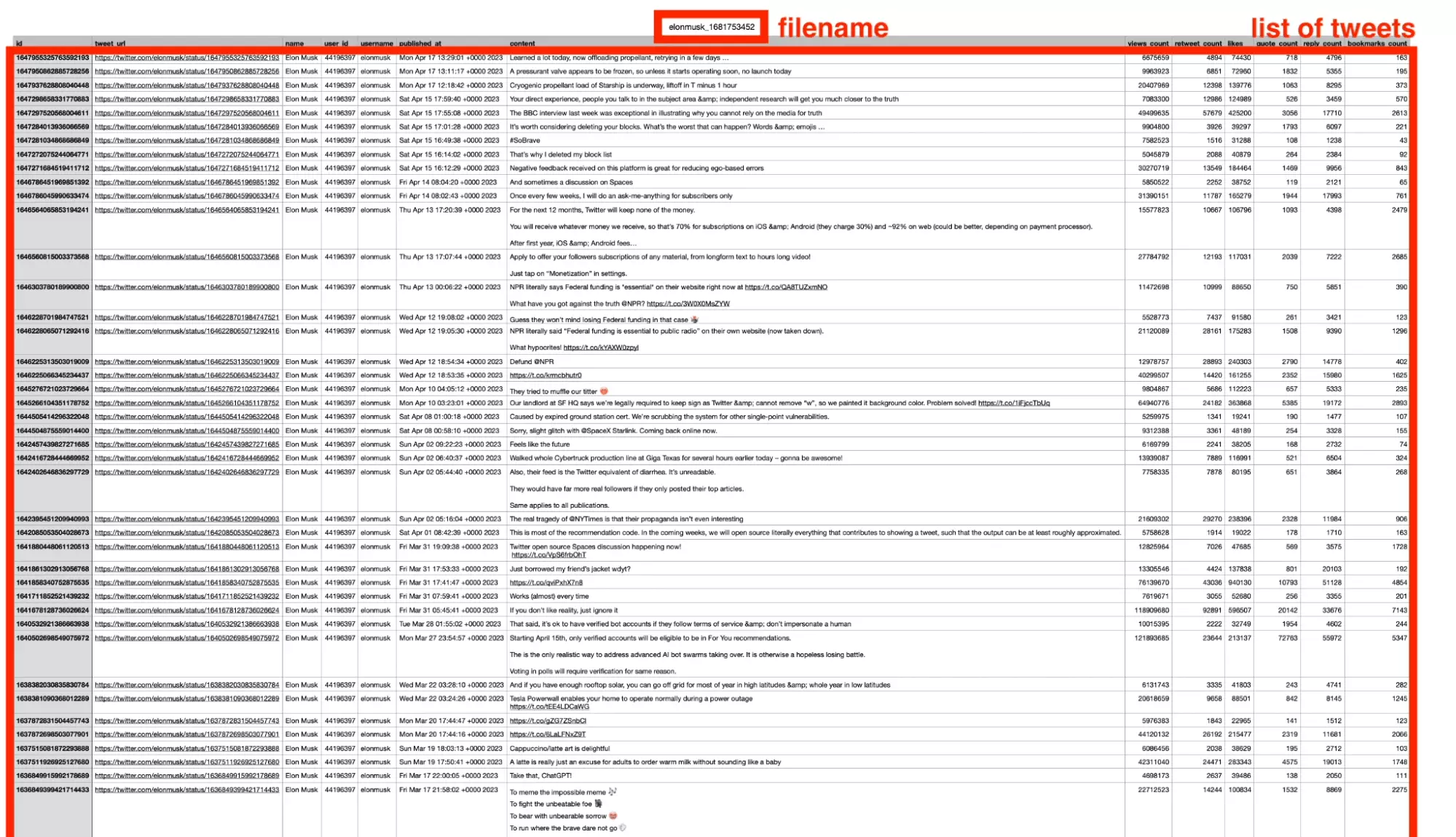
Magnifique!
5. Utilisation de variables dynamiques
Bon, si on veut scraper les tweets de Elon. OK.
- username — le nom d’utilisateur cible
- limit — le nombre max. de tweets à récupérer
Et pouvoir moduler au lancement du script la cible de collecte, et le volume de tweets à collecter. Allons-y!
D’abord on importe la librairie.
Puis, dans la dernière fonction main, on va générer les deux attributs mentionnés plus haut — username et limit.
Comme suit:
import argparse … def main(): argparser = argparse.ArgumentParser() argparser.add_argument('--username', '-u', type=str, required=False, help='user to scrape tweets from', default='elonmusk') argparser.add_argument('--limit', '-l', type=int, required=False, help='max tweets to scrape', default=100) args = argparser.parse_args() username = args.username limit = args.limitf
Par défaut, on note que le nom d’utilisateur par défaut est elonmusk, tandis que la limite de tweets est de 100. Owner takes all.
Et on instancie ensuite notre scraper, en lui assignant ces deux variables:
def main(): … twitter_scraper = TwitterScraper(username) tweets = twitter_scraper.iter_tweets(limit=limit) assert tweets twitter_scraper.generate_csv(tweets) print('''~~ success _ _ _ | | | | | | | | ___ | |__ ___| |_ __ __ | |/ _ \| '_ \/ __| __/| '__| | | (_) | |_) \__ \ |_ | | |_|\___/|_.__/|___/\__||_| ''')f
Et voilà!
On peut maintenant lancer une collecte, en choisissant précisément l’utilisateur cible, duquel on va récupérer des tweets.
Dans notre console, on peut donc utiliser la commande comme suit:
$ python3 twitter_scraper.py --username realdonaldtrump --limit 10f
On a alors récupéré les 10 derniers tweets du président notoire. Point trop s’en faut. Et tous proprement rangés dans un fichier .csv, prêt à l’usage:

Please remember who got it done!!!
😭
Benéfices
Le script est fonctionnel, flexible, et immédiatement prêt à l’emploi.
Mais quels en sont les bénéfices, par rapport à une stratégie de collecte via l’API officielle?
Avec ce script, nous allons pouvoir récupérer des tweets, sans aucune limite. Gratuitement.
Tout est dit.
Limitations
Attention, ce script présente toutefois des limitations claires.
La principale limitation est que vous ne pourrez récupérer que les 100 derniers tweets de n'importe quel utilisateur. Pas plus.
Par ailleurs, ce script ne récupère pas le type de message. On a bien le message, mais impossible de savoir s’il s’agit d’un tweet direct, d’un repost ou d’une réponse à un autre tweet.
Surtout, le script ne récupère que le contenu texte d’un message. Impossible de récupérer ni les vidéos, ni le format, ni les images. Pour les meme et le shitpost insipiré d’Elon on repassera.
Enfin, ce script se limite aux tweets d’un utilisateur. Vous voulez récupérer les tweets à partir d’un hashtag (un peu désuet, mais bon) ou à partir d’une recherche twitter? C’est niet.
FAQ
Est-ce que le scraping sur Twitter est légal?
Pourquoi ne pas utiliser l’API officielle?
L’API officiel est très bien!
Elle est proprement documentée, et peut résister à un volume de requêtes important sans faillir.
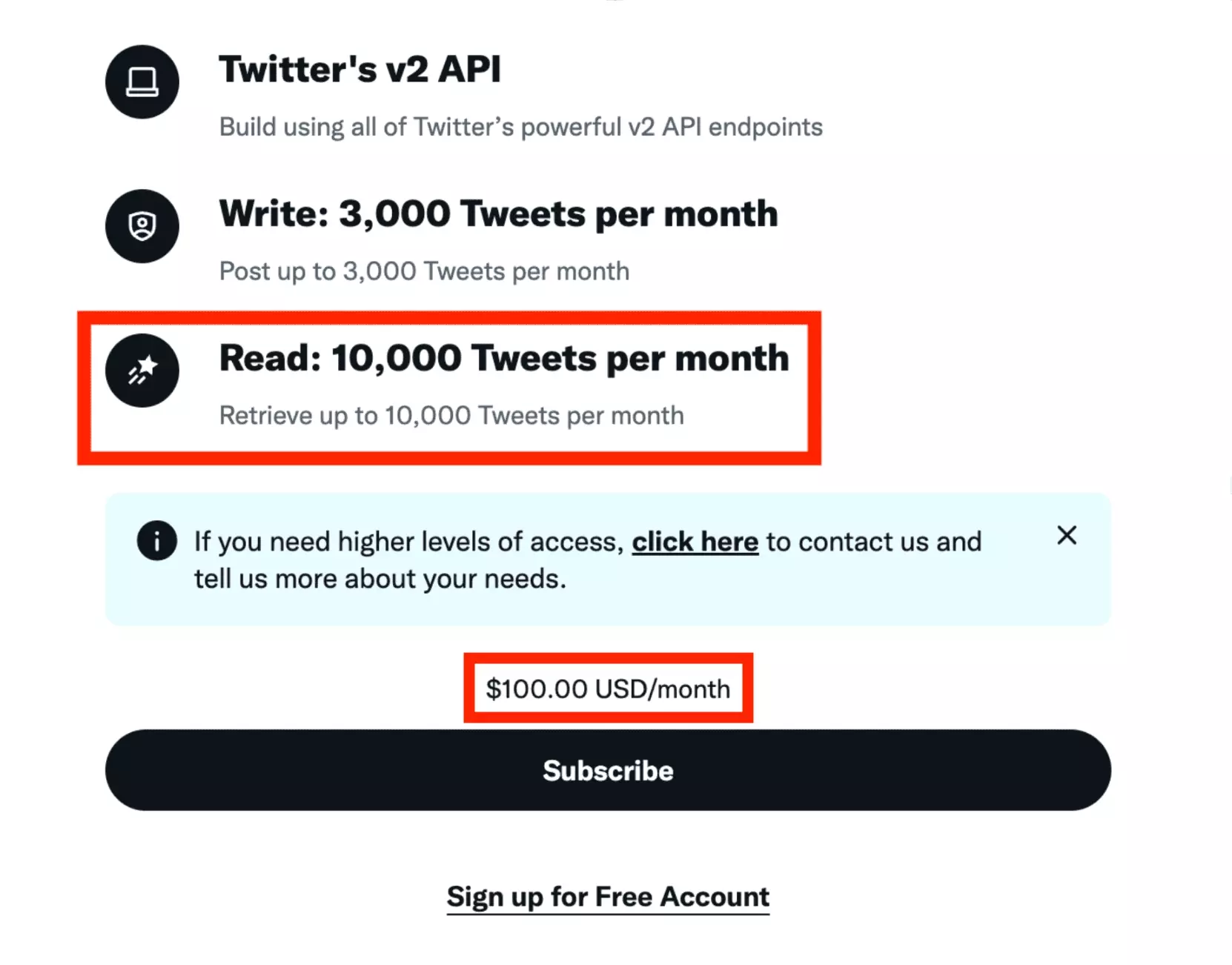
Toutefois, depuis le rachat de Twitter par Elon Musk, elle coûte un bras: il faudra compter 100 USD par mois, avec jusqu’à 10 000 tweets récupérés. Ça fait cher le MVP.
Le script proposé dans ce tutoriel est entièrement gratuit.
Si je lance ce script dans un mois, est-ce que ça marche?
Sauf modification du code depuis la plateforme, oui! Nous avons construit ce script pour qu’il résiste à l’épreuve du temps.
Je ne sais pas coder, est-ce qu’une solution no-code existe?
Oui, le voilà !
- 500 tweets par minute
- aucune limitation
- jusqu'à 10 threads simultanés
- 40+ attributs par tweet
Conclusion
Et voilà, c’est la fin de cet article!
Dans ce tutoriel, nous avons vu comment scraper directement à partir de l’API interne de tweeter, autant de tweets que nécessaire. Et ça sans dépenser un euro et sans aucune limitation.
Happy scraping!
🦀