
How to Scrape Twitter Search Results without coding [2024 Edition]
Want to analyze Twitter trends without complex code? Twitter (now X) is a goldmine of opinions and real-time reactions, but accessing that data often feels out of reach for non-coders.
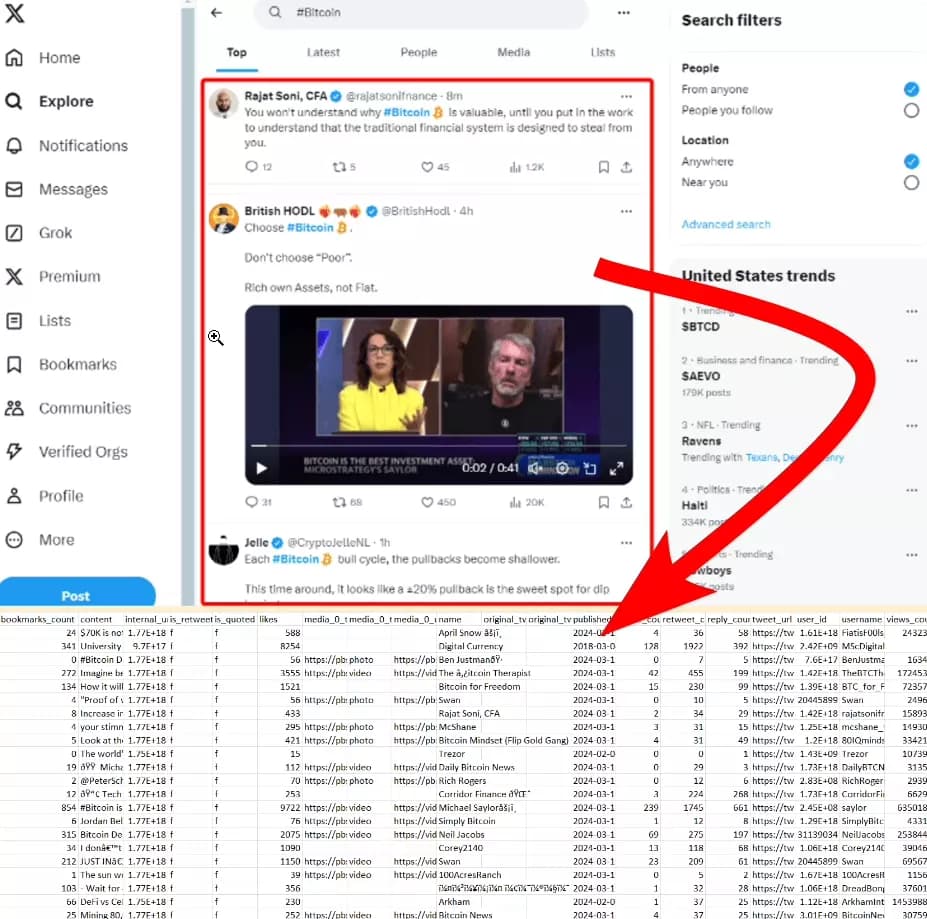
In this article, we’re going to learn how to scrape Twitter search results i.e. top and latest tweets from any search query, hashtag, or trend – without coding and absolutely for free.
But why would anyone want to scrape X trends data? Let’s explore some use cases.
Why scrape Twitter search results?
- Marketers: Track brand mentions, campaign performance, and analyze sentiment around your products or services.
- Researchers: Study public opinion, track social movements, and analyze language trends on Twitter.
- Businesses: Identify potential leads, collect customer feedback, and improve overall customer service.
- Competitive Analysis: Monitor what people are saying about your competitors' products, services, and overall brand image.
- Training Machine Learning Models: Train various ML models like sentiment analysis classifiers, topic modeling algorithms etc
But is it legal to scrape Twitter search data?
Is it legal to scrape Twitter search results?
Web scraping is legal until you’re only scraping publicly available data and no personal information is being collected.
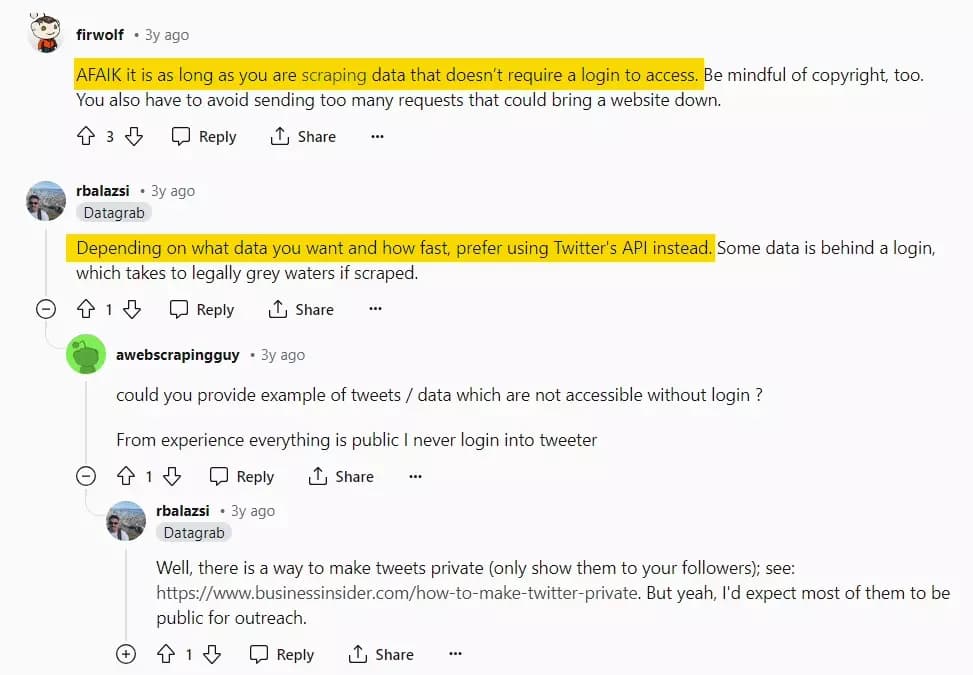
But is it true? Well, we can’t decide based on a random reddit opinion. So upon further research, I found 2 most relevant and recent law-suites about legality of scraping.
- Meta vs BrandTotal
- LinkedIn vs HiQ Labs

A federal judge ruled that BrandTotal violated Facebook's terms of use and anti-hacking laws.
Later BrandTotal updated its product, limiting itself to only public data collection; in return, Facebook agreed to cease action against the new version.

After the LinkedIn vs HiQ Labs case verdict, it has been solidified that scraping publicly available data is fully legal.
Since X search results are public tweets, they don’t have any copyright, and they don’t disclose any personal identifiable information, it’s fully legal to scrape them.

Why not use the official Twitter API?
X (formerly Twitter) does offer an API for collecting and analyzing data. Then why don’t we use it? There are plenty of reasons for not doing so.
- It’s too expensive
- It has limitations
- You need coding skills
For a step by step tutorial on how to extract data from Twitter using python, check out this article: How to scrape Tweets with Python and requests in 2023?
Now let’s address the elephant in the room – how to scrape Twitter search results without any API and without coding a custom scraper?
How to scrape Twitter search results without coding?
Cool features
- Scrape all latest and top tweets
- 25 vital data attributes e.g. tweet data, user data
- 125+ tweets per minute speed
- Cloud-based, no install required
- Schedule to scrape repeatedly and monitor
- Export data directly to Google Sheets and Amazon S3
- Developer-friendly API access
Pricing
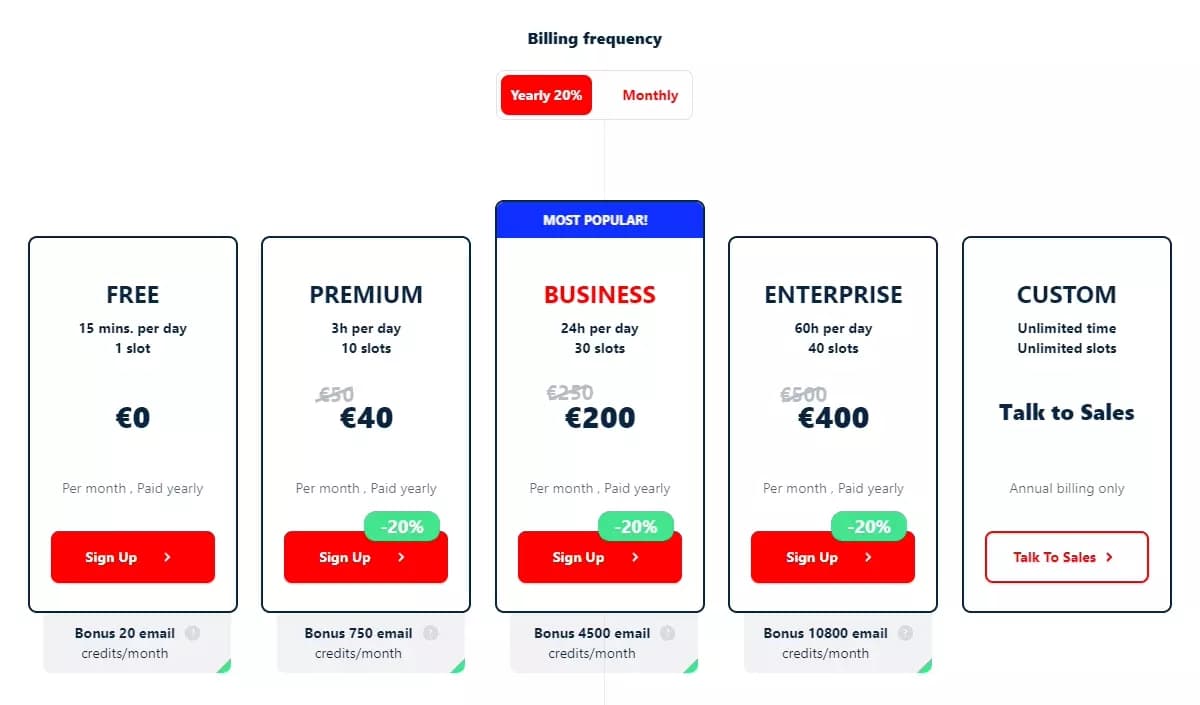
- Free: 56000 tweets per month
- Premium: €0.07 per 1000 tweets
- Business: €0.05 per 1000 tweets
- Enterprise: €0.03 per 1000 tweets
Now let’s get started ✨
Step by step guide to scraping Twitter search results using Lobstr.io
We’re going to scrape tweets from a Twitter trend published during a certain date range. We’ll do this in 6 really simple steps.
- Get Twitter search URL
- Create squid and Sync account
- Add tasks
- Adjust behavior
- Launch
- Enjoy
Let’s go!!! 💨
Step 1 - Get Twitter search URL
First step is to get the search URL from Twitter.
With Lobstr, you can scrape both top and latest tweets from any trend or search query by simply copying and pasting the search URL.
We’re going to scrape all top tweets on #bitcoin posted between March 9 - March 13, 2024. Let’s use Twitter advanced search to add date range.
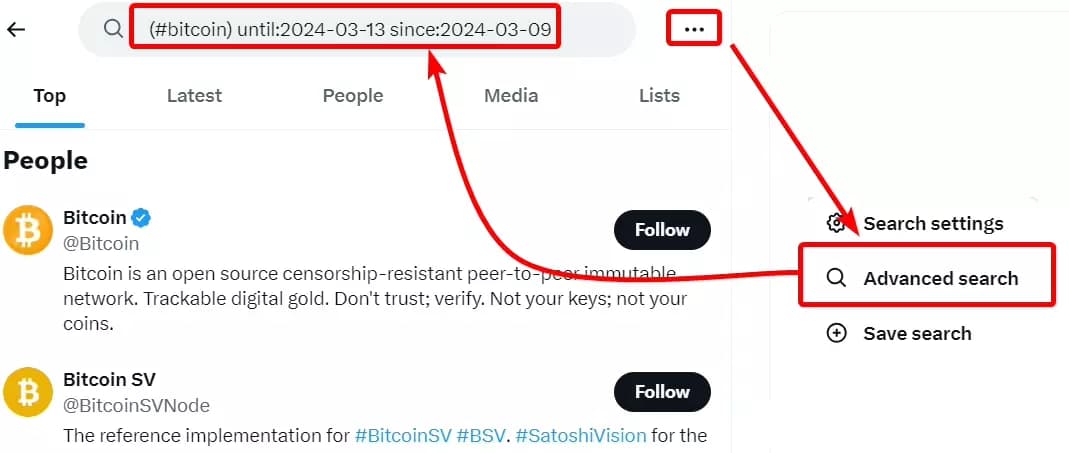
Here's the URL: https://twitter.com/search?q=(%23bitcoin)%20until%3A2024-03-13%20since%3A2024-03-09&src=typed_query
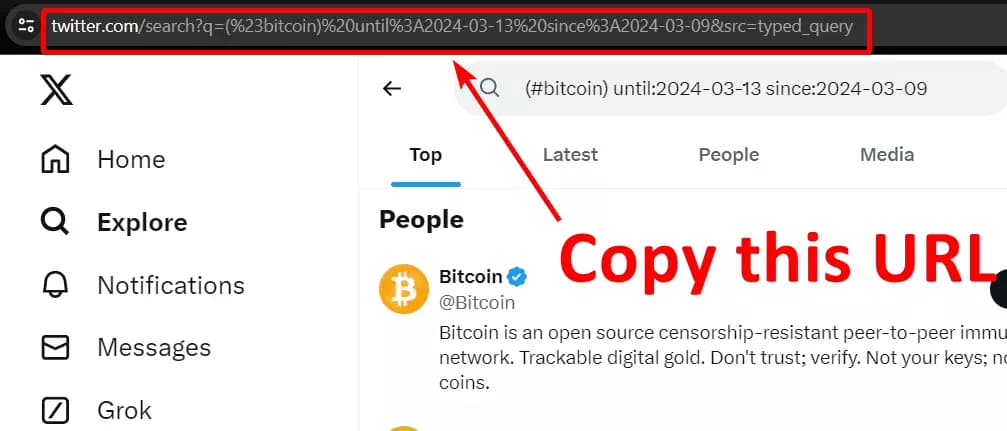
Now let’s move to the next step.
Step 2 - Create Squid and sync Twitter account
Next, go to your lobstr.io dashboard. Don’t have an account yet? It’s free! Go create one first. Once you’re in, click the new squid button and search ‘Twitter’.
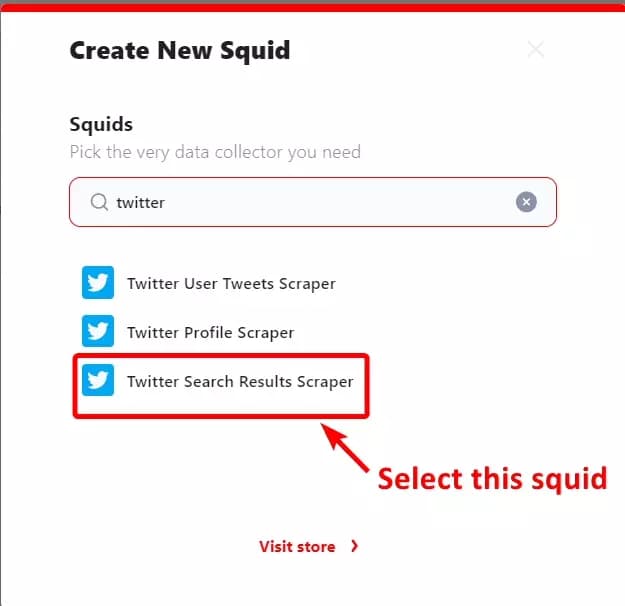
Select Twitter Search Results Scraper and you’ll see a new pop-up window asking you to sync a Twitter account.
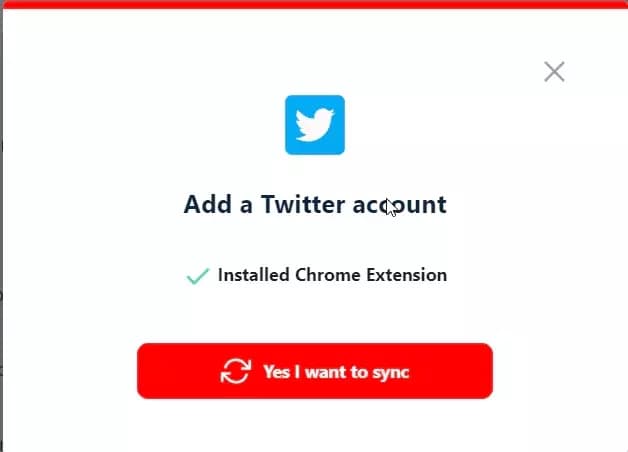
Once the Chrome Addon is installed, click Yes I want to sync, and you’re good to go.
Step 3 - Add tasks
This step is easy peasy. Just paste the Twitter search URL you copied in step 1 and click Add+. That’s it. But what if I’ve hundreds of URLs?
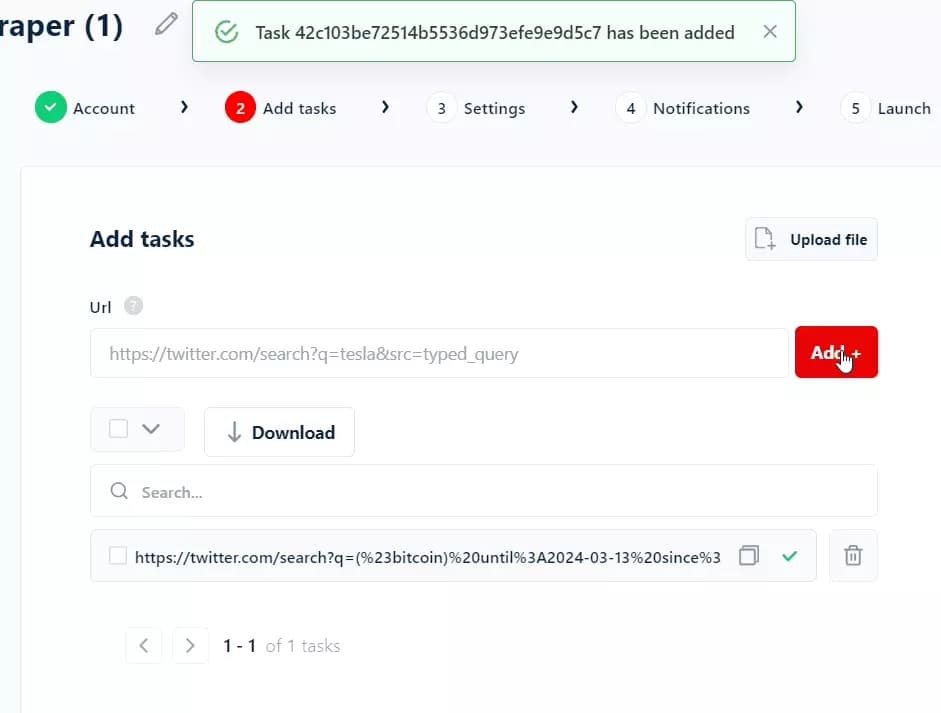
After adding tasks, click Save and you’ll see the settings menu.
Step 4 - Adjust behavior
In basic settings, you can choose the number of tweets to scrape per task. Want to scrape all tweets? Just leave it blank. I need 250 tweets only, so let’s set Max Results to 250.
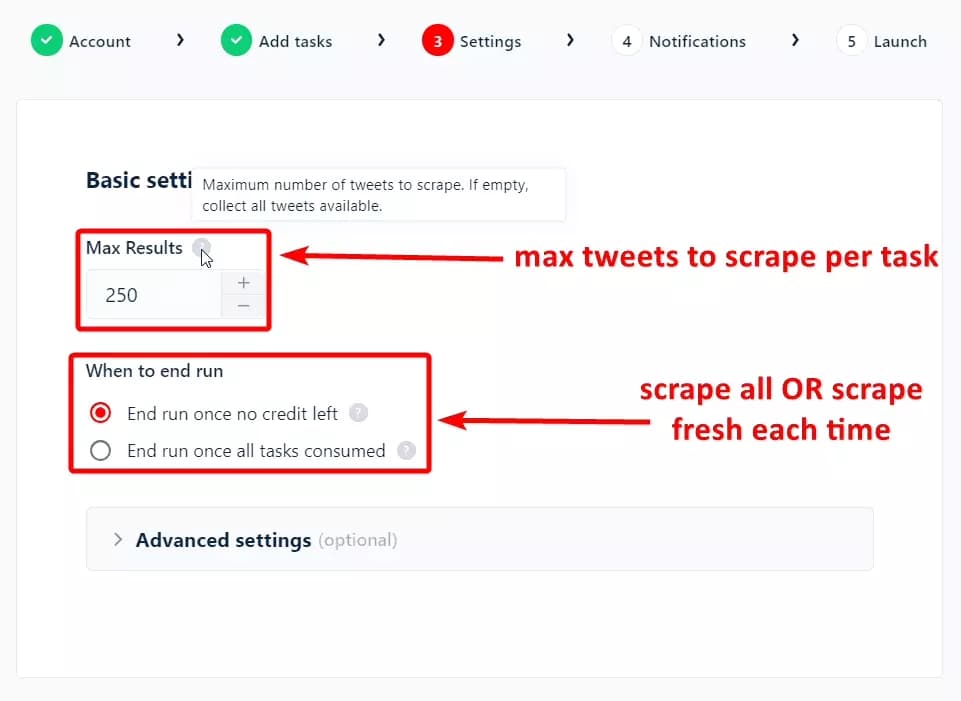
When to end run option will help you configure the freshness and quantity of data. If you want to collect fresh tweets every time the scraper runs, select the first option.
If you need all tweets available on a search query/trend, select the second option. It’s best for scraping tweets posted in specific date ranges.
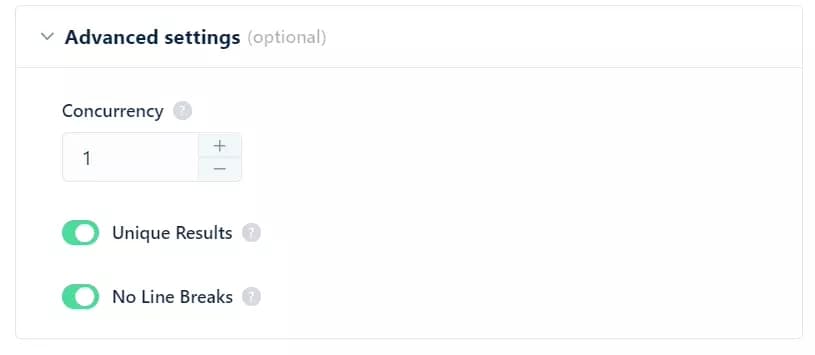
In advanced settings, you can give your crawler super speed. Use concurrency to increase the number of bots deployed per job.
more concurrency (more no. of bots) = more speed
You can remove duplicate results by toggling Unique Results, and for a better output in Excel, remove the line breaks from text using the No Line Breaks option.
After adjusting the crawler's behavior, click Save to move to notifications.
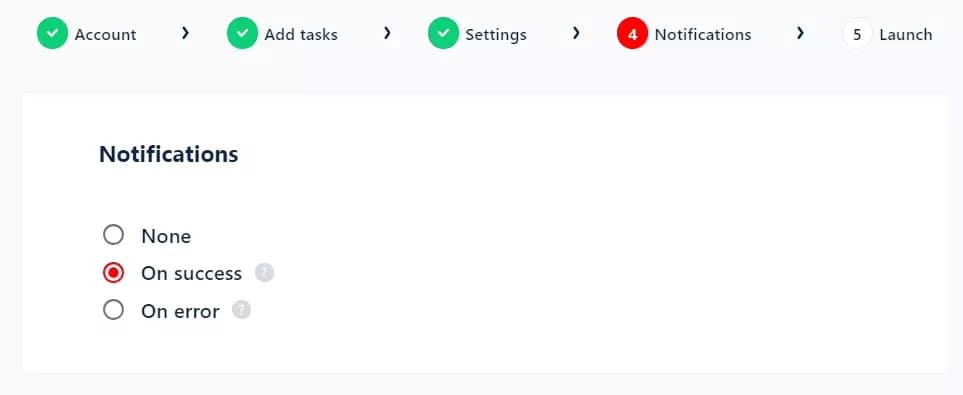
You can opt to receive email notifications when a run completes successfully or stops due to any issue.
Now we’re ready to launch 🚀
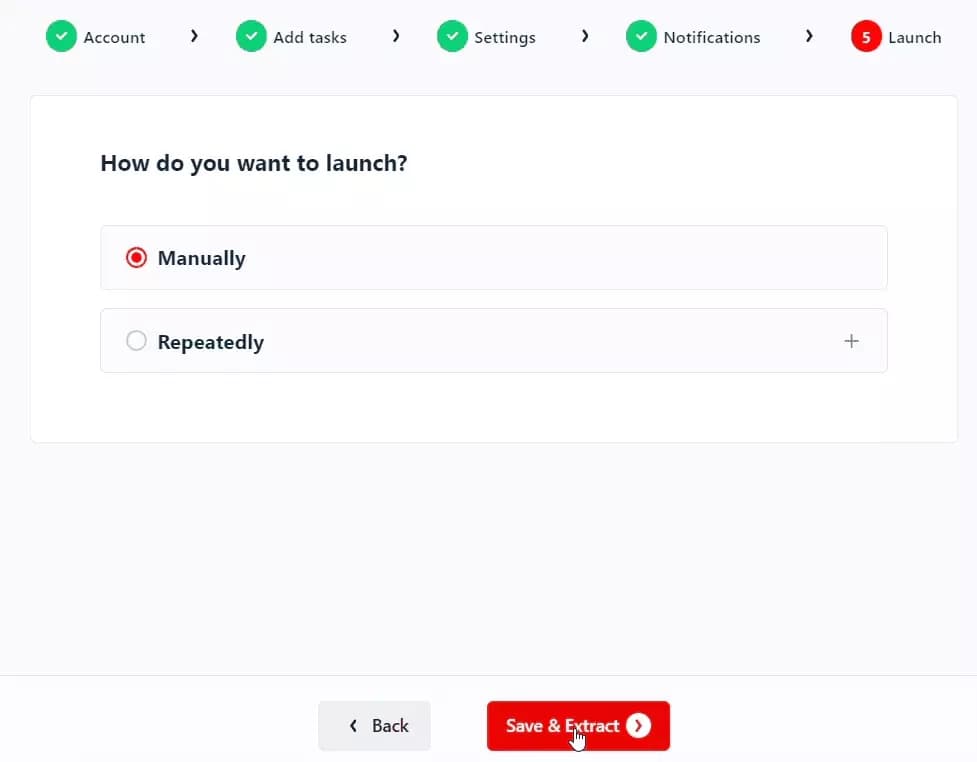
Step 5 - Launch
For instant data collection, you can launch the scraper manually. Just click the Save & Extract button and your data collection will begin.
But what if I want to monitor a trend continuously and collect fresh tweets every week or every day? That’s where the schedule feature comes into play.
You can schedule the Twitter search results scraper to run automatically and repeatedly on time and date of your choice. Whether it’s hourly, daily, weekly, or monthly.
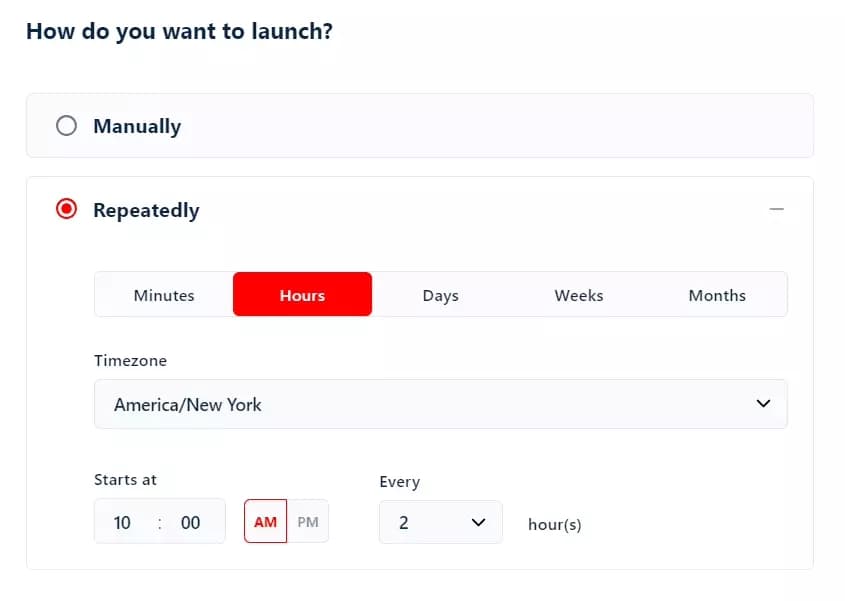
For example, I can schedule this crawler to collect the latest tweets every 2 hours, starting at 10 AM.
After setting your launch preferences, click Save and your launch sequence is complete. ✨
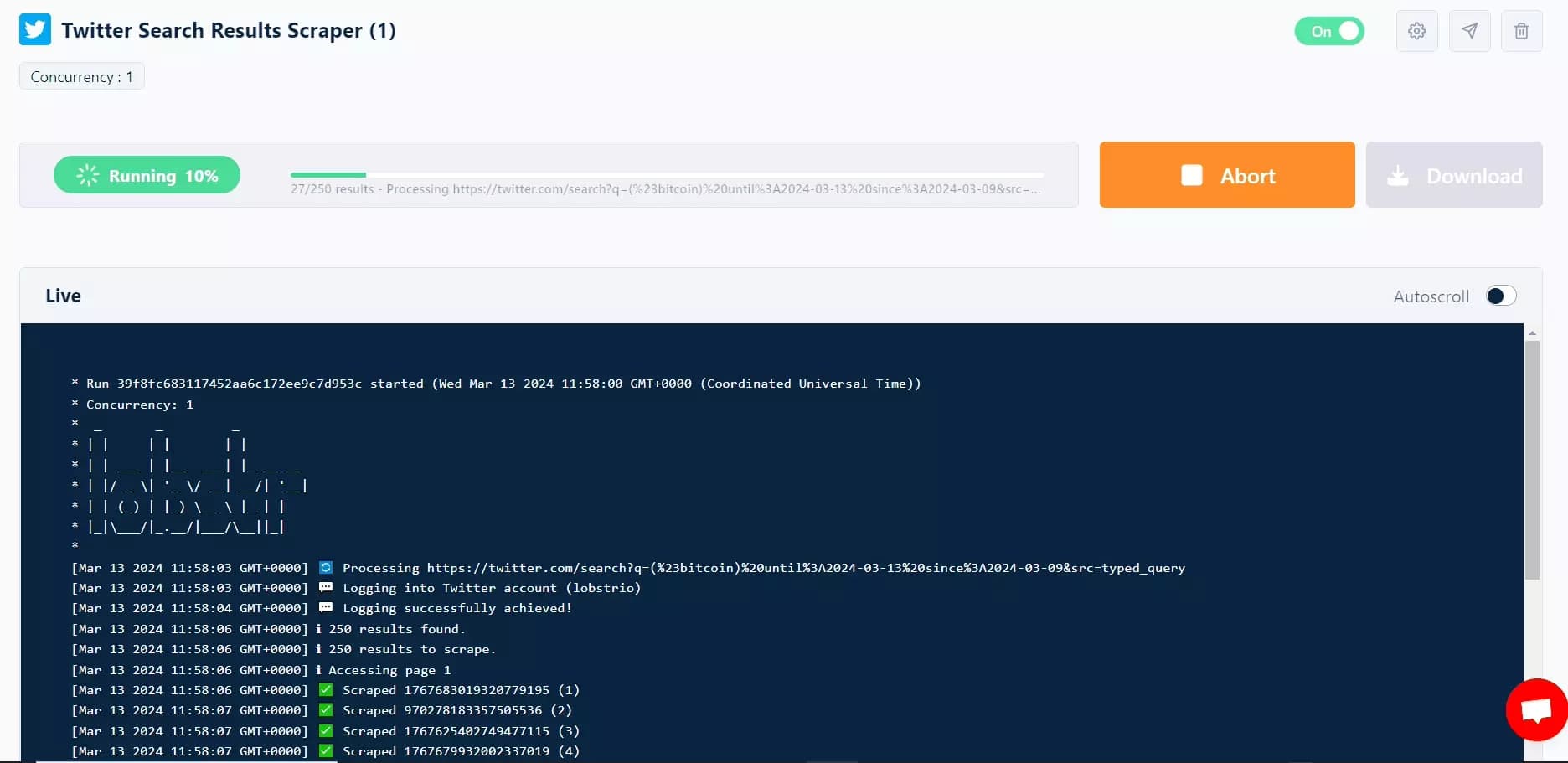
Step 6 - Enjoy
And here we go, in less than 2 minutes, we’ve collected 250 top tweets with 25 data attributes, from #bitcoin, filtered by date range.
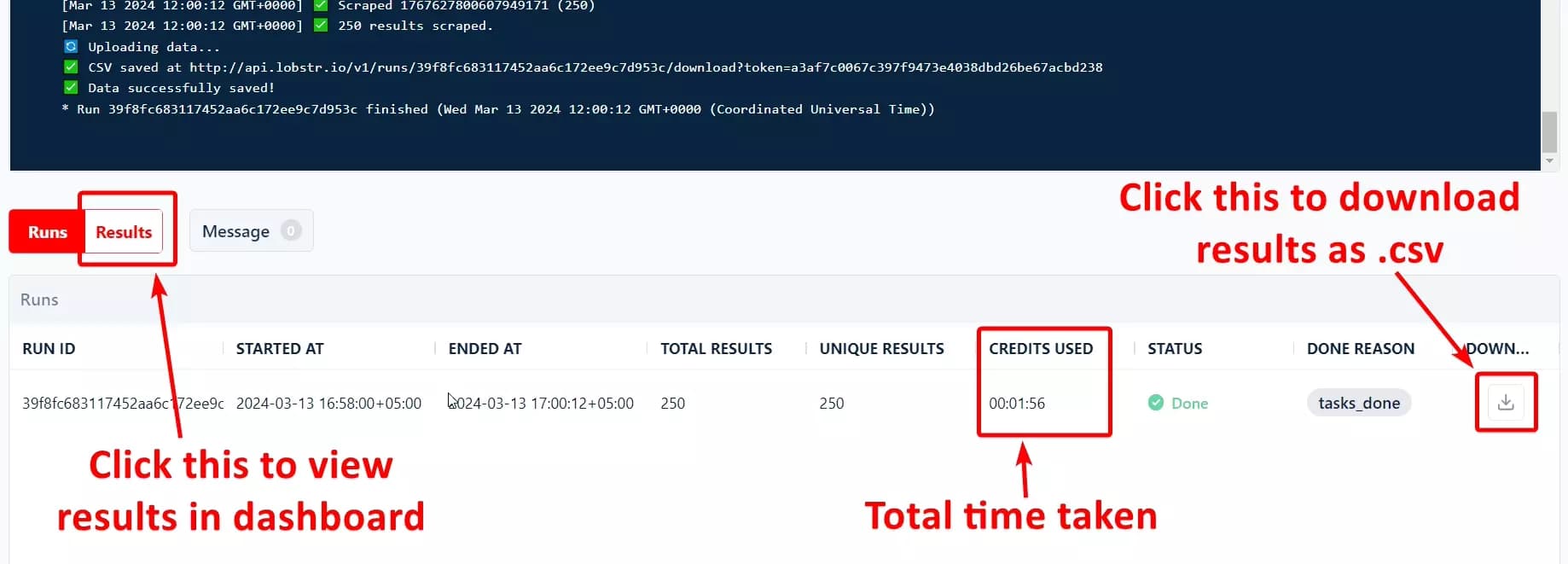
But what if I want to export them directly to Google Sheet?
That’s it. We just extracted 250 tweets from a Twitter trend in less than 2 minutes. Now let me answer some frequently asked questions for you.
FAQs
Does Twitter Search Results Scraper also offer data in JSON format?
How many tweets can you scrape?
There’s no rate limit at crawler level. You can scrape all tweets available on a Twitter trend or search query using this automation.
How to collect all tweets from a Twitter profile?
How to scrape Twitter profile data?
How can I scrape data from Twitter using Python?
Conclusion
That’s a wrap on scraping Twitter search results without coding. Try the Twitter Search Results Scraper – it’s free forever.