
Comment scraper Yelp en utilisant Python et requests en 2023?
Prérequis
Avant de scraper les annonces de restaurants de Yelp, nous devons nous assurer que nous avons les outils nécessaires en place. Les deux composants essentiels dont nous avons besoin sont Python et Sublime Text.
- Python : Assurez-vous d'avoir Python installé sur votre système. Si vous n'avez pas Python installé, vous pouvez le télécharger et l'installer à partir du site officiel de Python. Choisissez la version appropriée en fonction de votre système d'exploitation.
- Sublime Text : Sublime Text est un éditeur de texte populaire et léger qui offre un environnement simple et efficace pour écrire du code Python. Vous pouvez télécharger Sublime Text à partir du site officiel et l'installer sur votre ordinateur.
Une fois que vous avez Python et Sublime Text configurés, vous serez prêt à créer un scraper Yelp en utilisant Python et à écrire le code nécessaire.
Requirements
Pour scraper avec succès les annonces de Yelp en utilisant Python, nous devrons installer et importer plusieurs bibliothèques qui fournissent les fonctionnalités nécessaires. Voici les principales bibliothèques que nous utiliserons :
- requests : une bibliothèque HTTP puissante et conviviale pour Python. Elle simplifie le processus de réalisation de requêtes HTTP et de gestion des réponses, nous permettant de récupérer le contenu HTML des pages web.
- csv : offre des fonctionnalités pour lire et écrire des fichiers CSV (Comma-Separated Values). Nous utiliserons cette bibliothèque pour stocker les données dans un fichier CSV pour une analyse et un traitement ultérieurs.
- lxml : une bibliothèque robuste et efficace pour analyser les documents HTML et XML. Elle offre une navigation facile et une extraction de données en utilisant xPath ou les sélecteurs CSS, ce qui sera crucial pour extraire des éléments spécifiques des pages HTML de Yelp. lxml est généralement plus rapide que bs4, et elle peut analyser des HTML plus complexes. Cependant, elle est également plus complexe à utiliser et nécessite une dépendance externe en C.
- argparse : nous permet de gérer les arguments de la ligne de commande avec facilité. Il simplifie le processus de spécification des options et des paramètres lors de l'exécution du scraper Yelp, nous permettant de personnaliser l'URL de recherche et le nombre maximum de pages à scraper.
- time : fournit des fonctions pour les opérations liées au temps. Nous l'utiliserons pour introduire des délais entre les requêtes successives afin d'éviter de submerger le serveur.
pip install requests lxmlf
Code complet
Et ci-dessous:
import requests import csv from lxml import html import argparse import time class YelpSearchScraper: def iter_listings(self, url): response = requests.get(url) if response.status_code != 200: print("Error: Failed to fetch the URL") return None with open('response.html', 'w') as f: f.write(response.text) tree = html.fromstring(response.content) scraped_data = [] businesses = tree.xpath('//div[contains(@class, "container__09f24__mpR8_") and contains(@class, "hoverable__09f24__wQ_on") and contains(@class, "border-color--default__09f24__NPAKY")]') for business in businesses: data = {} name_element = business.xpath('.//h3[contains(@class, "css-1agk4wl")]/span/a') if name_element: data['Name'] = name_element[0].text.strip() data['URL'] = "https://www.yelp.com" + name_element[0].get('href') rating_element = business.xpath('.//div[contains(@aria-label, "star rating")]') if rating_element: rating_value = rating_element[0].get('aria-label').split()[0] if rating_value != 'Slideshow': data['Rating'] = float(rating_value) else: data['Rating'] = None reviews_element = business.xpath('.//span[contains(@class, "css-chan6m")]') if reviews_element: reviews_text = reviews_element[0].text if reviews_text: reviews_text = reviews_text.strip().split()[0] if reviews_text.isnumeric(): data['Reviews'] = int(reviews_text) else: data['Reviews'] = None price_element = business.xpath('.//span[contains(@class, "priceRange__09f24__mmOuH")]') if price_element: data['Price Range'] = price_element[0].text.strip() # ok getting proper xpath categories_element = business.xpath('.//span[contains(@class, "css-11bijt4")]') if categories_element: data['Categories'] = ", ".join([c.text for c in categories_element]) neighborhood_element = business.xpath('.//p[@class="css-dzq7l1"]/span[contains(@class, "css-chan6m")]') if neighborhood_element: neighborhood_text = neighborhood_element[0].text if neighborhood_text: data['Neighborhood'] = neighborhood_text.strip() assert data scraped_data.append(data) return scraped_data def save_to_csv(self, data, filename): keys = data[0].keys() with open(filename, 'w', newline='', encoding='utf-8-sig') as csvfile: writer = csv.DictWriter(csvfile, fieldnames=keys, extrasaction='ignore') writer.writeheader() writer.writerows(data) print("Success! \nData written to CSV file:", filename) def scrape_results(self, search_url, max_page): all_results = [] for page in range(1, max_page): page_url = search_url + f'&start={(page-1)*10}' print(f"Scraping Page {page}") results = self.iter_listings(page_url) if results: all_results.extend(results) time.sleep(2) return all_results def main(): s = time.perf_counter() argparser = argparse.ArgumentParser() argparser.add_argument('--search-url', '-u', type=str, required=False, help='Yelp search URL', default='https://www.yelp.com/search?find_desc=Burgers&find_loc=London') argparser.add_argument('--max-page', '-p', type=int, required=False, help='Max page to visit', default=5) args = argparser.parse_args() search_url = args.search_url max_page = args.max_page assert all([search_url, max_page]) scraper = YelpSearchScraper() results = scraper.scrape_results(search_url, max_page) if results: scraper.save_to_csv(results, 'yelp_search_results.csv') else: print("No results to save to CSV") elapsed = time.perf_counter() - s elapsed_formatted = "{:.2f}".format(elapsed) print("Elapsed time:", elapsed_formatted, "seconds") print('''~~ success _ _ _ | | | | | | | | ___ | |__ ___| |_ __ __ | |/ _ | '_ / __| __/| '__| | | (_) | |_) __ \ |_ | | |_|___/|_.__/|___/__||_| ''') if __name__ == '__main__': main()f
Explication détaillée du code étape par étape
Importation des bibliothèques requises
Pour commencer à coder notre scraper Yelp, nous devons d'abord importer les bibliothèques. En important ces bibliothèques, nous nous assurons que nous avons accès aux outils et fonctionnalités requis pour notre scraper Yelp.
import requests import csv from lxml import html import argparse import timef
Création de la classe YelpSearchScraper
Collecte des données des annonces d'entreprises sur Yelp
class YelpSearchScraper: def iter_listings(self, url): response = requests.get(url) if response.status_code != 200: print("Error: Failed to fetch the URL") return Nonef
Voici ce qui se passe dans cette méthode :
- Elle envoie une requête HTTP GET à l'URL spécifiée en utilisant la fonction requests.get() et attribue la réponse à la variable de réponse.
- Le code vérifie ensuite l'attribut status_code de l'objet de réponse. Un code de statut 200 indique une réponse réussie. Si le code de statut n'est pas 200, cela signifie qu'il y a eu une erreur lors de la récupération de l'URL.
- Si le code de statut n'est pas 200, le code affiche un message d'erreur indiquant l'échec de la récupération de l'URL et renvoie None.
Après avoir récupéré le contenu HTML de la page Yelp, nous voulons le sauvegarder pour référence. Pour cela, nous pouvons utiliser le code suivant :
with open('response.html', 'w') as f: f.write(response.text)f
Une fois que nous avons récupéré le contenu HTML de la page Yelp, l'étape suivante consiste à l'analyser et à en extraire les informations pertinentes. Examinons le code suivant :
tree = html.fromstring(response.content) scraped_data = []f
- Nous utilisons la fonction fromstring() du module html dans lxml pour créer un objet d'arbre appelé tree. Cette fonction prend en entrée response.content, qui contient le contenu HTML récupéré de Yelp.
- response.content représente le contenu HTML brut en bytes. En le passant à fromstring(), nous le convertissons en un objet d'arbre structuré que nous pouvons parcourir et extraire des données.
- Nous initialisons une liste vide appelée scraped_data pour stocker les données extraites des annonces de restaurants Yelp.
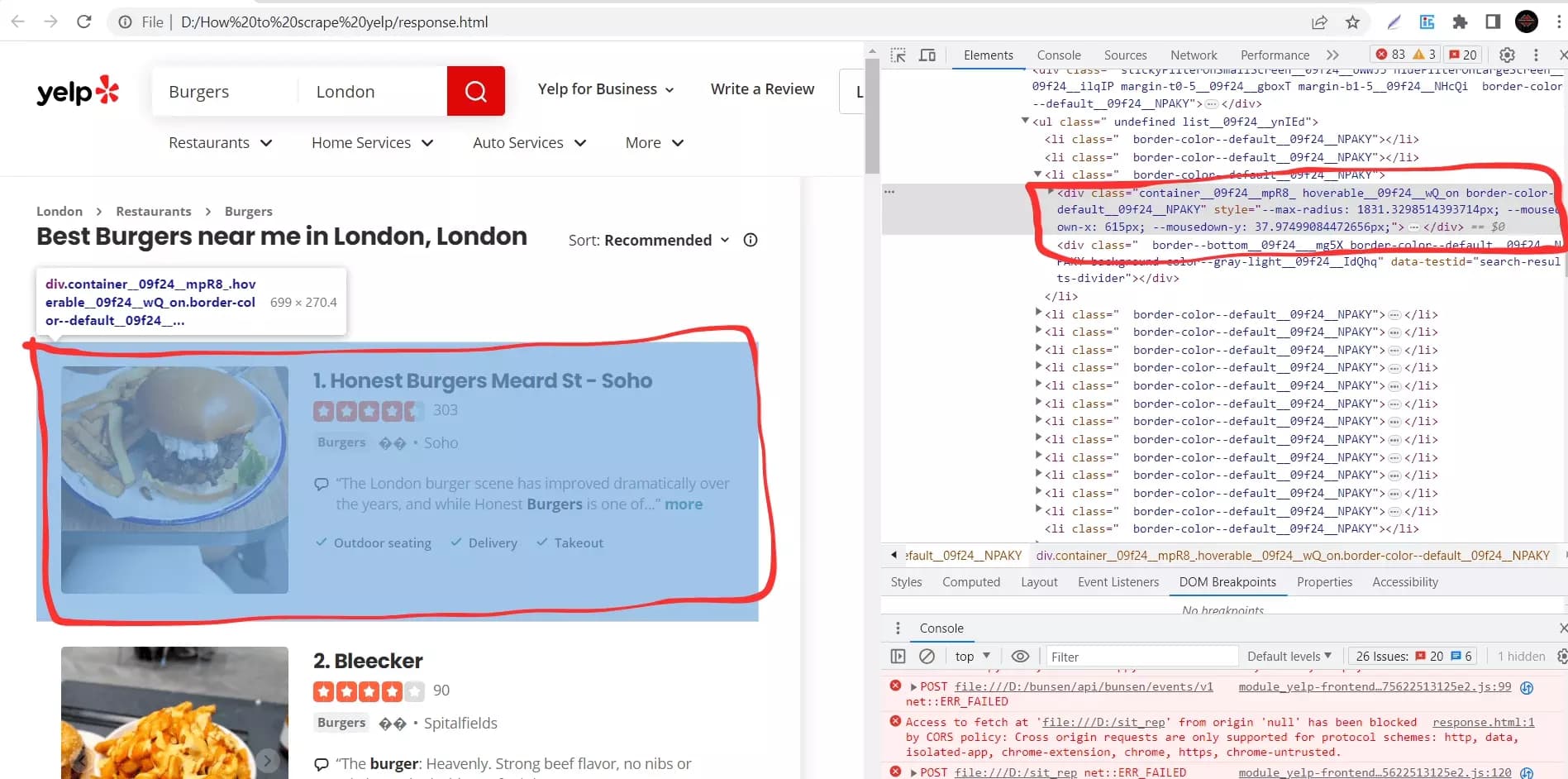
businesses = tree.xpath('//div[contains(@class, "container__09f24__mpR8_") and contains(@class, "hoverable__09f24__wQ_on") and contains(@class, "border-color--default__09f24__NPAKY")]')f
- La méthode xpath() est appelée sur l'objet tree et prend une expression xPath en argument. L'expression xPath utilisée ici est
'//div[contains(@class, "container__09f24__mpR8_") and contains(@class, "hoverable__09f24__wQ_on") and contains(@class, "border-color--default__09f24__NPAKY")]'.
- L'expression xPath cible les éléments <div> qui contiennent certaines classes. En utilisant la fonction contains(), nous spécifions que l'élément doit contenir les trois classes mentionnées dans l'expression. Cela nous aide à localiser les éléments spécifiques qui représentent les annonces commerciales sur la page Yelp.
- La méthode xpath() renvoie une liste d'éléments correspondants, qui est assignée à la variable businesses.
Extraction du nom de l'entreprise et de l'URL de l'annonce
Maintenant que nous avons extrait les éléments d'annonce commerciale et les avons stockés dans la liste des entreprises, nous pouvons procéder à l'extraction de détails spécifiques pour chaque annonce.
for business in businesses: data = {} name_element = business.xpath('.//h3[contains(@class, "css-1agk4wl")]/span/a') if name_element: data['Nom'] = name_element[0].text.strip() data['URL'] = "https://www.yelp.com" + name_element[0].get('href')f
- Pour chaque élément business, nous initialisons un dictionnaire vide appelé data pour stocker les détails extraits pour ce business particulier.
- Nous utilisons la méthode xpath() sur l'élément business pour trouver le nom du restaurant. L'expression xPath:
'.//h3[contains(@class, "css-1agk4wl")]/span/a'
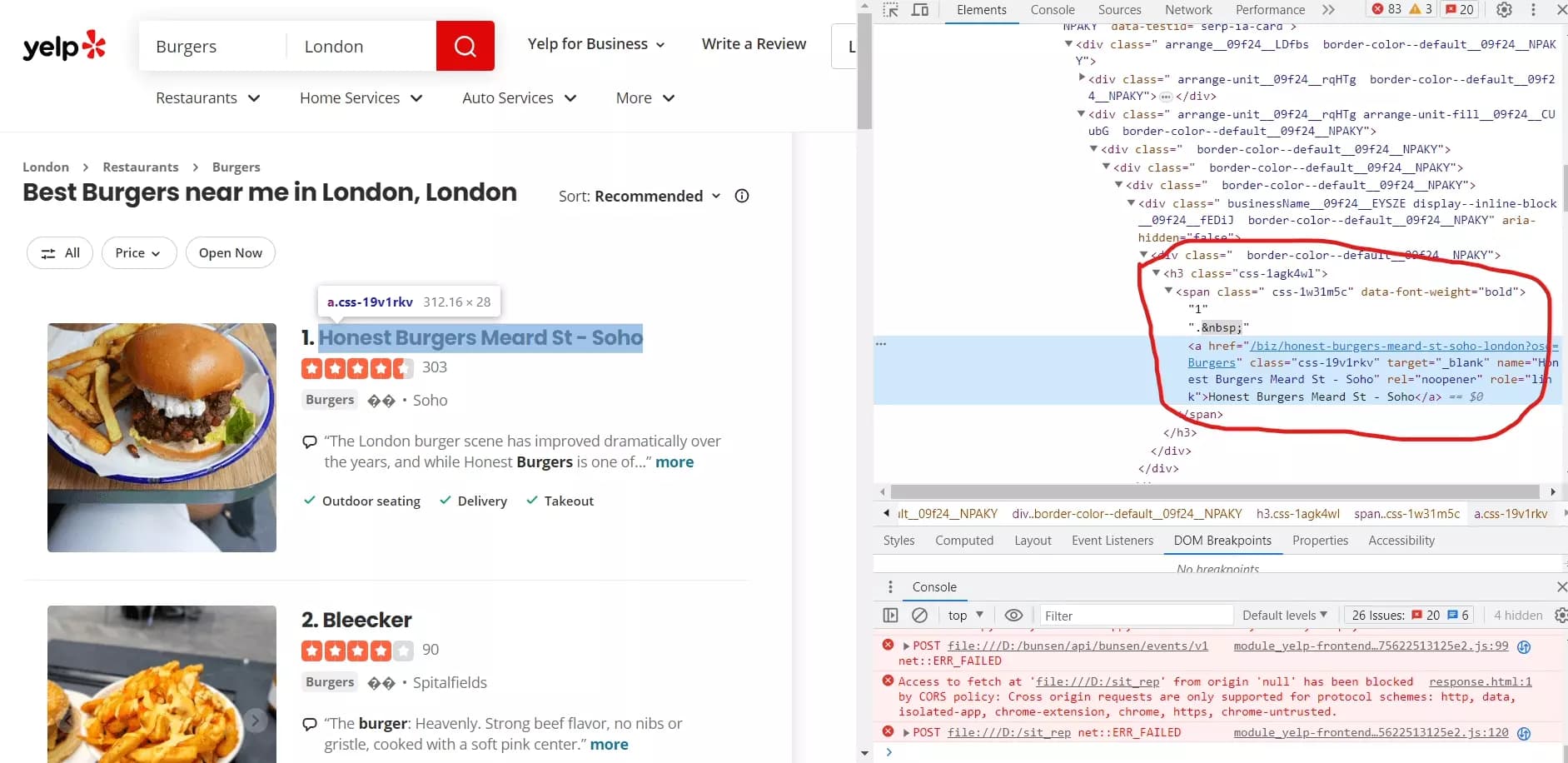
- Si l'élément_nom est trouvé, nous extrayons le texte de l'élément en utilisant .text.strip() et l'assignons à data['Nom']. Nous construisons également l'URL du restaurant en concaténant "https://www.yelp.com" avec l'attribut href de l'élément <a> en utilisant .get('href'). Cette URL est assignée à data['URL'].
C'est ainsi que ce fragment de code va scraper les noms d'entreprises Yelp et les URLs des annonces.
Extraction de la note de l'entreprise
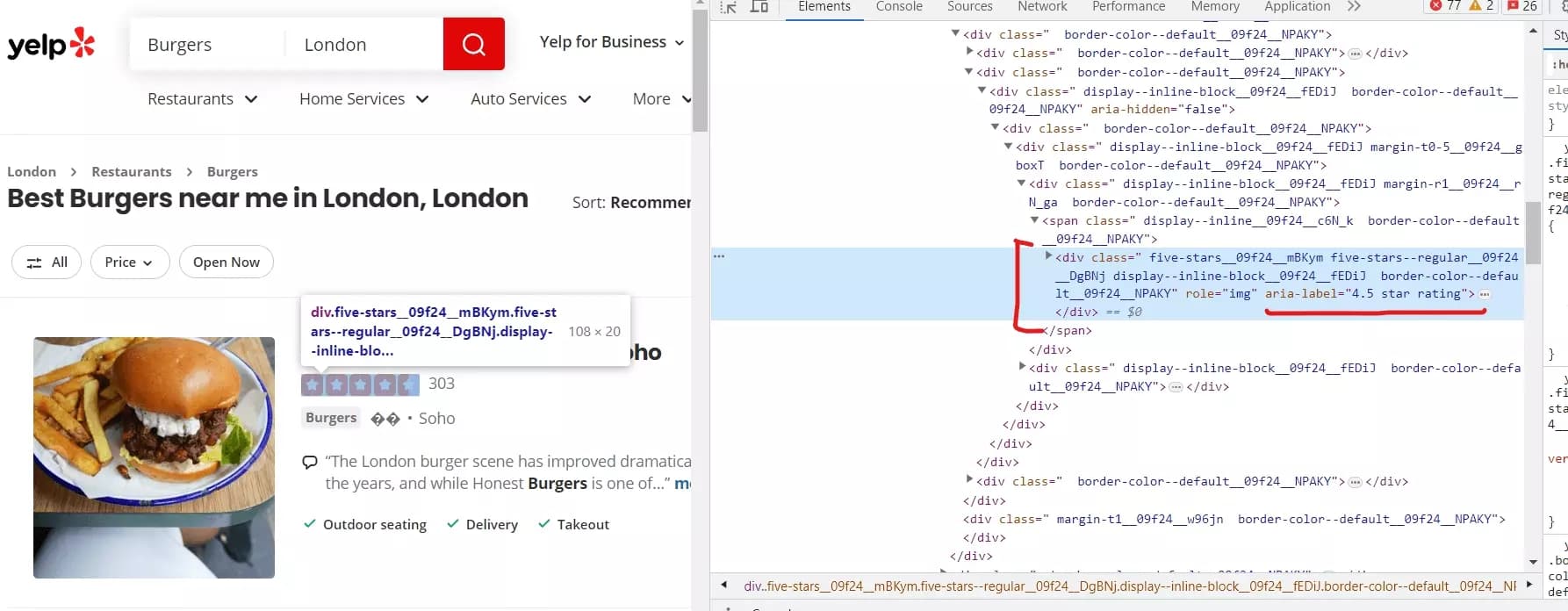
rating_element = business.xpath('.//div[contains(@aria-label, "star rating")]') if rating_element: rating_value = rating_element[0].get('aria-label').split()[0] if rating_value != 'Slideshow': data['Note'] = float(rating_value) else: data['Note'] = Nonef
Dans ce fragment de code, nous extrayons les informations de notation pour chaque annonce d'entreprise. Voici comment cela fonctionne :
- Encore une fois, nous avons utilisé la méthode xpath() sur l'élément business pour localiser l'élément <div> qui contient les informations de notation. L'expression xPath:
'.//div[contains(@aria-label, "star rating")]'
- Si le rating_element est trouvé, nous extrayons la valeur de notation de l'attribut aria-label de l'élément. Nous récupérons l'attribut aria-label en utilisant .get('aria-label') et le divisons en une liste de mots en utilisant .split(). La valeur de notation est le premier élément de cette liste, représentant la valeur de notation numérique.
- Nous vérifions si la valeur de notation extraite n'est pas égale à 'Slideshow' (un cas spécial où Yelp affiche un diaporama dynamique au lieu d'une notation numérique). Si ce n'est pas 'Slideshow', nous convertissons la valeur de notation en float en utilisant float(rating_value) et l'attribuons à data['Note']. Sinon, si c'est 'Slideshow', nous attribuons None à data['Note'].
Extraire le nombre d'avis
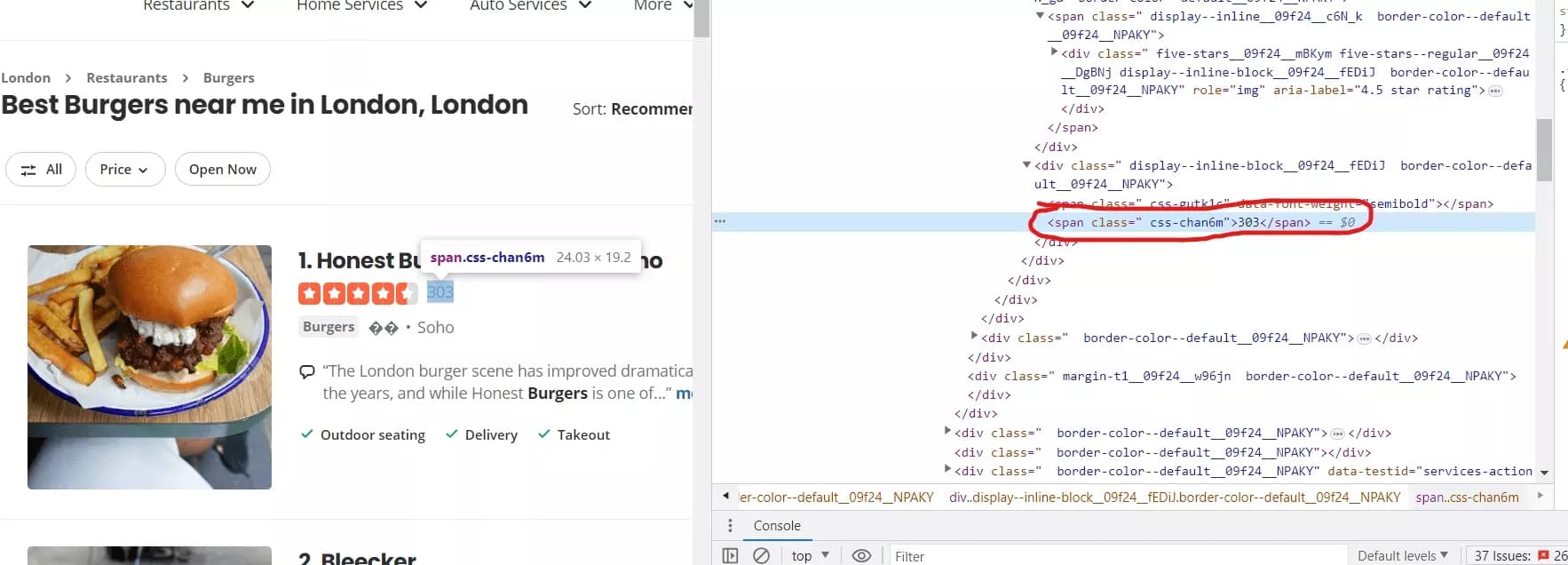
reviews_element = business.xpath('.//span[contains(@class, "css-chan6m")]') if reviews_element: reviews_text = reviews_element[0].text if reviews_text: reviews_text = reviews_text.strip().split()[0] if reviews_text.isnumeric(): data['Reviews'] = int(reviews_text) else: data['Reviews'] = Nonef
Voici une explication de ce morceau de code :
- Nous utilisons la méthode xpath() pour localiser l'élément pour extraire le nombre d'avis.
- Si l'élément reviews_element existe, nous extrayons le contenu textuel de l'élément en utilisant .text. Le texte extrait représente le nombre d'avis.
- Nous nous assurons que reviews_text n'est pas vide ou None. S'il contient une valeur, nous extraisons la partie numérique du texte en supprimant tous les espaces blancs et en prenant le premier mot.
- Après avoir extrait la partie numérique, nous vérifions si c'est un nombre valide en utilisant .isnumeric(). Si c'est le cas, on le convertit en entier et on l'affecte à data['Reviews']. Sinon, si ce n'est pas un nombre valide, on affecte None à data['Reviews'].
Extraire la fourchette de prix
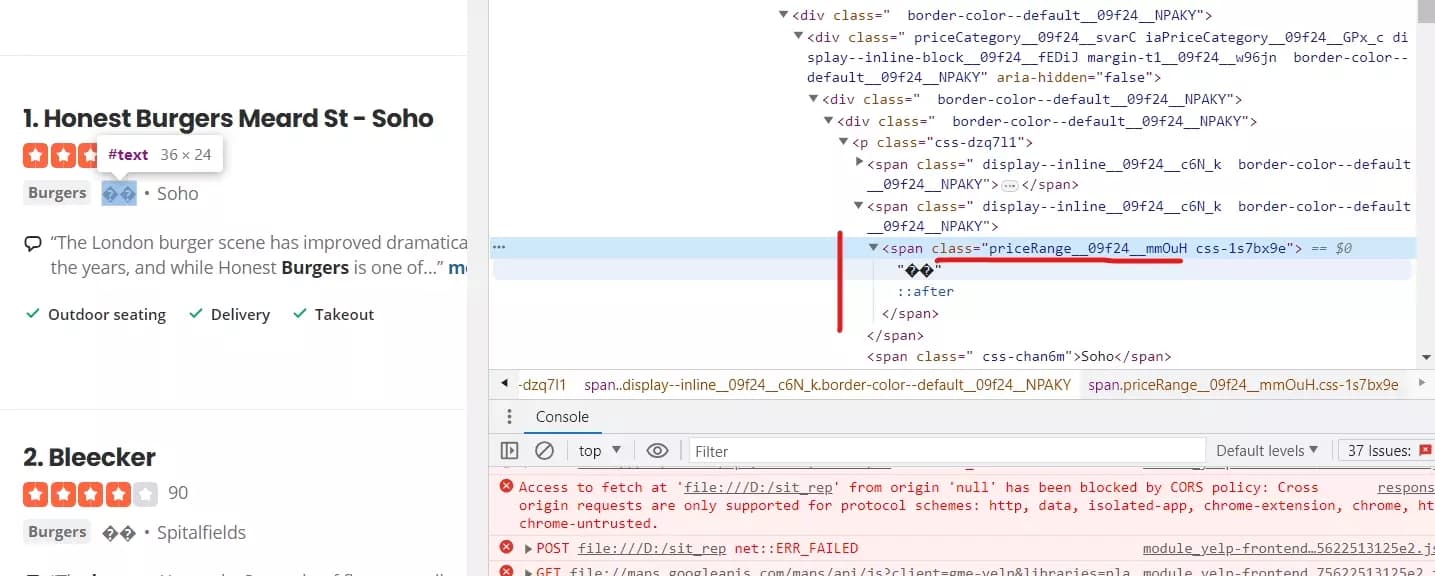
price_element = business.xpath('.//span[contains(@class, "priceRange__09f24__mmOuH")]') if price_element: data['Price Range'] = price_element[0].text.strip()f
Ce simple extrait extraira la fourchette de prix des annonces.
Extraire la catégorie du restaurant
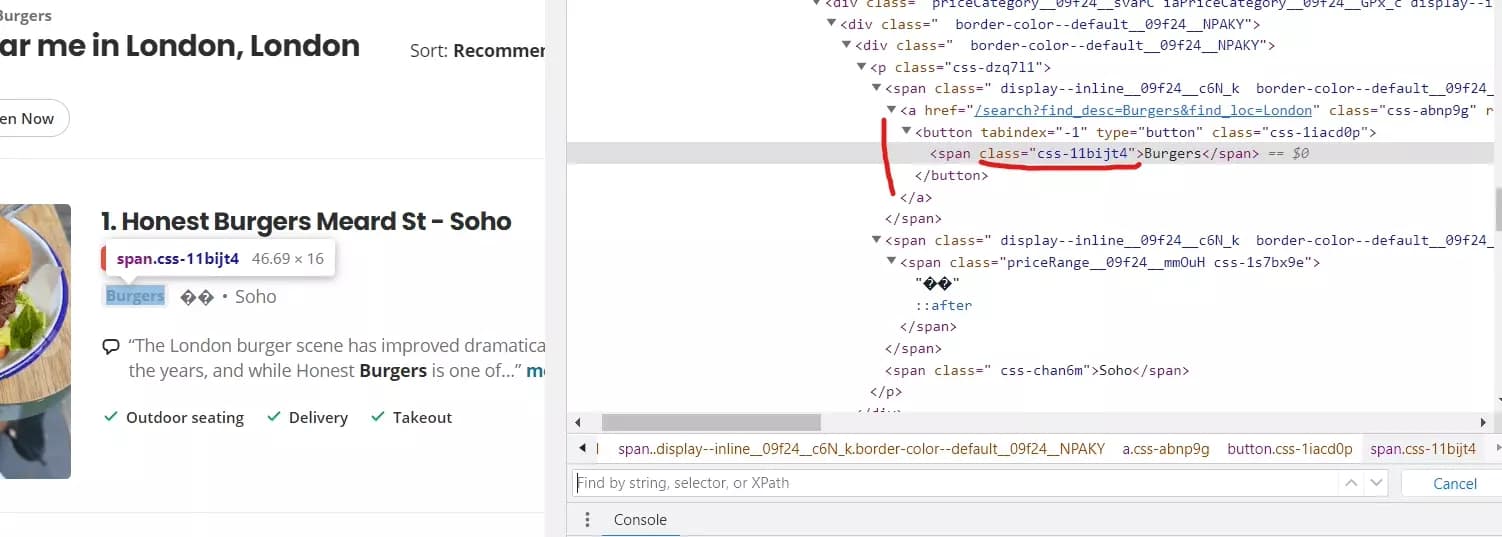
Pour récupérer les catégories associées à chaque annonce d'entreprise, nous utilisons le morceau de code suivant :
categories_element = business.xpath('.//span[contains(@class, "css-11bijt4")]') if categories_element: data['Categories'] = ", ".join([c.text for c in categories_element])f
Voici ce que fait ce morceau de code :
- Nous recherchons les éléments <span> qui contiennent une classe nommée "css-11bijt4" en utilisant le xpath()
- Si l'élément categories_element existe, nous extrayons le contenu textuel de chaque élément <span> en utilisant une compréhension de liste : [c.text for c in categories_element]. Cela crée une liste des noms de catégories.
- Ensuite, nous joignons les éléments de la liste en une seule chaîne, séparés par des virgules, en utilisant ", ".join(...). Cela consolide les noms de catégories en une chaîne formatée.
Extraction du quartier

neighborhood_element = business.xpath('.//p[@class="css-dzq7l1"]/span[contains(@class, "css-chan6m")]') if neighborhood_element: neighborhood_text = neighborhood_element[0].text if neighborhood_text: data['Neighborhood'] = neighborhood_text.strip()f
Nous avons déjà appris comment ce code fonctionne, donc pas besoin de l'expliquer à nouveau. Passons à la partie suivante de notre code.
Après avoir extrait les détails pertinents de chaque annonce d'entreprise, nous devons les stocker. Voici comment nous le faisons :
assert data scraped_data.append(data) return scraped_dataf
Ce morceau de code assure que le dictionnaire de données contient des informations valides avant de les stocker dans la liste scraped_data. Décortiquons le code :
- L'instruction assert est utilisée pour valider une condition. Dans ce cas, nous affirmons que les données ne sont pas vides ou None. Si la condition est évaluée à False, une AssertionError est soulevée, indiquant qu'un événement inattendu s'est produit pendant le processus de scraping.
- Après l'assertion, nous ajoutons le dictionnaire de données à la liste scraped_data. Cela ajoute les détails extraits pour une annonce d'entreprise particulière à la liste de toutes les données scrapées.
- Enfin, nous renvoyons la liste scraped_data, qui contient des dictionnaires représentant les informations extraites pour chaque annonce d'entreprise.
Maintenant, notre script Python est fonctionnel et peut scraper les annonces Yelp avec 6 attributs de données. Sauvegardons les annonces Yelp que nous avons extraites dans un fichier CSV.
Enregistrement des données en CSV
def save_to_csv(self, data, filename): keys = data[0].keys() with open(filename, 'w', newline='', encoding='utf-8-sig') as csvfile: writer = csv.DictWriter(csvfile, fieldnames=keys, extrasaction='ignore') writer.writeheader() writer.writerows(data) print("Succès!\nDonnées écrites dans le fichier CSV:", filename)f
def save_to_csv(self, data, filename):f
keys = data[0].keys()f
with open(filename, 'w', newline='', encoding='utf-8-sig') as csvfile:f
writer = csv.DictWriter(csvfile, fieldnames=keys, extrasaction='ignore')f
writer.writeheader() writer.writerows(data)f
Enfin, la ligne imprime un message de succès, confirmant que les données ont été écrites avec succès dans le fichier CSV.
Extraction de plusieurs pages
Lors de l'extraction des résultats de recherche Yelp, nous ne voulons pas seulement extraire la première page. Il n'y a que 10 résultats par page et Yelp vous montre 24 pages par URL de recherche. Cela signifie que vous pouvez extraire jusqu'à 240 résultats par URL de recherche. Jusqu'à présent, notre code est capable d'extraire uniquement la première page. Améliorons ses capacités et gérons la pagination de Yelp.
def scrape_results(self, search_url, max_page): all_results = [] for page in range(1, max_page): page_url = search_url + f'&start={(page-1)*10}' print(f"Extraction Page {page}") results = self.iter_listings(page_url) if results: all_results.extend(results) time.sleep(2) return all_resultsf
Décortiquons ce morceau de code pour une meilleure compréhension:
def scrape_results(self, search_url, max_page):f
all_results = []f
for page in range(1, max_page):f
page_url = search_url + f'&start={(page-1)*10}'f
results = self.iter_listings(page_url)f
if results: all_results.extend(results)f
time.sleep(2)f
return all_resultsf
Finalisation du Yelp Scraper
def main(): s = time.perf_counter() argparser = argparse.ArgumentParser() argparser.add_argument('--search-url', '-u', type=str, required=False, help='URL de recherche Yelp', default='https://www.yelp.com/search?find_desc=Burgers&find_loc=London') argparser.add_argument('--max-page', '-p', type=int, required=False, help='Page maximum à visiter', default=5) args = argparser.parse_args() search_url = args.search_url max_page = args.max_page assert all([search_url, max_page]) scraper = YelpSearchScraper() results = scraper.scrape_results(search_url, max_page) if results: scraper.save_to_csv(results, 'yelp_search_results.csv') else: print("Aucun résultat à sauvegarder en CSV") elapsed = time.perf_counter() - s elapsed_formatted = "{:.2f}".format(elapsed) print("Temps écoulé :", elapsed_formatted, "secondes") print('''~~ succès _ _ _ | | | | | | | | ___ | |__ ___| |_ __ __ | |/ _ | '_ / __| __/| '__| | | (_) | |_) __ \ |_ | | |_|___/|_.__/|___/__||_| ''') if __name__ == '__main__': main()f
Faisons une rapide décomposition de notre fonction principale :
def main(): s = time.perf_counter()f
argparser = argparse.ArgumentParser() argparser.add_argument('--search-url', '-u', type=str, required=False, help='URL de recherche Yelp', default='https://www.yelp.com/search?find_desc=Burgers&find_loc=London') argparser.add_argument('--max-page', '-p', type=int, required=False, help='Page maximum à visiter', default=5) args = argparser.parse_args()f
search_url = args.search_url max_page = args.max_pagef
assert all([search_url, max_page])f
scraper = YelpSearchScraper() results = scraper.scrape_results(search_url, max_page)f
if results: scraper.save_to_csv(results, 'yelp_search_results.csv') else: print("Aucun résultat à sauvegarder en CSV")f
elapsed = time.perf_counter() - s elapsed_formatted = "{:.2f}".format(elapsed) print("Temps écoulé :", elapsed_formatted, "secondes")f
Scraping des annonces de restaurants Yelp à partir d'une URL de recherche
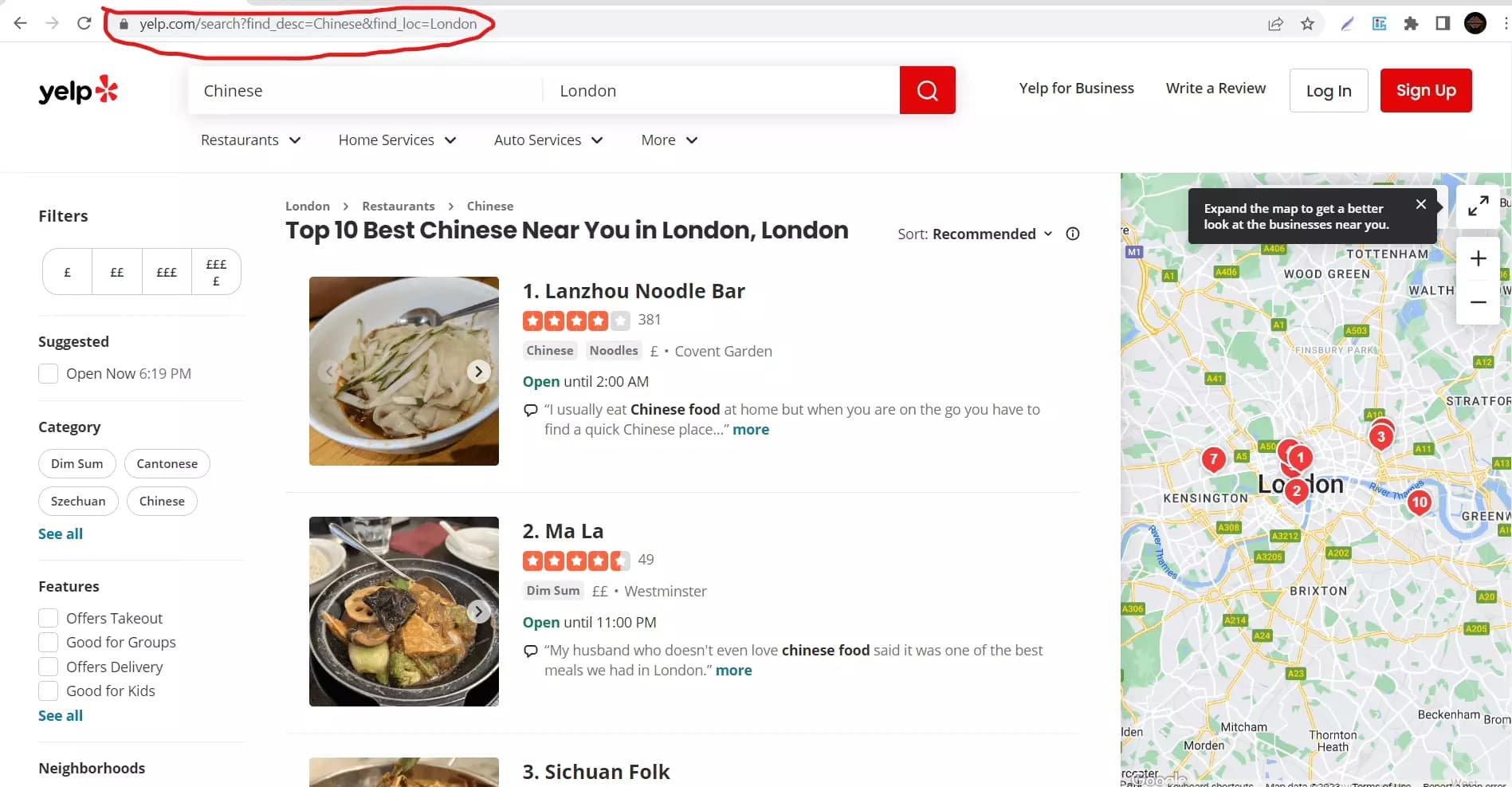
Il est temps de tester notre Yelp scraper. Nous allons scraper Yelp pour recueillir les détails de 30 restaurants chinois situés à Londres. La première étape consiste à obtenir l'URL. Visitez yelp.com, recherchez le mot-clé, et sélectionnez l'emplacement. Tout ce que nous avons à faire maintenant est de copier l'URL de la barre d'adresse.
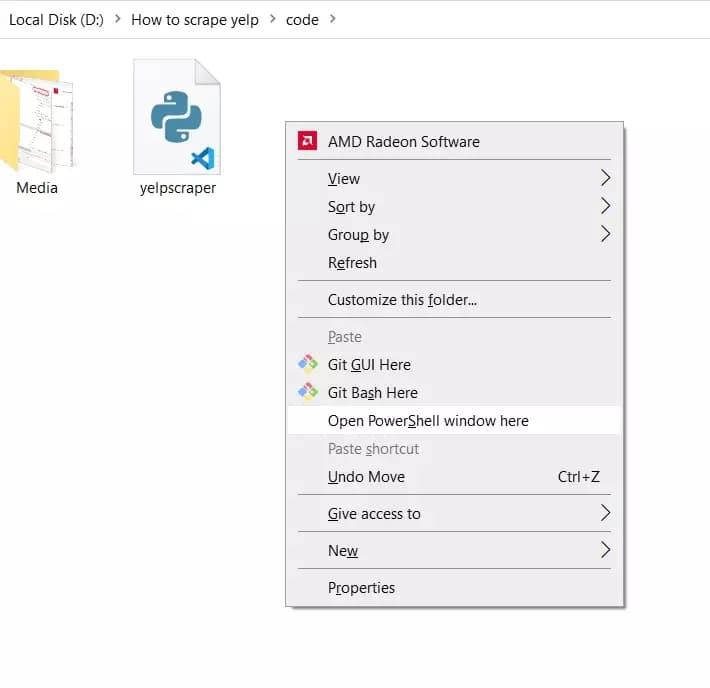
Lançons notre yelp scraper basé sur python. Allez dans le dossier où vous avez sauvegardé le script python. Appuyez sur shift et faites un clic droit sur une zone vide de votre écran. Dans le menu, sélectionnez "ouvrir la fenêtre Powershell ici".
Dans votre console, tapez la commande suivante :
python {your_script_name.py} -u {url} -p {nombre maximum de pages à scraper}f
python yelpscraper.py -u "https://www.yelp.com/search?find_desc=Chinese&find_loc=London" -p 3f
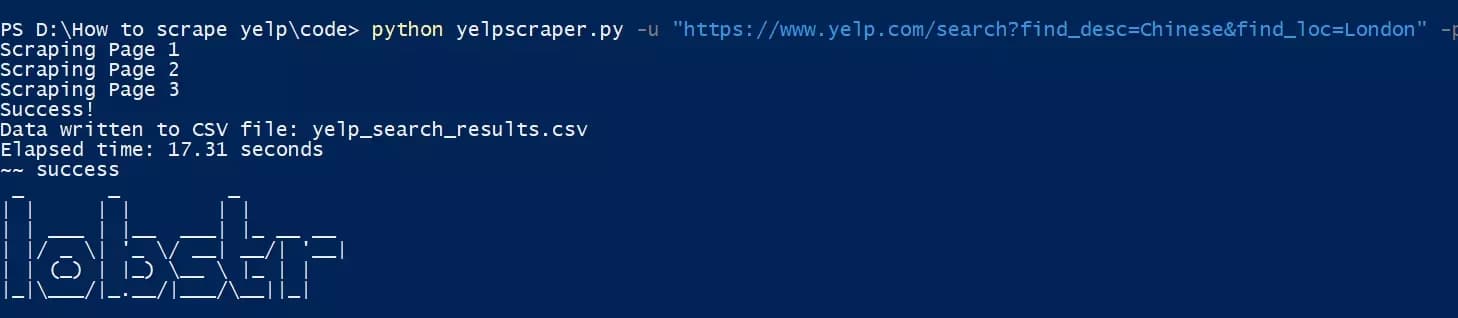
Et voilà. Nous venons d'extraire 30 annonces de restaurants avec 6 attributs de données de Yelp. Voyons à quoi ressemble le fichier de sortie :
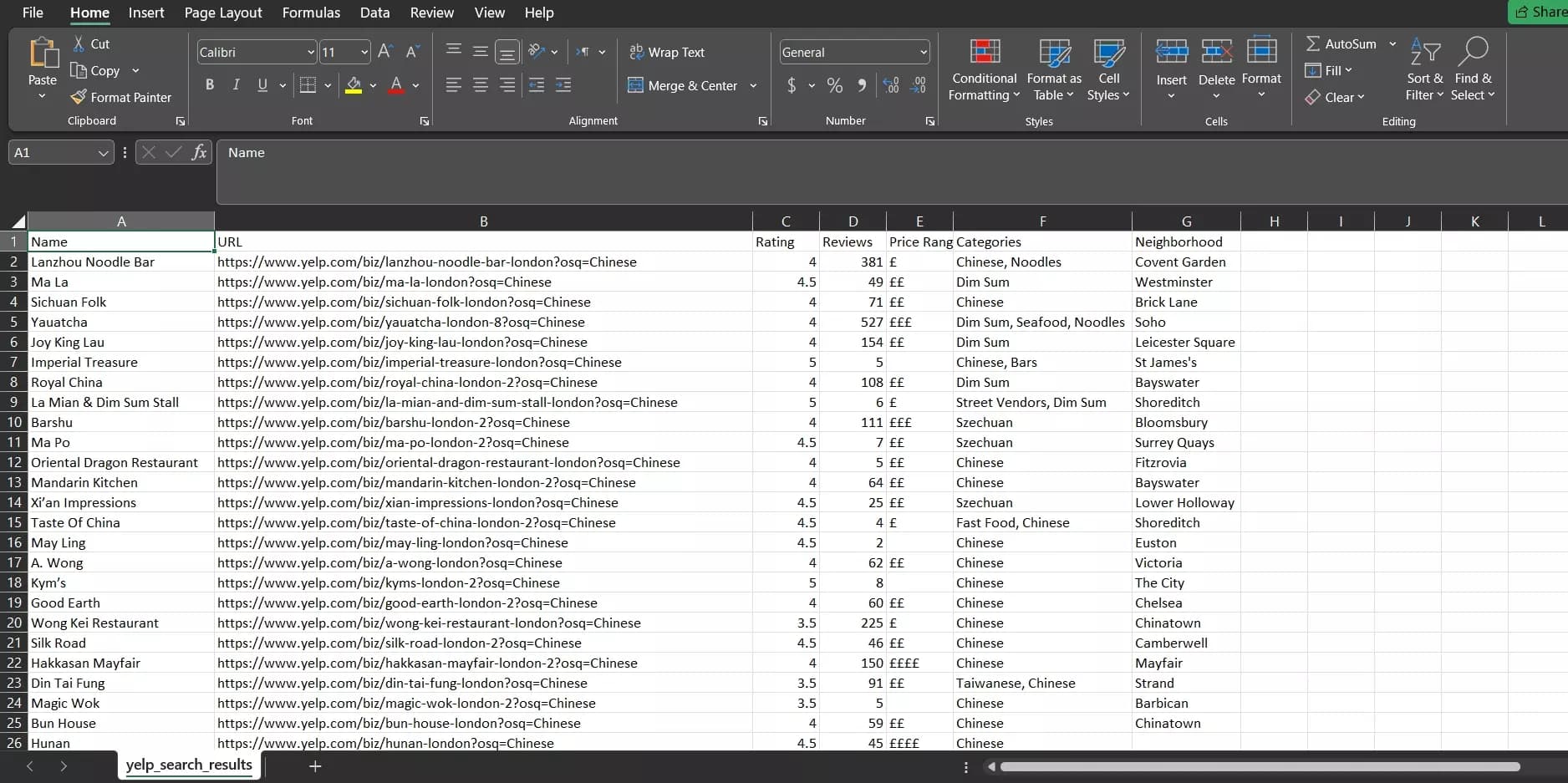
Et voici. 30 restaurants chinois situés à Londres extraits avec le nom, l'URL, la note, les avis, les catégories, et le quartier. Tout cela en seulement 17 secondes.
Limitations
Bien que notre scraper Yelp basé sur Python offre la commodité d'extraire les annonces de restaurants de Yelp, il a quelques limitations qui devraient être considérées. Ces limitations concernent l'étendue de l'extraction des données et l'absence de mesures pour contourner les anti-bots.
Tout d'abord, le scraper est incapable d'extraire les données des pages individuelles d'annonces, ce qui limite la profondeur et l'étendue des informations obtenues. Alors qu'il capture avec succès des attributs essentiels tels que le nom, la note, le quartier, et d'autres détails de base, il manque la capacité de naviguer vers les pages d'annonces individuelles et d'extraire des informations plus complètes comme les coordonnées, les heures d'ouverture, ou les éléments du menu.
De plus, l'absence de mesures anti-bots expose le scraper à la détection par les mécanismes de sécurité de Yelp. Cela peut entraîner une éventuelle interdiction de l'IP, entravant le processus de scraping et empêchant l'accès aux données de Yelp. Sans mesures anti-bots en place, la fiabilité et la scalabilité du scraper peuvent être compromises, posant des limitations pour les opérations de scraping à grande échelle ou l'extraction fréquente de données.
Conclusion
En conclusion, cet article a fourni un point de départ pour scraper les annonces de restaurants de Yelp en utilisant Python et la bibliothèque requests. Nous avons parcouru le code, en expliquant sa fonctionnalité et ses limitations. Si vous êtes curieux du web scraping ou si vous cherchez à apprendre le web scraping avec Python, nous espérons que cet article vous a été utile pour vous initier au processus.
Joyeux scraping 🦞