
Comment scraper Bien'Ici avec Python et requests en 2023
Chapeau les pro!
Si vous avez besoin de collecter de la donnée immobilière publique, que ce soit pour des besoins d’investissement personnel, de veille de prix de marché, ou du développement d’une application tierce, ce tutoriel est fait pour vous.
Pré-requis
Avant de se lancer dans le grand bain, voilà les 4 éléments que l’on va installer:
Au niveau des librairies Python, on va installer 2 librairies supplémentaires.
D’abord, l’indispensable requests, la librairie externe Python la plus téléchargée au monde, qu’on ne présente plus, qui permet tout simplement de naviguer sur internet avec un script python.
Enfin, on va installer retry, une librairie qui permet, en cas d’erreur au sein d’une méthode, d’exécuter à nouveau cette méthode, passé un délai. Cela permet au code que l’on va construire de ne pas casser au moindre accroc. Et de bâtir un code résilient et solide.
$ pip3 install requests retryf
Et voilà, on est prêts. Let’s go!
Code complet
Voilà le code complet, et accessible depuis ce Git.
import requests import csv import time import argparse from urllib.parse import urlparse, parse_qs import json import copy from retry import retry import re MIN_PAGE_VAL = 1 MAX_PAGE_VAL = 100 HEADERS = { 'authority': 'www.bienici.com', 'accept': '*/*', 'accept-language': 'fr-FR,fr;q=0.9', 'referer': 'https://www.bienici.com/recherche/achat/france/chateau?page=2&camera=11_2.3469385_48.8588675_0.9_0', 'sec-ch-ua': '"Not.A/Brand";v="8", "Chromium";v="114", "Google Chrome";v="114"', 'sec-ch-ua-mobile': '?0', 'sec-ch-ua-platform': '"macOS"', 'sec-fetch-dest': 'empty', 'sec-fetch-mode': 'cors', 'sec-fetch-site': 'same-origin', 'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36', 'x-requested-with': 'XMLHttpRequest', } FIELDNAMES = [ 'city', 'postal_code', 'ad_type', 'property_type', 'reference', 'title', 'publication_date', 'modification_date', 'new_property', 'rooms_quantity', 'bedrooms_quantity', 'price', 'photos' ] BOOLEAN_VALUES = { "newProperty": True, "isOnLastFloor": True, "isGroundFloor": True, "isNotGroundFloor": True, "hasPool": True, "hasBalcony": True, "hasTerrace": True, "hasBalconyOrTerrace": True, "hasCellar": True, "hasParking": True, "hasFirePlace": True, "hasDoorCode": True, "hasIntercom": True, "hasGarden": True, "hasElevator": True, "workToDo": False, "has3DModel": True, "flatSharingNotAllowed": False, "isBuildingPlot": True, "isExclusiveSaleMandate": True, "hasCaretaker": True, "isDuplex": True, "hasSeparateToilet": True, "isFurnished": True, "isNotFurnished": True, "hasPhoto": True, "onTheMarket": True, "isPreview": True, "isEligibleForPinelLaw": True, "isEligibleForDenormandieLaw": True, "exportableAd": True, "isInStudentResidence": True, "isInSeniorResidence": True, "isInTourismResidence": True, "isInManagedResidence": True, "isNotInResidence": True, "isNotLifeAnnuitySale": True, "isLifeAnnuitySaleOnly": True, "needProfessionalPict": True, "needVirtualTour": True, "needHomeStaging": True, "hasNoPhoto": True, "hasNoAddress": True, "hasAddress": True, "hasNoPrice": True, "isPromotedAsExclusive": True, "hasToBeBuilt": True, "hasNotToBeBuilt": True, "opticalFiberStatus": "deploye", "chargingStations": True } ENERGY_CLASSIFICATION_VALUES = ["energyClassification"] NUMBER_VALUES = ["minPrice", "maxPrice", "minBedrooms", "maxBedrooms", "minArea", "maxArea", "minGardenSurfaceArea", "maxGardenSurfaceArea"] # Property URL parameters mapping URL_PARAMETERS = { "minPrice": "prix-min", "maxPrice": "prix-max", "minArea": "surface-min", "maxArea": "surface-max", "page": "page", "camera": "camera", "newProperty": "neuf", "onTheMarket": "disponible", "isPreview": "en-avant-premiere", "listMode": "mode", "mapMode": "carte", "limit": "limite", "isOnLastFloor": "dernier-etage", "has3DModel": "modelisation-3d", "isLeading": "a-la-une", "highlighted": "recommande", "isGroundFloor": "rez-de-chaussee", "isNotGroundFloor": "pas-au-rez-de-chaussee", "hasPool": "piscine", "hasBalcony": "balcon", "hasTerrace": "terrasse", "hasBalconyOrTerrace": "balcon-ou-terrasse", "hasCellar": "cave", "hasParking": "parking", "hasFirePlace": "cheminee", "hasDoorCode": "digicode", "hasIntercom": "interphone", "hasGarden": "jardin", "hasElevator": "ascenseur", "workToDo": "sans-travaux", "flatSharingNotAllowed": "colocation-autorisee", "isBuildingPlot": "constructible", "isExclusiveSaleMandate": "exclusif", "hasCaretaker": "gardien", "isDuplex": "duplex", "hasSeparateToilet": "toilettes-separees", "isFurnished": "meuble", "isNotFurnished": "non-meuble", "hasPhoto": "photo", "geocoding": "geocoding", "reference": "reference", "queryString": "query-string", "adsNestedQueryString": "nested-query-string", "contactRequestsNestedQueryString": "contacts-nested-query-string", "isEligibleForPinelLaw": "eligible-loi-pinel", "isEligibleForDenormandieLaw": "eligible-loi-denormandie", "energyClassification": "classification-energetique", "exportableAd": "multidiffusable", "extensionType": "recherche-etendue", "isInStudentResidence": "residence-etudiants", "isInSeniorResidence": "residence-seniors", "isInTourismResidence": "residence-tourisme", "isInManagedResidence": "residence-geree", "isNotInResidence": "pas-en-residence", "isNotLifeAnnuitySale": "viagers-exclus", "isLifeAnnuitySaleOnly": "viagers-uniquement", "excludeAgencyNew": "8", "needProfessionalPict": "amelioration-photos-professionnelles", "needVirtualTour": "amelioration-visites-virtuelles", "needHomeStaging": "amelioration-home-staging-virtuels", "hasNoPhoto": "annonces-sans-photo", "hasNoAddress": "annonces-sans-adresse", "hasAddress": "annonces-avec-adresse", "hasNoPrice": "annonces-sans-prix", "minBedrooms": "chambres-min", "maxBedrooms": "chambres-max", "minGardenSurfaceArea": "surface-terrain-min", "maxGardenSurfaceArea": "surface-terrain-max", "isPromotedAsExclusive": "avant-premiere-bienici", "is3dHighlighted": "en-avant-en-3d", "hasToBeBuilt": "maisons-a-construire", "hasNotToBeBuilt": "maisons-a-construire-exclues", "opticalFiberStatus": "fibre", "chargingStations": "recharge-vehicule-electrique" } # Reverse mapping of URL parameters REVERSED_URL_PARAMETERS = {v: k for k, v in URL_PARAMETERS.items()} # Sort options mapping SORT_OPTIONS = { "price": "prix", "pricePerSquareMeter": "prixm2", "surfaceArea": "surface", "roomsQuantity": "pieces", "relevance": "pertinence", "relevanceDev": "pertinencedev", "publicationDate": "publication", "modificationDate": "modification", "views": "vue", "viewers": "visiteurs", "followers": "favoris", "contactRequests": "contacts", "phoneDisplays": "appels" } # Reverse mapping of sort options REVERSED_SORT_OPTIONS = {v: k for k, v in SORT_OPTIONS.items()} FILTER_TYPE_OPTIONS = { "achat": "buy", "location": "rent" } FRENCH_SLUG_TO_DB = { "parkingbox":"parking", "maison":"house", "maisonvilla":"house", "appartement":"flat", "parking":"parking", "terrain":"terrain", "batiment":"building", "chateau":"castle", "loft":"loft", "bureau":"office", "local":"premises", "commerce":"shop", "hotel":"townhouse", "annexe":"annexe", "autres":"others" } DEFAULT_PROPERTY_TYPES = ["house","flat","loft","castle","townhouse"] DEFAULT_SORT_BY = ("relevance","desc") ROOMS_PATTERN_PLUS = re.compile(r"(\d+)-pi[èe]ces?-et-plus") ROOMS_PATTERN_MINUS = re.compile(r"(\d+)-pi[èe]ces?-et-moins") ROOMS_PATTERN_RANGE = re.compile(r"de-(\d+)-a-(\d+)-?pi[èe]ces?") ROOMS_PATTERN_SINGLE = re.compile(r"(\d+)-pi[èe]ces?") class BienIciScraper: def __init__( self, url, limit, output ): self.s = requests.Session() self.s.headers = HEADERS self.DATA = [] self.total_scraped_results = 0 self.page = 1 self.limit = limit self.url = url self.output = output assert all([self.url, self.limit, self.output]) def convert_url_to_api_parameters(self, url): """ Convert a URL to API parameters for the Bienici API. Args: url (str): The URL to convert. Returns: dict: The API parameters. Raises: AssertionError: If the input URL is not provided or if any expected assertions fail during the conversion process. """ PARAMS = {"filters":{}} FILTERS = PARAMS["filters"] FILTERS["size"] = 24 FILTERS["from"] = None FILTERS["page"] = None FILTERS["onTheMarket"] = [True] parsed_url = urlparse(url) query_params = parse_qs(parsed_url.query) path = parsed_url.path # /marseille-13000,paris-75000,montpellier-34000/ # /france/ location_ids = self.get_location_ids(path) if location_ids: FILTERS["zoneIdsByTypes"] = {"zoneIds":location_ids} # /location/ for k, v in FILTER_TYPE_OPTIONS.items(): if k in path: FILTERS["filterType"] = FILTER_TYPE_OPTIONS[k] # /maisonvilla,appartement,loft,chateau,bureau,hotel _property_types_values = [] for k, v in FRENCH_SLUG_TO_DB.items(): if k in path: _property_types_values.append(v) _property_types_values = _property_types_values if _property_types_values else DEFAULT_PROPERTY_TYPES FILTERS["propertyType"] = _property_types_values # /10-pieces-et-plus min_rooms = None max_rooms = None if ROOMS_PATTERN_PLUS.findall(path): min_rooms = int(ROOMS_PATTERN_PLUS.findall(path)[0]) elif ROOMS_PATTERN_MINUS.findall(path): min_rooms = int(ROOMS_PATTERN_MINUS.findall(path)[0]) elif ROOMS_PATTERN_RANGE.findall(path): min_rooms = int(ROOMS_PATTERN_RANGE.findall(path)[0]) max_rooms = int(ROOMS_PATTERN_RANGE.findall(path)[1]) elif ROOMS_PATTERN_SINGLE.match(path): min_rooms = int(ROOMS_PATTERN_SINGLE.findall(path)[0]) if min_rooms: FILTERS["minRooms"] = min_rooms if max_rooms: FILTERS["maxRooms"] = max_rooms # additional parameters if query_params: for k, v in query_params.items(): # prix-min=50 if k in REVERSED_URL_PARAMETERS.keys(): if REVERSED_URL_PARAMETERS[k] in NUMBER_VALUES: FILTERS[REVERSED_URL_PARAMETERS[k]] = int(v[0]) # balcon=oui if k in REVERSED_URL_PARAMETERS.keys() and REVERSED_URL_PARAMETERS[k] in BOOLEAN_VALUES.keys(): FILTERS[REVERSED_URL_PARAMETERS[k]] = BOOLEAN_VALUES[REVERSED_URL_PARAMETERS[k]] # classification-energetique=F if k == 'classification-energetique': FILTERS["energyClassification"] = v[0].split(',') # tri=surface-desc if k == 'tri': for s in v: t, w = s.split('-') assert all([t,w]) FILTERS["sortBy"] = t FILTERS["sortOrder"] = w if not "sortBy" in FILTERS.keys(): t,w = DEFAULT_SORT_BY FILTERS["sortBy"] = t FILTERS["sortOrder"] = w assert PARAMS return PARAMS @retry(AssertionError, tries=3, delay=5, backoff=2) def get_location_ids(self, path): """ Retrieve location IDs for the given path. Args: path (str): The path containing the locations to retrieve IDs for. Returns: list: A list of location IDs. Raises: AssertionError: If the path is not provided, or if an expected assertion fails during the retrieval process. """ assert path and isinstance(path, str) # https://www.bienici.com/recherche/location/marseille-13000,paris-75000,montpellier-34000/ path = [p for p in path.split('/') if p] locations = path[2].split(',') if len(locations) == 1 and "".join(locations) == 'france': return [] location_ids = [] for l in locations: url = 'https://res.bienici.com/suggest.json?q=%s' % l print('searching location id for %s' % l) response = requests.get(url, headers=HEADERS) assert response.status_code == 200 location_dict = response.json()[0] location_ids_list = location_dict["zoneIds"] assert location_ids_list for l in location_ids_list: print('found %s' % l) location_ids.append(l) return location_ids @retry(AssertionError, tries=3, delay=5, backoff=2) def go_api_page(self, params): """ Send a GET request to the API page with the specified parameters. Args: params (dict): The parameters to include in the GET request. Returns: requests.Response: The response object from the API page. Raises: AssertionError: If the response status code is not 200 (OK) after retrying. """ print('going to page: %s' % self.page) response = self.s.get('https://www.bienici.com/realEstateAds.json', params=params, headers=HEADERS) assert response.status_code == 200 return response def collect_results(self): """ Collect the results by making API requests and scraping the data. Raises: AssertionError: If any of the assertions fail during the data collection process. """ params = self.convert_url_to_api_parameters(self.url) assert params while True: assert self.page and isinstance(self.page, int) params["filters"]["page"] = self.page params["filters"]["from"] = (self.page-1)*24 _params = copy.deepcopy(params) _params["filters"] = json.dumps(_params["filters"]) assert _params response = self.go_api_page(_params) total_available_results = response.json()["total"] assert total_available_results is not None and isinstance(total_available_results, int) if self.limit: total_results_to_scrape = min(total_available_results, 2500, self.limit) else: total_results_to_scrape = min(total_available_results, 2500) assert all([total_available_results, total_results_to_scrape]) if self.page == 1: print("total results: %s" % total_available_results) print("total results to scrape: %s" % total_results_to_scrape) ads = response.json()["realEstateAds"] for ad in ads: d = self.parse_ad(ad) self.DATA.append(d) self.total_scraped_results += 1 if self.limit: if self.total_scraped_results == self.limit: print('limit reached') self.write_to_csv() return if self.total_scraped_results >= total_available_results: print('all data collected') break self.page += 1 self.write_to_csv() def parse_ad(self, ad): """ Parse the given ad data dictionary and extract relevant information. Args: ad (dict): A dictionary containing ad information. Returns: dict: A dictionary containing extracted ad information. """ assert ad and isinstance(ad, dict) city = ad.get("city","") postal_code = ad.get("postalCode","") ad_type = ad.get("adType","") property_type = ad.get("propertyType","") reference = ad.get("reference","") title = ad.get("title","") publication_date = ad.get("publicationDate","") modification_date = ad.get("modificationDate","") new_property = ad.get("newProperty","") rooms_quantity = ad.get("roomsQuantity","") bedrooms_quantity = ad.get("bedroomsQuantity","") price = ad.get("price","") photos = ", ".join([u.get("url_photo","") for u in ad.get("photos",[])]) VALUES = [ city, postal_code, ad_type, property_type, reference, title, publication_date, modification_date, new_property, rooms_quantity, bedrooms_quantity, price, photos ] print("scraped: %s" % title) d = dict(zip(FIELDNAMES, VALUES)) return d def write_to_csv(self): """ Write the extracted data to a CSV file. Requires that the 'DATA' attribute of the class is properly populated. Raises: AssertionError: If the 'DATA' attribute is not populated. """ assert self.DATA with open('data_bienici_lobstr_io.csv', 'w') as f: writer = csv.DictWriter(f, fieldnames=FIELDNAMES) writer.writeheader() for d in self.DATA: writer.writerow(d) print('csv written') def range_limited_integer_type(arg): try: f = int(arg) except ValueError: raise argparse.ArgumentTypeError("must be an integer") if f < MIN_PAGE_VAL or f > MAX_PAGE_VAL: raise argparse.ArgumentTypeError("must be < " + str(MAX_PAGE_VAL) + " and > " + str(MIN_PAGE_VAL)) return f if __name__ == '__main__': s = time.perf_counter() parser = argparse.ArgumentParser(description='bienici listings scraper') parser.add_argument( '-u', '--url', type=str, required=False, default='https://www.bienici.com/recherche/achat/france/chateau', help='url to scrape the listings from -- by default https://www.bienici.com/recherche/achat/france/chateau' ) parser.add_argument( '-l', '--limit', type=range_limited_integer_type, required=False, default=100, help='maximum number of listings to scrape -- by default 100' ) parser.add_argument( '-o', '--output', type=str, required=False, default='data_bienici_lobstr_io.csv', help='filename to save the results -- by default data_bienici_lobstr_io.csv' ) args = parser.parse_args() url = args.url limit = args.limit output = args.output b = BienIciScraper( url=url, limit=limit, output=output ) b.collect_results() elapsed = time.perf_counter() - s elapsed_formatted = "{:.2f}".format(elapsed) print("elapsed:", elapsed_formatted, "s") print('''~~ success _ _ _ | | | | | | | | ___ | |__ ___| |_ __ __ | |/ _ \| '_ \/ __| __/| '__| | | (_) | |_) \__ \ |_ | | |_|\___/|_.__/|___/\__||_| ''')f
Vous allez pouvoir télécharger le fichier, et le lancer depuis la ligne de commande, en précisant 3 paramètres:
- u — l’URL de recherche Bien’Ici, par defaut https://www.bienici.com/recherche/achat/france/chateau
l — le nombre maximal de listings à aller chercher, par défaut on va aller chercher les 100 premiers listings
o — le nom du fichier .csv dans lequel les données vont être enregistrées, par défaut databienicilobstr_io.csv
Et ce qui nous donne :
$ python3 bienici-listings-scraper.py -u https://www.bienici.com/recherche/achat/france/chateau -l 10 -o my_cool_file.csv going to page: 1 total results: 577 total results to scrape: 10 scraped: Domaine 6 hectares proche Etretat scraped: Château à vendre dans le lot avec dépendances et piscine. scraped: Manoir 15 pièces BIVIERS scraped: ANCIENNE DEPENDANCE DE L'ABBAYE DE CONQUES, CONSTITUEE D'UN CHATEAU scraped: Château scraped: Vente Château 8 pièces scraped: DOMAINE D'EXCEPTION MONTS DU LYONNAIS scraped: Château scraped: Eyzines - Domaine de 463m² avec 6800m² de terrain - piscine - dépendance scraped: SOUS OFFRE - Magnifique Château du 17ème siècle avec concier limit reached csv written elapsed: 0.22 s ~~ success _ _ _ | | | | | | | | ___ | |__ ___| |_ __ __ | |/ _ \| '_ \/ __| __/| '__| | | (_) | |_) \__ \ |_ | | |_|\___/|_.__/|___/\__||_|f
A nous la vie de Château.
🏰
Tutoriel étape par étape
Dans ce tutoriel, on va voir comment scraper toutes les annonces immobilières depuis n’importe quelle URL de recherche Bien’Ici, et jusqu’à la page qui nous plaît. Et ce quel que soit l’attribut de filtre utilisé, le mode de tri, ou la localisation choisie.
Un scraper exhaustif et universel.
Et parce qu’on aime les belles choses, on va, dans le cadre du développement, commencer par scraper avec les châteaux en France.
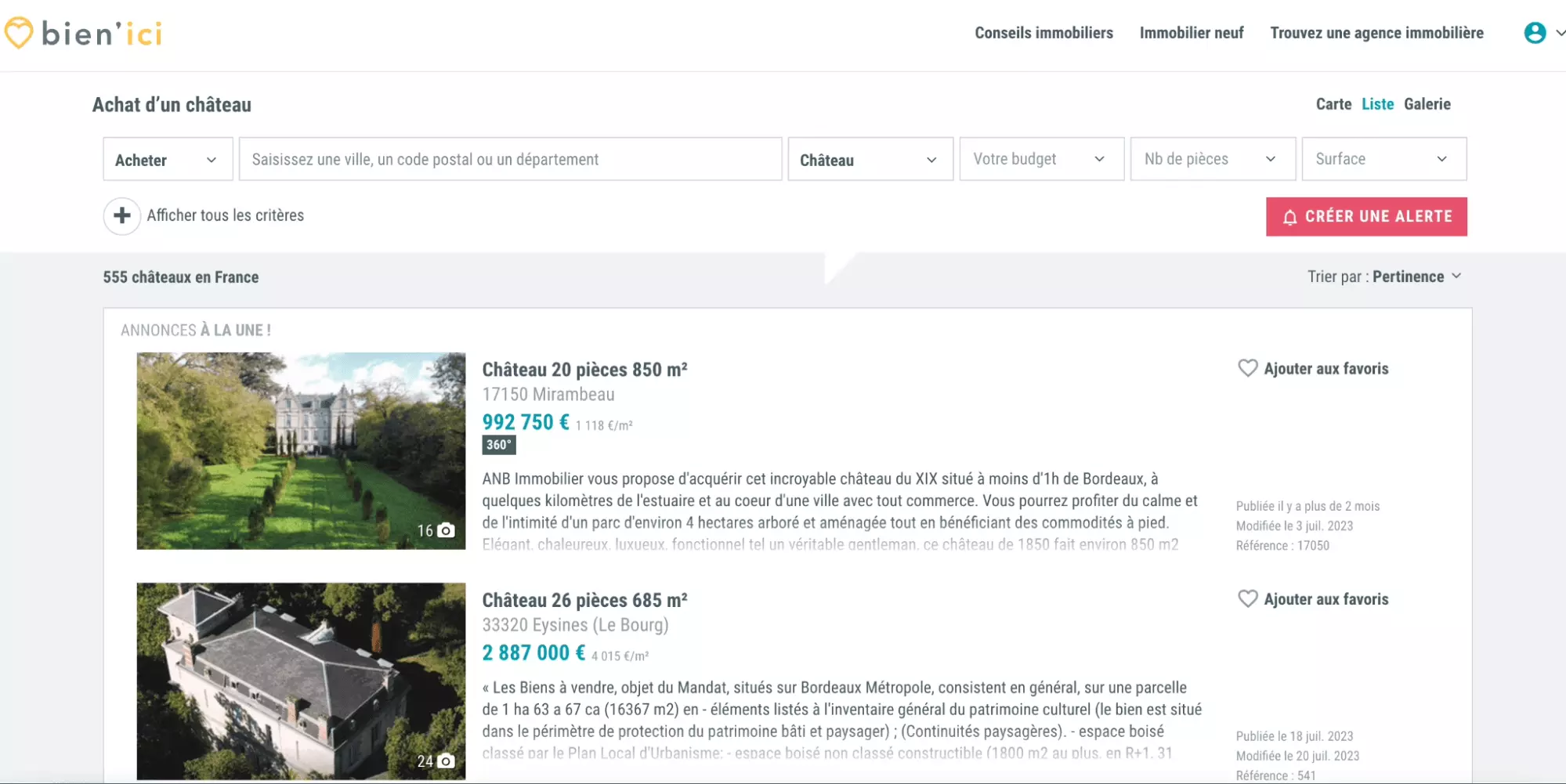
C’est pas mal hein. C’est français
🥹
Et on va récupérer, pour chaque annonce, 13 attributs distincts:
- city
- postal_code
- ad_type
- property_type
- reference
- title
- publication_date
- modification_date
- new_property
- rooms_quantity
- bedrooms_quantity
- price
- photos
Et comme illustré ci-dessous:
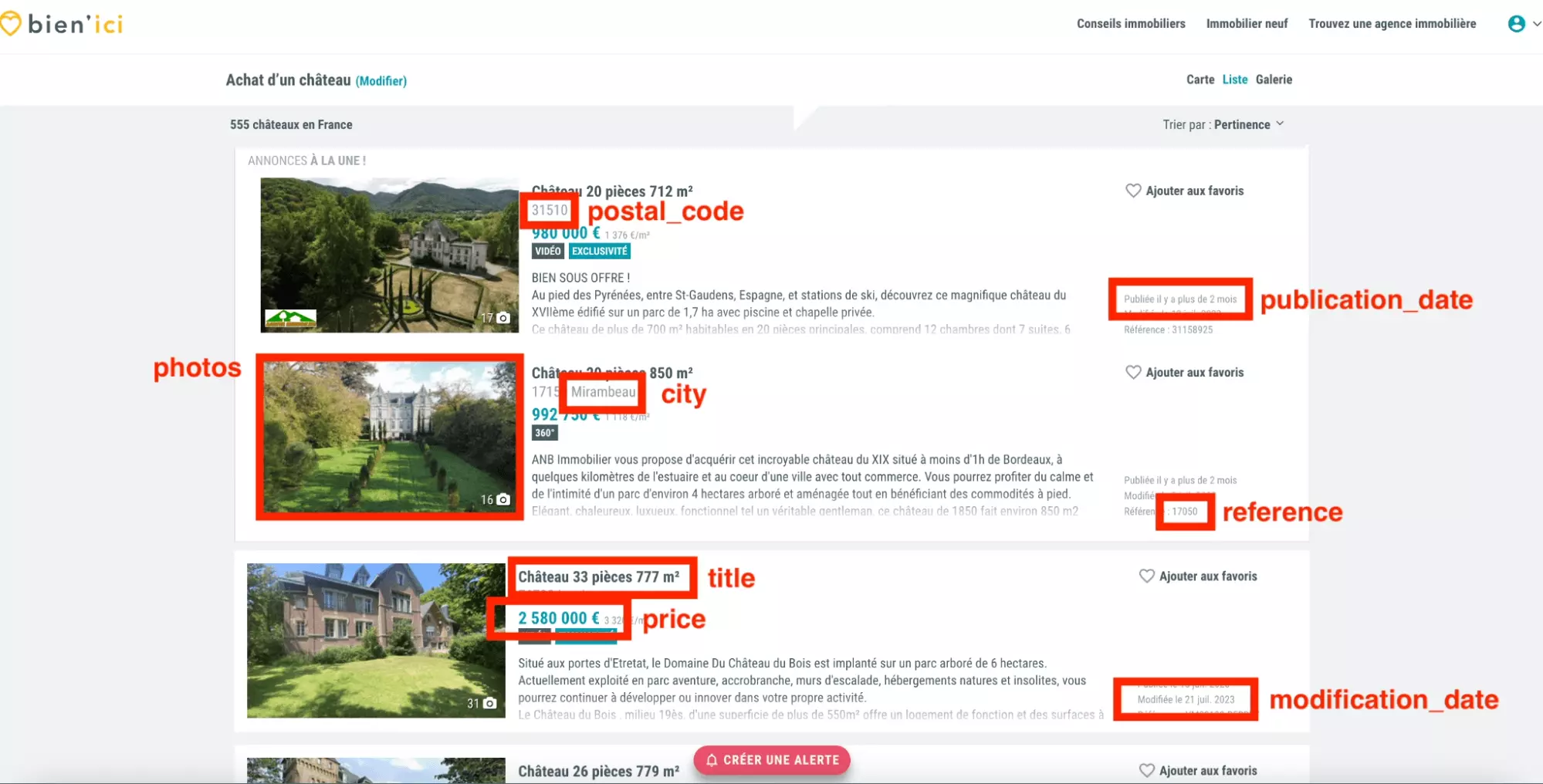
Certains attributs ne sont pas illustrés sur l’imprimé-écran ci-dessus: le type d’annonce, le type de propriété, le nombre de chambres et de pièces. C’est normal, ils sont présents dans le code source, mais pas visibles directement. On va les retrouver ensuite!
Et ce tutoriel va se passer en 7 sympathiques étapes distinctes:
- Identification de la requête cURL principale
- Conversion de l’URL en requête API
- Récupération de la localisation
- Navigation d’une page à l’autre
- Parsing des données
- Sauvegarde des données au format .csv
- Ajout de variables dynamiques
Allons-y!
1. Identification de la requête cURL principale
Ensuite, on ouvre l’onglet Network, qui va simplement nous permettre d’observer les requêtes, toutes les requêtes, qui sont échangées entre le site cible et notre navigateur.
Enfin, on va passer de la page 1 à la page 2, pour que des requêtes soient à nouveau échangées entre le site cible et notre navigateur. Les requêtes vont s’afficher au niveau de l’onglet Network, et on va pouvoir isoler et reproduire la requête qui contient les données que l’on veut récupérer.
OKK toutes les requêtes ont été proprement enregistrées.
Mais comment trouver la requête qui contient les données que l’on souhaite récupérer?
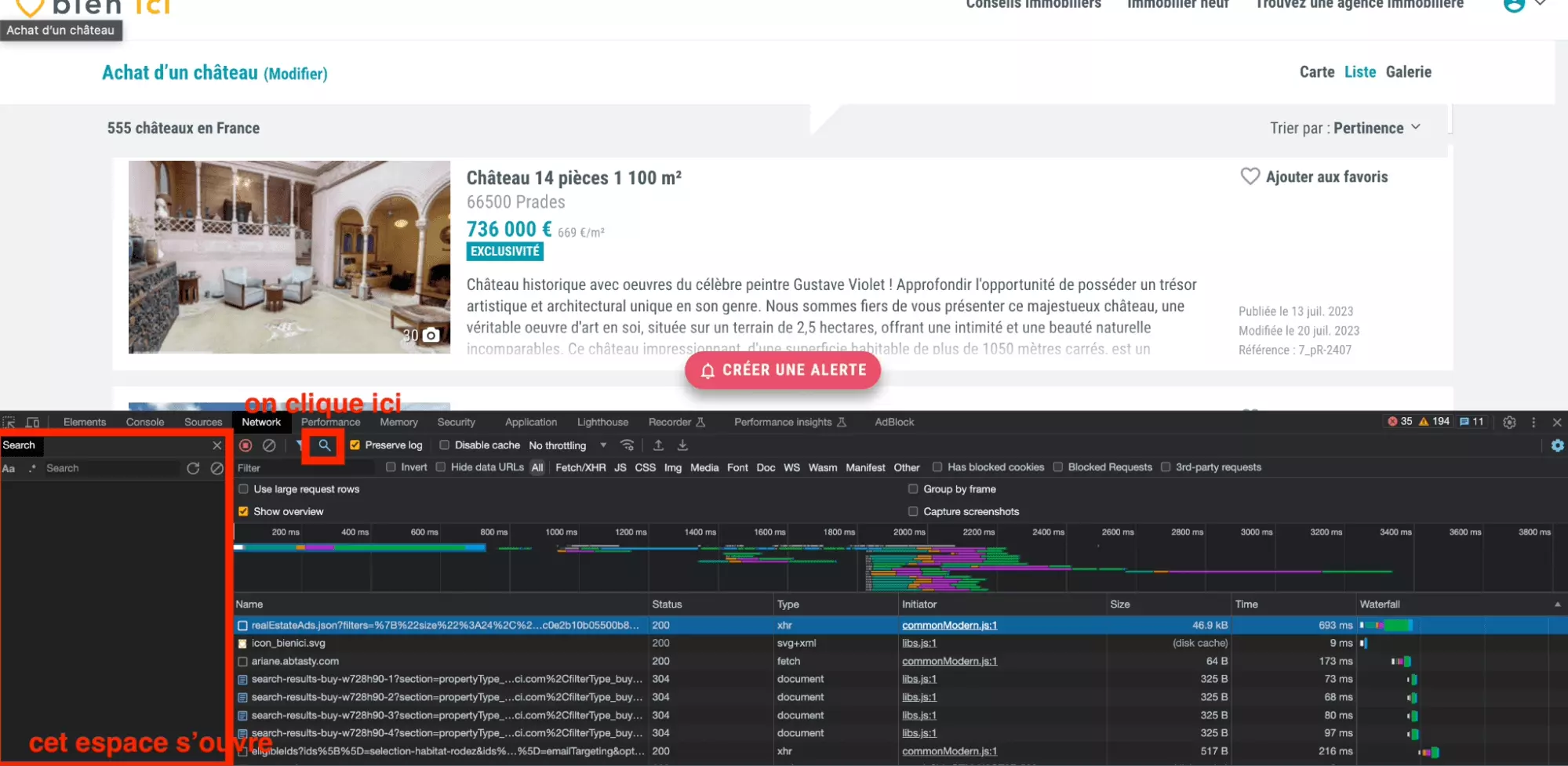
Et bien c’est très simple, on va utiliser l’outil de recherche de l’onglet Network, qui permet de chercher un élément de texte parmi toutes les requêtes enregistrées.
Ici, on va chercher le texte Gustave Violet.
C'est-à-dire qu’on va essayer d’identifier la requête échangée entre le navigateur et le site-cible qui a permis de récupérer la chaîne de caractère Gustave Violet.
On va donc d’abord commencer par ouvrir l’outil de Recherche parmi les requêtes depuis l’onglet Network:
Puis on va ensuite chercher depuis l’outil de recherche, un mot clé précis présent de la page. Il faut choisir un mot qui soit suffisamment précis, pour que l’on tombe exactement sur la requête qui a permis le transfert de cette donnée du serveur vers notre navigateur.
Dans notre cas, on va donc choisir… Gustave Violet!
On tape donc le mot clé dans la barre de recherche, afin d’identifier la requête réalisée par le navigateur qui a permis de récupérer cette chaîne de caractères.
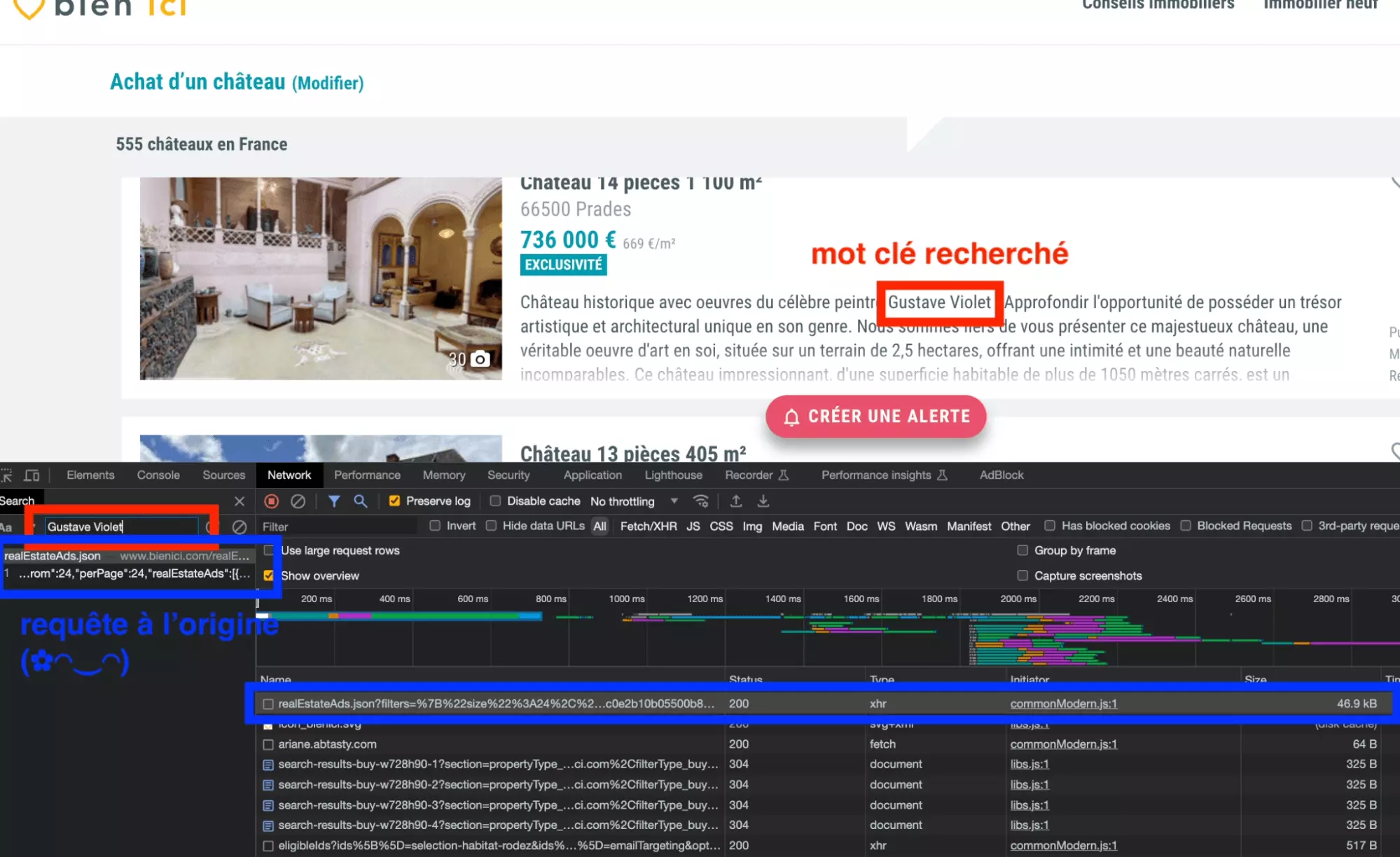
Et magnifique la requête apparaît!
La voilà, tout en majesté:
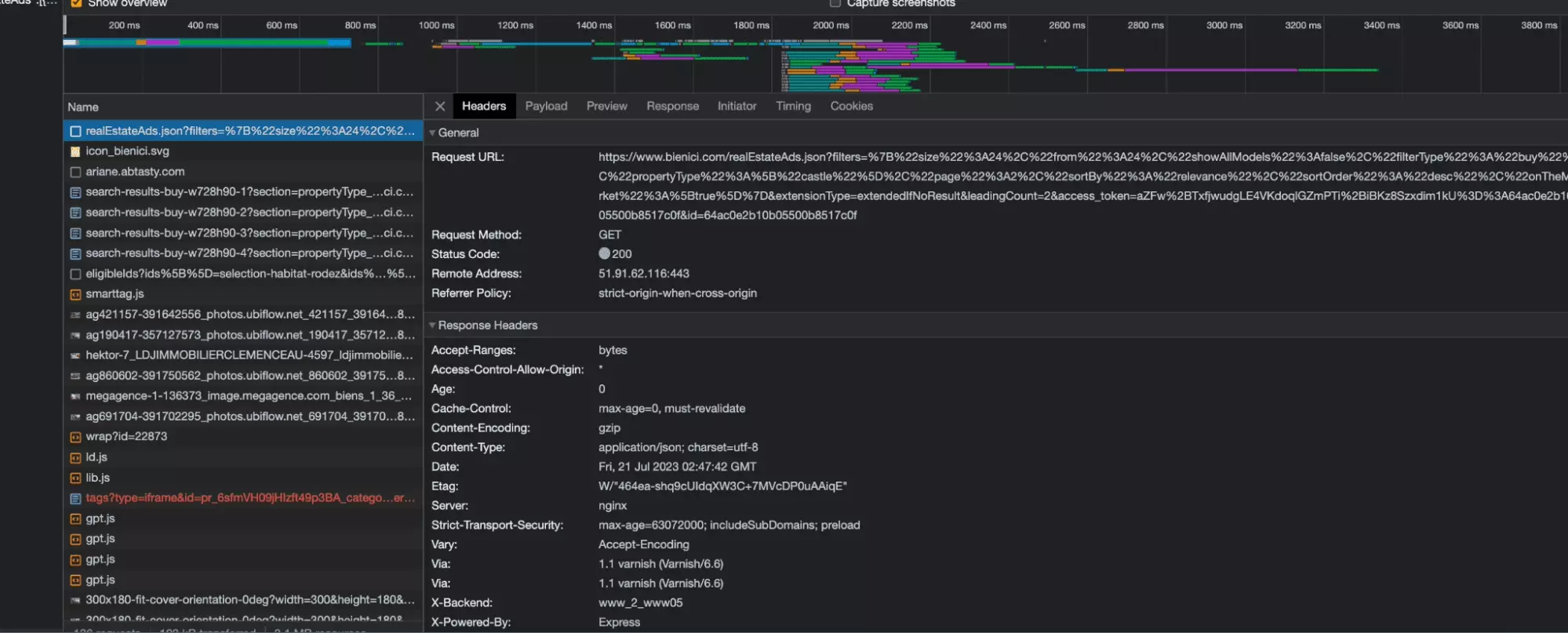
L’URL de la requête se termine par json. Il s’agit d’une requête qui récupère l’intégralité des données des annonces immobilières depuis le serveur au format json, idéal pour la manipulation de données. Les données sont ensuite rendues lisibles par le navigateur.
Et maintenant, comment réaliser cette requête avec un script Python?
Et bien c’est très simple, on va récupérer la valeur de la requête au format cURL, et ensuite la convertir au format Python.
Pour récupérer la requête cURL, on double clique sur notre requête au niveau de l’espace de recherche, puis une fois identifiée la requête dans la fenêtre de droite, on fait: Clique droit > Copy as cURL.
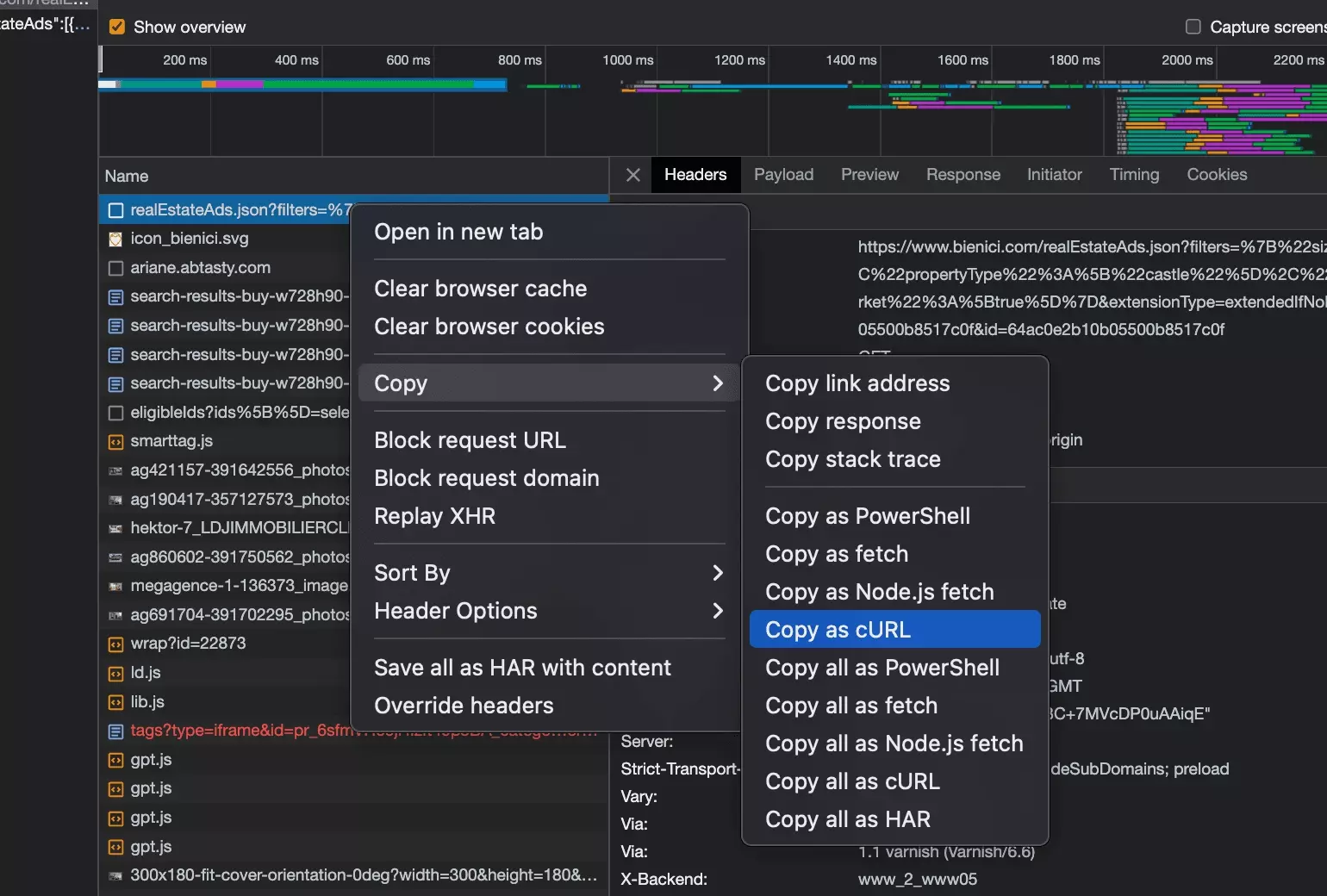
Voilà le cURL tant espéré!
curl 'https://www.bienici.com/realEstateAds.json?filters=%7B%22size%22%3A24%2C%22from%22%3A24%2C%22showAllModels%22%3Afalse%2C%22filterType%22%3A%22buy%22%2C%22propertyType%22%3A%5B%22castle%22%5D%2C%22page%22%3A2%2C%22sortBy%22%3A%22relevance%22%2C%22sortOrder%22%3A%22desc%22%2C%22onTheMarket%22%3A%5Btrue%5D%7D&extensionType=extendedIfNoResult&leadingCount=2&access_token=aZFw%2BTxfjwudgLE4VKdoqlGZmPTi%2BiBKz8Szxdim1kU%3D%3A64ac0e2b10b05500b8517c0f&id=64ac0e2b10b05500b8517c0f' \ -H 'authority: www.bienici.com' \ -H 'accept: */*' \ -H 'accept-language: fr-FR,fr;q=0.9,en-US;q=0.8,en;q=0.7' \ -H 'if-none-match: W/"45db8-4CtwLKdZmC5JcCsBEORTsszX0Ow"' \ -H 'referer: https://www.bienici.com/recherche/achat/france/chateau?page=2' \ -H 'sec-ch-ua: "Not.A/Brand";v="8", "Chromium";v="114", "Google Chrome";v="114"' \ -H 'sec-ch-ua-mobile: ?0' \ -H 'sec-ch-ua-platform: "macOS"' \ -H 'sec-fetch-dest: empty' \ -H 'sec-fetch-mode: cors' \ -H 'sec-fetch-site: same-origin' \ -H 'user-agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36' \ -H 'x-requested-with: XMLHttpRequest' \ --compressedf
Il suffit de:
- coller le curl dans le champ du dessus
- cliquer sur copy to clipboard
Et voilà, on a un code Python propre et directement exploitable.
On va simplement ajouter imprimer à la fin le contenu de la réponse:
import requests headers = { 'authority': 'www.bienici.com', 'accept': '*/*', 'accept-language': 'fr-FR,fr;q=0.9,en-US;q=0.8,en;q=0.7', 'if-none-match': 'W/"45db8-4CtwLKdZmC5JcCsBEORTsszX0Ow"', 'referer': 'https://www.bienici.com/recherche/achat/france/chateau?page=2', 'sec-ch-ua': '"Not.A/Brand";v="8", "Chromium";v="114", "Google Chrome";v="114"', 'sec-ch-ua-mobile': '?0', 'sec-ch-ua-platform': '"macOS"', 'sec-fetch-dest': 'empty', 'sec-fetch-mode': 'cors', 'sec-fetch-site': 'same-origin', 'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36', 'x-requested-with': 'XMLHttpRequest', } params = { 'filters': '{"size":24,"from":24,"showAllModels":false,"filterType":"buy","propertyType":["castle"],"page":2,"sortBy":"relevance","sortOrder":"desc","onTheMarket":[true]}', 'extensionType': 'extendedIfNoResult', 'leadingCount': '2', } response = requests.get('https://www.bienici.com/realEstateAds.json', params=params, headers=headers) print(response.text)f
Et là… bingo!
On obtient de superbes données au format JSON, bien structurées et qu’il va être très simple ensuite de de trier et de sauvegarder dans un fichier .csv réutilisable ensuite à l’envie.
$ python3 bienici-listings-scraper.py { "total":555, "from":24, "perPage":24, "realEstateAds":[ { "blurInfo":{ "type":"disk", "radius":250, "bbox":[ 2.4164820225520023, 42.61975078401878, 2.4225858691623072, 42.62424242004583 ], "position":{ "lat":42.621996602032304, "lon":2.4195339458571548 }, "centroid":{ "lat":42.621996602032304, "lon":2.4195339458571548 } }, "city":"Prades", "postalCode":"66500", "hasGeorisquesMention":false, "id":"hektor-7_LDJIMMOBILIERCLEMENCEAU-4597", "adType":"buy", "propertyType":"castle", "reference":"7_pR-2407", "description":" Château historique avec oeuvres du célèbre peintre Gustave Violet ! …", "title":"PRADES Château historique avec oeuvres du célèbre peintre Gus", "publicationDate":"2023-07-13T11:17:31.483Z", "modificationDate":"2023-07-20T05:03:23.708Z", "newProperty":false, "accountType":"agency", "isBienIciExclusive":false, "price":736000, "surfaceArea":1100, "roomsQuantity":14, "bedroomsQuantity":10, "availableDate":"2023-07-18T00:00:00.000Z", "isExclusiveSaleMandate":true, "photos":[ { "url_photo":"https://ldjimmobilier.staticlbi.com/original/images/biens/7/cbffe2c95a7ce746882e34f2e79e0b33/photo_7c3767e9ff4ebcd684b0778af4ec7548.jpg", "photo":"hektor-7_LDJIMMOBILIERCLEMENCEAU-4597_ldjimmobilier.staticlbi.com_original_images_biens_7_cbffe2c95a7ce746882e34f2e79e0b33_photo_7c3767e9ff4ebcd684b0778af4ec7548.jpg", "url":"https://file.bienici.com/photo/hektor-7_LDJIMMOBILIERCLEMENCEAU-4597_ldjimmobilier.staticlbi.com_original_images_biens_7_cbffe2c95a7ce746882e34f2e79e0b33_photo_7c3767e9ff4ebcd684b0778af4ec7548.jpg" } ... ] }f
Ça y est c’est terminé?
Il faut garder en tête que notre objectif est de récupérer les annonces depuis n’importe quel URL de recherche Bien’Ici. Les châteaux c’est bien, mais notre scraper doit aussi pouvoir récupérer les annonces de villa dans les Cévennes, ou d’immeubles neufs à Dijon.
Or, si on compare l’URL initiale qui a servi de point de départ à notre recherche, et la requête réalisée entre le serveur et le navigateur, quelque chose ne colle pas:
- dans l’URL, on retrouve le mot clé chateau
- dans les paramètres de la requête, on a le mot clé en anglais castle
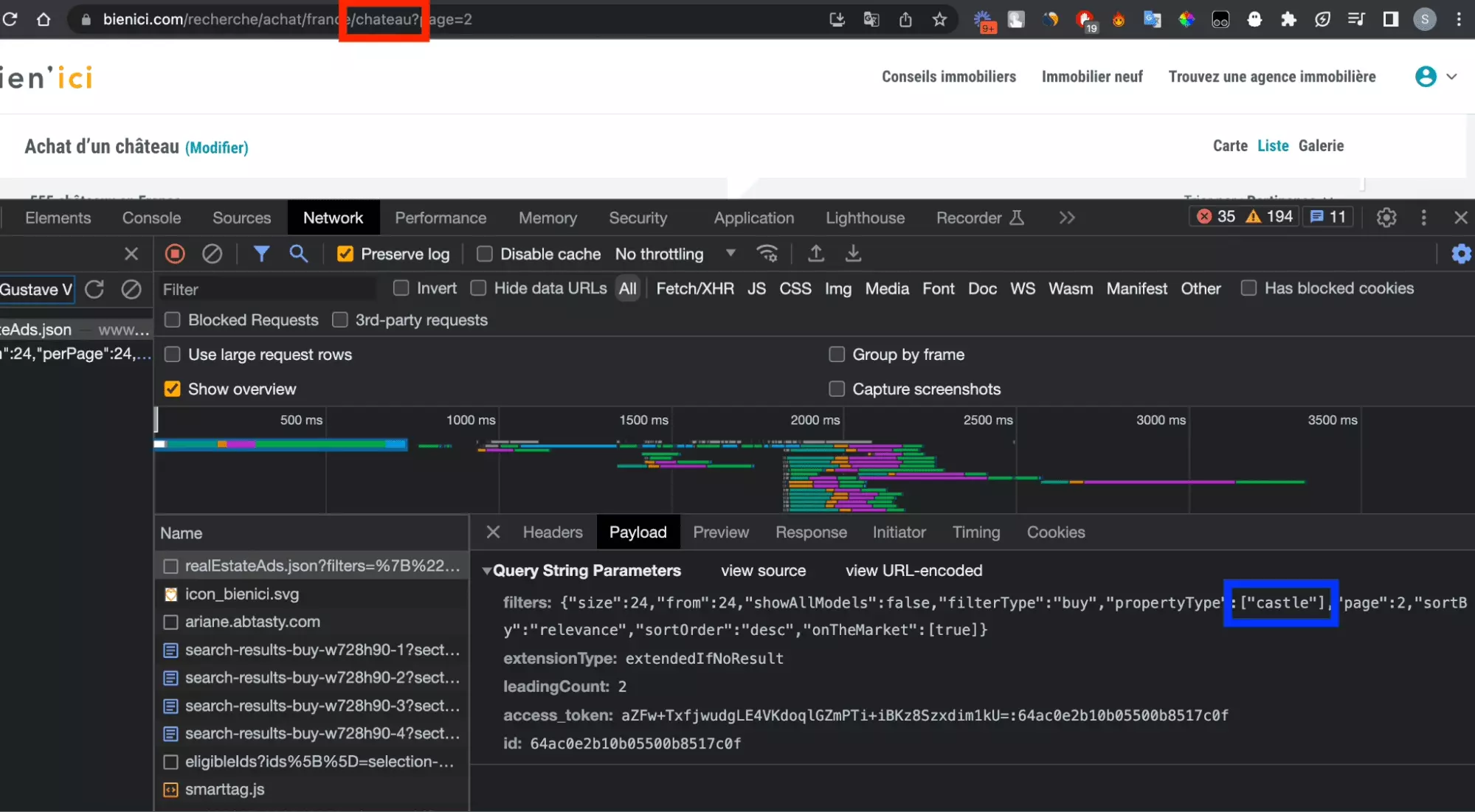
Et si l’on répète l’expérience avec d’autres URLs de recherche, le constat se répète: appartement devient flat, acheter devient buy etc.
Autrement dit, il semble que l’URL subisse une transformation avant que la requête soit effectuée:
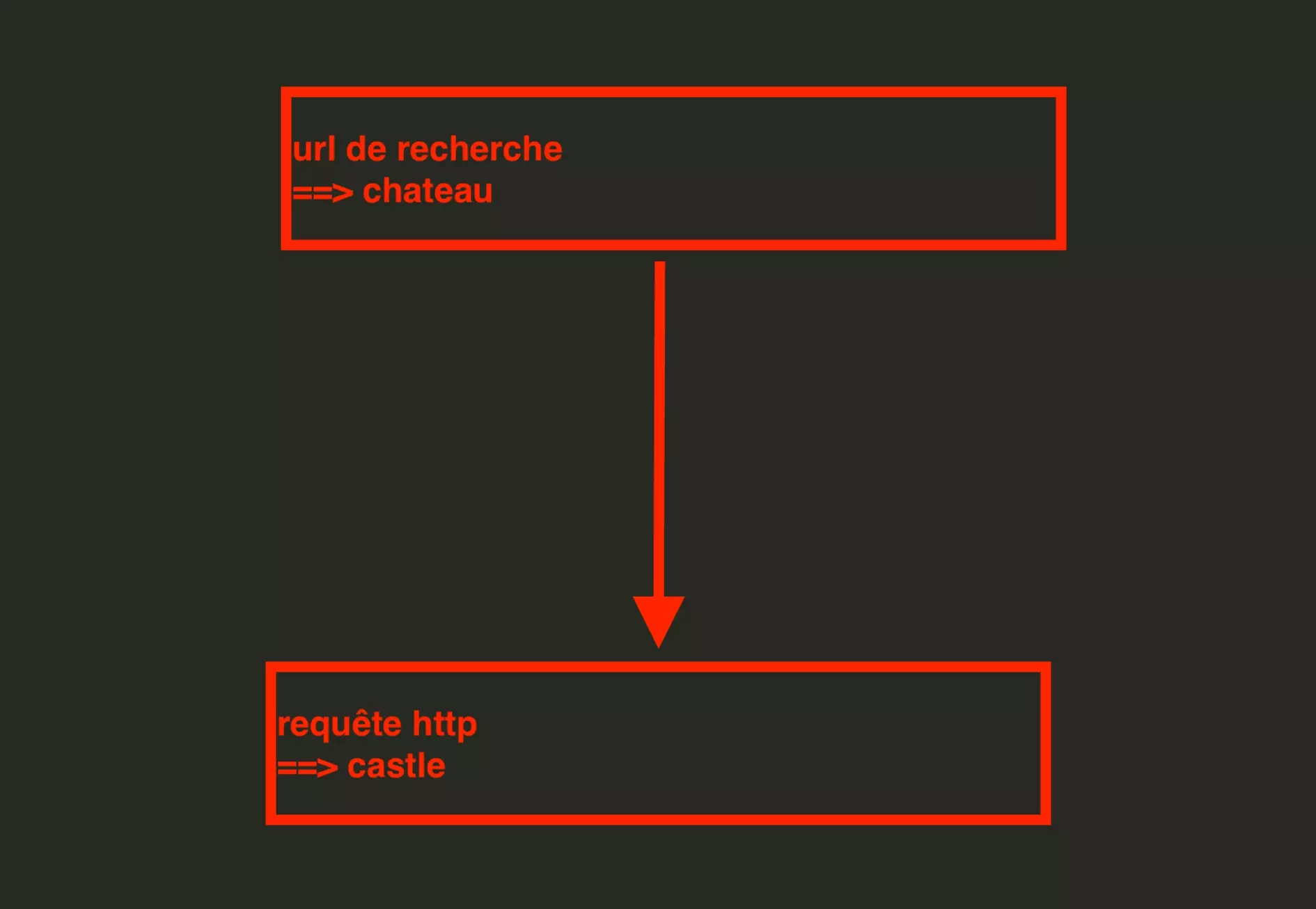
Dans la partie suivante, on va donc chercher à comprendre comment le passage de l’URL à la requête est effectué.
D’expérience, les transformations dynamiques, réalisées sans que de trace ne soit laissée au niveau de la partie Network, sont le fait de scripts Javascript, téléchargés et exécutés par le navigateur.
Et on va développer une fonction en Python qui va nous permettre de passer d’une URL à une requête d’API.
2. Conversion de l’URL en requête API
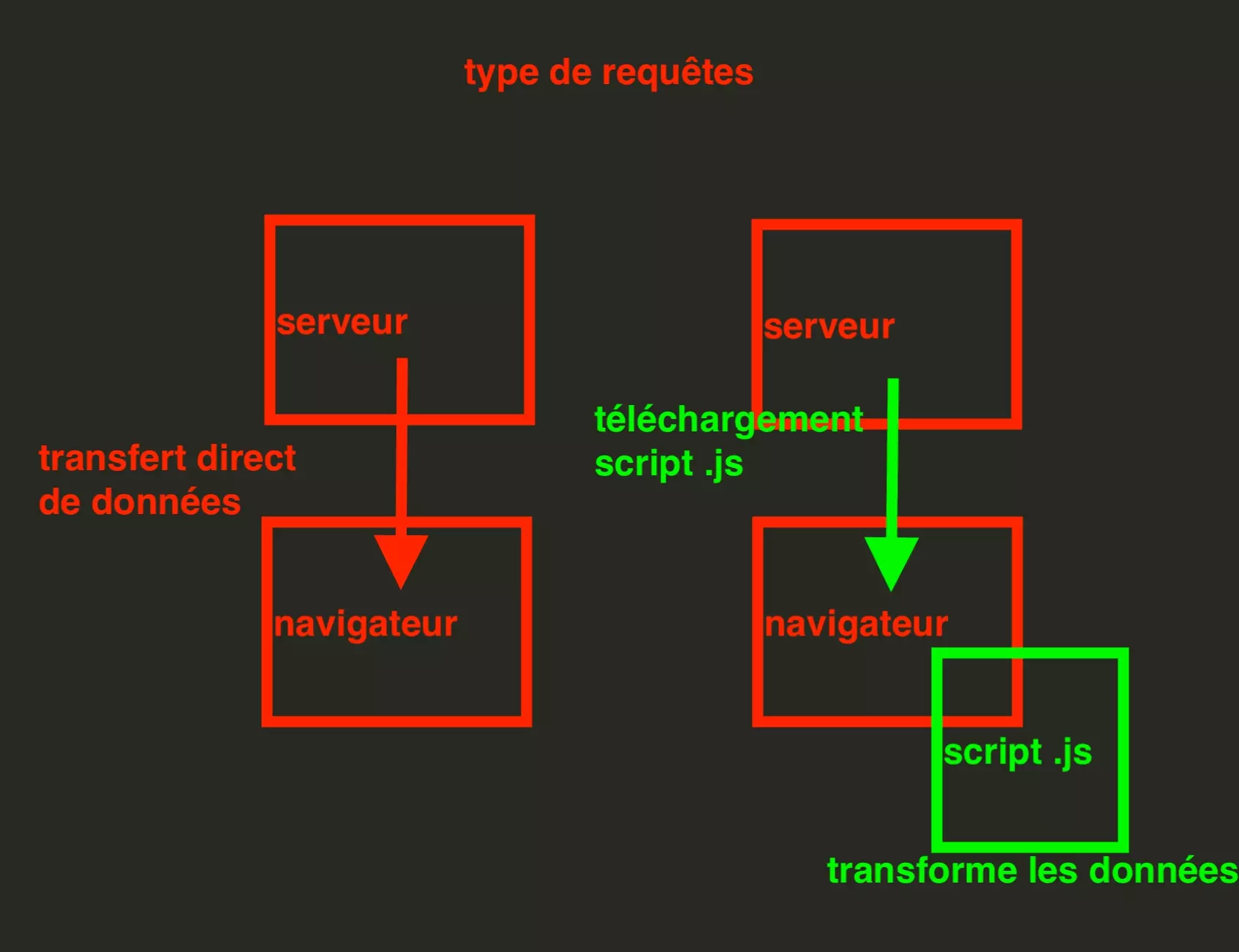
Comme précisé plus haut, lors d’un échange entre un navigateur et un serveur, deux types d’actions coexistent:
requête serveur: le navigateur fait une requête vers le serveur, et le serveur renvoie des données — ces requêtes apparaissent dans l’onglet Network
transformation javascript: le navigateur télécharge un script javascript .js depuis le serveur, et l’exécute ensuite à sa guise pour effectuer des transformations en toute autonomie, et en toute discrétion, sans laisser de trace au niveau de la partie Network
a. PropertyTypes
On va donc taper le mot clé ‘castle’ en utilisant l’outil de recherche de l’onglet Network, et on va avoir à partir de là 2 possibilités: soit le navigateur effectue une requête vers le serveur pour transformer l’URL en paramètres de requête d’API, soit un script javascript est téléchargé par le navigateur, et il va falloir ensuite qu’on le décode.
On tape donc le mot ‘castle’ dans l’onglet Network comme évoqué. On retrouve des requêtes publicitaires, un fichier de traduction et… au milieu de tout ça… la gemme.
Un fichier javascript, immense, qui fait le lien entre chateau, le mot clé en français de notre URL, et castle le paramètre de requête de notre API.
💎
Le bien nommé s’appelle: commonModern.js.
C’est peu commun, mais c’est moderne.
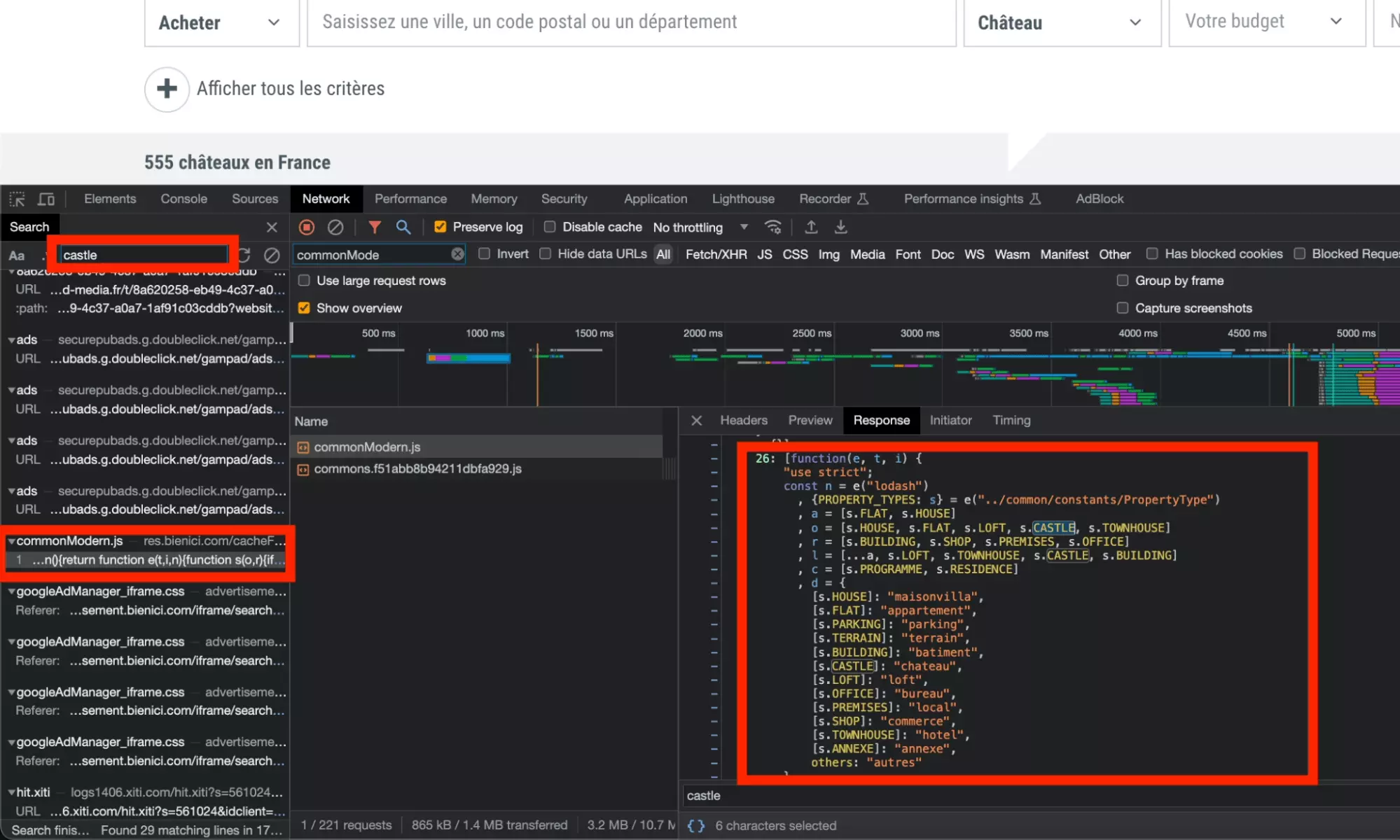
En dehors du castle, on retrouve l’ensemble des types de propriété, et le fichier javascript semble bien faire le lien entre le type de propriété présent dans une URL, et le paramètre de requête:
maisonvilla > house
chateau > castle
parking > parking (bon)
bureau > office
...
Le site fonctionne donc comme suit:
- une requête est effectuée entre le navigateur et le serveur
- le fichier commonModern.js est téléchargé
- lorsqu’une URL est soumise, le fichier .js est exécuté et permet le passage de l’un à l’autre \
Notre objectif va donc être maintenant de convertir ce fichier Javascript en fichier Python, afin de pouvoir nous aussi, à l’envie, convertir un URL de recherche Bien’Ici en paramètres de requête d’API.
On va donc commencer par télécharger ce gros fichier js dans sa totalité, pour en observer la structure.
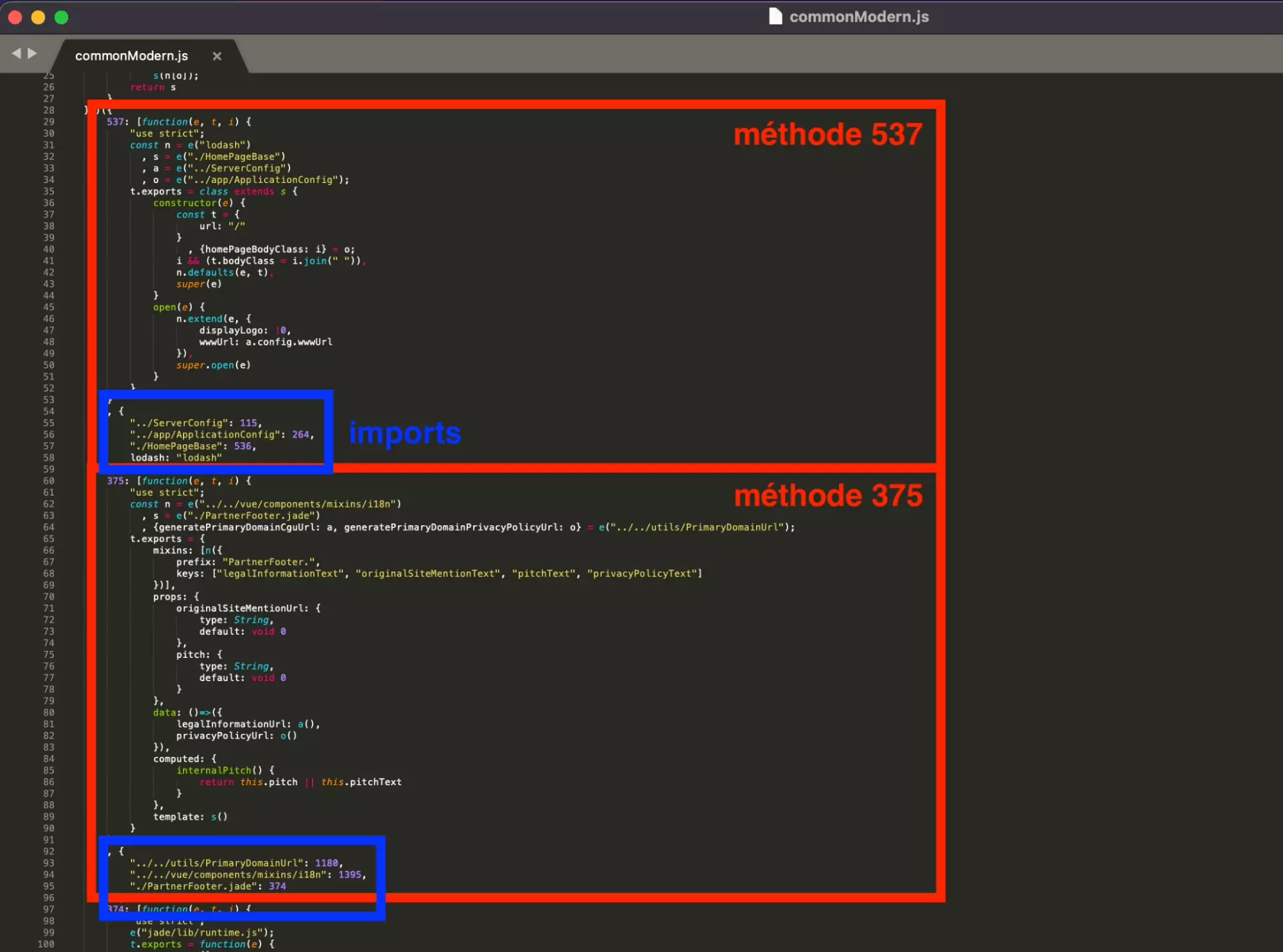
Et il semble que le fichier soit structuré comme décrit ci-après:
- plusieurs méthodes — chacune porte un numéro
- les méthodes s’appellent les une entre les autres
Et comme on le voit visuellement ci-dessous, avec la méthode 537 et la méthode 375:
La première méthode qui nous intéresse, celle identifiée plus haut, est la méthode 26: PropertyTypes. On y retrouve toutes les correspondances entre mot clé d’URL et paramètre d’API, en ce qui concerne les types de propriété.
Mais aussi des mots clés intéressants, comme DBTOFRENCH_SLUG, ce qui suggère qu’on a bien affaire à la méthode responsable du passage de l’un à l’autre.
26: [function(e, t, i) { "use strict"; const n = e("lodash") , {PROPERTY_TYPES: s} = e("../common/constants/PropertyType") , a = [s.FLAT, s.HOUSE] , o = [s.HOUSE, s.FLAT, s.LOFT, s.CASTLE, s.TOWNHOUSE] , r = [s.BUILDING, s.SHOP, s.PREMISES, s.OFFICE] , l = [...a, s.LOFT, s.TOWNHOUSE, s.CASTLE, s.BUILDING] , c = [s.PROGRAMME, s.RESIDENCE] , d = { [s.HOUSE]: "maisonvilla", [s.FLAT]: "appartement", [s.PARKING]: "parking", [s.TERRAIN]: "terrain", [s.BUILDING]: "batiment", [s.CASTLE]: "chateau", [s.LOFT]: "loft", [s.OFFICE]: "bureau", [s.PREMISES]: "local", [s.SHOP]: "commerce", [s.TOWNHOUSE]: "hotel", [s.ANNEXE]: "annexe", others: "autres" } , u = n.extend({ parkingbox: s.PARKING, maison: s.HOUSE }, n.invert(d)) , h = n.union(l, c, r, [s.PARKING, s.TERRAIN]) , p = { business: r, programmeAndResidence: c, housingSingle: l, housing: n.union(l, c), withEnergyDiagnostic: n.union(l, r), singleBuilt: n.union(l, r, [s.PARKING]), single: n.union(l, [s.TERRAIN, s.PARKING], r), housingAndBusiness: n.union(l, c, r), all: h, FLAT_AND_HOUSE: a, FOR_USER_SEARCH: n.without(h, s.ANNEXE) } , m = n.difference(h, [s.SHOP, s.OFFICE, s.PREMISES]); n.each(p, e=>{ e.push("unknown") } ), t.exports = n.extend({ canSimulateCreditForPropertyType: function(e) { return n.includes(m, e) }, DB_TO_FRENCH_SLUG: d, FRENCH_SLUG_TO_DB: u, DEFAULT_USER_SEARCH: o }, p) } , { "../common/constants/PropertyType": 44, lodash: "lodash" }]f
Et voilà le résultat en Python:
import copy def can_simulate_credit_for_property_type(property_type): return property_type in m PROPERTY_TYPES = { "FLAT": "flat", "HOUSE": "house", "PARKING": "parking", "TERRAIN": "terrain", "BUILDING": "building", "CASTLE": "castle", "LOFT": "loft", "OFFICE": "office", "PREMISES": "premises", "SHOP": "shop", "TOWNHOUSE": "townhouse", "ANNEXE": "annexe", "others": "others" } a = [PROPERTY_TYPES["FLAT"], PROPERTY_TYPES["HOUSE"]] o = [PROPERTY_TYPES["HOUSE"], PROPERTY_TYPES["FLAT"], PROPERTY_TYPES["LOFT"], PROPERTY_TYPES["CASTLE"], PROPERTY_TYPES["TOWNHOUSE"]] r = [PROPERTY_TYPES["BUILDING"], PROPERTY_TYPES["SHOP"], PROPERTY_TYPES["PREMISES"], PROPERTY_TYPES["OFFICE"]] l = a + [PROPERTY_TYPES["LOFT"], PROPERTY_TYPES["TOWNHOUSE"], PROPERTY_TYPES["CASTLE"], PROPERTY_TYPES["BUILDING"]] c = [PROPERTY_TYPES["PROGRAMME"], PROPERTY_TYPES["RESIDENCE"]] d = { PROPERTY_TYPES["HOUSE"]: "maisonvilla", PROPERTY_TYPES["FLAT"]: "appartement", PROPERTY_TYPES["PARKING"]: "parking", PROPERTY_TYPES["TERRAIN"]: "terrain", PROPERTY_TYPES["BUILDING"]: "batiment", PROPERTY_TYPES["CASTLE"]: "chateau", PROPERTY_TYPES["LOFT"]: "loft", PROPERTY_TYPES["OFFICE"]: "bureau", PROPERTY_TYPES["PREMISES"]: "local", PROPERTY_TYPES["SHOP"]: "commerce", PROPERTY_TYPES["TOWNHOUSE"]: "hotel", PROPERTY_TYPES["ANNEXE"]: "annexe", "others": "autres" } u = copy.deepcopy({ "parkingbox": PROPERTY_TYPES["PARKING"], "maison": PROPERTY_TYPES["HOUSE"] }) u.update({v: k for k, v in d.items()}) h = l + c + r + [PROPERTY_TYPES["PARKING"], PROPERTY_TYPES["TERRAIN"]] p = { "business": r, "programmeAndResidence": c, "housingSingle": l, "housing": l + c, "withEnergyDiagnostic": l + r, "singleBuilt": l + r + [PROPERTY_TYPES["PARKING"]], "single": l + [PROPERTY_TYPES["TERRAIN"], PROPERTY_TYPES["PARKING"]] + r, "housingAndBusiness": l + c + r, "all": h, "FLAT_AND_HOUSE": a, "FOR_USER_SEARCH": [item for item in h if item != PROPERTY_TYPES["ANNEXE"]] } m = [item for item in h if item not in [PROPERTY_TYPES["SHOP"], PROPERTY_TYPES["OFFICE"], PROPERTY_TYPES["PREMISES"]]] def export_functions(): return { "canSimulateCreditForPropertyType": can_simulate_credit_for_property_type, "DB_TO_FRENCH_SLUG": d, "FRENCH_SLUG_TO_DB": u, "DEFAULT_USER_SEARCH": o, **p } exported_functions = export_functions()f
C’est excessivement complexe, mais l’essentiel est là. On va pouvoir créer une méthode simple en Python:
# Import necessary modules from the standard library from urllib.parse import urlparse, parse_qs # Mapping of French slugs to corresponding property types in the database FRENCH_SLUG_TO_DB = { "parkingbox": "parking", "maison": "house", "maisonvilla": "house", "appartement": "flat", "parking": "parking", "terrain": "terrain", "batiment": "building", "chateau": "castle", "loft": "loft", "bureau": "office", "local": "premises", "commerce": "shop", "hotel": "townhouse", "annexe": "annexe", "autres": "others" } # Default property types if no specific type is provided in the URL DEFAULT_PROPERTY_TYPES = ["house", "flat", "loft", "castle", "townhouse"] # Function to convert a URL to API parameters def convert_url_to_api_parameters(url): # Initialize the parameters dictionary PARAMS = {"filters": {}} # Extract the "filters" dictionary from PARAMS for convenience FILTERS = PARAMS["filters"] # Set some default filter values FILTERS["size"] = 24 # The number of results to return FILTERS["from"] = None # The starting index of the results (unused in this code) FILTERS["page"] = None # The page number of the results (unused in this code) FILTERS["onTheMarket"] = [True] # A filter for properties that are on the market # Parse the URL to extract query parameters and path parsed_url = urlparse(url) query_params = parse_qs(parsed_url.query) path = parsed_url.path # Initialize a list to store property types extracted from the URL _property_types_values = [] # Loop through the FRENCH_SLUG_TO_DB mapping and check if the slug exists in the URL's path for k, v in FRENCH_SLUG_TO_DB.items(): if k in path: # If the slug is found, add its corresponding value (property type) to the list _property_types_values.append(v) # If no property types were extracted from the URL, use the default property types _property_types_values = _property_types_values if _property_types_values else DEFAULT_PROPERTY_TYPES # Set the propertyType filter in the parameters to the extracted or default values FILTERS["propertyType"] = _property_types_values # Print the final filter parameters (you might want to use them for an API call) print(FILTERS) # Entry point of the script, only executed if this script is run directly, not imported as a module if __name__ == '__main__': # Call the function with a sample URL for testing convert_url_to_api_parameters('https://www.bienici.com/recherche/achat/france/chateau')f
Et en sortie:
$ python3 bienici-listings-scraper.py {'size': 24, 'from': None, 'page': None, 'onTheMarket': [True], 'propertyType': ['castle']}f
On retrouve bien notre château d’outre-manche. Magnifique!
Mais une recherche Bien’Ici, ça n’est pas toujours qu’un type de propriété.
C’est aussi souvent pleins d’autres paramètres: prix mini, prix maxi, surface, nombre de chambres, possède une piscine etc.
Et pour l’instant impossible de convertir ces paramètres additionnels, pourtant présents dans l’URL, en paramètre de requête d’API.
C’est ce qu’on va voir dans la prochaine partie.
b. Paramètres additionnels
Parce qu’on a des goûts de luxe, et pourquoi pas?, on va cette fois un petit peu modifier notre URL de recherche, et prendre l’URL présente juste en dessous:
C’est à dire qu’on veut récupérer les châteaux en France sur Bien’Ici, mais on veut désormais récupérer tous les éléments suivant:
- chateau ✅
- achat
- france
- 10+ pièces
- 1000+ m2
- 1 cheminée — pour passer l’hiver au chaud
Si on a bien l’attribut type de propriété dans notre requête vers le serveur, justement résolu à la partie précédente, il nous manque maintenant l’ensemble des paramètres additionnels: achat, 10+ pièces, 1000+ m2, cheminée.
Comme vous l’aurez peut-être remarqué, il manque aussi la localisation, mais on va prendre cette partie en charge dans la partie suivante. Qui va piano va sano.
En répétant la stratégie d’identification de requête comme réalisé dans la première partie de ce tutoriel, voilà les paramètre envoyés au serveur:
{"size":24,"from":0,"showAllModels":false,"filterType":"buy","propertyType":["castle"],"minRooms":10,"minArea":1000,"minBedrooms":1,"hasFirePlace":true,"page":1,"sortBy":"relevance","sortOrder":"desc","onTheMarket":[true],"mapMode":"enabled"}f
On va les correspondances suivantes:
achat > buy
10+ pièces > minRooms 10
1000+ m2 > minArea 1000
Cheminée > hasFirePlace true
En d’autres termes, comme pour le type de propriété, les paramètres présents dans l’URL sont transformés en paramètres et envoyés vers le serveur.
On va donc chercher, comme pour la partie précédente, la partie du script javascript qui réalise le passage de l’un à l’autre.
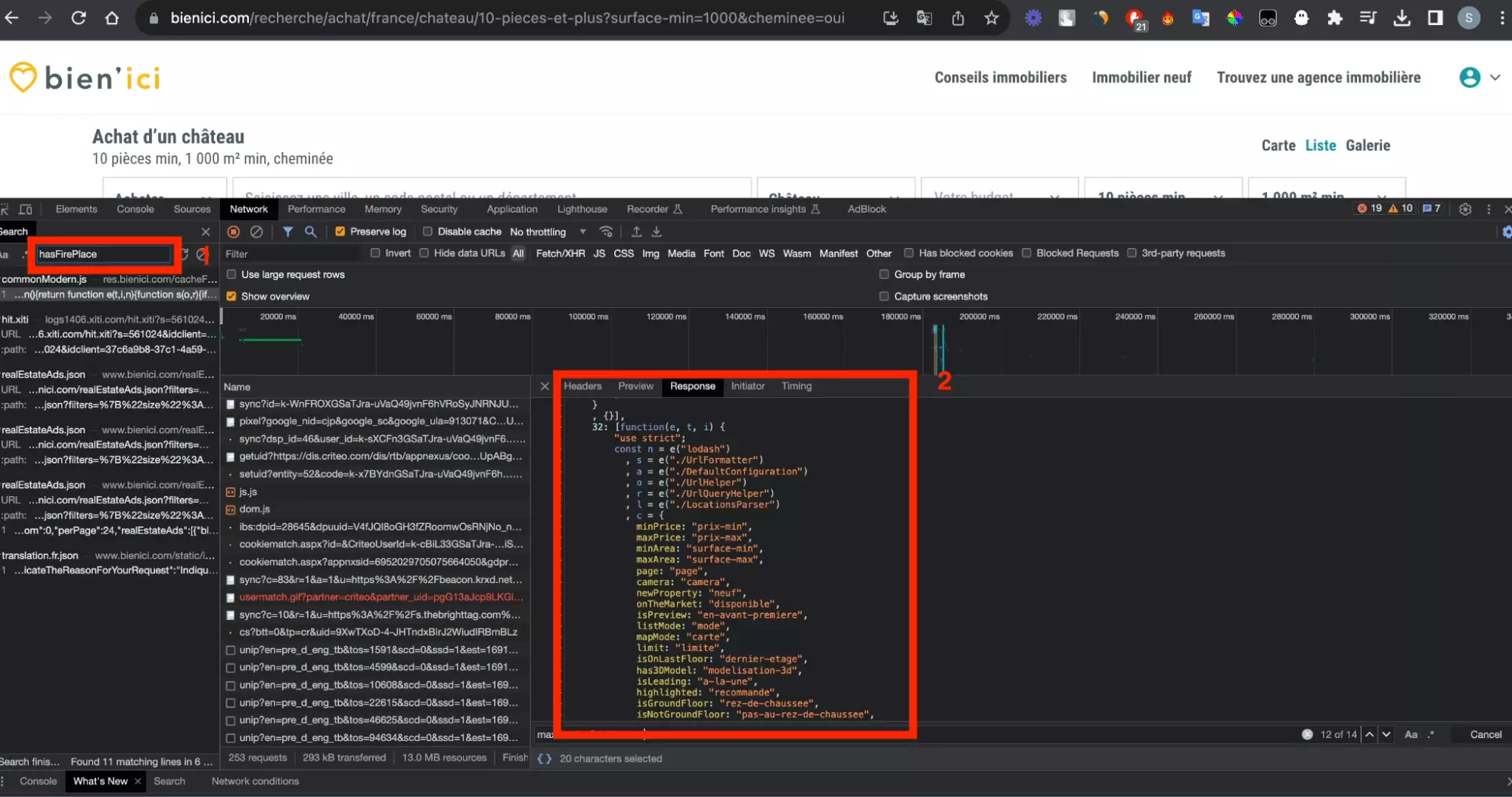
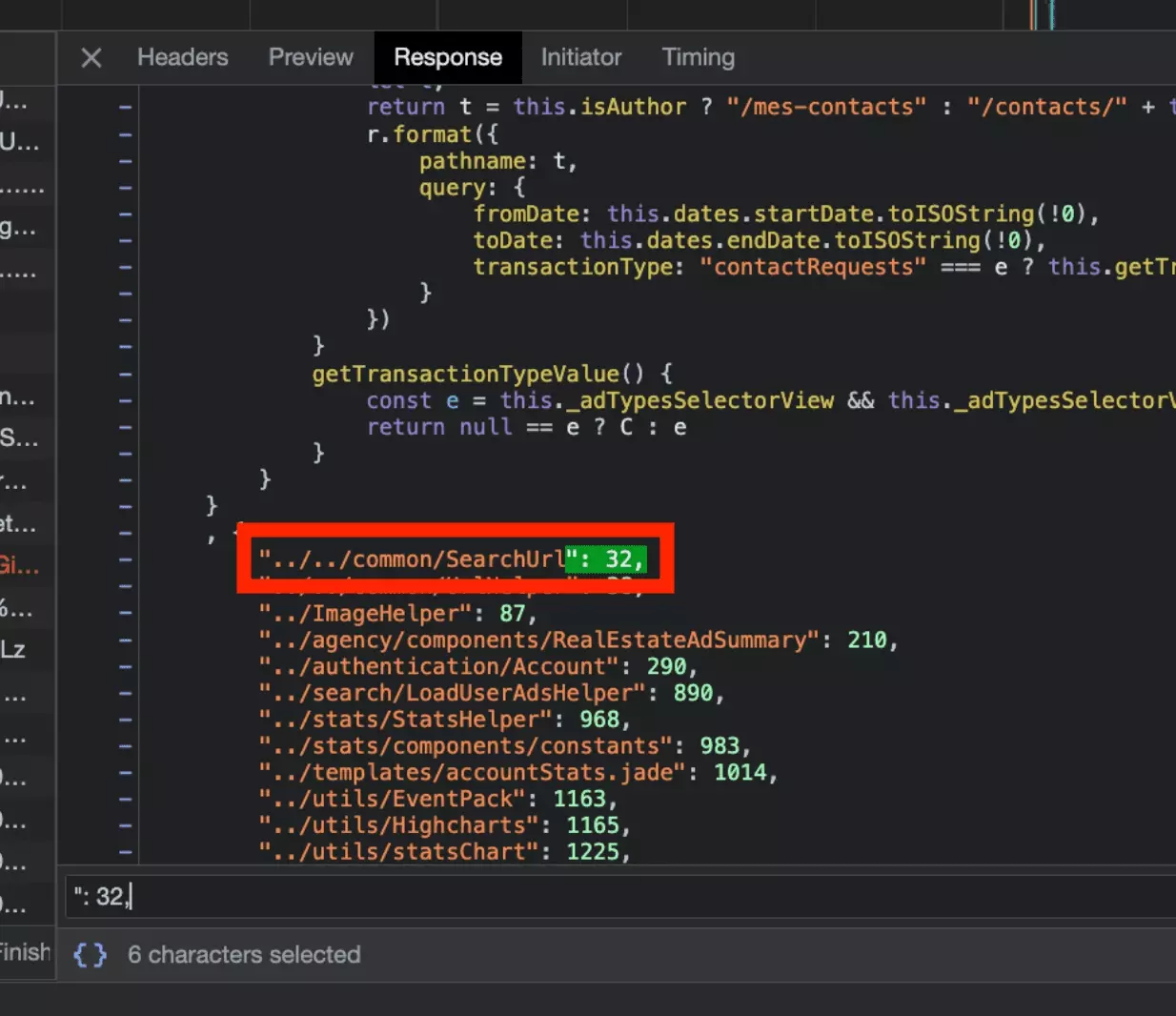
On touche au but!
Voilà un snapshot du code proposé par ChatGPT:
# Define other placeholders and default configuration c = { "minPrice": "prix-min", # ... truncated for brevity } h = { "price": "prix", # ... truncated for brevity } # Define swapKeysValues function based on given JavaScript code def swap_keys_values(dic): return {v: k for k, v in dic.items()} d = swap_keys_values(c) p = swap_keys_values(h) u = "tri" # ... truncated for brevity def make_search_url(e, t, i): r = "enabled" if e.get("fullList"): r = "disabled" t = t if t else default_configuration.search t["mapMode"] = "enabled" if t.get("fullList"): t["mapMode"] = "disabled" i = i if i else "recherche" l = "/" + i + "/" # ... truncated for brevity return l # ... truncated for brevityf
On va donc faire le contraire de ce que produit cette méthode, c'est-à-dire la réécrire en prenant en entrée les paramètres d’API, pour les convertir ensuite en paramètres d’API.
Ce qui nous donne après réécriture la méthode suivante:
from urllib.parse import urlparse, parse_qs # Define lists and dictionaries for various values # Mapping of boolean values to their corresponding keys BOOLEAN_VALUES = {"hasFirePlace": True, ...} # List of energy classification values ENERGY_CLASSIFICATION_VALUES = ["energyClassification"] # List of number values used in URL parameters NUMBER_VALUES = ["minPrice", "maxPrice", ...] # Mapping of URL parameter keys to their corresponding values URL_PARAMETERS = {"hasFirePlace": "cheminee", ...} # Reverse mapping of URL parameter values to their keys REVERSED_URL_PARAMETERS = {'cheminee': 'hasFirePlace', ...} # Mapping of sort options used in API parameters SORT_OPTIONS = {"price": "prix", ...} # Reverse mapping of sort option values to their keys REVERSED_SORT_OPTIONS = {'prix': 'price', ...} # Mapping of filter type options used in API parameters FILTER_TYPE_OPTIONS = {"achat": "buy", "location": "rent"} # Mapping of French slugs to property types in the database FRENCH_SLUG_TO_DB = { "parkingbox": "parking", ... } # Default property types DEFAULT_PROPERTY_TYPES = ["house", "flat", ...] # Default sort option DEFAULT_SORT_BY = ("relevance", "desc") # Regular expression to match a pattern for room count, like "10-pièces-et-plus" ROOMS_PATTERN_PLUS = re.compile(r"(\d+)-pi[èe]ces?-et-plus") # Regular expression to match a pattern for room count, like "5-pièces-et-moins" ROOMS_PATTERN_MINUS = re.compile(r"(\d+)-pi[èe]ces?-et-moins") # Regular expression to match a range pattern for room count, like "de-3-a-6-pièces" ROOMS_PATTERN_RANGE = re.compile(r"de-(\d+)-a-(\d+)-?pi[èe]ces?") # Regular expression to match a pattern for a single room count, like "3-pièces" ROOMS_PATTERN_SINGLE = re.compile(r"(\d+)-pi[èe]ces?") # Import necessary libraries and functions if required (not shown in the provided code) def convert_url_to_api_parameters(url): """ Convert a URL to API parameters for the Bienici API. Args: url (str): The URL to convert. Returns: dict: The API parameters. Raises: AssertionError: If the input URL is not provided or if any expected assertions fail during the conversion process. """ # Initialize the main parameters dictionary PARAMS = {"filters":{}} # Create a reference to the nested "filters" dictionary for brevity FILTERS = PARAMS["filters"] # Set default values for some parameters FILTERS["size"] = 24 FILTERS["from"] = None FILTERS["page"] = None FILTERS["onTheMarket"] = [True] # Parse the URL parsed_url = urlparse(url) query_params = parse_qs(parsed_url.query) path = parsed_url.path # Extract filter type from URL path for k, v in FILTER_TYPE_OPTIONS.items(): if k in path: FILTERS["filterType"] = FILTER_TYPE_OPTIONS[k] # Extract property types from URL path _property_types_values = [] for k, v in FRENCH_SLUG_TO_DB.items(): if k in path: _property_types_values.append(v) # Set property types or use default if not found _property_types_values = _property_types_values if _property_types_values else DEFAULT_PROPERTY_TYPES FILTERS["propertyType"] = _property_types_values # Extract minimum and maximum rooms from URL path min_rooms = None max_rooms = None if ROOMS_PATTERN_PLUS.findall(path): min_rooms = int(ROOMS_PATTERN_PLUS.findall(path)[0]) elif ROOMS_PATTERN_MINUS.findall(path): min_rooms = int(ROOMS_PATTERN_MINUS.findall(path)[0]) elif ROOMS_PATTERN_RANGE.findall(path): min_rooms = int(ROOMS_PATTERN_RANGE.findall(path)[0]) max_rooms = int(ROOMS_PATTERN_RANGE.findall(path)[1]) elif ROOMS_PATTERN_SINGLE.findall(path): min_rooms = int(ROOMS_PATTERN_SINGLE.findall(path)[0]) if min_rooms: FILTERS["minRooms"] = min_rooms if max_rooms: FILTERS["maxRooms"] = max_rooms # Extract additional parameters from query string if query_params: for k, v in query_params.items(): # Handle numeric values if k in REVERSED_URL_PARAMETERS.keys(): if REVERSED_URL_PARAMETERS[k] in NUMBER_VALUES: FILTERS[REVERSED_URL_PARAMETERS[k]] = int(v[0]) # Handle boolean values if k in REVERSED_URL_PARAMETERS.keys() and REVERSED_URL_PARAMETERS[k] in BOOLEAN_VALUES.keys(): FILTERS[REVERSED_URL_PARAMETERS[k]] = BOOLEAN_VALUES[REVERSED_URL_PARAMETERS[k]] # Handle energy classification parameter if k == 'classification-energetique': FILTERS["energyClassification"] = v[0].split(',') # Handle sorting parameter if k == 'tri': for s in v: t, w = s.split('-') assert all([t,w]) FILTERS["sortBy"] = t FILTERS["sortOrder"] = w # Set default sorting values if not provided if not "sortBy" in FILTERS.keys(): t,w = DEFAULT_SORT_BY FILTERS["sortBy"] = t FILTERS["sortOrder"] = w # Ensure that PARAMS dictionary is not empty assert PARAMS # Return the final API parameters return PARAMS if __name__ == '__main__': # Call the function with a sample URL for testing PARAMS = convert_url_to_api_parameters('https://www.bienici.com/recherche/achat/france/chateau/10-pieces-et-plus?surface-min=1000&cheminee=oui') print(PARAMS)f
$ python3 bienici-listings-scraper.py {'filters': {'size': 24, 'from': None, 'page': None, 'onTheMarket': [True], 'filterType': 'buy', 'propertyType': ['castle'], 'minRooms': 10, 'minArea': 1000, 'hasFirePlace': True, 'sortBy': 'relevance', 'sortOrder': 'desc'}}f
On retrouve bien nos paramètres d’URL, proprement transformés en paramètres d’API:
- buy
- minArea
- hasFirePlace
- minRooms
On y est!
C’est ce qu’on va voir dans la partie suivante.
3. Récupération des localisations géographiques
Dans la dernière partie de la conversion de l’URL en paramètres d’API, on va voir comment prendre en charge les paramètres de localisation géographiques.
Voilà notre URL de recherche, focalisée sur la région de Narbonne, qui a pour code postal 11000:
Et le payload de la requête d’API:
{"size":24,"from":0,"showAllModels":false,"filterType":"buy","propertyType":["castle"],"minRooms":10,"minArea":1000,"hasFirePlace":true,"page":1,"sortBy":"relevance","sortOrder":"desc","onTheMarket":[true],"zoneIdsByTypes":{"zoneIds":["-37774","-1085702"]}}f
On voit que la modification a lieu comme suit:
11000 dans l’URL > -37774, -1085702 dans la requête d’API
On va utiliser à nouveau l’outil de recherche parmi les requêtes, avec la valeur -37774 atypique.
Ici, on voit qu’il ne s’agit plus d’une transformation effectuée par un script, mais qu’il s’agit d’une nouvelle requête faite vers le site en amont, qui utilise en entrée l’élément présent dans l’URL, ici 11000:
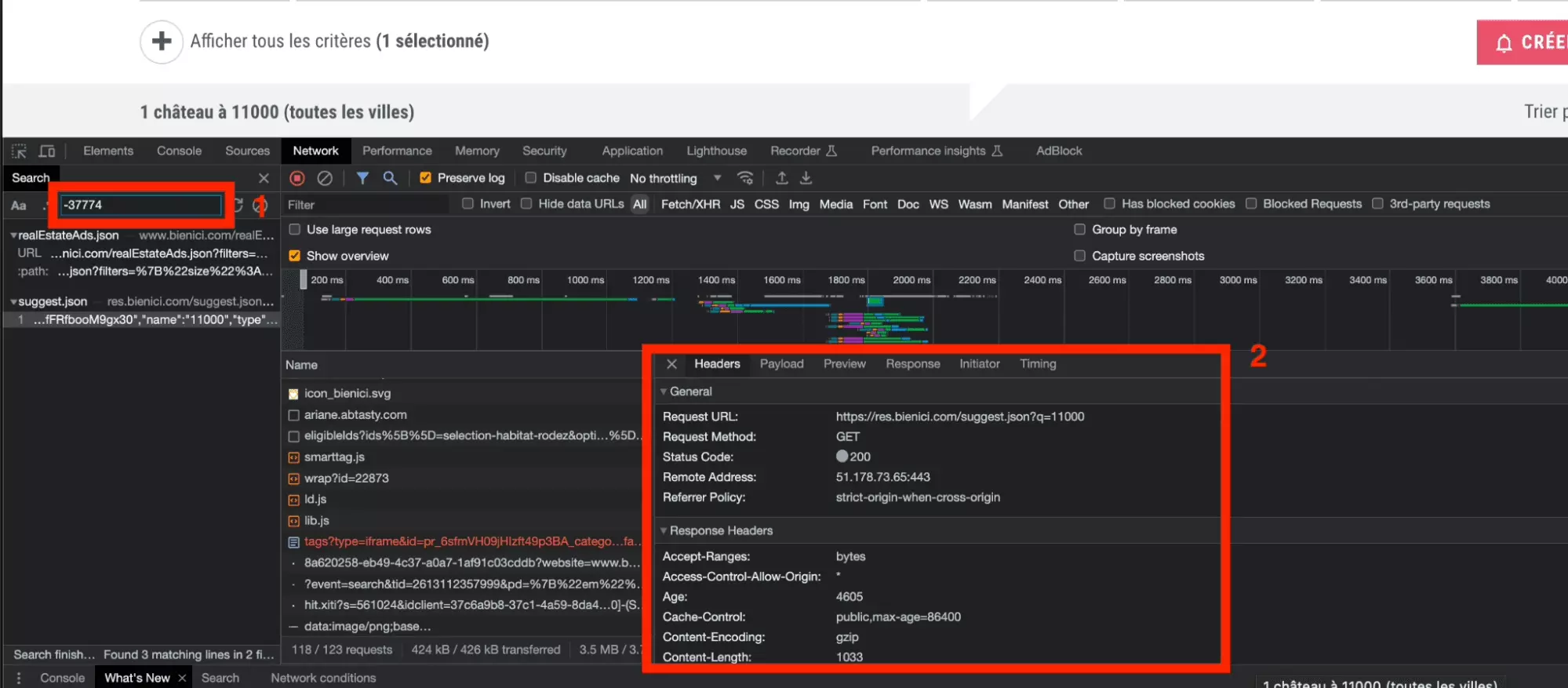
Et dans la réponse de cette requête, on retrouve bien nos deux valeurs:
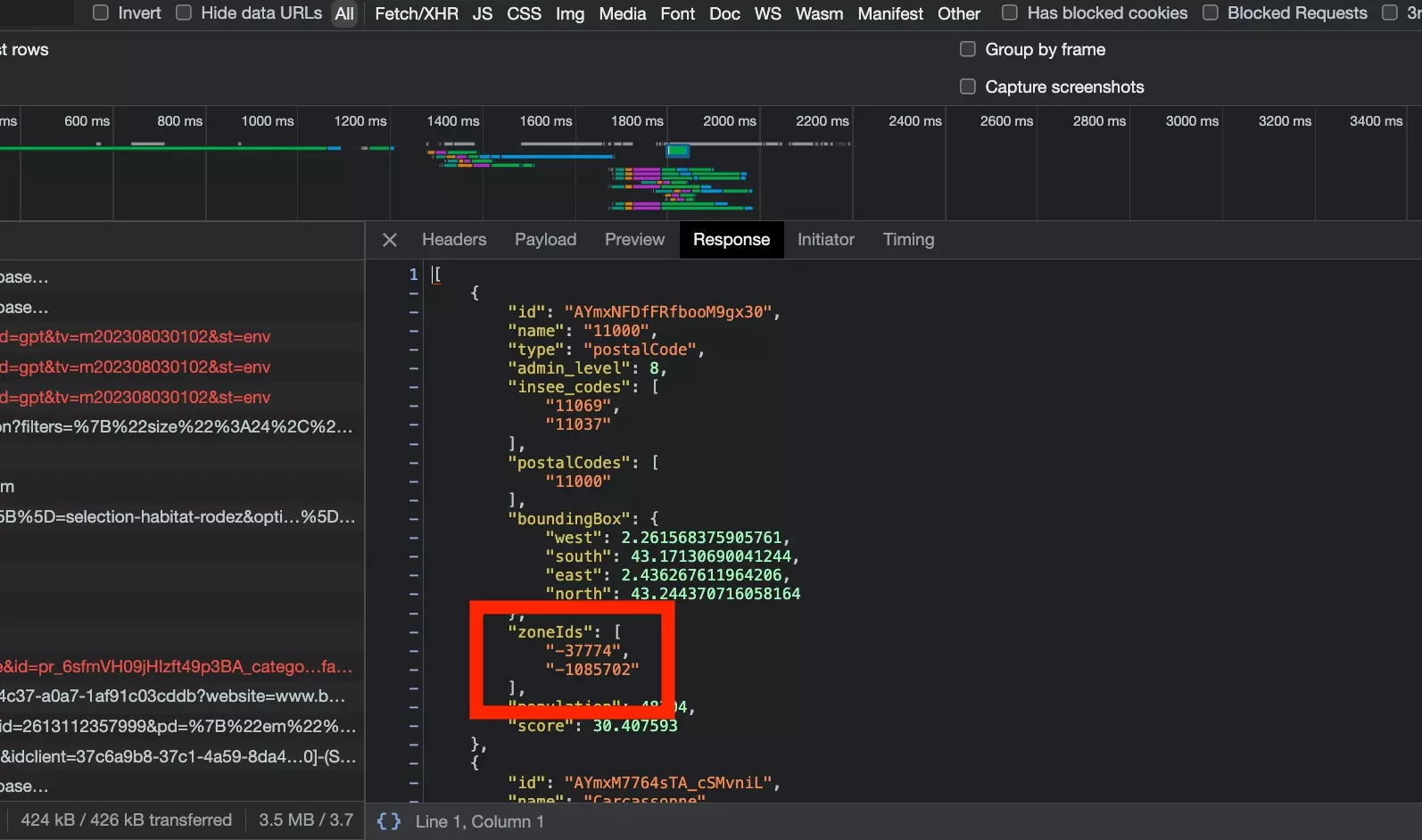
On a donc deux cas de figure:
Pas de nouvel élément à envoyer au niveau de la requête d’API.
Voilà le cURL de la requête:
curl 'https://res.bienici.com/suggest.json?q=110000' \ -H 'authority: res.bienici.com' \ -H 'accept: */*' \ -H 'accept-language: fr-FR,fr;q=0.9,en-US;q=0.8,en;q=0.7' \ -H 'origin: https://www.bienici.com' \ -H 'referer: https://www.bienici.com/' \ -H 'sec-ch-ua: "Not/A)Brand";v="99", "Google Chrome";v="115", "Chromium";v="115"' \ -H 'sec-ch-ua-mobile: ?0' \ -H 'sec-ch-ua-platform: "macOS"' \ -H 'sec-fetch-dest: empty' \ -H 'sec-fetch-mode: cors' \ -H 'sec-fetch-site: same-site' \ -H 'user-agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36' \ --compressedf
Qu’on va donc transformer en Python, comme suit:
def get_location_ids(path): """ Retrieve location IDs for the given path. Args: path (str): The path containing the locations to retrieve IDs for. Returns: list: A list of location IDs. Raises: AssertionError: If the path is not provided, or if an expected assertion fails during the retrieval process. """ assert path and isinstance(path, str) # https://www.bienici.com/recherche/location/marseille-13000,paris-75000,montpellier-34000/ path = [p for p in path.split('/') if p] locations = path[2].split(',') if len(locations) == 1 and "".join(locations) == 'france': return [] location_ids = [] for l in locations: url = 'https://res.bienici.com/suggest.json?q=%s' % l print('searching location id for %s' % l) response = requests.get(url, headers=HEADERS) assert response.status_code == 200 location_dict = response.json()[0] location_ids_list = location_dict["zoneIds"] assert location_ids_list for l in location_ids_list: print('found %s' % l) location_ids.append(l) return location_idsf
Et ensuite ajouter ces nouvelles variables au niveau de nos paramètres d’API:
def convert_url_to_api_parameters(url): ... PARAMS = {"filters":{}} FILTERS = PARAMS["filters"] ... # /marseille-13000,paris-75000,montpellier-34000/ # /france/ location_ids = get_location_ids(path) if location_ids: FILTERS["zoneIdsByTypes"] = {"zoneIds":location_ids} ... assert PARAMS return PARAMSf
Et en exécutant le script:
$ python3 bienici-listings-scraper.py searching location id for 11000 found -37774 found -1085702 {'filters': {'size': 24, 'from': None, 'page': None, 'onTheMarket': [True], 'zoneIdsByTypes': {'zoneIds': ['-37774', '-1085702']}, 'filterType': 'buy', 'propertyType': ['castle'], 'minRooms': 10, 'minArea': 1000, 'hasFirePlace': True, 'sortBy': 'relevance', 'sortOrder': 'desc'}}f
4. Navigation d’une page à l’autre
OKK on convertit maintenant n’importe quel URL en paramètres d’API. Eureka!
Et si on prend cet url:
Il est transformé en paramètres d’API, comme suit:
{'filters': {'size': 24, 'from': None, 'page': None, 'onTheMarket': [True], 'zoneIdsByTypes': {'zoneIds': ['-37774', '-1085702']}, 'filterType': 'buy', 'propertyType': ['castle'], 'minRooms': 10, 'minArea': 1000, 'hasFirePlace': True, 'sortBy': 'relevance', 'sortOrder': 'desc'}}f
Il suffit donc de remplacer le dictionnaire que l’on envoie, vu à la partie 1, par le dictionnaire avec les bons paramètres d’API.
Mais cela va nous permettre de récupérer uniquement la première page de résultats. Comment passer d’une page à l’autre?
On va donc, comme dans les parties précédentes, en ayant l’onglet Network de l’outil d’inspection, passer d’une page à l’autre, et observer le format de la nouvelle requête échangée:
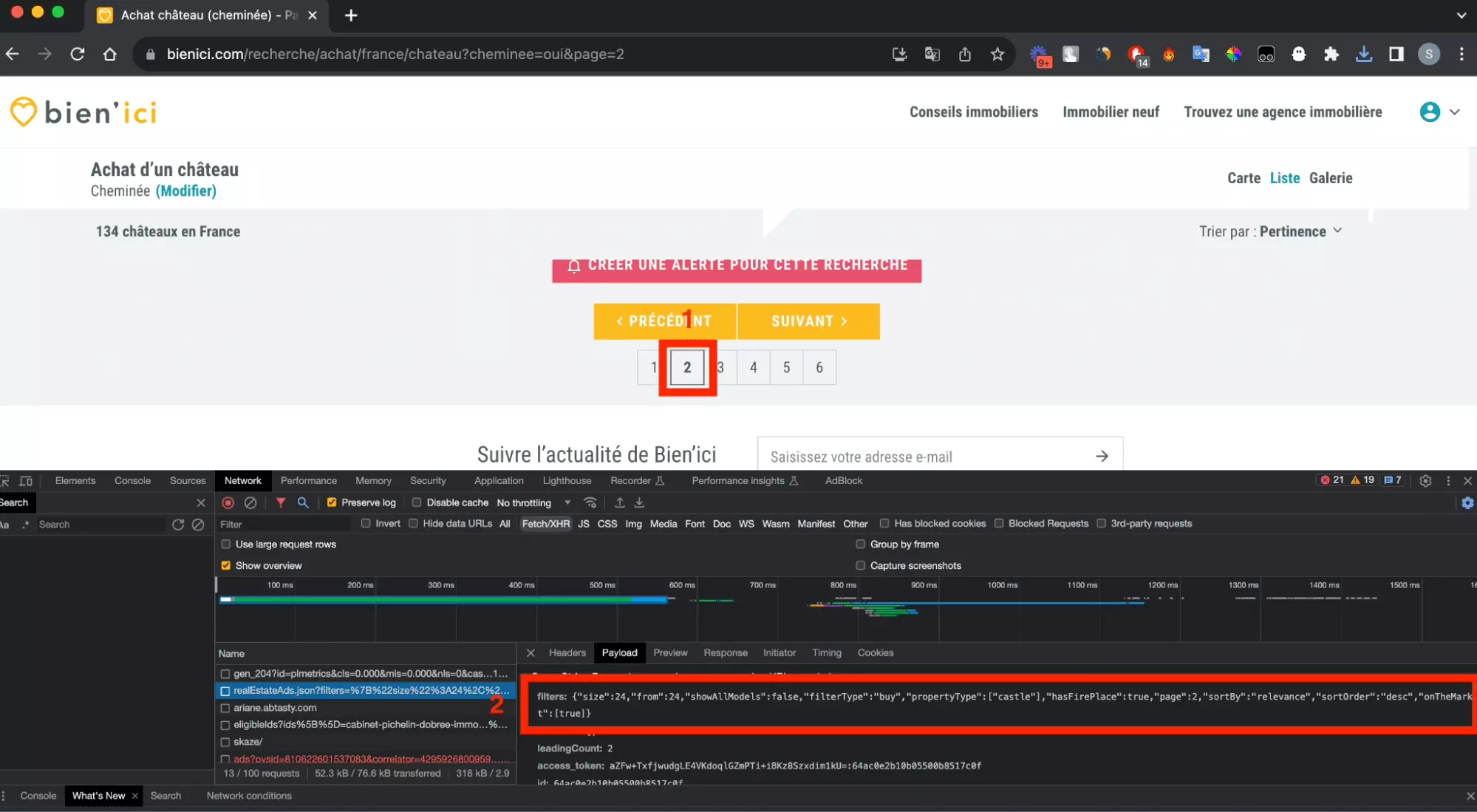
Et ici, on peut observer que deux nouveaux paramètres de pagination apparaissent:
- page le numéro de la page visitée
- from le nombre de biens que l’on a vu jusqu’ici
OKK, on va maintenant convertir ça en Python! Avec le code comme suit:
def go_api_page(params, page): """ Send a GET request to the API page with the specified parameters. Args: params (dict): The parameters to include in the GET request. Returns: requests.Response: The response object from the API page. Raises: AssertionError: If the response status code is not 200 (OK) after retrying. """ print('going to page: %s' % page) response = requests.get('https://www.bienici.com/realEstateAds.json', params=params, headers=HEADERS) assert response.status_code == 200 return response def collect_results(url): """ Collect the results by making API requests and scraping the data. Raises: AssertionError: If any of the assertions fail during the data collection process. """ page = 1 total_scraped_results = 0 total_results_to_scrape = None total_available_results = None params = convert_url_to_api_parameters(url) assert params while True: assert page and isinstance(page, int) params["filters"]["page"] = page params["filters"]["from"] = (page-1)*24 _params = copy.deepcopy(params) _params["filters"] = json.dumps(_params["filters"]) assert _params response = go_api_page(_params, page) listings = response.json()['realEstateAds'] total_scraped_results+=len(listings) total_available_results = response.json()["total"] assert total_available_results is not None and isinstance(total_available_results, int) total_results_to_scrape = min(total_available_results, 2500) assert all([total_available_results, total_results_to_scrape]) if page == 1: print("total results: %s" % total_available_results) print("total results to scrape: %s" % total_results_to_scrape) if total_scraped_results >= total_available_results: print('all data collected') break page += 1f
Et en lançant le script partiel:
$ python3 bienici-listings-scraper.py going to page: 1 total results: 578 total results to scrape: 578 going to page: 2 going to page: 3 going to page: 4 ... going to page: 19 going to page: 20 going to page: 21 going to page: 22 going to page: 23 going to page: 24 going to page: 25 all data collectedf
On pagine avec succès! Ne nous reste plus qu’à récupérer les données, et proprement les exporter dans un fichier .csv.
Allons-y.
5. Parsing des données
Chaque bien sur le site est structuré dans un dictionnaire comme suit:
{ "blurInfo":{ "type":"disk", "radius":250, "bbox":[ 0.2560260064912187, 49.689687975138945, 0.2629693614859498, 49.6941796186882 ], "origin":"accounts", "position":{ "lat":49.691933796913574, "lon":0.25949768398858425 }, "centroid":{ "lat":49.691933796913574, "lon":0.25949768398858425 } }, "city":"Les Loges", "postalCode":"76790", "hasGeorisquesMention":true, "id":"netty-perrey-house-32129", "adType":"buy", "propertyType":"castle", "reference":"VM32129-PERREY", "description":"Situé aux portes d'Etretat, le Domaine Du Château du Bois est implanté sur un parc arboré de 6 hectares.<br>Actuellement exploité en parc aventure, accrobranche, murs d'escalade, hébergements natures et insolites, vous pourrez continuer à développer ou innover dans votre propre activité.<br>Le Château du Bois , milieu 19ès, d'une superficie de plus de 550m² offre un logement de fonction et des surfaces à réexploiter.<br>Sur le domaines, une autre bâtisse de plus de 200m², avec une salle de réception au rez-de-chaussée et quatre grandes suites à l'étage.<br>Renseignements en agence<br>Honoraires à la charge du vendeur. Classe énergie F, Classe climat F. Logement à consommation énergétique excessive. La loi impose que le niveau de performance énergétique (DPE) du bien immobilier, actuellement de classe F, soit compris, à compter du 1er janvier 2028, entre la classe A et la classe E. Montant moyen estimé des dépenses annuelles d'énergie pour un usage standard, établi à partir des prix de l'énergie de l'année 2021 : entre 5310.00 et 7220.00 €. Ce bien vous est proposé par un agent commercial. Nos honoraires : <span class=\"importDescriptionDecorator\" data-url=\"https://files.netty.immo/file/perrey/152/4z277/bareme_honoraires_de_negociation.pdf\" data-type=\"agencyFeeUrl\">https://files.netty.immo/file/perrey/152/4z277/bareme_honoraires_de_negociation.pdf</span> Les informations sur les risques auxquels ce bien est exposé sont disponibles sur le site Géorisques : georisques.gouv.fr <br>L'Agence au coeur de vote projet !", "title":"Domaine 6 hectares proche Etretat", "publicationDate":"2023-07-15T12:33:52.315Z", "modificationDate":"2023-08-10T16:55:26.893Z", "newProperty":false, "yearOfConstruction":1850, "virtualTours":[ { "url":"https://player.previsite.net/video/A898EE8D1CB15DC0D0486CE37E75D890", "previewImageUrl":"https://player.previsite.net/image/A898EE8D1CB15DC0D0486CE37E75D890.jpg", "type":"video", "highlighted":true, "accepted":true, "https":true, "size":"responsive", "mobileSupport":true, "id":"netty-perrey-house-32129_virtualTour_0" } ], "accountType":"agency", "isBienIciExclusive":false, "price":2580000, "surfaceArea":777, "landSurfaceArea":58208, "roomsQuantity":33, "bedroomsQuantity":22, "floorQuantity":2, "hasTerrace":false, "hasUnobstructedView":true, "isExclusiveSaleMandate":true, "photos":[ { "url_photo":"https://img.netty.immo/productw/perrey/2/VM32129/1689102585_VM32129_11_original.jpg", "photo":"netty-perrey-house-32129_img.netty.immo_productw_perrey_2_VM32129_1689102585_VM32129_11_original.jpg", "url":"https://file.bienici.com/photo/netty-perrey-house-32129_img.netty.immo_productw_perrey_2_VM32129_1689102585_VM32129_11_original.jpg" }, { "url_photo":"https://img.netty.immo/productw/perrey/2/VM32129/1689103511_VM32129_69_original.jpg", "photo":"netty-perrey-house-32129_img.netty.immo_productw_perrey_2_VM32129_1689103511_VM32129_69_original.jpg", "url":"https://file.bienici.com/photo/netty-perrey-house-32129_img.netty.immo_productw_perrey_2_VM32129_1689103511_VM32129_69_original.jpg" }, { "url_photo":"https://img.netty.immo/productw/perrey/2/VM32129/1689103549_VM32129_75_original.jpg", "photo":"netty-perrey-house-32129_img.netty.immo_productw_perrey_2_VM32129_1689103549_VM32129_75_original.jpg", "url":"https://file.bienici.com/photo/netty-perrey-house-32129_img.netty.immo_productw_perrey_2_VM32129_1689103549_VM32129_75_original.jpg" }, { "url_photo":"https://img.netty.immo/productw/perrey/2/VM32129/1689103533_VM32129_73_original.jpg", "photo":"netty-perrey-house-32129_img.netty.immo_productw_perrey_2_VM32129_1689103533_VM32129_73_original.jpg", "url":"https://file.bienici.com/photo/netty-perrey-house-32129_img.netty.immo_productw_perrey_2_VM32129_1689103533_VM32129_73_original.jpg" }, { "url_photo":"https://img.netty.immo/productw/perrey/2/VM32129/1689102585_VM32129_4_original.jpg", "photo":"netty-perrey-house-32129_img.netty.immo_productw_perrey_2_VM32129_1689102585_VM32129_4_original.jpg", "url":"https://file.bienici.com/photo/netty-perrey-house-32129_img.netty.immo_productw_perrey_2_VM32129_1689102585_VM32129_4_original.jpg" }, { "url_photo":"https://img.netty.immo/productw/perrey/2/VM32129/1689102585_VM32129_10_original.jpg", "photo":"netty-perrey-house-32129_img.netty.immo_productw_perrey_2_VM32129_1689102585_VM32129_10_original.jpg", "url":"https://file.bienici.com/photo/netty-perrey-house-32129_img.netty.immo_productw_perrey_2_VM32129_1689102585_VM32129_10_original.jpg" }, { "url_photo":"https://img.netty.immo/productw/perrey/2/VM32129/1689102585_VM32129_3_original.jpg", "photo":"netty-perrey-house-32129_img.netty.immo_productw_perrey_2_VM32129_1689102585_VM32129_3_original.jpg", "url":"https://file.bienici.com/photo/netty-perrey-house-32129_img.netty.immo_productw_perrey_2_VM32129_1689102585_VM32129_3_original.jpg" }, { "url_photo":"https://img.netty.immo/productw/perrey/2/VM32129/1689102585_VM32129_19_original.jpg", "photo":"netty-perrey-house-32129_img.netty.immo_productw_perrey_2_VM32129_1689102585_VM32129_19_original.jpg", "url":"https://file.bienici.com/photo/netty-perrey-house-32129_img.netty.immo_productw_perrey_2_VM32129_1689102585_VM32129_19_original.jpg" }, { "url_photo":"https://img.netty.immo/productw/perrey/2/VM32129/1689102585_VM32129_7_original.jpg", "photo":"netty-perrey-house-32129_img.netty.immo_productw_perrey_2_VM32129_1689102585_VM32129_7_original.jpg", "url":"https://file.bienici.com/photo/netty-perrey-house-32129_img.netty.immo_productw_perrey_2_VM32129_1689102585_VM32129_7_original.jpg" }, { "url_photo":"https://img.netty.immo/productw/perrey/2/VM32129/1689102586_VM32129_12_original.jpg", "photo":"netty-perrey-house-32129_img.netty.immo_productw_perrey_2_VM32129_1689102586_VM32129_12_original.jpg", "url":"https://file.bienici.com/photo/netty-perrey-house-32129_img.netty.immo_productw_perrey_2_VM32129_1689102586_VM32129_12_original.jpg" }, { "url_photo":"https://img.netty.immo/productw/perrey/2/VM32129/1689102585_VM32129_6_original.jpg", "photo":"netty-perrey-house-32129_img.netty.immo_productw_perrey_2_VM32129_1689102585_VM32129_6_original.jpg", "url":"https://file.bienici.com/photo/netty-perrey-house-32129_img.netty.immo_productw_perrey_2_VM32129_1689102585_VM32129_6_original.jpg" }, { "url_photo":"https://img.netty.immo/productw/perrey/2/VM32129/1689102585_VM32129_9_original.jpg", "photo":"netty-perrey-house-32129_img.netty.immo_productw_perrey_2_VM32129_1689102585_VM32129_9_original.jpg", "url":"https://file.bienici.com/photo/netty-perrey-house-32129_img.netty.immo_productw_perrey_2_VM32129_1689102585_VM32129_9_original.jpg" }, { "url_photo":"https://img.netty.immo/productw/perrey/2/VM32129/1689102586_VM32129_1_original.jpg", "photo":"netty-perrey-house-32129_img.netty.immo_productw_perrey_2_VM32129_1689102586_VM32129_1_original.jpg", "url":"https://file.bienici.com/photo/netty-perrey-house-32129_img.netty.immo_productw_perrey_2_VM32129_1689102586_VM32129_1_original.jpg" }, { "url_photo":"https://img.netty.immo/productw/perrey/2/VM32129/1689102586_VM32129_13_original.jpg", "photo":"netty-perrey-house-32129_img.netty.immo_productw_perrey_2_VM32129_1689102586_VM32129_13_original.jpg", "url":"https://file.bienici.com/photo/netty-perrey-house-32129_img.netty.immo_productw_perrey_2_VM32129_1689102586_VM32129_13_original.jpg" }, { "url_photo":"https://img.netty.immo/productw/perrey/2/VM32129/1689102585_VM32129_8_original.jpg", "photo":"netty-perrey-house-32129_img.netty.immo_productw_perrey_2_VM32129_1689102585_VM32129_8_original.jpg", "url":"https://file.bienici.com/photo/netty-perrey-house-32129_img.netty.immo_productw_perrey_2_VM32129_1689102585_VM32129_8_original.jpg" }, { "url_photo":"https://img.netty.immo/productw/perrey/2/VM32129/1689102585_VM32129_5_original.jpg", "photo":"netty-perrey-house-32129_img.netty.immo_productw_perrey_2_VM32129_1689102585_VM32129_5_original.jpg", "url":"https://file.bienici.com/photo/netty-perrey-house-32129_img.netty.immo_productw_perrey_2_VM32129_1689102585_VM32129_5_original.jpg" }, { "url_photo":"https://img.netty.immo/productw/perrey/2/VM32129/1689102585_VM32129_15_original.jpg", "photo":"netty-perrey-house-32129_img.netty.immo_productw_perrey_2_VM32129_1689102585_VM32129_15_original.jpg", "url":"https://file.bienici.com/photo/netty-perrey-house-32129_img.netty.immo_productw_perrey_2_VM32129_1689102585_VM32129_15_original.jpg" }, { "url_photo":"https://img.netty.immo/productw/perrey/2/VM32129/1689102585_VM32129_14_original.jpg", "photo":"netty-perrey-house-32129_img.netty.immo_productw_perrey_2_VM32129_1689102585_VM32129_14_original.jpg", "url":"https://file.bienici.com/photo/netty-perrey-house-32129_img.netty.immo_productw_perrey_2_VM32129_1689102585_VM32129_14_original.jpg" }, { "url_photo":"https://img.netty.immo/productw/perrey/2/VM32129/1689102585_VM32129_16_original.jpg", "photo":"netty-perrey-house-32129_img.netty.immo_productw_perrey_2_VM32129_1689102585_VM32129_16_original.jpg", "url":"https://file.bienici.com/photo/netty-perrey-house-32129_img.netty.immo_productw_perrey_2_VM32129_1689102585_VM32129_16_original.jpg" }, { "url_photo":"https://img.netty.immo/productw/perrey/2/VM32129/1689102586_VM32129_2_original.jpg", "photo":"netty-perrey-house-32129_img.netty.immo_productw_perrey_2_VM32129_1689102586_VM32129_2_original.jpg", "url":"https://file.bienici.com/photo/netty-perrey-house-32129_img.netty.immo_productw_perrey_2_VM32129_1689102586_VM32129_2_original.jpg" }, { "url_photo":"https://img.netty.immo/productw/perrey/2/VM32129/1689102585_VM32129_17_original.jpg", "photo":"netty-perrey-house-32129_img.netty.immo_productw_perrey_2_VM32129_1689102585_VM32129_17_original.jpg", "url":"https://file.bienici.com/photo/netty-perrey-house-32129_img.netty.immo_productw_perrey_2_VM32129_1689102585_VM32129_17_original.jpg" }, { "url_photo":"https://img.netty.immo/productw/perrey/2/VM32129/1689102585_VM32129_23_original.jpg", "photo":"netty-perrey-house-32129_img.netty.immo_productw_perrey_2_VM32129_1689102585_VM32129_23_original.jpg", "url":"https://file.bienici.com/photo/netty-perrey-house-32129_img.netty.immo_productw_perrey_2_VM32129_1689102585_VM32129_23_original.jpg" }, { "url_photo":"https://img.netty.immo/productw/perrey/2/VM32129/1689102585_VM32129_21_original.jpg", "photo":"netty-perrey-house-32129_img.netty.immo_productw_perrey_2_VM32129_1689102585_VM32129_21_original.jpg", "url":"https://file.bienici.com/photo/netty-perrey-house-32129_img.netty.immo_productw_perrey_2_VM32129_1689102585_VM32129_21_original.jpg" }, { "url_photo":"https://img.netty.immo/productw/perrey/2/VM32129/1689102585_VM32129_22_original.jpg", "photo":"netty-perrey-house-32129_img.netty.immo_productw_perrey_2_VM32129_1689102585_VM32129_22_original.jpg", "url":"https://file.bienici.com/photo/netty-perrey-house-32129_img.netty.immo_productw_perrey_2_VM32129_1689102585_VM32129_22_original.jpg" }, { "url_photo":"https://img.netty.immo/productw/perrey/2/VM32129/1689102585_VM32129_18_original.jpg", "photo":"netty-perrey-house-32129_img.netty.immo_productw_perrey_2_VM32129_1689102585_VM32129_18_original.jpg", "url":"https://file.bienici.com/photo/netty-perrey-house-32129_img.netty.immo_productw_perrey_2_VM32129_1689102585_VM32129_18_original.jpg" }, { "url_photo":"https://img.netty.immo/productw/perrey/2/VM32129/1689102586_VM32129_24_original.jpg", "photo":"netty-perrey-house-32129_img.netty.immo_productw_perrey_2_VM32129_1689102586_VM32129_24_original.jpg", "url":"https://file.bienici.com/photo/netty-perrey-house-32129_img.netty.immo_productw_perrey_2_VM32129_1689102586_VM32129_24_original.jpg" }, { "url_photo":"https://img.netty.immo/productw/perrey/2/VM32129/1689102586_VM32129_25_original.jpg", "photo":"netty-perrey-house-32129_img.netty.immo_productw_perrey_2_VM32129_1689102586_VM32129_25_original.jpg", "url":"https://file.bienici.com/photo/netty-perrey-house-32129_img.netty.immo_productw_perrey_2_VM32129_1689102586_VM32129_25_original.jpg" }, { "url_photo":"https://img.netty.immo/productw/perrey/2/VM32129/1689102586_VM32129_26_original.jpg", "photo":"netty-perrey-house-32129_img.netty.immo_productw_perrey_2_VM32129_1689102586_VM32129_26_original.jpg", "url":"https://file.bienici.com/photo/netty-perrey-house-32129_img.netty.immo_productw_perrey_2_VM32129_1689102586_VM32129_26_original.jpg" }, { "url_photo":"https://img.netty.immo/productw/perrey/2/VM32129/1689102585_VM32129_27_original.jpg", "photo":"netty-perrey-house-32129_img.netty.immo_productw_perrey_2_VM32129_1689102585_VM32129_27_original.jpg", "url":"https://file.bienici.com/photo/netty-perrey-house-32129_img.netty.immo_productw_perrey_2_VM32129_1689102585_VM32129_27_original.jpg" }, { "url_photo":"https://img.netty.immo/productw/perrey/2/VM32129/1689102586_VM32129_28_original.jpg", "photo":"netty-perrey-house-32129_img.netty.immo_productw_perrey_2_VM32129_1689102586_VM32129_28_original.jpg", "url":"https://file.bienici.com/photo/netty-perrey-house-32129_img.netty.immo_productw_perrey_2_VM32129_1689102586_VM32129_28_original.jpg" } ], "workToDo":true, "energyValue":332, "energyClassification":"F", "greenhouseGazValue":79, "greenhouseGazClassification":"F", "feesChargedTo":"seller", "agencyFeeUrl":"https://files.netty.immo/file/perrey/152/4z277/bareme_honoraires_de_negociation.pdf", "energyPerformanceDiagnosticDate":"2023-07-03", "minEnergyConsumption":5310, "maxEnergyConsumption":7220, "energySimulationReferenceDate":"2021-01-01", "exposition":"Sud Est", "useJuly2021EnergyPerformanceDiagnostic":true, "adCreatedByPro":true, "district":{ "id_polygone":76390, "id_type":2, "name":"Les Loges", "libelle":"Les Loges", "cp":"76790", "code_insee":"76390", "id":76390, "insee_code":"76390", "postal_code":"76790", "type_id":2 }, "status":{ "onTheMarket":true, "closedByUser":false, "autoImported":true, "isLeading":false, "highlighted":false, "is3dHighlighted":false }, "addressKnown":false, "displayDistrictName":true, "pricePerSquareMeter":3320.4633204633205, "postalCodeForSearchFilters":"76790", "descriptionTextLength":1353, "userRelativeData":{ "importAccountId":"643eb01ff69fb300b6dd4eaf", "accountIds":[ "netty-ag761424" ], "searchAccountIds":[ "netty-ag761424", "contract-type-low-budget", "643eb01ff69fb300b6dd4eaf", "58f00450872c49009bfbcc10", "contract-type-agency-package", "extension-boost" ], "isAdmin":false, "isAdModifier":false, "canSeeExactPosition":false, "canSeeAddress":false, "canSeeStats":false, "canSeeContacts":false, "canSeeRealDates":false, "canSeePublicationCertificateHtml":false, "canSeePublicationCertificatePdf":false }, "priceHasDecreased":false, "transactionType":"buy", "adTypeFR":"vente", "with3dModel":false, "endOfPromotedAsExclusive":0, "chargingStations":{ "providers":[ ] }, "nothingBehindForm":false, "highlightMailContact":false, "customerId":"bruno-rioult-immobilier", "displayInsuranceEstimation":true, "needHomeStaging":true, "phoneDisplays":[ ] }f
On va donc, au sein de la liste renvoyé par le serveur, aller chercher les attributs qui nous intéressent:
- city
- postal_code
- ad_type
- property_type
- reference
- title
- publication_date
- modification_date
- new_property
- rooms_quantity
- bedrooms_quantity
- price
- photos
Comme vous le voyez, on récupère vraiment le stricte minimum! Il est possible de récupérer plus, et même de prendre le JSON brut, mais dans le cadre de ce tutoriel, on va se limiter à ces 13 attributs essentiels.
La méthode, très simple, est structurée comme suit:
FIELDNAMES = [ 'city', 'postal_code', 'ad_type', 'property_type', 'reference', 'title', 'publication_date', 'modification_date', 'new_property', 'rooms_quantity', 'bedrooms_quantity', 'price', 'photos' ] … def parse_ad(self, raw_ad): assert ad and isinstance(ad, dict) city = ad.get("city","") postal_code = ad.get("postalCode","") ad_type = ad.get("adType","") property_type = ad.get("propertyType","") reference = ad.get("reference","") title = ad.get("title","") publication_date = ad.get("publicationDate","") modification_date = ad.get("modificationDate","") new_property = ad.get("newProperty","") rooms_quantity = ad.get("roomsQuantity","") bedrooms_quantity = ad.get("bedroomsQuantity","") price = ad.get("price","") photos = ", ".join([u.get("url_photo","") for u in ad.get("photos",[])]) VALUES = [ city, postal_code, ad_type, property_type, reference, title, publication_date, modification_date, new_property, rooms_quantity, bedrooms_quantity, price, photos ] print("scraped: %s" % title) d = dict(zip(FIELDNAMES, VALUES)) return df
Ne reste plus qu’à exporter ça dans un joli fichier .csv. Et la messe est dite.
6. Sauvegarde des données au format .csv
Avoir les données au format dictionnaire c’est bien.
Plus facile à exporter, à lire, à manipuler: posséder ces données là au format .csv c’est mieux.
Dans cette dernière partie, on va donc simplement utiliser une méthode pour exporter notre liste plein de jolis dictionnaires de listing immobilier, en fichier .csv bien structuré.
Il s’agit ici aussi d’une méthode simple en Python, comme suit:
def write_to_csv(DATA, output): """ Write the collected data to a CSV file. Raises: AssertionError: If the data or output file path is not provided. """ assert DATA assert output with open(output, 'w') as f: writer = csv.DictWriter(f, fieldnames=FIELDNAMES) writer.writeheader() for d in DATA: writer.writerow(d)f
Et voilà, on est bons!
Les données apparaissent proprement structurées au format .csv, et directement exploitable sans plus de traitement:
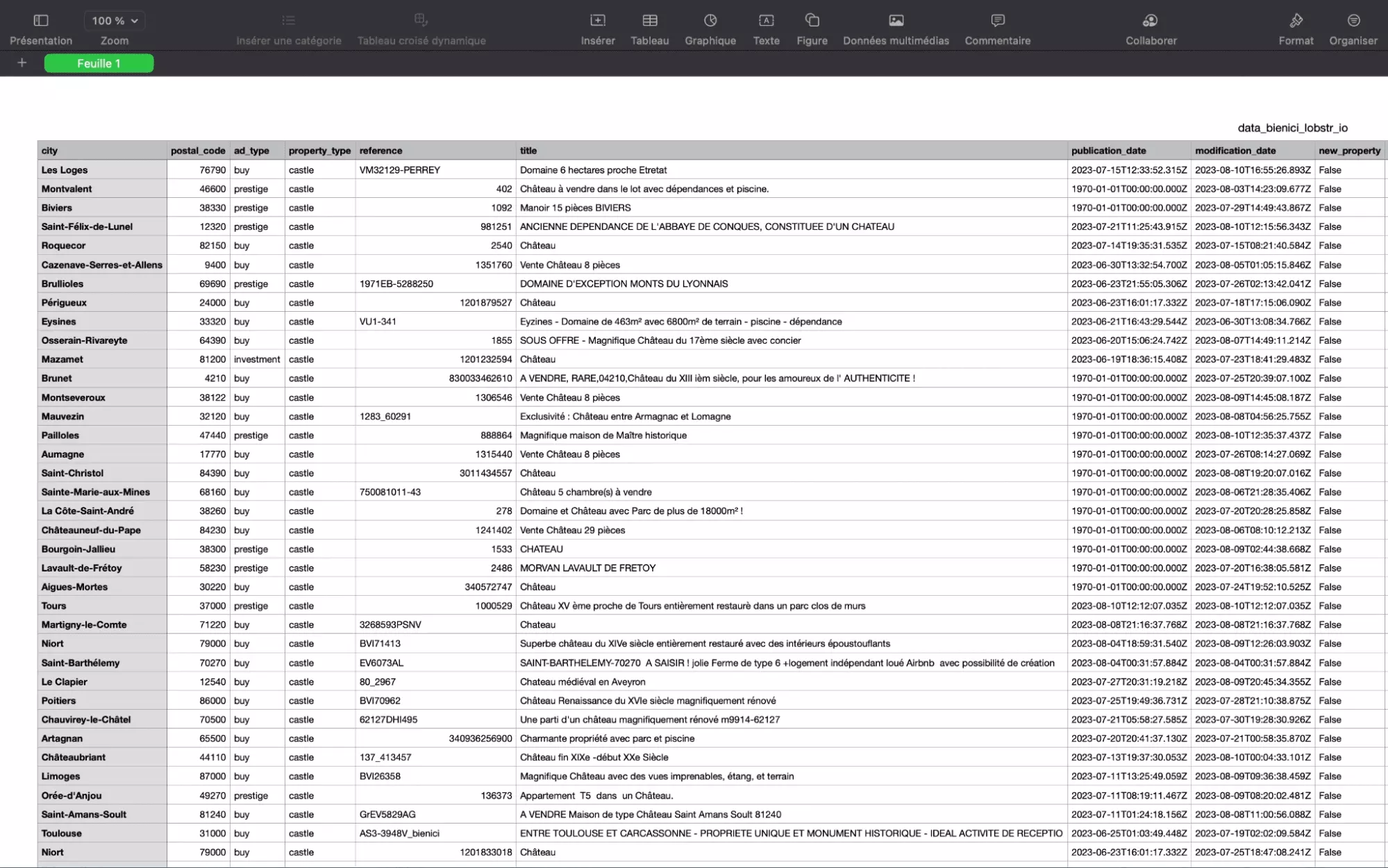
Magnifique.
✨
7. Ajout de variables dynamiques
Collecter tous les listings d’une URL donnée, c’est bien.
Mais comment faire si je veux collecter seulement les 100 premiers studios à Paris, et enregistrer ça dans un fichier .csv appelé messtudiosprefaparis.csv?
C’est ici qu’interviennent les variables dynamiques.
Avec un code comme suit:
def main(): parser = argparse.ArgumentParser(description='bienici listings scraper') parser.add_argument( '-u', '--url', type=str, required=False, default='https://www.bienici.com/recherche/achat/france/chateau', help='url to scrape the listings from -- by default https://www.bienici.com/recherche/achat/france/chateau' ) parser.add_argument( '-l', '--limit', type=range_limited_integer_type, required=False, default=2500, help='maximum number of listings to scrape -- by default 2500' ) parser.add_argument( '-o', '--output', type=str, required=False, default='data_bienici_lobstr_io.csv', help='filename to save the results -- by default data_bienici_lobstr_io.csv' ) args = parser.parse_args() scrape(url=args.url, limit=args.limit, output=args.output) if __name__ == '__main__': main()f
On peut maintenant préciser 3 paramètres de façon dynamique depuis la ligne de commande:
- u — l’URL de recherche Bien’Ici, par defaut https://www.bienici.com/recherche/achat/france/chateau
- l — le nombre maximal de listings à aller chercher, par défaut on va aller chercher les 100 premiers listings
- o — le nom du fichier .csv dans lequel les données vont être enregistrées, par défaut databienicilobstr_io.csv
Et en lançant depuis la ligne de commande:
$ python3 bienici-listings-scraper.py -u https://www.bienici.com/recherche/achat/paris-75000/appartement/2-pieces-et-moins -l 10 -o test.csv searching location id for paris-75000 found -7444 going to page: 1 total results: 7677 total results to scrape: 10 scraped: 9 pièces - 5 chambres - Trocadéro -Victor Hugo scraped: PARIS XIVème - ALÉSIA - TRIPLEX TERRASSE scraped: Paris Vème - Appartement d'exception - Boulevard Saint-Germain scraped: 3 pièces au coeur d'une impasse piétonne - Paris 14e scraped: Paris XIVème: Appartement familial trois chambres exposé Sud scraped: PARIS XVI - AVENUE FOCH - MAGNIFIQUE 9 PIÈCES scraped: 4 pièces - Paris XV scraped: Alésia - Appartement familial avec terrasses - Paris XIV scraped: scraped: Saint-Charles limit reached csv written elapsed: 0.49 s ~~ success _ _ _ | | | | | | | | ___ | |__ ___| |_ __ __ | |/ _ \| '_ \/ __| __/| '__| | | (_) | |_) \__ \ |_ | | |_|\___/|_.__/|___/\__||_|f
Top, ça marche à la perfection. On a maintenu un script universel, robuste et extraordinairement flexible.
Bénéfices
Ce script Python permet donc de scraper les listings depuis Bien’Ici, et a plusieurs bénéfices clairs.
D’abord, il récupère 13 attributs distincts par listing: la ville, le code postal, le type de bien, la référence interne, le titre, le prix… Ça n’est pas l’hyper exhaustivité, mais les attributs essentiels sont là.
Par ailleurs, le script permet de collecter des données exhaustives: passer d’une page à l’autre, et récupérer toutes les données d’une catégorie donnée. Rien n’est laissé à la trappe.
Surtout, le script est universel et extraordinairement flexible: collecter les données depuis n’importe quel URL, quel que soit le type de recherche, le type d’attributs additionnels mentionnés, ou la localisation choisie. Scrapez tous les biens sur Bien’Ici, sans aucune limitation.
Limitations
D’abord, attention, sur Bien’Ici ne sont affichés que les 2500 premières annonces disponibles. Il y a une limite d’affichage stricte, indépendante de notre volonté.
Supposons que vous souhaitiez par exemple collecter les listes de 2 pièces à Paris, et qu’il y a plus de 2500 résultats disponibles. Il faudra alors segmenter votre recherche, par exemple par arrondissement:
75001, récupérer toutes les données.
75002,
75003
etc.
FAQ
Est-ce que c’est légal de scraper de la donnée sur Bien’Ici?
Le scraping fait couler beaucoup d’encre, parfois associé, à tort, à une activité illicite et répréhensible.
Effectivement, après tout, récupérer toutes les informations d’un site tiers, est-ce que ce n’est pas du vol après tout?
- accès licite aux données
- extraction non substantielle
Autrement dit, il est entièrement légal de scraper de la donnée sur Bien’Ici.
Pourquoi ne pas utiliser l’API officielle Bien’Ici?
Sauf erreur de notre part, cette API n’existe tout simplement pas.
Si je lance ce script dans 3 mois, ça va marcher?
Oui, le script a été conçu pour résister à toute modification mineure, et être robuste dans le temps.
À quoi ça sert de collecter de la donnée sur Bien’Ici?
La donnée immobilière peut servir à diverses usages:
- Recherche de biens: vous recherchez un bien, et souhaitez recevoir les biens qui correspondent à votre recherche en temps réel. Il existe toutefois des applications qui font déjà ça très bien, et on peut vous conseiller dans ces cas là d’utiliser l’alerte Bien’Ici, ou Jinka, l'agrégateur de données multi-plateformes. Attention, Jinka n’est pas disponible dans toutes les villes, à l’heure où on écrit cet article au moins.
Création d’applications tierces: vous êtes un développeur, et souhaitez bâtir une application tierce à partir des données Bien’Ici.
Analyse de tendances: vous êtes un data analyst ou un investisseur immobilier, et souhaitez faire de l’analyse de tendances sur le marché immobilier.
Est-ce qu’il existe un outil no-code pour scraper Bien’Ici?
Non, par pour le moment.
Mais si ça vous intéresse, dites le nous ici! Si ça vous intéresse, ça nous intéresse.
Conclusion
Et voilà, c’est la fin de ce tutoriel!
Dans ce tutoriel, on a vu comment, à partir de l’analyse des requêtes échangées entre Bien’Ici et votre navigateur, et en effectuant la rétro ingénierie d’un script javascript, construire un script Python pour scraper les données depuis Bien’Ici, depuis n’importe quel URL de recherche, et ce sans limitation. Quel que soit la localisation, les paramètres de filtre avancés, ou la localisation.
Si vous avez des requêtes supplémentaires, n’hésitez bien entendu pas à nous contacter directement ici.
Joyeux scraping!
🦞