
Comment scraper des annonces immo avec l’API Lobstr.io pour SeLoger ?
(updated)
Il n’existe aucune API officielle fournie par SeLoger. Lobstr.io propose un service externe, totalement indépendant et non affilié à SeLoger, permettant d’extraire les données accessibles au public.
Vous avez peut-être déjà cherché un moyen d’extraire automatiquement les annonces SeLoger… sans succès, puisqu’il n’existe pas d’API officielle.
Mais ne vous inquiétez pas, on va arranger ça !
Dans ce guide, je vais vous montrer comment scraper facilement les annonces SeLoger avec l’API Lobstr.io pour SeLoger et Python, même si vous n’êtes pas un pro du code.
P.S. Si vous êtes juste là pour le code et que vous ne voulez pas lire tout l’article, voici le script complet.
Est-ce légal de scraper des annonces immobilières ?
⚠️ Disclaimer Ceci n’est pas un conseil juridique. Les règles sur le scraping peuvent évoluer, et leur application varie. Avant de scraper une plateforme, consultez un expert juridique**.

- Les données sont accessibles publiquement.
- Seule une partie dite non-substantielle de la base de données est récupérée.
Mais scraper des données en masse peut entraîner des conséquences légales.
Même si la collecte de données publiques est permise, il faut donc éviter de collecter une part trop importante des données ou de nuire au bon fonctionnement du site.
Si vous avez un doute, consultez un professionnel du droit avant de vous lancer.
Passons maintenant à la pratique.
Comment scraper des annonces immobilières sur SeLoger ?
Si vous cherchez une API officielle de SeLoger, mauvaise nouvelle : elle n’existe pas. Alors, comment récupérer les données ?
Deux options s’offrent à vous :

- Utiliser un scraper no-code – pas de code, juste quelques réglages
- Coder votre propre scraper – plus de contrôle, mais aussi plus de galères
Les outils no-code sont la solution la plus simple. Vous n’avez pas besoin de coder, gérer des proxys ou faire de la maintenance.
Il suffit de configurer le scraper, de le lancer et de récupérer vos données. C’est idéal pour les débutants ou ceux qui ne veulent pas s’embêter avec la partie technique.
Si vous voulez récupérer automatiquement des annonces SeLoger sans coder, essayez Lobstr.io’s SeLoger Search Export.
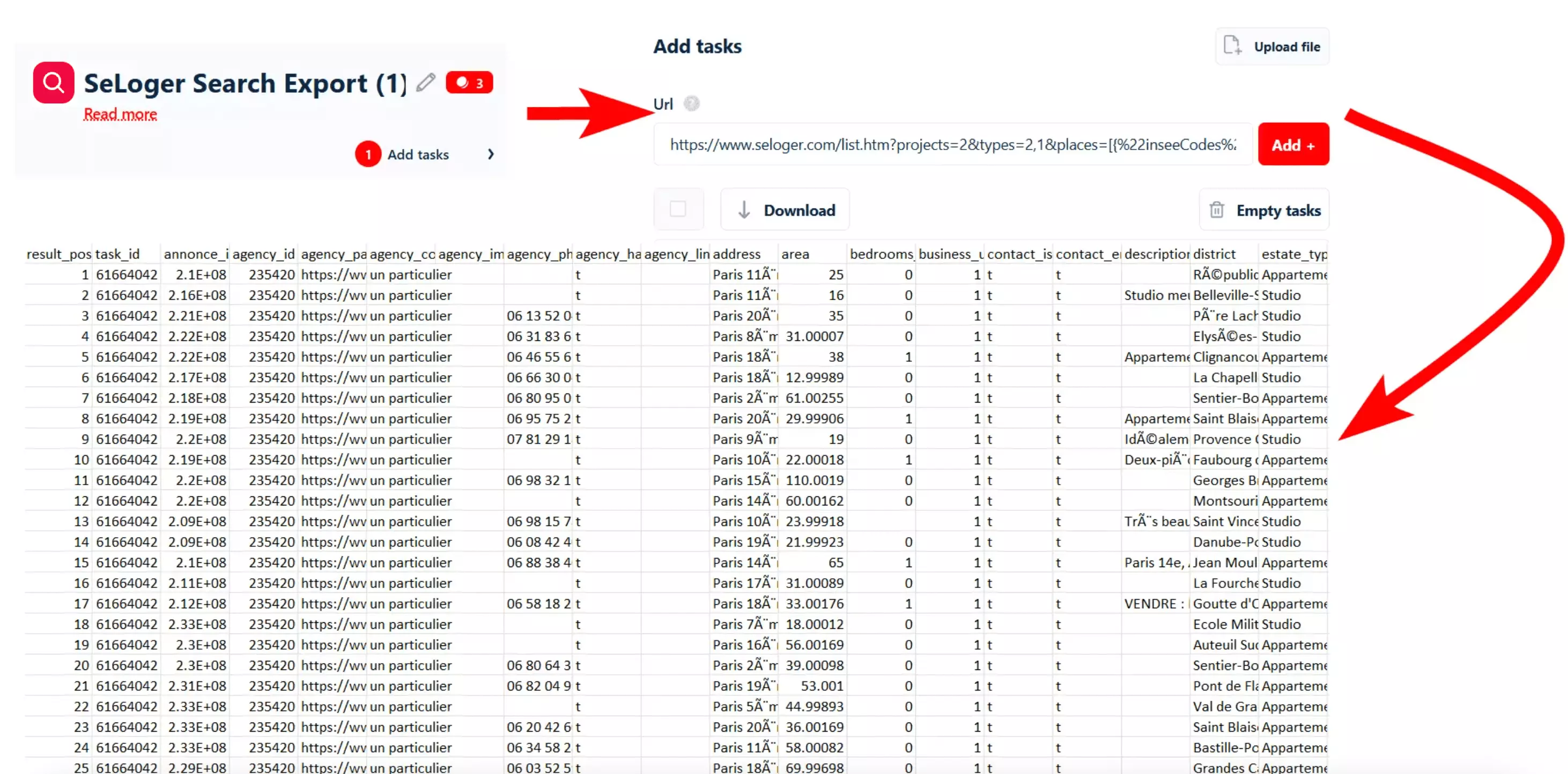
Mais les scrapers no-code sont souvent limités. Il est difficile de les adapter à un workflow spécifique.
C’est pour ça que les développeurs préfèrent les solutions programmatiques.
Mais coder un scraper de zéro, c’est loin d’être simple. Vous devez gérer les blocages, les captchas, les proxys et bien d’autres complications.
C’est pourquoi les solutions low-code et les API sont souvent le meilleur compromis. Elles offrent plus de flexibilité sans complexité inutile.
C’est pour cette raison que je vais utiliser l’API Lobstr.io pour SeLoger.
Comment scraper des annonces immobilières avec l’API Lobstr.io pour SeLoger ?
Avant de commencer à extraire des données immobilières, il faut préparer notre environnement. De quoi avons-nous besoin ?
- Une clé API Lobstr.io
- Un environnement de développement basique
1. Récupérer sa clé API Lobstr.io
Pour obtenir votre clé API, connectez-vous à votre compte Lobstr.io (ou créez-en un si ce n’est pas encore fait). Ensuite, cliquez sur le menu API dans la barre latérale gauche et copiez votre clé API.

2. Préparer son environnement de développement
Pour écrire et exécuter du code Python, assurez-vous d’avoir :
- Python installé (de préférence en version 3.x)
- Un éditeur de code
- Les bibliothèques nécessaires
Installer Python

Choisir un éditeur de code
3. Installer les bibliothèques Python nécessaires
requests
Sans elle, notre script ne pourrait pas communiquer avec l’API.
python-dotenv
Cela rend le script plus propre et plus sécurisé.
Pour installer ces bibliothèques, exécutez cette commande dans votre terminal :
pip install requests python-dotenvf
Tout est en place, on peut maintenant passer à l’action ! 🚀
Nous allons créer un scraper complet en 5 étapes :
C’est parti ! 🎯
Étape 1 - Authentification
Tout d’abord, il faut authentifier nos requêtes API en utilisant la clé API de Lobstr.io. Pour cela, copiez votre clé API depuis le tableau de bord Lobstr.io.
LOBSTR_API_KEY=your-api-key-heref
from dotenv import load_dotenv import os import sys # Load environment variables from .env file load_dotenv() # Fetch API key API_KEY = os.getenv("LOBSTR_API_KEY") # Check if API key is loaded if not API_KEY: sys.exit("Error: LOBSTR_API_KEY not set in .env file!")f
À partir de maintenant, le processus est assez similaire à l’application no-code de Lobstr.io. On va créer un Squid, ajouter des tâches, ajuster les paramètres et le lancer.
La seule différence ? Sur le tableau de bord, tout se fait en quelques clics, alors qu’avec l’API, on va écrire du code pour chaque étape.
Passons maintenant à l’étape suivante : créer notre Squid.
Étape 2 - Création d’un Squid
La première chose dont on a besoin pour créer un Squid, c’est un Crawler ID.
Lobstr.io ne propose pas uniquement une API pour SeLoger—nous offrons plus de 20 outils d’automatisation prêts à l’emploi. Chaque outil possède son propre Crawler ID, qui permet de spécifier quel type de données extraire.
Pour créer un Squid pour SeLoger, il faut d’abord trouver le bon Crawler ID, afin d’indiquer à l’API quel crawler utiliser.
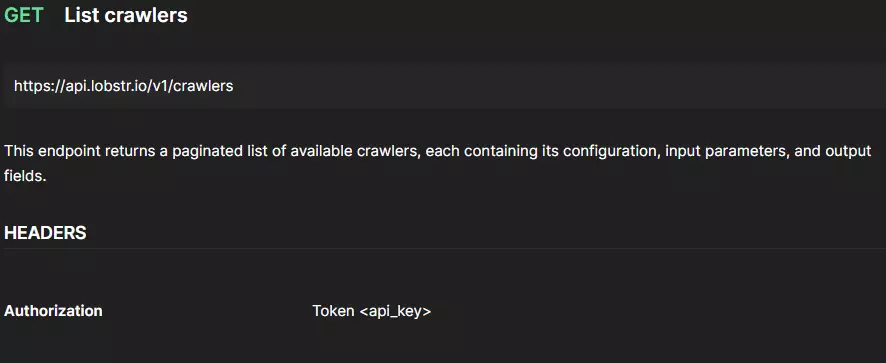
curl --location "https://api.lobstr.io/v1/crawlers" ^ --header "Authorization: <api-key>"f
Mauvaise idée, la sortie est illisible...
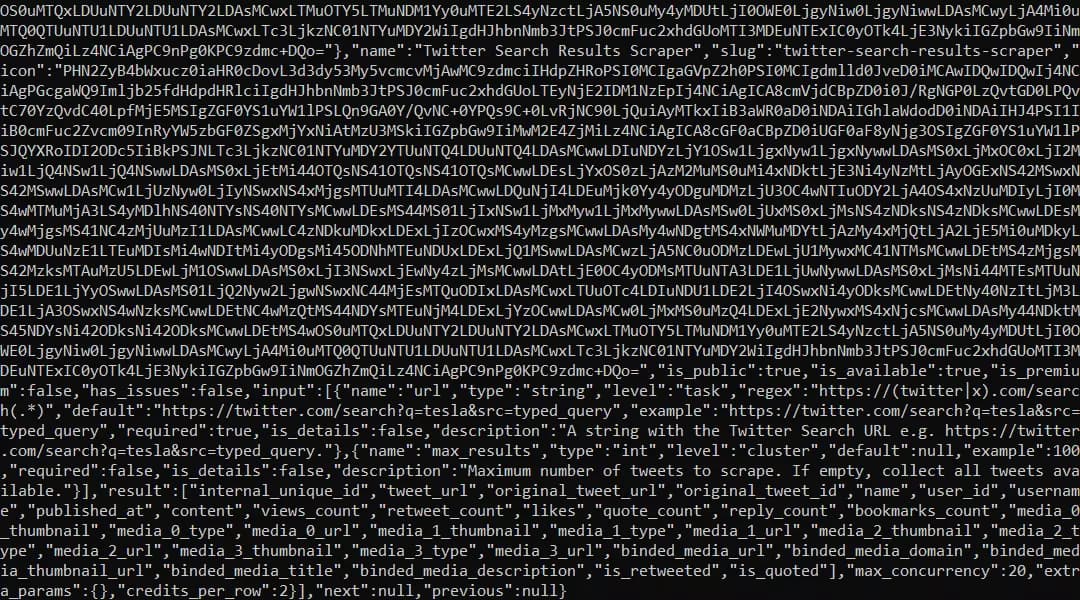
J’ai donc demandé de l’aide à GPT, et il me conseille d’utiliser Python. Vous pouvez aussi trouver des exemples de code Python dans la documentation.

Et voilà, on a récupéré notre Crawler ID ! 🎉

Maintenant qu’on a le Crawler ID, on peut créer un Squid.
Un Squid est une instance de scraping qui va récupérer les annonces SeLoger.
def create_squid(): CREATE_SQUID_URL = "https://api.lobstr.io/v1/squids" payload = {"crawler": "78f5839ee4b97c30e67eec391b907dd0"} print("Creating Squid...") resp = requests.post(CREATE_SQUID_URL, headers=HEADERS, json=payload) if not resp.ok: sys.exit(f"Error creating Squid: {resp.text}") squid_id = resp.json().get("id") if not squid_id: sys.exit("Error: Squid ID not found!") print(f"Squid created successfully! Squid ID: {squid_id}") return squid_id squid_id = create_squid()f
Maintenant que notre Squid est prêt, passons à l’ajout des tâches et à la mise à jour des paramètres. 🚀
Étape 3 - Ajouter des tâches et configurer le Squid
Dans ce contexte, une tâche correspond à une URL de recherche SeLoger que l’on va utiliser pour extraire les annonces immobilières.
def add_task(squid_id): task_url = ("https://www.seloger.com/list.htm?" "projects=2&types=1,2&places=[{%22inseeCodes%22:[750056]}]&" "qsVersion=1.0&m=homepage_new_search_classified_search_result") payload = {"tasks": [{"url": task_url}], "squid": squid_id} print("Adding task...") resp = requests.post(ADD_TASK_URL, headers=HEADERS, json=payload) if not resp.ok: sys.exit(f"Error adding task: {resp.text}") print("Task added successfully!")f
Avant de lancer notre Squid, on doit préciser :
- Combien de pages scraper ?
- Faut-il récupérer les détails complets des annonces ?
Comment trouver les bons paramètres ?

Les principaux paramètres à configurer :
- max_pages – Nombre maximum de pages à scraper
- annonce_details – Récupérer les détails complets des annonces en visitant chaque page
Mais on peut aller plus loin avec d’autres paramètres utiles :
- concurrency – Définit le nombre de threads (par défaut : 1)
- export_unique_results – Évite les doublons dans les résultats
- no_line_breaks – Supprime les sauts de ligne dans l’export CSV
- run_notify – Envoie une notification par email en cas de succès ou d’erreur
def update_squid(squid_id): url = f"https://api.lobstr.io/v1/squids/{squid_id}" payload = { "concurrency": 1, # Enable multi-threading "export_unique_results": True, # Remove duplicate results "no_line_breaks": True, # Format output for CSV "run_notify": "on_success", # Notify on completion "params": { "max_pages": 1, # Define number of pages to scrape "fill_results_details": {"annonce_details": False} } } print("Updating Squid...") resp = requests.post(url, headers=HEADERS, json=payload) if not resp.ok: sys.exit(f"Error updating Squid: {resp.text}") print("Squid updated successfully.")f
Et si on a plus de 100 URLs à scraper ?

On peut maintenant lancer notre scraper et collecter les annonces immobilières.
Étape 4 - Lancer le crawler
def start_run(squid_id): url = "https://api.lobstr.io/v1/runs" payload = {"squid": squid_id} print("Starting run...") resp = requests.post(url, headers=HEADERS, json=payload) if not resp.ok: sys.exit(f"Error starting run: {resp.text}") run_id = resp.json().get("id") if not run_id: sys.exit("Run ID not found!") print("Run started with ID:", run_id) return run_idf
Mais il faut aussi surveiller la progression de l’exécution.
Pourquoi ?
- S’assurer que le scraping est bien terminé avant de passer à l’étape suivante
- Détecter si le scraper se bloque ou rencontre une erreur
- Avoir des mises à jour en temps réel sur la quantité de données récupérées
def poll_run_progress(run_id): url = f"https://api.lobstr.io/v1/runs/{run_id}/stats" print("Polling for run progress:") while True: resp = requests.get(url, headers=HEADERS) if not resp.ok: sys.exit(f"Error retrieving run stats: {resp.text}") data = resp.json() percent_done = data.get("percent_done", "0%") results_done = data.get("results_done", 0) results_total = data.get("results_total", 0) sys.stdout.write(f"\rProgress: {percent_done} ({results_done}/{results_total} results)") sys.stdout.flush() if data.get("is_done"): print("\nRun is complete.") break time.sleep(2)f
Et maintenant, comment récupérer les résultats ? 🤔
Étape 5 - Télécharger les résultats
Une fois l’exécution terminée avec succès, Lobstr.io exporte automatiquement les résultats vers un bucket S3 et génère un lien de téléchargement temporaire contenant l’ensemble des données collectées.
⚠️ Le scraping peut prendre du temps avant que les résultats ne soient prêts.
Si on essaie de télécharger les données avant la fin de l’export, l’API renverra une erreur.
Comment être sûr que l’export est terminé ?

def poll_export_status(run_id): url = f"https://api.lobstr.io/v1/runs/{run_id}" print("Polling for export completion (export_done:true):") max_wait = 120 # Maximum time to wait (in seconds) interval = 5 # Check every 5 seconds elapsed = 0 while elapsed < max_wait: resp = requests.get(url, headers=HEADERS) if not resp.ok: sys.exit(f"Error retrieving run details: {resp.text}") data = resp.json() if data.get("export_done", False): print("Export is complete.\n") print("Run Details:") print("Status:", data.get("status")) print("Done Reason:", data.get("done_reason")) print("Duration:", data.get("duration")) print("Credit Used:", data.get("credit_used")) print("Total Results:", data.get("total_results")) print("Unique Results:", data.get("total_unique_results")) return print("Export not done yet. Waiting...") time.sleep(interval) elapsed += interval sys.exit("Export did not complete within expected time.")f
On va créer une fonction qui récupère l’URL et télécharge les résultats au format CSV.
def fetch_and_download_results(run_id): url = f"https://api.lobstr.io/v1/runs/{run_id}/download" print("Requesting download URL for run results...") resp = requests.get(url, headers=HEADERS) if not resp.ok: sys.exit(f"Error requesting download URL: {resp.text}") s3_url = resp.json().get("s3") if not s3_url: sys.exit("S3 URL not found!") print("Downloading CSV file from S3 URL...") csv_resp = requests.get(s3_url) if not csv_resp.ok: sys.exit(f"Error downloading CSV file: {csv_resp.text}") filename = "run_results.csv" with open(filename, "wb") as f: f.write(csv_resp.content) print(f"CSV file downloaded and saved as '{filename}'.")f
Plutôt que d’écrire une seule fonction, je vais séparer les tâches en plusieurs fonctions.
Pourquoi ?
- Réutilisabilité : On pourrait avoir besoin du lien S3 ailleurs dans le projet.
- Débogage plus simple : En cas d’erreur, on sait précisément où chercher.
def get_s3_url(run_id): url = f"https://api.lobstr.io/v1/runs/{run_id}/download" print("Requesting download URL for run results...") resp = requests.get(url, headers=HEADERS) if not resp.ok: sys.exit(f"Error requesting download URL: {resp.text}") s3_url = resp.json().get("s3") if not s3_url: sys.exit("S3 URL not found!") print("\nS3 URL for run results:") print(s3_url) return s3_urlf
def download_csv(s3_url): print("Downloading CSV file from S3 URL...") resp = requests.get(s3_url) if not resp.ok: sys.exit(f"Error downloading CSV file: {resp.text}") filename = "run_results.csv" with open(filename, "wb") as f: f.write(resp.content) print(f"CSV file downloaded and saved as '{filename}'.")f
Et si on veut envoyer les données directement vers un Google Sheet ?

def main(): squid_id = create_squid() update_squid(squid_id) add_task(squid_id) run_id = start_run(squid_id) poll_run_progress(run_id) poll_export_status(run_id) s3_url = get_s3_url(run_id) download_csv(s3_url) if __name__ == "__main__": main()f
Prêt à lancer ? 🤔
Hmm… avant ça, on va nettoyer et optimiser le code.
Un script brut peut fonctionner pour des petits tests, mais pour du scraping à grande échelle, on a besoin de stabilité, fiabilité et efficacité.
Perso, j’utilise l’IA pour ça. D’habitude, je demande à ChatGPT, mais en ce moment Claude Sonnet 3.7 est le meilleur modèle pour coder, donc on va l’utiliser.

Et voilà, mission accomplie ! 🚀
Code complet
import os import sys import time import requests from dotenv import load_dotenv from typing import Dict, Any, Optional, Tuple class LobstrAPISeLoger: """ A class to interact with the Lobstr API for web scraping Seloger real estate data. Handles the creation, configuration, and execution of scraping tasks through the Lobstr API. """ def __init__(self): # Load environment variables from .env file load_dotenv() # Get API key from environment variables self.api_key = os.getenv("LOBSTR_API_KEY") if not self.api_key: raise ValueError("LOBSTR_API_KEY not found in environment variables. Please add it to your .env file.") # Setup base headers for all API requests self.headers = { 'Authorization': f'Token {self.api_key}', 'Content-Type': 'application/json' } # Base URL for API requests self.base_url = "https://api.lobstr.io/v1" def _make_request(self, method: str, endpoint: str, payload: Optional[Dict[str, Any]] = None) -> Dict[str, Any]: """ Helper method to make API requests with proper error handling. Args: method: HTTP method (get, post, etc.) endpoint: API endpoint to call payload: JSON payload for the request (optional) Returns: JSON response data Raises: RuntimeError: If the API request fails """ url = f"{self.base_url}/{endpoint}" try: if method.lower() == "get": response = requests.get(url, headers=self.headers) elif method.lower() == "post": response = requests.post(url, headers=self.headers, json=payload) else: raise ValueError(f"Unsupported HTTP method: {method}") response.raise_for_status() # Raise exception for 4XX/5XX responses return response.json() except requests.exceptions.RequestException as e: # Catch all request-related exceptions error_msg = f"API request failed: {str(e)}" if hasattr(e, 'response') and e.response: error_msg += f" - Response: {e.response.text}" raise RuntimeError(error_msg) def create_squid(self, crawler_id: str = "78f5839ee4b97c30e67eec391b907dd0") -> str: """ Create a new squid (scraper) with the specified crawler. Args: crawler_id: ID of the crawler to use Returns: ID of the created squid """ print("Creating squid...") payload = {"crawler": crawler_id} response = self._make_request("post", "squids/", payload) squid_id = response.get("id") if not squid_id: raise ValueError("Squid ID not found in response") print(f"Squid created with ID: {squid_id}") return squid_id def update_squid(self, squid_id: str) -> None: """ Configure the squid with the desired parameters. Args: squid_id: ID of the squid to update """ print("Updating squid configuration...") payload = { "concurrency": 1, # number of bots "export_unique_results": True, "no_line_breaks": True, "to_complete": False, "params": { "max_pages": 1, "fill_results_details": {"annonce_details": False} }, "accounts": None, "run_notify": "on_success" } self._make_request("post", f"squids/{squid_id}", payload) print("Squid configuration updated successfully.") def add_task(self, squid_id: str, search_params: Optional[Dict[str, Any]] = None) -> None: """ Add a scraping task to the squid. Args: squid_id: ID of the squid to add the task to search_params: Optional custom search parameters (defaults to Paris apartments) """ print("Adding task to squid...") # Default task URL for Paris apartments task_url = ("https://www.seloger.com/list.htm?" "projects=2&types=1,2&places=[{%22inseeCodes%22:[750056]}]&" "qsVersion=1.0&m=homepage_new_search_classified_search_result") # Override with custom URL if search params are provided if search_params: # Code to build custom URL could be added here pass payload = {"tasks": [{"url": task_url}], "squid": squid_id} self._make_request("post", "tasks", payload) print("Task added successfully.") def start_run(self, squid_id: str) -> str: """ Start executing the squid's tasks. Args: squid_id: ID of the squid to run Returns: ID of the run """ print("Starting scraping run...") payload = {"squid": squid_id} response = self._make_request("post", "runs", payload) run_id = response.get("id") if not run_id: raise ValueError("Run ID not found in response") print(f"Run started with ID: {run_id}") return run_id def poll_run_progress(self, run_id: str, polling_interval: int = 2) -> None: """ Monitor the progress of a run until completion. Args: run_id: ID of the run to monitor polling_interval: Time in seconds between status checks """ print("Monitoring run progress:") while True: response = self._make_request("get", f"runs/{run_id}/stats") percent_done = response.get("percent_done", "0%") results_done = response.get("results_done", 0) results_total = response.get("results_total", 0) sys.stdout.write(f"\rProgress: {percent_done} ({results_done}/{results_total} results)") sys.stdout.flush() if response.get("is_done"): print("\nRun completed successfully.") break time.sleep(polling_interval) def wait_for_export(self, run_id: str, max_wait: int = 120, interval: int = 5) -> Dict[str, Any]: """ Wait for the export of results to complete. Args: run_id: ID of the run max_wait: Maximum wait time in seconds interval: Polling interval in seconds Returns: Run details """ print("Waiting for export completion...") elapsed = 0 while elapsed < max_wait: response = self._make_request("get", f"runs/{run_id}") if response.get("export_done", False): print("Export completed successfully.\n") print("Run Details:") print(f"Status: {response.get('status')}") print(f"Done Reason: {response.get('done_reason')}") print(f"Duration: {response.get('duration')}") print(f"Credit Used: {response.get('credit_used')}") print(f"Total Results: {response.get('total_results')}") print(f"Unique Results: {response.get('total_unique_results')}") return response print("Export still in progress. Waiting...") time.sleep(interval) elapsed += interval raise TimeoutError("Export did not complete within the expected time") def get_download_url(self, run_id: str) -> str: """ Get the S3 URL to download the results. Args: run_id: ID of the run Returns: S3 URL for downloading results """ print("Requesting download URL for results...") response = self._make_request("get", f"runs/{run_id}/download") s3_url = response.get("s3") if not s3_url: raise ValueError("S3 URL not found in response") print("\nS3 URL for run results:") print(s3_url) return s3_url def download_results(self, s3_url: str, filename: str = "run_results.csv") -> str: """ Download results from the provided S3 URL. Args: s3_url: URL to download the results from filename: Name of the file to save results to Returns: Path to the downloaded file """ print(f"Downloading results to '{filename}'...") try: response = requests.get(s3_url) response.raise_for_status() with open(filename, "wb") as f: f.write(response.content) print(f"Results downloaded successfully to '{filename}'.") return os.path.abspath(filename) except requests.exceptions.RequestException as e: raise RuntimeError(f"Failed to download results: {str(e)}") def run_complete_workflow(self, output_filename: str = "run_results.csv") -> Tuple[str, str]: """ Run the complete workflow from creating a squid to downloading results. Args: output_filename: Name of the file to save results to Returns: Tuple of (run_id, path to downloaded file) """ try: # Execute the complete workflow squid_id = self.create_squid() self.update_squid(squid_id) self.add_task(squid_id) run_id = self.start_run(squid_id) self.poll_run_progress(run_id) self.wait_for_export(run_id) s3_url = self.get_download_url(run_id) filepath = self.download_results(s3_url, output_filename) return run_id, filepath except Exception as e: print(f"Error during workflow execution: {str(e)}") raise def main(): """Main function to execute the complete workflow.""" try: # Create and run the LobstrAPISeLoger client client = LobstrAPISeLoger() run_id, filepath = client.run_complete_workflow() print("\nWorkflow completed successfully!") print(f"Run ID: {run_id}") print(f"Results saved to: {filepath}") except ValueError as e: print(f"Configuration error: {str(e)}") sys.exit(1) except RuntimeError as e: print(f"API error: {str(e)}") sys.exit(2) except TimeoutError as e: print(f"Timeout error: {str(e)}") sys.exit(3) except Exception as e: print(f"Unexpected error: {str(e)}") sys.exit(4) if __name__ == "__main__": main()f
Lançons le script :
python lobstrapiseloger.pyf


Voilà, on a maintenant notre propre scraper d’annonces immobilières, basé sur l’API Lobstr.io pour SeLoger. 🚀
Conclusion
Et voilà, vous savez maintenant comment scraper des annonces immobilières avec l’API Lobstr.io pour SeLoger.
SeLoger® est une marque déposée de SeLoger, Groupe AVIV. Ce tutoriel n’est ni approuvé, ni sponsorisé, ni affilié à SeLoger. Lobstr.io agit comme un outil d’extraction de données publiques, sous votre entière responsabilité. L’utilisation de ce script est soumise au respect des CGU de SeLoger et de la législation sur les bases de données. Lobstr.io fournit un outil technique ; l’utilisateur est seul responsable de la finalité et de la portée de la collecte.