
Comment scraper Doctolib avec Python et requests en 2023?
Doctolib c’est vraiment un site merveilleux: on peut accéder au calendrier de plus de 215 000 médecins de toutes les spécialités, partout en France, et réserver, en quelques clics, son créneau du bout des doigts.

On est prévenus. Et il récupère 8 likes.
Alors, qu’est-ce qui rend le scraping de doctolib si compliqué — est-ce même possible? Spoiler alert: oui.
🦀
Dans ce tutoriel, on va donc voir comment scraper toutes les données de médecins sur doctolib, quelle que soit la profession, avec python3 et requests.
Nerds, développeurs de santé, passionnés de médecine, ou chasseurs de docteur de France et de navarre, cet article est fait pour vous.
Pré-requis
Avant de se lancer dans le grand bain, voilà les 5 éléments que l’on va installer:
curl-impersonate est ce que l’on va installer après: un outil qui permet de réaliser des requêtes vers le site client, en utilisant exactement la même version du HTTP handshake que votre navigateur Chrome.
Si le HTTP handshake est un peu flou pour vous pour le moment: pas de frayeur, on va aborder ça en détails au cours du tutoriel.
Si vous utilisez Mac OS, il faut réaliser les étapes comme suit.
Installer ces même dépendances:
$ brew install pkg-config make cmake ninja autoconf automake libtool # For the Firefox version only $ brew install sqlite nss $ pip3 install gyp-next # For the Chrome version only $ brew install gof
$ git clone https://github.com/lwthiker/curl-impersonate.git $ cd curl-impersonatef
Et enfin compiler l’ensemble:
$ mkdir build && cd build ../configure # Build and install the Firefox version $ gmake firefox-build $ sudo gmake firefox-install # Build and install the Chrome version $ gmake chrome-build $ sudo gmake chrome-install # Optionally remove all the build files $ cd ../ && rm -Rf buildf
Au niveau des librairies Python, on va installer 3 librairies supplémentaires.
D’abord, requests, la librairie externe Python la plus téléchargée au monde, qu’on ne présente plus, qui permet tout simplement de naviguer sur internet avec un script python.
On va ensuite utiliser installer le module, qui va nous permettre d’utiliser ce fameux cURL impersonate, directement avec Python: il s’agit de curl_cffi.
Enfin, on va installer lxml, une librairie allemande (uh) qui permet de convertir du texte en un document HTML structuré, et de faciliter ainsi la récupération d’éléments depuis la page HTML.
$ pip3 install --upgrade requests curl_cffi lxmlf
Et voilà, on est fin prêts. Let’s go!
Code complet
from curl_cffi import requests from lxml import html import json import csv import time import argparse HEADERS = { 'authority': 'www.doctolib.fr', 'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7', 'accept-language': 'fr-FR,fr;q=0.9', 'sec-ch-ua': '"Not.A/Brand";v="8", "Chromium";v="114", "Google Chrome";v="114"', 'sec-ch-ua-mobile': '?0', 'sec-ch-ua-platform': '"macOS"', 'sec-fetch-dest': 'document', 'sec-fetch-mode': 'navigate', 'sec-fetch-site': 'none', 'sec-fetch-user': '?1', 'upgrade-insecure-requests': '1', 'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36', } FIELDNAMES = [ 'type', 'name', 'specialty', 'url', 'address_name', 'address_street', 'address_postal_code', 'address_locality', 'payment_accepted' ] DATA = [] class DoctolibScraper: def __init__(self): self.s = requests.Session(impersonate="chrome101") self.s.headers = HEADERS def iter_doctors(self, url, max_page): assert all([url, max_page]) for i in range(1, max_page+1): u = url + '?page=%s' % i print('going page %s' % i) time.sleep(1) response = self.s.get(u) assert response.status_code == 200 doc = html.fromstring(response.text) raw_json_data = doc.xpath("//script[@type='application/ld+json' and contains(text(), 'medicalSpecialty')]") if not raw_json_data: print('no more data') break assert raw_json_data and len(raw_json_data) == 1 raw_json_data = json.loads(raw_json_data[0].text) assert isinstance(raw_json_data, list) doctors = raw_json_data for doctor in doctors: d = {} d['type'] = doctor['@type'] d['name'] = doctor['name'] d['specialty'] = doctor['medicalSpecialty'] d['url'] = 'https://www.doctolib.fr/'+doctor['url'] _address = doctor['address'] d['address_name'] = _address['name'] d['address_street'] = _address['streetAddress'] d['address_postal_code'] = _address['postalCode'] d['address_locality'] = _address['addressLocality'] d['payment_accepted'] = doctor['paymentAccepted'] print('scraped: %s' % d['name']) DATA.append(d) return DATA def write_csv(self, data): filename = 'data_scraping_doctolib_lobstr_io.csv' assert data and isinstance(data, list) assert filename with open(filename, 'w') as f: writer = csv.DictWriter(f, fieldnames=FIELDNAMES) writer.writeheader() for d in DATA: writer.writerow(d) print('write csv: complete') if __name__ == '__main__': s = time.perf_counter() d = DoctolibScraper() argparser = argparse.ArgumentParser() argparser.add_argument('--search-url', '-u', type=str, required=False, help='doctolib search url', default='https://www.doctolib.fr/radiologue/lyon') argparser.add_argument('--max-page', '-p', type=int, required=False, help='max page to visit', default=2) args = argparser.parse_args() search_url = args.search_url max_page = args.max_page assert all([search_url, max_page]) data = d.iter_doctors(search_url, max_page) d.write_csv(data) elapsed = time.perf_counter() - s elapsed_formatted = "{:.2f}".format(elapsed) print("elapsed:", elapsed_formatted, "s") print('''~~ success _ _ _ | | | | | | | | ___ | |__ ___| |_ __ __ | |/ _ \| '_ \/ __| __/| '__| | | (_) | |_) \__ \ |_ | | |_|\___/|_.__/|___/\__||_| ''')f
Vous allez pouvoir télécharger le fichier, et le lancer depuis la ligne de commande, en précisant 2 paramètres:
- u — l’URL de recherche Doctolib, par defaut https://www.doctolib.fr/radiologue/lyon
- p — la page maximale à laquelle vous souhaitez aller, par defaut 3
Et ce qui nous donne :
$ python3 doctolib_scraper_072023 -u https://www.doctolib.fr/pneumologue/reims -p 2 going page 1 scraped: Juliette VELLA-BOUCAUD scraped: Bruno Picavet scraped: Dragisa MILOSEVIC scraped: Julie Nardi scraped: Véronique Garcia scraped: Pierre BERTRAND scraped: Dragisa MILOSEVIC scraped: Bruno Picavet scraped: Juliette VELLA-BOUCAUD scraped: Centre Hospitalier de Laon scraped: Véronique Garcia scraped: Bruno Picavet scraped: Dragisa MILOSEVIC scraped: Francois Lebargy scraped: Anne Sophie Angelier scraped: Bertrand Guy going page 2 no more data write csv: complete elapsed: 2.92 s ~~ success _ _ _ | | | | | | | | ___ | |__ ___| |_ __ __ | |/ _ \| '_ \/ __| __/| '__| | | (_) | |_) \__ \ |_ | | |_|\___/|_.__/|___/\__||_|f
Chirurgical.
👨⚕️
Tutoriel étape par étape
Dans ce tutoriel, on va voir comment scraper tous les médecins depuis n’importe quelle URL de recherche Doctolib, et jusqu’à la page qui nous chante.
Et parce qu’on est des nerds, on va commencer par scraper les plus nerds des médecins: les radiologues, à Lyon. Après tout pourquoi pas.
Et on va récupérer 9 attributs distincts:
- type
- name
- specialty
- url
- address_name
- address_street
- address_postal_code
- address_locality
- payment_accepted
Et comme illustré ci-dessous:
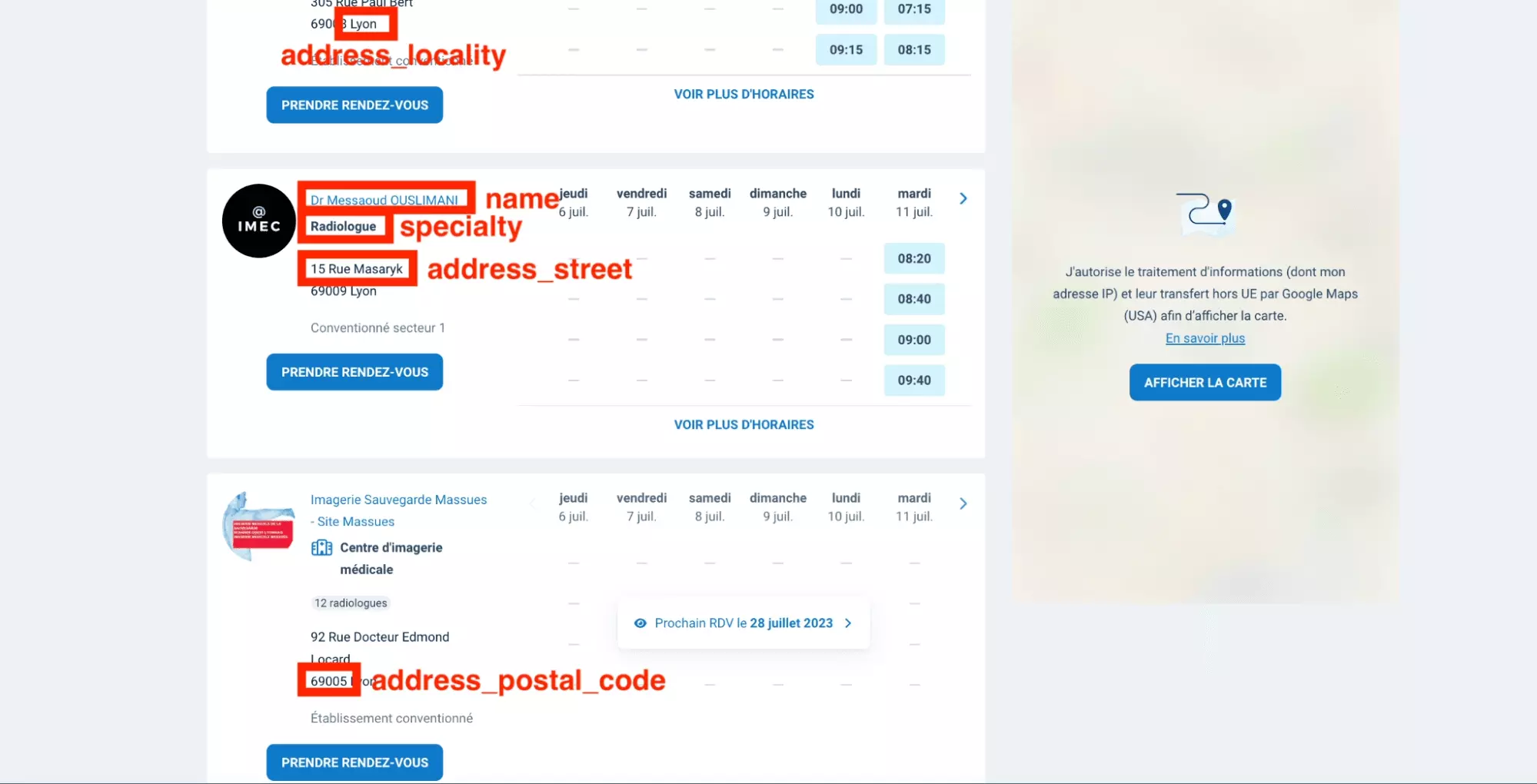
L’URL du docteur, et les paiements acceptés ne sont pas présents sur cet imprimé écran, mais on va les retrouver lors de la récupération d’informations depuis le code source de la page.
Et ce tutoriel va se passer en 6 étapes distincts:
- Identification de la requête cURL principale
- Résolution du Retry Later challenge
- Parsing des données
- Navigation d’une page à l’autre
- Ajout des variables dynamiques
- Sauvegarde des données au format .csv
En route.
1. Identification de la requête cURL principale
Ensuite, on ouvre l’onglet Network, qui va simplement nous permettre d’observer les requêtes, toutes les requêtes, qui sont échangées entre le site cible et notre navigateur.
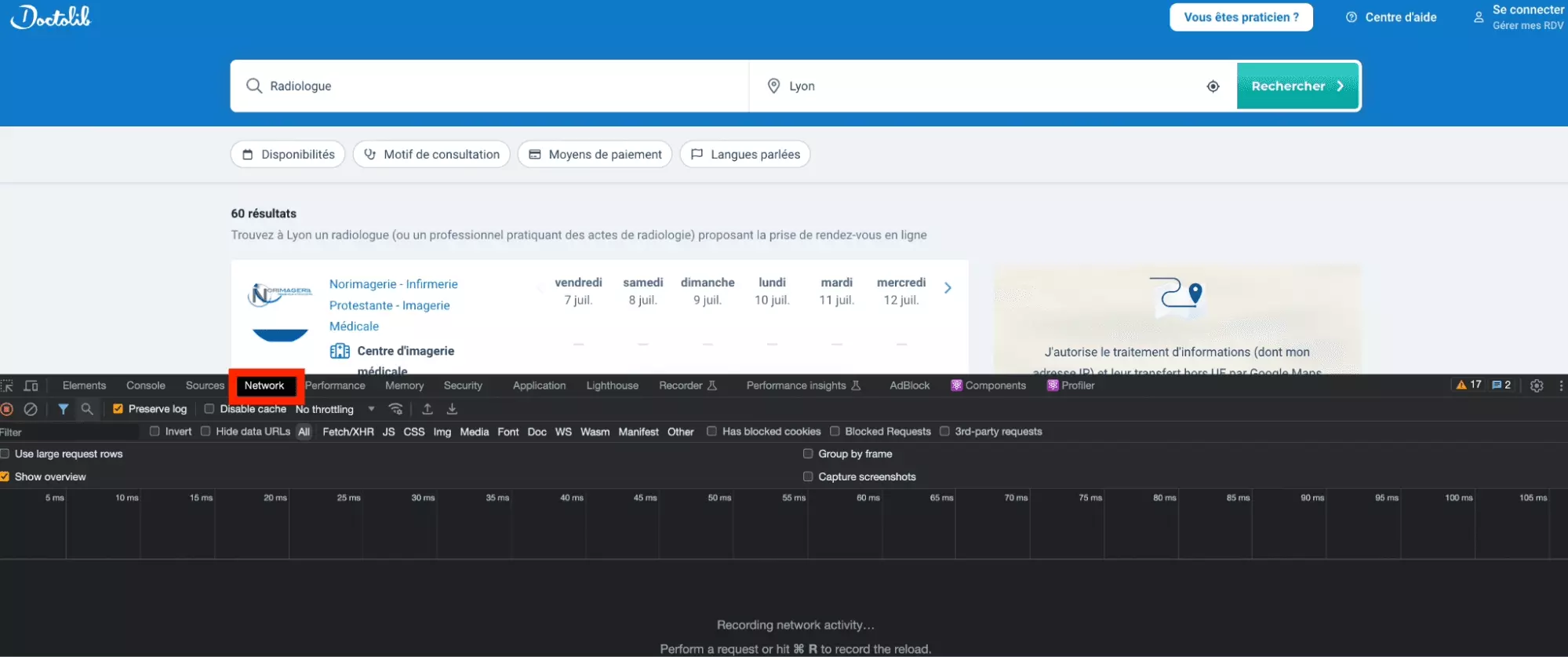
Enfin, on rafraîchit la page, pour que des requêtes soient à nouveau échangées entre le site cible et notre navigateur, et que toutes ces requêtes soient enregistrées.
OKK toutes les requêtes ont été proprement enregistrées!
Mais comment trouver la requête qui contient les données que l’on souhaite récupérer?
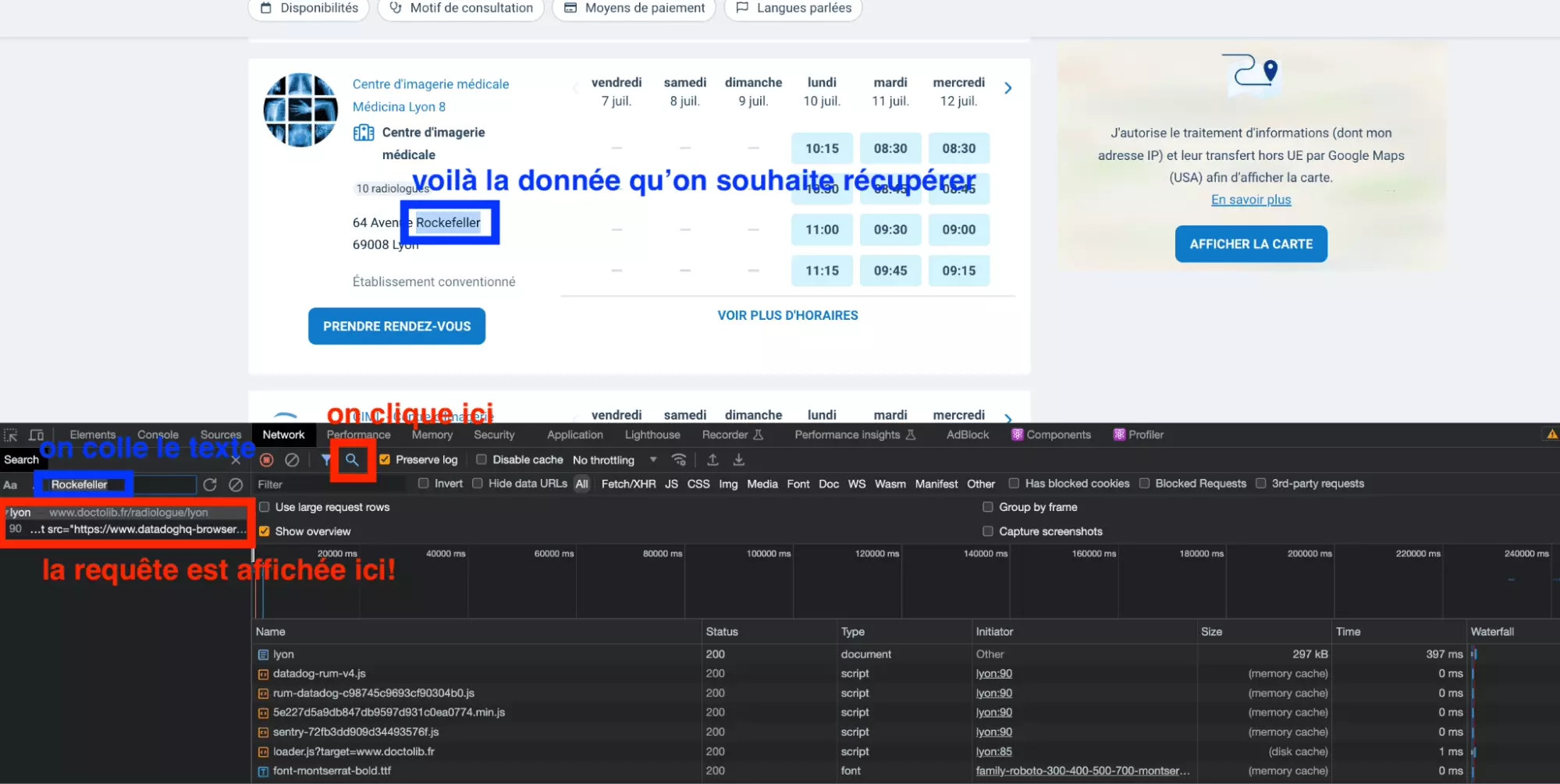
Et bien c’est très simple, on va utiliser l’outil de recherche de l’onglet Network, qui permet de chercher un élément de texte parmi toutes les requêtes enregistrées. Ici, on va chercher le texte Rockfeller.
C’est à dire qu’on va essayer d’identifier la requête échangée entre le navigateur et le site-cible qui a permis de récupérer la chaîne de caractère Rockfeller.
On procède donc comme suit:
- on clique sur l’icône de recherche pour ouvrir l’outil de recherche de l’onglet Network
- on copie la chaîne de caractères Rockfeller
- on la colle au niveau du champ de recherche
- on appuie sur entrée
Et top, la requête apparaît!
Et maintenant, comment réaliser cette requête avec un script Python?
Et bien c’est très simple, on va récupérer la valeur de la requête au format cURL, et ensuite la convertir au format Python.
Pour récupérer la requête cURL, on double clique sur notre requête au niveau de l’espace de recherche, puis une fois identifiée la requête dans la fenêtre de droite, on fait: Clique droit > Copy as cURL.
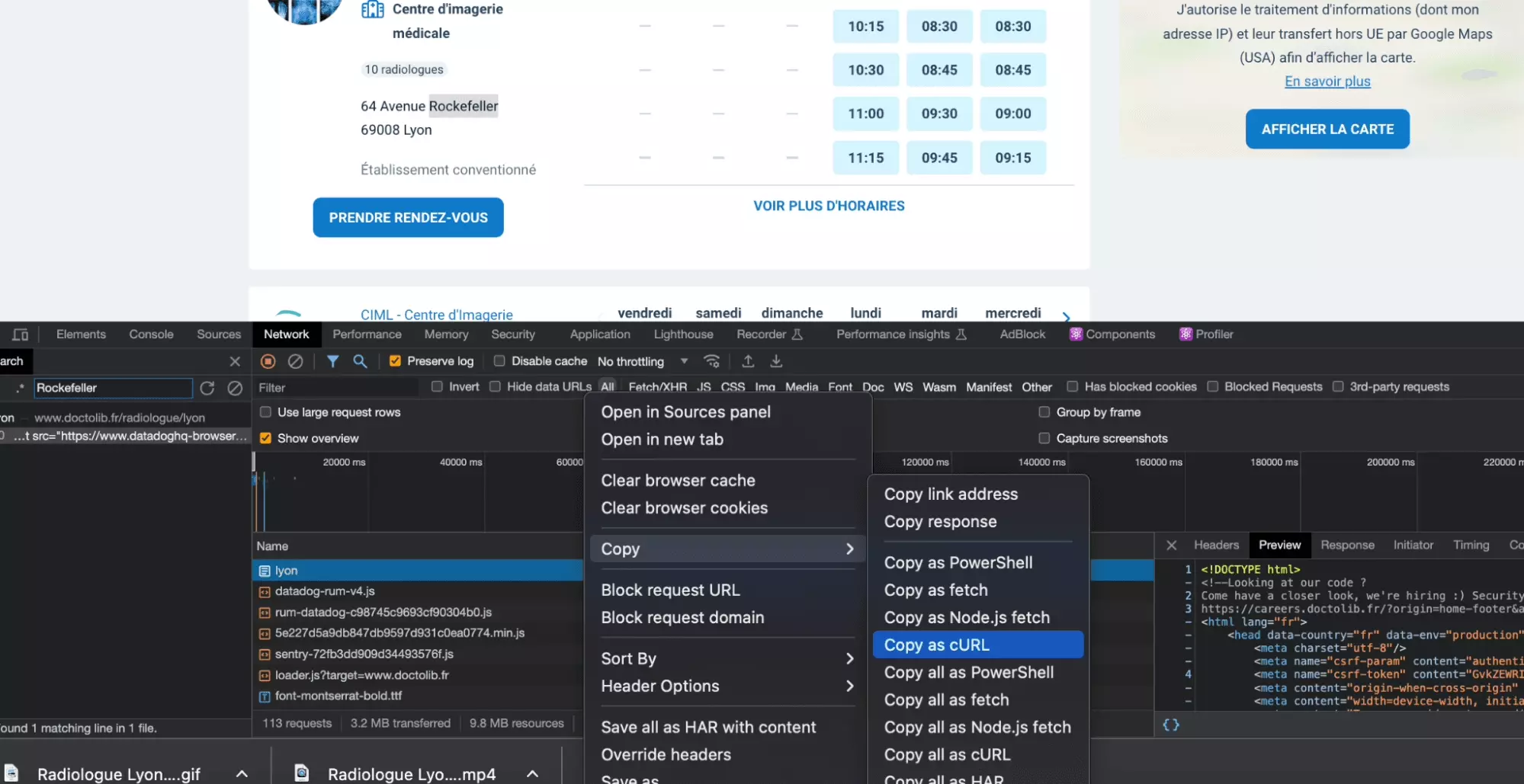
Voilà le cURL tant espéré!
curl 'https://www.doctolib.fr/radiologue/lyon' \ -H 'authority: www.doctolib.fr' \ -H 'accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7' \ -H 'accept-language: fr-FR,fr;q=0.9,en-US;q=0.8,en;q=0.7' \ -H 'cache-control: max-age=0' \ -H 'if-none-match: W/"363291d1faae7973b0c8b7aa7aa0856a"' \ -H 'sec-ch-ua: "Not.A/Brand";v="8", "Chromium";v="114", "Google Chrome";v="114"' \ -H 'sec-ch-ua-mobile: ?0' \ -H 'sec-ch-ua-platform: "macOS"' \ -H 'sec-fetch-dest: document' \ -H 'sec-fetch-mode: navigate' \ -H 'sec-fetch-site: same-origin' \ -H 'sec-fetch-user: ?1' \ -H 'upgrade-insecure-requests: 1' \ -H 'user-agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36' \ --compressedf
Pour faciliter la lisibilité, on a simplement enlever les cookies, qui n’ont pas grand intérêt ici.
Il suffit de:
- coller le curl dans le champ du dessus
- cliquer sur copy to clipboard
Et voilà, on a un code Python propre et directement exploitable.
On va simplement ajouter imprimer à la fin le contenu de la réponse:
import requests headers = { 'authority': 'www.doctolib.fr', 'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7', 'accept-language': 'fr-FR,fr;q=0.9,en-US;q=0.8,en;q=0.7', 'cache-control': 'max-age=0', 'if-none-match': 'W/"363291d1faae7973b0c8b7aa7aa0856a"', 'sec-ch-ua': '"Not.A/Brand";v="8", "Chromium";v="114", "Google Chrome";v="114"', 'sec-ch-ua-mobile': '?0', 'sec-ch-ua-platform': '"macOS"', 'sec-fetch-dest': 'document', 'sec-fetch-mode': 'navigate', 'sec-fetch-site': 'same-origin', 'sec-fetch-user': '?1', 'upgrade-insecure-requests': '1', 'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36', } response = requests.get('https://www.doctolib.fr/radiologue/lyon', headers=headers) print(response.text)f
Et là… Terrible, on se prend un villain stop. Retry Later. Essayez plus tard.
Et puis c’est tout.
% python3 doctolib_scraper_072023.py Retry laterf
Comment contourner cette limite?
2. Résolution du Retry Later challenge
a. Identification du HTTP fingerprinting
Deux mots, secs, et intransigeants. Repassez plus tard, il n’y a rien à voir. Comment contourner ce challenge?
Comme nous utilisons plusieurs outils pour faire la requête, le problème peut venir de différents niveaux:
On l’a vu, le script avec requests ne fonctionne pas. Quid de la requête cURL?
On va donc essayer directement avec cURL. On copy as cURL comme vu précédemment, et on colle ça dans notre ligne de commande:
$ curl 'https://www.doctolib.fr/radiologue/lyon' \ -H 'authority: www.doctolib.fr' \ -H 'accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7' \ -H 'accept-language: fr-FR,fr;q=0.9,en-US;q=0.8,en;q=0.7' \ -H 'cache-control: max-age=0' \ -H 'if-none-match: W/"363291d1faae7973b0c8b7aa7aa0856a"' \ -H 'sec-ch-ua: "Not.A/Brand";v="8", "Chromium";v="114", "Google Chrome";v="114"' \ -H 'sec-ch-ua-mobile: ?0' \ -H 'sec-ch-ua-platform: "macOS"' \ -H 'sec-fetch-dest: document' \ -H 'sec-fetch-mode: navigate' \ -H 'sec-fetch-site: same-origin' \ -H 'sec-fetch-user: ?1' \ -H 'upgrade-insecure-requests: 1' \ -H 'user-agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36' \ --compressed Retry laterf
Et là: même résultat, Retry Later.
En d’autres termes:
- la requête passe depuis le navigateur
- la requête ne passe pas avec cURL
Il doit y avoir une différence de paramétrage entre la requête cURL et la requête effectuée par le navigateur.
Essayons de regarder les paramètres de la requête du navigateur plus en détail. En regardant la requête avec Firefox cette fois-ci, on remarque un élément qu’on avait négligé jusqu’ici:
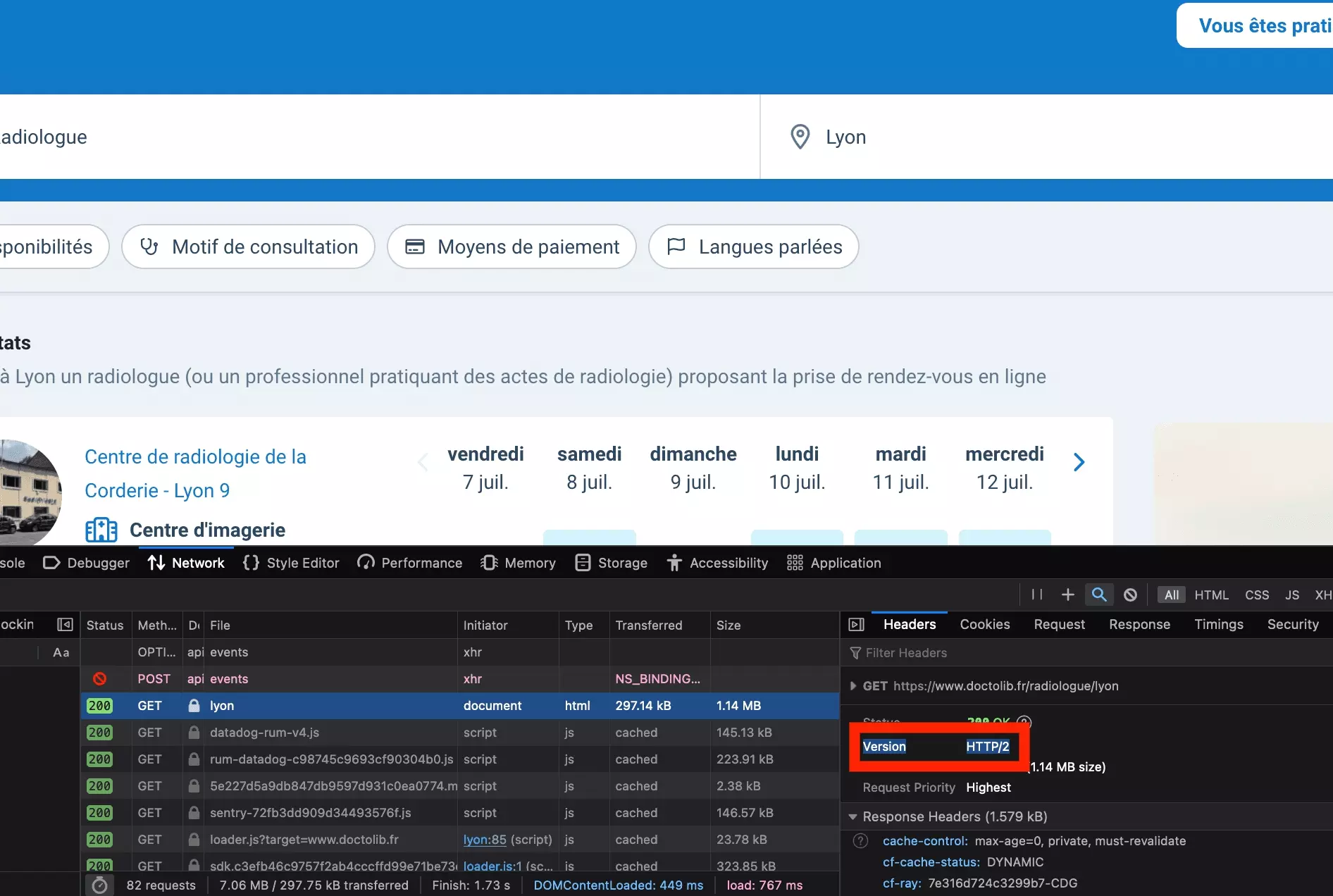
OK mais quelle est la version de notre cURL?
Après une recherche Google rapide, sauf mise à jour, par défaut la version de la requête du cURL est HTTP/1:
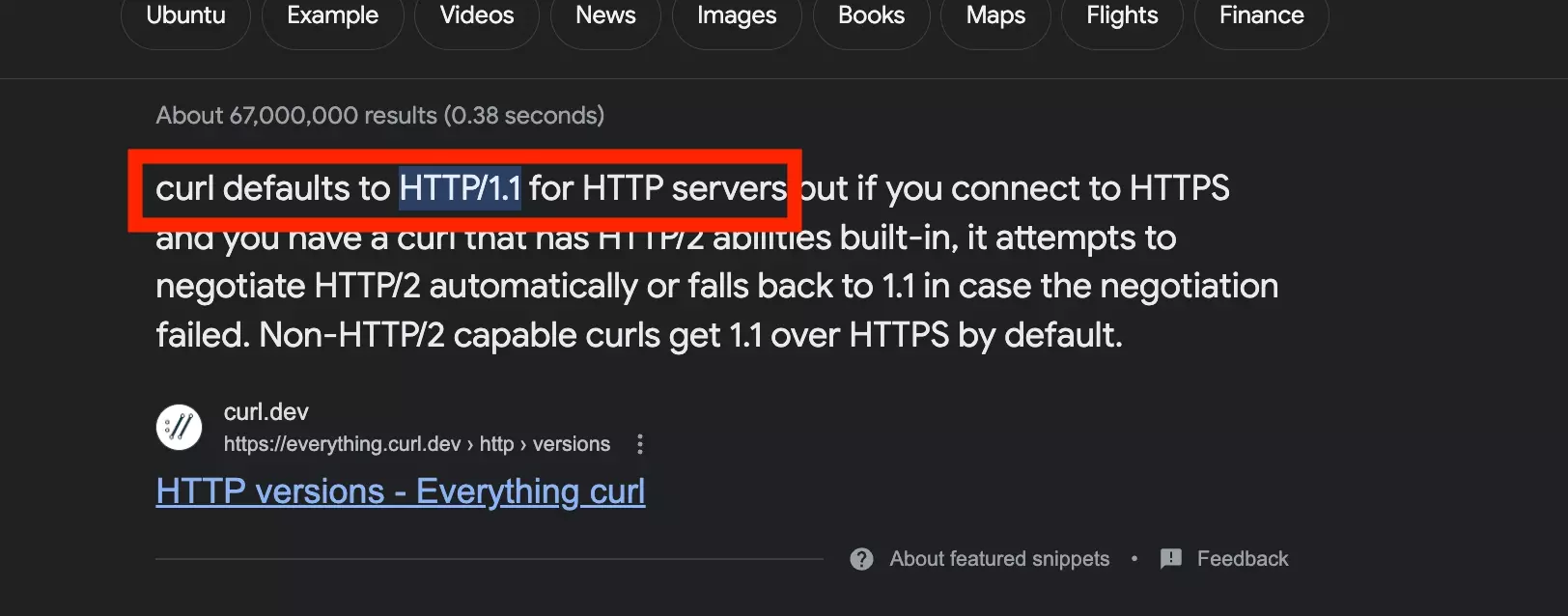
On y est!
Le site utilise en réalité ce que l’on appelle le le HTTP handshakes fingerprinting: le site observe la version HTTP utilisée pour faire la requête, et utilise cette observation pour déterminer si oui ou non la requête vient d’un navigateur traditionnel ou d’un robot.
Il s’agit de stratégie de fingerprinting traditionnelle, mais qui s’appuie sur la version du HTTP handshake pour déterminer si le trafic doit être considéré comme licite.
Mais dès lors, comment réaliser une requête, idéalement avec Python, qui utilise cette version du HTTP handshake? C’est ce qu’on va voir dans la partie suivante.
b. Installation de curl-impersonate
Et bien c’est très simple, on va installer une nouvelle version de cURL, qui a exactement les mêmes paramètres de HTTP qu’une requête venant du navigateur chrome: il s’agit de curl-impersonate.
Comme mentionné dans la partie pré-requis, si vous utilisez Mac OS, il faut réaliser les étapes comme suit.
Ensuite, il faut installer ces dépendances depuis la ligne de commande:
$ brew install pkg-config make cmake ninja autoconf automake libtool # For the Firefox version only $ brew install sqlite nss $ pip3 install gyp-next # For the Chrome version only $ brew install gof
Ensuite, cloner le repo Git publique:
$ git clone https://github.com/lwthiker/curl-impersonate.git $ cd curl-impersonatef
Et enfin, compiler l’ensemble:
$ mkdir build && cd build ../configure # Build and install the Firefox version $ gmake firefox-build $ sudo gmake firefox-install # Build and install the Chrome version $ gmake chrome-build $ sudo gmake chrome-install # Optionally remove all the build files $ cd ../ && rm -Rf buildf
Et maintenant comment réaliser un cURL avec cette version de cURL?
Et bien c’est très simple, on va réaliser la même requête, mais au lieu d’utiliser la commande curl, on va utiliser la commande curl_chrome110. Il s’agit, comme son nom l’indique d’un cURL, qui a exactement les même paramètres qu’une requête effectuée par le navigateur Chrome.
$ curl_chrome110 'https://www.doctolib.fr/radiologue/lyon' \ -H 'authority: www.doctolib.fr' \ -H 'accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7' \ -H 'accept-language: fr-FR,fr;q=0.9,en-US;q=0.8,en;q=0.7' \ -H 'cache-control: max-age=0' \ -H 'if-none-match: W/"363291d1faae7973b0c8b7aa7aa0856a"' \ -H 'sec-ch-ua: "Not.A/Brand";v="8", "Chromium";v="114", "Google Chrome";v="114"' \ -H 'sec-ch-ua-mobile: ?0' \ -H 'sec-ch-ua-platform: "macOS"' \ -H 'sec-fetch-dest: document' \ -H 'sec-fetch-mode: navigate' \ -H 'sec-fetch-site: same-origin' \ -H 'sec-fetch-user: ?1' \ -H 'upgrade-insecure-requests: 1' \ -H 'user-agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36' \ --compressedf
Et là… ça fonctionne avec succès!
On reçoit dans la console le plein de données, et parmi elle, on retrouve bien la chaîne de caractères Rockfeller:
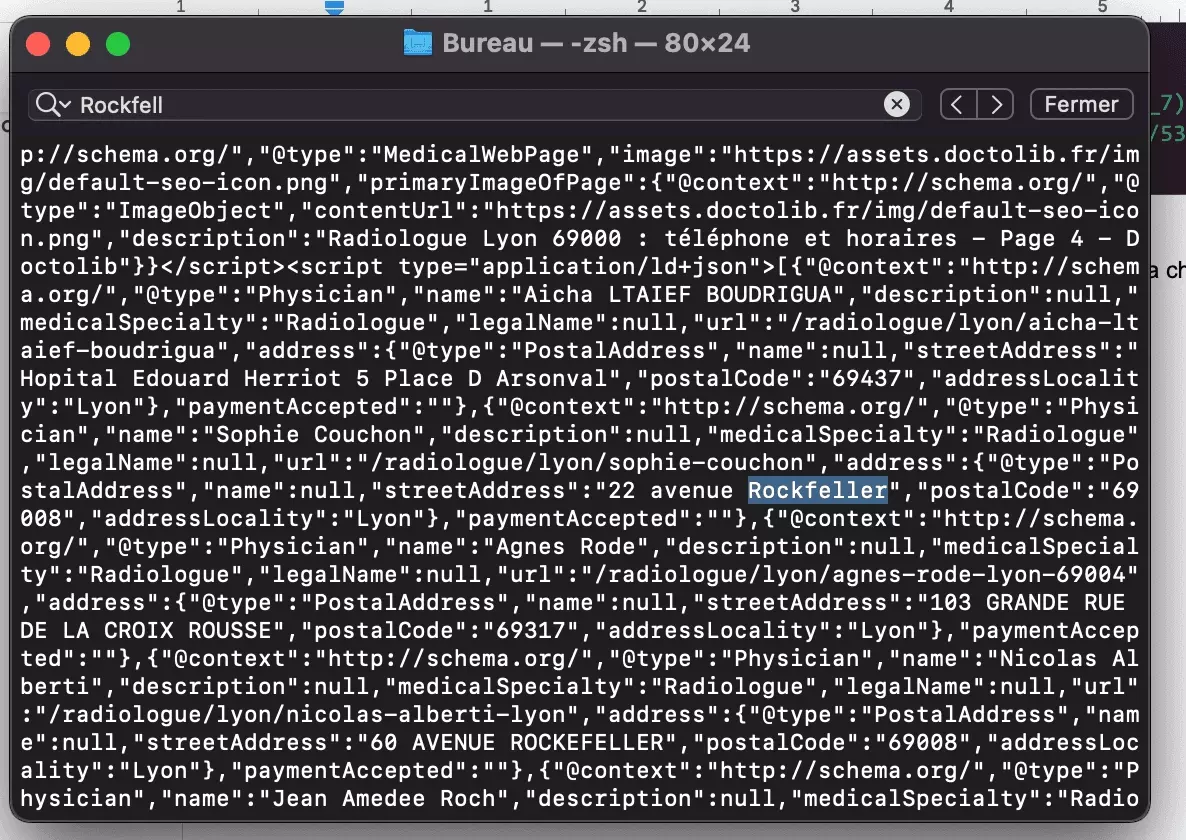
C’est réussi.
Et maintenant, comment utiliser cette requête cURL avec Python et requests? C’est ce qu’on va voir dans la partie suivante.
c. Utilisation de curl-impersonate avec Python et requests via curl_cffi
Utiliser curl-impersonate depuis la ligne de commande, c’est bien. Mais pour rappel, on souhaite utiliser cette méthode avec Python et requests.
Pour ce faire, on va télécharger curl-cffi: il s’agit, pour faire simple, d’une librairie Python qui permet d’utiliser curl-impersonate.. depuis un script Python.
Pour l’installer c’est très simple:
$ pip3 install --upgrade curl_cffif
Et ensuite, on l’importe au niveau du script Python, avant de réaliser la même requête que précédemment. Enfin, on vérifie que l’on a bien Rockfeller dans notre chaîne de caractères.
from curl_cffi import requests headers = { 'authority': 'www.doctolib.fr', 'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7', 'accept-language': 'fr-FR,fr;q=0.9,en-US;q=0.8,en;q=0.7', 'cache-control': 'max-age=0', 'if-none-match': 'W/"363291d1faae7973b0c8b7aa7aa0856a"', 'sec-ch-ua': '"Not.A/Brand";v="8", "Chromium";v="114", "Google Chrome";v="114"', 'sec-ch-ua-mobile': '?0', 'sec-ch-ua-platform': '"macOS"', 'sec-fetch-dest': 'document', 'sec-fetch-mode': 'navigate', 'sec-fetch-site': 'same-origin', 'sec-fetch-user': '?1', 'upgrade-insecure-requests': '1', 'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36', } response = requests.get('https://www.doctolib.fr/radiologue/lyon', headers=headers, impersonate="chrome101") if 'Rockefeller' in response.text: print('crab crab')f
On lance notre script et… crab crab. C’est un succès!
$ python3 doctolib_scraper_072023.py crab crabf
🦀
Le challenge a été contourné avec succès!
Il ne nous reste plus maintenant qu’à récupérer les données, et à les stocker dans un fichier .csv. Allons-y.
3. Parsing des données
Si l’on observe la donnée que l’on récupère, on se rend compte d’abord que l’ensemble des données sont stockées au format JSON, au sein d’un dictionnaire présent dans une balise script.

Avec la librairie lxml, on va donc d’abord aller dénicher ce script. On installe d’abord la librairie allemande (uh) en question:
$ pip3 install lxmlf
Avec le code comme suit:
from curl_cffi import requests from lxml import html HEADERS = { 'authority': 'www.doctolib.fr', 'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7', 'accept-language': 'fr-FR,fr;q=0.9,en-US;q=0.8,en;q=0.7', 'cache-control': 'max-age=0', 'if-none-match': 'W/"363291d1faae7973b0c8b7aa7aa0856a"', 'sec-ch-ua': '"Not.A/Brand";v="8", "Chromium";v="114", "Google Chrome";v="114"', 'sec-ch-ua-mobile': '?0', 'sec-ch-ua-platform': '"macOS"', 'sec-fetch-dest': 'document', 'sec-fetch-mode': 'navigate', 'sec-fetch-site': 'same-origin', 'sec-fetch-user': '?1', 'upgrade-insecure-requests': '1', 'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36', } DATA = [] class DoctolibScraper: def __init__(self): self.s = requests.Session(impersonate="chrome101") self.s.headers = HEADERS def iter_doctors(self): response = self.s.get('https://www.doctolib.fr/radiologue/lyon') assert response.status_code == 200 doc = html.fromstring(response.text) raw_json_data = doc.xpath("//script[@type='application/ld+json' and contains(text(), 'medicalSpecialty')]")f
On vérifie qu’il y ait bien le terme medicalSpecialty dans notre script, histoire d’éviter de récupérer le contenu d’un script qui ne nous intéresse pas.
Et ensuite à l’aide la librairie json, on va convertir ce texte en dictionnaire, et stocker chacune de nos données dans le dictionnaire qui nous est propre:
import json ... raw_json_data = json.loads(raw_json_data[0].text) assert isinstance(raw_json_data, list) doctors = raw_json_data for doctor in doctors: d = {} d['type'] = doctor['@type'] d['name'] = doctor['name'] d['specialty'] = doctor['medicalSpecialty'] d['url'] = 'https://www.doctolib.fr/'+doctor['url'] _address = doctor['address'] d['address_name'] = _address['name'] d['address_street'] = _address['streetAddress'] d['address_postal_code'] = _address['postalCode'] d['address_locality'] = _address['addressLocality'] d['payment_accepted'] = doctor['paymentAccepted'] print('scraped: %s' % d['name']) DATA.append(d) return DATAf
Et si l’on imprime le contenu d’un de nos dictionnaires?
$ python3 doctolib_parser_072023.py {'address_locality': 'Marseille', 'address_name': 'SCM Imagerie médicale du midi', 'address_postal_code': '13007', 'address_street': '7 Rampe Saint-Maurice', 'name': "Centre d'Imagerie Médicale - Dr Tenoudji & Dr Bueno", 'payment_accepted': 'Cash, Check, Credit card', 'specialty': "Centre d'imagerie médicale", 'type': 'Hospital', 'url': 'https://www.doctolib.fr//centre-d-imagerie-medicale/marseille/centre-d-imagerie-medicale-dr-tenoudji-dr-bueno'}f
Nickel chrome. Bon, on a la première page, mais comment obtenir la seconde?
4. Navigation d’une page à l’autre
Si l’on réalise la même opération d’identification de requête réalisée lors de la première partie, mais sur la seconde page on se rend compte que la requête de la seconde page est structurée comme suit:
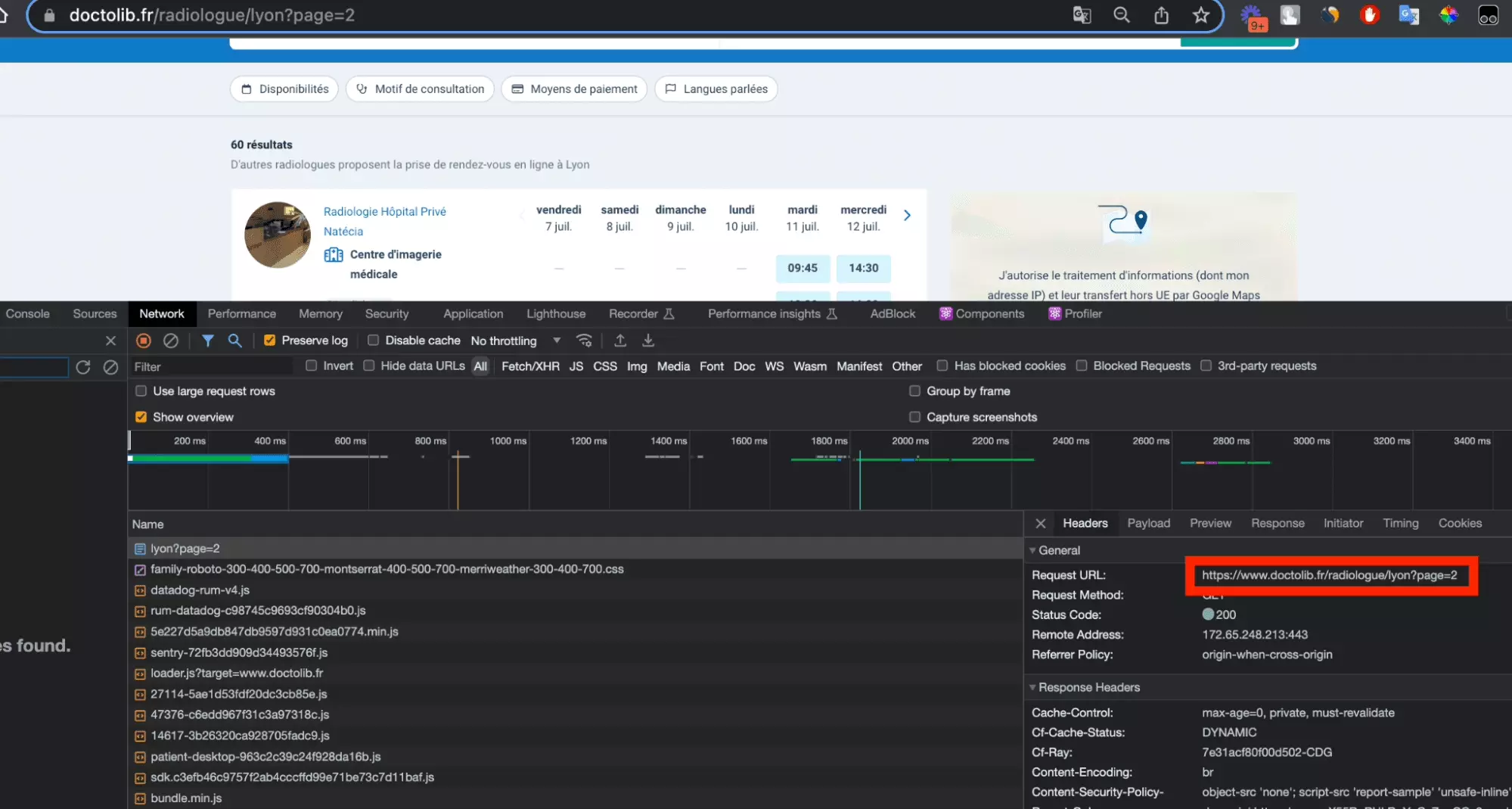
https://www.doctolib.fr/radiologue/marseille?page=2
En d’autres termes, il faut ajouter à la fin de l’URL, le paramètre ?page=$PAGE. Où $PAGE représente le numéro de la page à atteindre.
Et comme on le voit sur ce screenshot:
On va donc écrire une simple boucle for, pour naviguer progressivement d’une page à l’autre:
def iter_doctors(self): for i in range(1, 3): print('go to page %s' % i) u = 'https://www.doctolib.fr/radiologue/lyon?page=%s' % i response = self.s.get(u) assert response.status_code == 200f
Et si on lance depuis la ligne de commande:
$ python3 doctolib_scraper_072023.py go to page 1 go to page 2f
Enorme!
Bon, les radiologues, c’est bien. Mais que faire si on veut une autre profession? Et si on ne veut pas s’arrêter à la page 2?
5. Ajout des variables dynamiques
Dans cette partie, on va s’offrir un peu de flexibilité, et ajouter des variables dynamiques, afin de pouvoir préciser notre périmètre de recherche, directement depuis la ligne de commande.
Et on va ajouter 2 paramètres dynamiques
- search-url, si par exemple on souhaite scraper les pneumologues à Reims
- max-page, le nombre total de résultats que l’on souhaite récupérer
On utilise donc la librairie native de Python, argparse.
Et on ajoute ça au niveau de notre méthode principale de navigation:
import argparse if __name__ == '__main__': d = DoctolibScraper() argparser = argparse.ArgumentParser() argparser.add_argument('--search-url', '-u', type=str, required=False, help='doctolib search url', default='https://www.doctolib.fr/radiologue/marseille') argparser.add_argument('--max-page', '-p', type=int, required=False, help='max page to visit', default=2) args = argparser.parse_args() search_url = args.search_url max_page = args.max_page assert all([search_url, max_page]) data = d.iter_doctors(search_url, max_page)f
Par ailleurs, on modifie notre méthode principale pour qu’elle prenne ces deux arguments en entrée, et on forme l’URL de recherche final avec ces deux arguments:
import time ... def iter_doctors(self, url, max_page): assert all([url, max_page]) for i in range(1, max_page+1): u = url + '?page=%s' % i print('going page %s' % u) time.sleep(1) response = self.s.get(u) assert response.status_code == 200f
Et si on lance depuis la ligne de commande:
$ python3 mmm.py -u https://www.doctolib.fr/pneumologue/reims -p 3 going page https://www.doctolib.fr/pneumologue/reims?page=1 going page https://www.doctolib.fr/pneumologue/reims?page=2f
Ça fonctionne à merveille!
6. Sauvegarde des données au format .csv
Les données dans la console, c’est bien. Mais comment sauvegarder dans un format qui soit lisible et facilement exploitable?
Pour ça, c’est très simple, on va utiliser la librairie native Python csv, et notamment la méthode DictWriter, qui permet très rapidement de convertir une liste de dictionnaires en un fichier proprement structuré.
La méthode se construit comme suit:
import csv ... FIELDNAMES = [ 'type', 'name', 'specialty', 'url', 'address_name', 'address_street', 'address_postal_code', 'address_locality', 'payment_accepted' ] ... class DoctolibScraper: ... def write_csv(self, data): filename = 'data_scraping_doctolib_lobstr_io.csv' assert data and isinstance(data, list) assert filename with open(filename, 'w') as f: writer = csv.DictWriter(f, fieldnames=FIELDNAMES) writer.writeheader() for d in DATA: writer.writerow(d) print('write csv: complete')f
On lance la machine et… magnifique! Un set de données exhaustif, proprement structuré et directement exploitable.
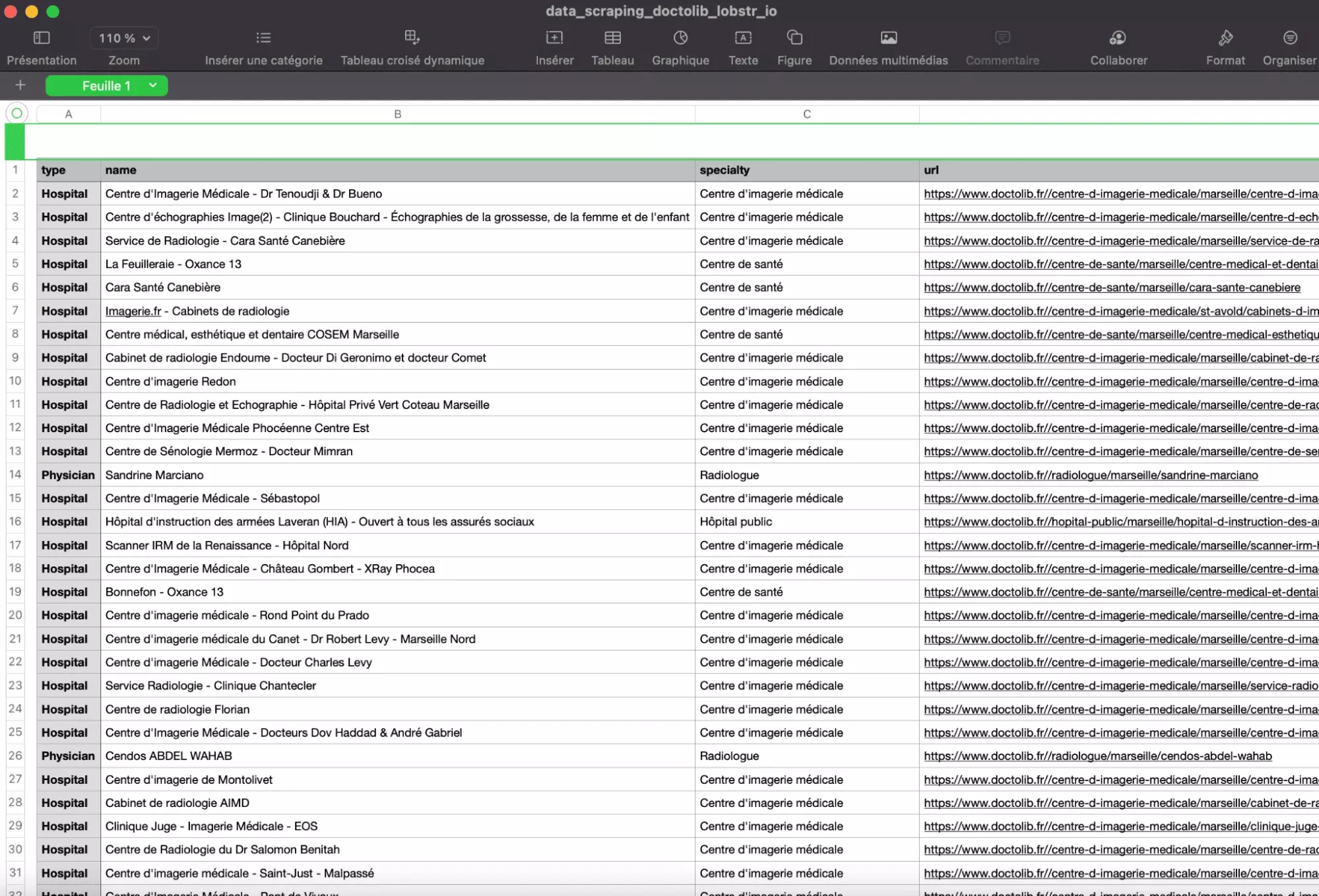
Lourd.
Limitations
Le script permet de scraper, sans aucune limitation, les données des médecins sur Doctolib, quel que soit l’URL de recherche ou la page à laquelle vous souhaitez vous rendre. Solide.
Toutefois, le script ne récupère que 9 attributs par médecin. Aucune visite sur la page du médecin n’est effectuée. Aussi, vous pouvez dire adieu au prix, aux créneaux horaires disponibles, ou au numéro de téléphone du praticien.
Par ailleurs, le script, si vous le téléchargez sur votre ordinateur et le faites tourner sur votre ordinateur, va utiliser les ressources de votre ordinateur. Autrement, cette solution n’est pas cloud-based. Si vous éteignez votre ordinateur, la collecte va s’éteindre avec lui.
FAQ
Est-ce que le scraping est légal sur Doctolib?
Contrairement à ce qu’on peut imaginer, oui c’est entièrement légal!
D’après l’article L342-3 du code de la propriété intellectuelle, si une base de données est mise à disposition du publique, celui-ci peut extraire et réutiliser les données, à condition de n’extraire qu’une partie non substantielle.
C’est donc légal, à condition de ne pas aspirer le site dans son intégralité.
Pourquoi utiliser le scraping plutôt que l’API officielle Doctolib?
L’API officielle Doctolib n’existe pas.
Est-ce que le script Python de scraping va fonctionner dans 1 mois?
Oui, on l’espère!
Sauf modification du côté du site, tout devrait parfaitement fonctionner. Si le script ne fonctionne pas, n’hésitez pas à nous contacter ici.
Pourquoi scraper de la donnée sur Doctolib?
Les cas d’usage sont multiples et diverses.
En voici quelques-uns:
- Études de marché: le scraping peut vous permettre de connaître, pour une typologie de médecins donnés, et sur une zone géographique donnée, le nombre de praticiens présents et les potentialités de “marché” possible. Jusqu’ici les médecins sont libres de s’installer où bon leur semble, ces informations peuvent avoir leur importance.
- Lead Generation: si vous avez une entreprise qui offre des services commerciaux à une population de médecins, le scraping peut vous permettre de très rapidement collecter les coordonnées des praticiens avant de les contacter. Attention dans le cadre de la RGPD, à les notifier une fois leurs coordonnées récupérées, afin de vous assurer qu’ils souhaitent bien être contactés par vos équipes.
Recherche académique: en tant que chercher vous pouvez être intéressé par le scraping sur doctolib, afin d’interroger des thématiques comme l'accessibilité des soins de santé, l'efficacité de la prise de rendez-vous en ligne, etc.
Il ne s’agit que d’une liste non exhaustive, tirée de nos expériences personnelles.
Est-ce qu’il existe un scraper Doctolib no-code?
Non, pas encore! Mais on y réfléchit.
Conclusion
Et voilà c’est terminé!
Dans ce tutoriel, on a vu comment, avec Python et requests, scraper les données de médecins sur Doctolib, depuis n’importe quel URL de recherche et jusqu’à n’importe quelle page.
C’est tout pour cette fois.
Joyeux scraping!
🦀
 Sasha Bouloudnine
Sasha Bouloudnine Co-founder @ lobstr.io depuis 2019. Fou de la data et amoureux zélé du lowercase. Je veille à ce que vous ayez toujours la donnée que vous voulez.