
Comment contourner un Captcha (simple) avec Python3 et Pytesseract?
Un CAPTCHA, acronyme qui signifie Completely Automated Public Turing test to tell Computers and Humans Apart, est un test utilisé par les sites internets partout dans le monde, pour déterminer si un utilisateur est véritablement un humain.
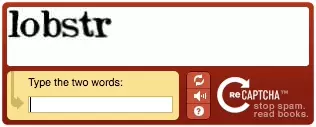
Le code est disponible en intégralité ici: https://gist.github.com/lobstrio/da95d31bff3f83a5e95ee9daeb253107#file-bypasssimplecaptcha_pytesseract-py
Prérequis
Afin de réaliser ce tutoriel de bout en bout, soyez sur d’avoir les éléments suivants installés sur votre ordinateur.
Vous pouvez cliquer sur les liens ci-dessous, qui vous dirigeront soit vers un tutoriel d’installation, soit vers le site en question.
Pour préciser l’utilité de chacun des éléments cités ci-dessus: python3 est le langage informatique avec lequel nous allons scraper le pdf, et SublimeText est un éditeur de texte. Sublime.
À nous de jouer!
Installation
On va procéder comme suit:
- Installer open-cv
- Installer pytesseract
- Installer tesseract
- Télécharger le Captcha
Pour les 2 premières librairies, Il suffit dans la console, de taper les commandes suivantes:
$ pip3 install opencv-python $ pip3 install pytesseractf
Enfin, il faut installer tesseract, qui est un OCR, l’acronyme de Optical Character Recognition, c'est-à-dire la technologie qui va permettre de déchiffrer les caractères du Captcha.
Mac OS
$ brew install tesseractf
Linux
sudo apt update sudo apt install tesseract-ocr sudo apt install libtesseract-devf
Et voilà, les librairies sont installées!
Allons désormais déchiffrer cette image. Et prouvez notre humanité. Sans aucune intervention humaine.
🤖
Guide Complet
Nous allons passer par 3 étapes distinctes:
- Resize
- Close
- Threshold
Avec les 3 transformations comme suit:

1. Resize
D’abord, nous allons redimensionner l’image. Le redimensionnement de l'image permet à l'algorithme OCR de détecter les traits de caractères ou de chiffres dans l'image d'entrée.
Le code comme suit:
filename = 'lobstr.jpeg' img = cv2.imread(filename) gry = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) (h, w) = gry.shape[:2] gry = cv2.resize(gry, (w*2, h*2))f
2. Close
Le closing est une opération morphologique visant à supprimer les petits trous dans l'image d'entrée. Si nous regardons attentivement les caractères l et b se composent de beaucoup de petits trous.
Le code:
cls = cv2.morphologyEx(gry, cv2.MORPH_CLOSE, None)f
3. Threshold
Nous appliquerons un seuil simple pour binariser l'image. Notre objectif est de supprimer tous les artefacts restants de l'image, qui nuisent à la lisibilité.
Le code:
thr = cv2.threshold(cls, 0, 255, cv2.THRESH_BINARY | cv2.THRESH_OTSU)[1]f
4. Decrypt
Et on imprime le message décodé dans la console:
txt = image_to_string(thr) print(txt)f
Le Code
Voilà le code en intégralité:
import cv2 from pytesseract import image_to_string # pip3 install opencv-python # pip3 install pytesseract # brew install tesseract filename = 'lobstr.jpeg' img = cv2.imread(filename) gry = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) (h, w) = gry.shape[:2] gry = cv2.resize(gry, (w*2, h*2)) cls = cv2.morphologyEx(gry, cv2.MORPH_CLOSE, None) thr = cv2.threshold(cls, 0, 255, cv2.THRESH_BINARY | cv2.THRESH_OTSU)[1] txt = image_to_string(thr) print(txt)f
Pour exécuter le code:
- Télécharger le code .py
- Changer le chemin de l’image
- Lancer le script via la ligne de commande
Et voilà ce qui va apparaître directement sur votre terminal:
$ python3 bypass-captcha-pytesseract-tutorial.py lobstrf
Eureka!
✨
Limitations
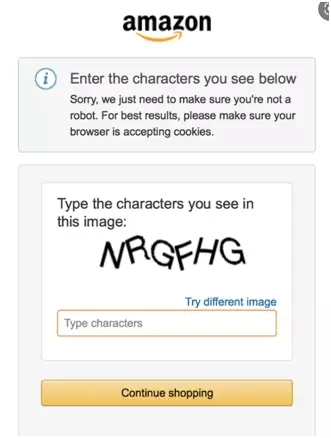
On lance le script:
$ python3 bypass-captcha-pytesseract-tutorial.py nrrthf
Qui ne fonctionne tout simplement pas.
🤷♀️
Conclusion
Et c’est la fin du tutoriel!
Dans ce tutoriel, nous avons vu comment contourner un Captcha simple avec Python3 et Pytesseract, et ce de façon programmatique.
Happy scraping!
🦀