
Comment scraper anonymement avec Python et des Tor Proxies?
Dans ce tutoriel, nous allons voir comment utiliser le réseau de proxies de Tor, l’acronyme anglais de The Onion Router, avec Python 3 et Torpy pour naviguer en ligne. Il s’agit d’un réseau collaboratif et décentralisé, où le message envoyé passe par une série d’identités distinctes avant d’arriver à destination, ce qu’on appelle le Onion Routing.
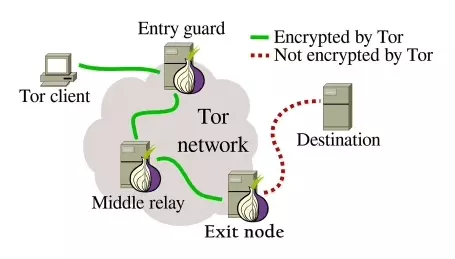
D’où ce joli logo qui prend la forme d’un oignon. Le code complet est disponible ici.
En avant!
Prérequis
Afin de réaliser ce tutoriel de bout en bout, soyez sur d’avoir les éléments suivants installés sur votre ordinateur.
Vous pouvez cliquer sur les liens ci-dessous, qui vous dirigeront soit vers un tutoriel d’installation, soit vers le site en question.
Pour préciser l’utilité de chacun des éléments cités ci-dessus: python3 est le langage informatique avec lequel nous allons scraper le pdf, et SublimeText est un éditeur de texte. Sublime.
À nous de jouer!
Installation
On va procéder comme suit:
- télécharger tor
- installer tor
- installer torpy
Télécharger ensuite le navigateur qui correspond à votre système d’exploitation. Ici pour moi, Mac OS:
Et suivez tranquillement les instructions d’installation:

$ pip3 install requests $ pip3 install torpyf
Et voilà, nous sommes prêts à scraper.
NB: avec 273 stars, 43 forks, et un commit le plus récent en date du 15/04/2021, la librairie Torpy est la librairie d’accès à Tor via Python 3 la plus populaire, la plus facile d’utilisation, et la mieux maintenue
🌟
Le code
Voilà le code en intégralité:
# On importe la classe TorRequests depuis la librairie torpy from torpy.http.requests import TorRequests print('start') with TorRequests() as tor_requests: # On réalise un première requête vers ipify.org pour connaître notre adresse IP print("build circuit #1") with tor_requests.get_session() as sess: print(sess.get("https://api.ipify.org/").text) # On réalise un première requête vers ipify.org pour connaître notre adresse IP print("build circuit #2") with tor_requests.get_session() as sess: print(sess.get("https://api.ipify.org/").text) print('~~success')f
Le code se décompose en 3 parties distinctes:
- on import de la librairie torpy
- on instancie une session Tor
- on requête https://api.ipify.org/ qui nous renvoie notre adresse IP
Et lorsque qu’on exécute le code depuis le terminal:
$ python3 torpy-tor-proxies-python-tutorial.py start build circuit #1 185.220.100.252 build circuit #2 185.220.101.33 ~~successf
On voit donc bien qu’à chaque fois qu’une session est ouverte, une nouvelle adresse IP nous est assignée.
C’est un succès total!
✨
Bénéfices
Ce code va vous permettre, en 50 secondes, d’accéder, depuis Python 3 et à l’aide de la librairie Torpy, au réseau de proxies Tor.
Autrement dit, vous allez pouvoir
- utiliser un pool de 1000-2000 adresses IPs
- anonymiser votre navigation
- gratuitement
Magnifique!
🧅
Limitations
Vous pouvez toutefois normalement accéder à Google, quand vous avez un peu de chance:
Le résultat du script ci-dessous:
$ python3 test-speed-tor-vs-brightdata.py tor ip 185.82.127.25 delay 3.131886832998134 brightdata ip 185.255.166.252 delay 0.8867947079997975 ~~successf
Avancer masqué oui, mais avancer lentement.
🐌
Conclusion
Et c’est la fin du tutoriel!
Dans ce tutoriel, nous avons vu comment utiliser les proxies du réseau Tor avec Python 3, et Torpy, la dernière librairie la plus facile d’utilisation du marché.
Happy scraping!
🦀