
Comment télécharger des ebooks depuis un .onion avec Python3
import requests r = requests.get('http://libraryqxxiqakubqv3dc2bend2koqsndbwox2johfywcatxie26bsad.onion/special/index') print(r.text)f
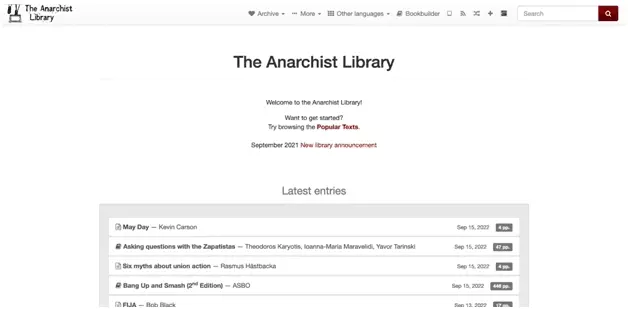
Impossible d’y accéder — avec l’impossibilité de télécharger les éléments de la page:
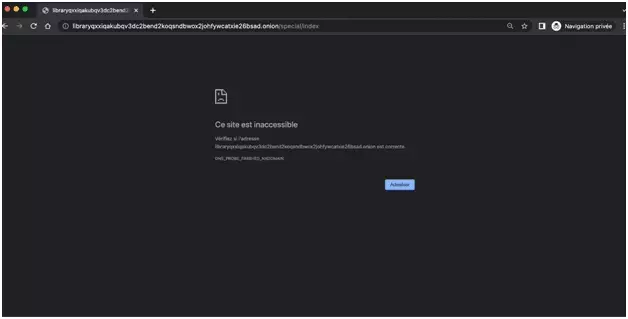
Que faire?
En route vers les sombres contrées du darknet!
🥷
Prérequis
Afin de réaliser ce tutoriel de bout en bout, soyez sur d’avoir les éléments suivants installés sur votre ordinateur.
Vous pouvez cliquer sur les liens ci-dessous, qui vous dirigeront soit vers un tutoriel d’installation, soit vers le site en question.
Pour préciser l’utilité de chacun des éléments cités ci-dessus: python3 est le langage informatique avec lequel nous allons scraper les sites et télécharger les pdf, et SublimeText est un éditeur de texte. Sublime.
À nous de jouer.
Installation
On va procéder comme suit:
- installer TorBrowser
- installer le package tor
Télécharger ensuite le navigateur qui correspond à votre système d’exploitation. Ici pour moi, Mac OS:
Et suivez ensuite simplement les instructions d’installation:

$ pip3 install requests $ pip3 install pysocks $ pip3 install lxmlf
Enfin, on va installer Tor depuis la ligne de commande:
Mac OS
$ /usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"f
$ brew install torf
On vérifie que tor est bien installé:
$ brew info tor ==> tor: stable 0.4.7.10 (bottled)f
Enfin, on lance le service:
$ brew services start torf
Linux
On installe le package:
$ sudo apt install torf
Et on lance la machine:
$ sudo /etc/init.d/tor startf
Et voilà, nous sommes prêts à scraper, avec notre navigateur requests directement connecté aux proxies de Tor.
🔥
Le code
Voilà le code en intégralité:
import requests from lxml import html import time print('~~ start') anarchist_library_onion_link = "http://libraryqxxiqakubqv3dc2bend2koqsndbwox2johfywcatxie26bsad.onion/special/index" latest_books_library_onion_link = "http://libraryqxxiqakubqv3dc2bend2koqsndbwox2johfywcatxie26bsad.onion/latest?bare=1" session = requests.session() session.proxies = {'http': 'socks5h://localhost:9050', 'https': 'socks5h://localhost:9050'} tor_ip = session.get("https://api.ipify.org/").text local_ip = requests.get("https://api.ipify.org/").text assert all([tor_ip, local_ip]) assert tor_ip != local_ip response = session.get("http://libraryqxxiqakubqv3dc2bend2koqsndbwox2johfywcatxie26bsad.onion/latest?bare=1", timeout=100) doc = html.fromstring(response.text) items = doc.xpath('//div[@class="list-group"]//div[@class="amw-listing-item"]') for i, item in enumerate(items[:10]): link = "".join(item.xpath('./a/@href')) print(link) response = session.get(link, timeout=100) assert response.ok item_page_doc = html.fromstring(response.text) pdf_link = "".join(item_page_doc.xpath('//span[@id="download-format-pdf"]/a/@href')) assert pdf_link pdf_name = pdf_link.split('/')[-1] pdf_response = session.get(pdf_link, stream=True) with open(pdf_name, 'wb') as fd: for chunk in pdf_response.iter_content(2000): fd.write(chunk) print('✅ %s (%s)' % (pdf_name, i+1)) time.sleep(1) print('~~ success') print(""" _ _ _ | | | | | | | | ___ | |__ ___| |_ __ __ | |/ _ \| '_ \/ __| __/| '__| | | (_) | |_) \__ \ |_ | | |_|\___/|_.__/|___/\__||_| """)f
Pour exécuter le code:
- télécharger le code .py
- lancer le script via la ligne de commande
Et voilà ce qui va apparaître directement sur votre terminal:
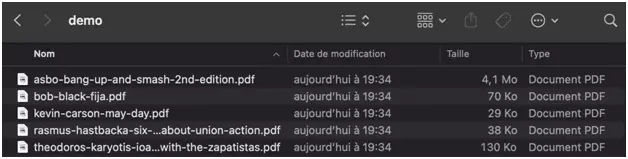
$ python3 scraping-anarchists-library-darknet-requests-tor-tutorial.py ~~ start ✅ kevin-carson-may-day.pdf (1) ✅ theodoros-karyotis-ioanna-maria-maravelidi-yavor-tarinski-asking-questions-with-the-zapatistas.pdf (2) ✅ rasmus-hastbacka-six-myths-about-union-action.pdf (3) ✅ asbo-bang-up-and-smash-2nd-edition.pdf (4) ✅ bob-black-fija.pdf (5) ~~ success _ _ _ | | | | | | | | ___ | |__ ___| |_ __ __ | |/ _ \| '_ \/ __| __/| '__| | | (_) | |_) \__ \ |_ | | |_|\___/|_.__/|___/\__||_|f
Et les précieux ebooks d’anarchistes, téléchargés gratuitement depuis le darknet, directement sauvegardé sur votre ordinateur:
Guide Complet
Le guide va se décomposer en 3 parties.
- se connecter aux proxies Tor avec requests et Python
- naviguer sur le site
- télécharger les pdfs
Tor Proxies
D’abord, connectons-nous aux proxies de Tor avec Python3 et requests, comme suit:
session = requests.session() session.proxies = {'http': 'socks5h://localhost:9050', 'https': 'socks5h://localhost:9050'}f
tor_ip = session.get("https://api.ipify.org/").text local_ip = requests.get("https://api.ipify.org/").text print(tor_ip) print(local_ip)f
Et le résultat est clair:
$ python3 scraping-anarchists-library-darknet-requests-tor-tutorial.py 5.45.106.207 80.125.29.188f
2 IPs différentes — nous sommes bien connectés aux proxies de Tor!
Maintenant essayons de nous connecter au site:
response = session.get(latest_books_library_onion_link, timeout=100) print(response.status_code)f
Et ici encore, en lançant le script, le message est clair:
$ python3 scraping-anarchists-library-darknet-requests-tor-tutorial.py 200f
Plus de page inaccessible. Nous accèdons positivement à ce site présent sur le darknet de façon programmatique, avec requests et Python.
🐍
Page de résultats
Maintenant, nous allons naviguer sur le site.
Une fois que vous êtes sur le site, ouvrez votre console d’inspection, avec clique droit + Inspect, puis sélectionnez la partie Network.
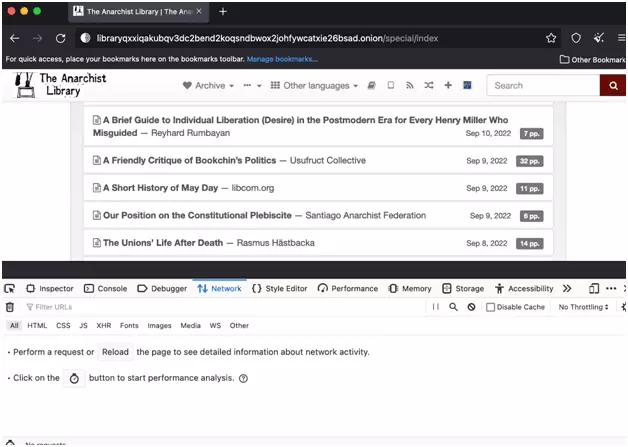
Appuyez ensuite sur l’icône de recherche (1) ci-dessous, ce qui va ouvrir l’outil de recherche de requêtes:
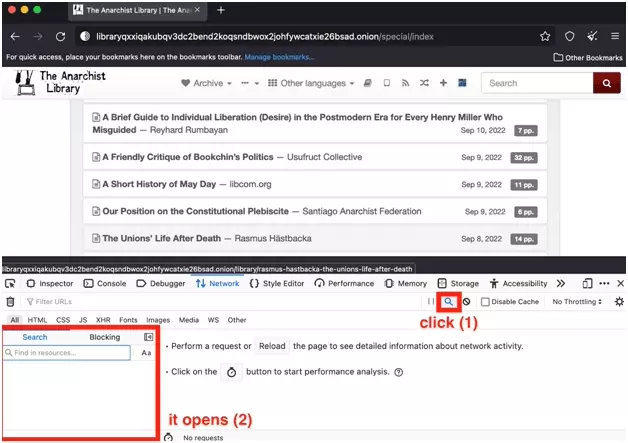
Rechargez la page, et dans l’outil de recherche, sélectionnez un des mots présents sur la page, ici “A short history of May Day”:
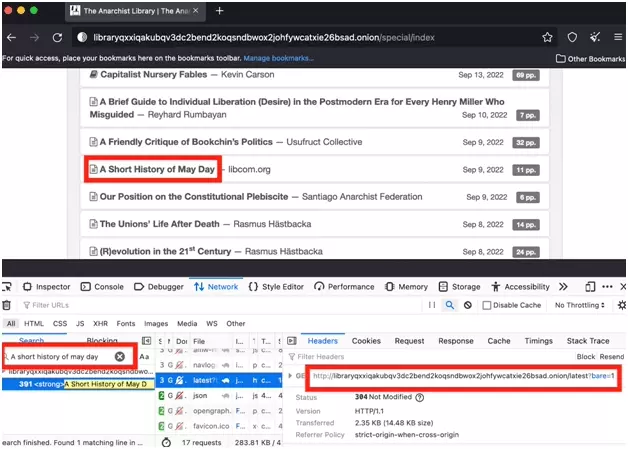
Une requête apparaît! C’est l’URL de cette requête que nous allons récupérer, et insérer directement dans notre code en Python:
response = session.get("http://libraryqxxiqakubqv3dc2bend2koqsndbwox2johfywcatxie26bsad.onion/latest?bare=1", timeout=100)f
Maintenant, nous allons récupérer l’URL de chacune des pages de chaque ouvrage.
En ouvrant la partie Inspector de l’outil d’inspection, on se rend compte que chaque page d’ouvrage est située dans une div qui a pour classe 'amw-listing-item':
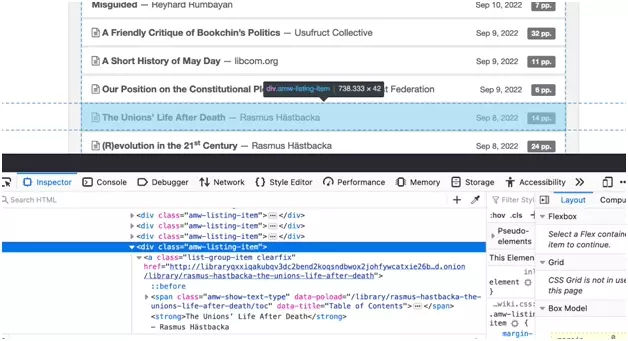
Voilà le code:
response = session.get("http://libraryqxxiqakubqv3dc2bend2koqsndbwox2johfywcatxie26bsad.onion/latest?bare=1", timeout=100) doc = html.fromstring(response.text) items = doc.xpath('//div[@class="list-group"]//div[@class="amw-listing-item"]') for i, item in enumerate(items[:10]): link = "".join(item.xpath('./a/@href')) print(link)f
Et lorsqu’on le lance depuis la ligne de commande, les liens apparaissent distinctement:
$ python3 scraping-anarchists-library-darknet-requests-tor-tutorial.py http://libraryqxxiqakubqv3dc2bend2koqsndbwox2johfywcatxie26bsad.onion/library/kevin-carson-may-day http://libraryqxxiqakubqv3dc2bend2koqsndbwox2johfywcatxie26bsad.onion/library/theodoros-karyotis-ioanna-maria-maravelidi-yavor-tarinski-asking-questions-with-the-zapatistas http://libraryqxxiqakubqv3dc2bend2koqsndbwox2johfywcatxie26bsad.onion/library/rasmus-hastbacka-six-myths-about-union-action http://libraryqxxiqakubqv3dc2bend2koqsndbwox2johfywcatxie26bsad.onion/library/asbo-bang-up-and-smash-2nd-edition http://libraryqxxiqakubqv3dc2bend2koqsndbwox2johfywcatxie26bsad.onion/library/bob-black-fijaf
Magnifique!
Ne nous reste plus qu’à:
- nous rendre sur la page de chaque ouvrage
- télécharger le livre au format .pdf
Page d’ouvrage
D’abord, on se rend sur la page d’ouvrage avec requests:
response = session.get(link)f
Puis depuis le TorBrowser, une fois sur la page d’ouvrage, inspecte la zone avec le lien vers le pdf:
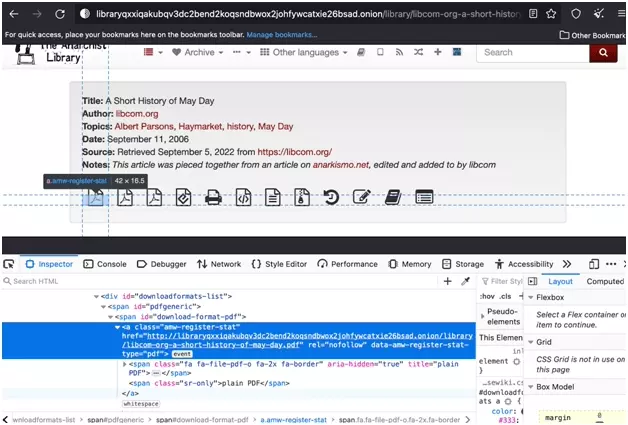
'//span[@id="download-format-pdf"]/a/@href'f
pdf_link = "".join(item_page_doc.xpath('//span[@id="download-format-pdf"]/a/@href')) assert pdf_link pdf_name = pdf_link.split('/')[-1] pdf_response = session.get(pdf_link, stream=True) with open(pdf_name, 'wb') as fd: for chunk in pdf_response.iter_content(2000): fd.write(chunk)f
Et voilà, le tour est joué!
Bénéfices
Limitations
Pour accéder à d’autres sources de données, il va falloir modifier le script conjointement.
Attention, enfin, ce tutoriel est à usage purement éducatif.
Nous nous dégageons donc de toute responsabilité quant à l’usage immodéré qui pourrait en être fait, notamment sur des sites liés à d’autres types de services ou d’autres types de données. Par ailleurs, nous souhaitons vous rappeler que, selon la législation du pays dans lequel vous opérez, il est strictement interdit de posséder des textes protégés par le droit d’auteur, sans offrir la rémunération juste qui en revient à l’auteur. Aussi, nous vous recommandons fortement de consulter les législations en vigueur dans votre pays d’exercice avant de vous engager dans une quelconque démarche de développement informatique comme illustré ci-avant.
Conclusion
Et c’est la fin du tutoriel!
Happy scraping!
🦀
 Sasha Bouloudnine
Sasha Bouloudnine Co-founder @ lobstr.io depuis 2019. Fou de la data et amoureux zélé du lowercase. Je veille à ce que vous ayez toujours la donnée que vous voulez.