
Comment scraper des PDFs avec Python3 et Tika?
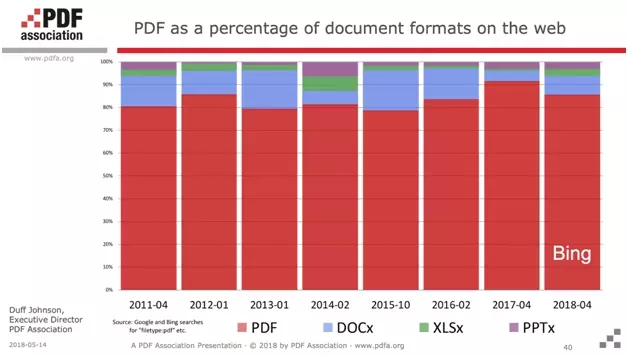
Par ailleurs, plus de 85% des documents indexés sur le net sont reconnus comme des PDFs. Le PDF règne sans partage.
Prérequis
Afin de réaliser ce tutoriel de bout en bout, soyez sur d’avoir les éléments suivants installés sur votre ordinateur.
Vous pouvez cliquer sur les liens ci-dessous, qui vous dirigeront soit vers un tutoriel d’installation, soit vers le site en question.
Pour préciser l’utilité de chacun des éléments cités ci-dessus: python3 est le langage informatique avec lequel nous allons scraper le pdf, et SublimeText est un éditeur de texte. Sublime.
À nous de jouer!
Installation
$ pip3 install tika
NB: attention, si vous travaillez sur Mac OS, n’oubliez pas d’installer le compilateur Java d’abord:
$ brew install --cask adoptopenjdk8
Et voilà, la librairie est installée!
🤖
Guide Complet
1. Téléchargement
Il suffit de se rendre sur le site, taper le nom de l’entreprise, et récupérer ce qui est appelé “l’extrait Pappers”:
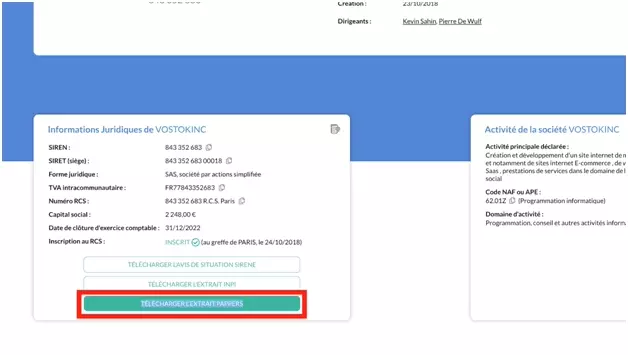
Voilà le lien des PDFs des 4 entreprises:
Avec des PDFs qui ont tous un format similaire, comme suit:

Ensuite, pensez-bien à les enregistrer dans le même dossier que celui dans lequel est enregistré votre fichier Python.
Place à la récupération des données!
2. Conversion
Dans cette seconde partie, une fois les PDFs récupérés, nous allons convertir ces documents PDFs en document texte. Ce qui va ensuite nous permettre de récupérer facilement les données.
from tika import parser
raw = parser.from_file(filename)
print(raw)
On obtient alors un dictionnaire proprement structuré — et c’est ce qui rend cette librairie particulièrement puissante! — avec l’ensemble des données du PDF au format texte, mais également des métadonnées riches en informations: statut de la conversion, date de publication, date de dernière de modification, version du PDF etc.

Et ci-après le code au format brut:
sashabouloudnine@mbp-de-sasha dev % python3
Python 3.10.6 (main, Aug 11 2022, 13:37:17) [Clang 13.0.0 (clang-1300.0.29.30)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> from tika import parser
>>> raw = parser.from_file(/Users/sashabouloudnine/Desktop/LOBSTR - Extrait d'immatriculation.pdf)
KeyboardInterrupt
>>> raw = parser.from_file("/Users/sashabouloudnine/Desktop/LOBSTR - Extrait d'immatriculation.pdf")
>>> print(raw)
{'metadata': {'Content-Type': 'application/pdf', 'Creation-Date': '2022-09-02T17:16:09Z', 'Last-Modified': '2022-09-02T17:16:09Z', 'Last-Save-Date': '2022-09-02T17:16:09Z', 'X-Parsed-By': ['org.apache.tika.parser.DefaultParser', 'org.apache.tika.parser.pdf.PDFParser'], 'X-TIKA:content_handler': 'ToTextContentHandler', 'X-TIKA:embedded_depth': '0', 'X-TIKA:parse_time_millis': '89', 'access_permission:assemble_document': 'true', 'access_permission:can_modify': 'true', 'access_permission:can_print': 'true', 'access_permission:can_print_degraded': 'true', 'access_permission:extract_content': 'true', 'access_permission:extract_for_accessibility': 'true', 'access_permission:fill_in_form': 'true', 'access_permission:modify_annotations': 'true', 'created': '2022-09-02T17:16:09Z', 'date': '2022-09-02T17:16:09Z', 'dc:format': 'application/pdf; version=1.4', 'dcterms:created': '2022-09-02T17:16:09Z', 'dcterms:modified': '2022-09-02T17:16:09Z', 'meta:creation-date': '2022-09-02T17:16:09Z', 'meta:save-date': '2022-09-02T17:16:09Z', 'modified': '2022-09-02T17:16:09Z', 'pdf:PDFVersion': '1.4', 'pdf:charsPerPage': '1603', 'pdf:docinfo:created': '2022-09-02T17:16:09Z', 'pdf:docinfo:creator_tool': 'Chromium', 'pdf:docinfo:modified': '2022-09-02T17:16:09Z', 'pdf:docinfo:producer': 'Skia/PDF m92', 'pdf:encrypted': 'false', 'pdf:hasMarkedContent': 'false', 'pdf:hasXFA': 'false', 'pdf:hasXMP': 'false', 'pdf:unmappedUnicodeCharsPerPage': '0', 'producer': 'Skia/PDF m92', 'resourceName': "bLOBSTR - Extrait d'immatriculation.pdf", 'xmp:CreatorTool': 'Chromium', 'xmpTPg:NPages': '1'}, 'content': "\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\nLOBSTR Extrait Pappers\n\nCe document reproduit les informations présentes sur le site pappers.fr et est fourni à titre informatif. 1/1\n\nN° de gestion 2019B05393\n\nExtrait Pappers du registre national du commerce et des sociétés\nà jour au 02 septembre 2022\n\nIDENTITÉ DE LA PERSONNE MORALE\n\n \n \n\n \n\n \n\n \n \n\n \n\n \n\n \n \n\n \n\n \n\nDIRIGEANTS OU ASSOCIÉS\n\n \n\n \n\n \n\n \n\n \n\n \n\n \n\n \n\nRENSEIGNEMENTS SUR L'ACTIVITÉ ET L'ÉTABLISSEMENT PRINCIPAL\n\n \n\n \n \n\n \n\n \n\nImmatriculation au RCS, numéro 841
840 499 R.C.S. Creteil\n\nDate d'immatriculation 26/08/2019\n\nTransfert du R.C.S. en date du 05/08/2019\n\nDate d'immatriculation d'origine 21/08/2018\n\nDénomination ou raison sociale LOBSTR\n\nForme juridique Société par actions simpli'ée\n\nCapital social 2,00 Euros\n\nAdresse du siège 5 Avenue du Général de Gaulle 94160 Saint-Mandé\n\nActivités principales Collecte et analyse de données à haute fréquence sur internet\n\nDurée de la personne morale Jusqu'au 26/08/2118\n\nDate de clôture de l'exercice social 31 Décembre\n\nDate de clôture du 1er exercice social 31/12/2019\n\nPrésident\n\nNom, prénoms BOULOUDNINE Sasha\n\nDate et lieu de naissance Le 04/10/1993 à Marseille (13)\n\nNationalité Française\n\nDomicile personnel 6 Avenue de Corinthe 13006 Marseille 6e Arrondissement\n\nDirecteur général\n\nNom, prénoms ROCHWERG Simon\n\nDate et lieu de naissance Le 06/12/1990 à Vincennes (94)\n\nNationalité Française\n\nDomicile personnel la Garenne Colombes 42 Rue de Plaisance 92250 La Garenne-\nColombes\n\nAdresse de l'établissement 5 Avenue du Général de Gaulle 94160 Saint-Mandé\n\nActivité(s) exercée(s) Collecte et analyse de données à haute fréquence sur internet\n\nDate de commencement d'activité 24/07/2018\n\nOrigine du fonds ou de l'activité Création\n\nMode d'exploitation Exploitation directe\n\n\n", 'status': 200}
Maintenant que ces données sont présentes au format texte, il nous reste une dernière étape: la récupération des données, et l’enregistrement dans un fichier .csv.
3. Extraction
Nous avons les données au format texte. Ce qui est nettement plus pratique que le PDF, document rigide et difficilement altérable. Maintenant, nous allons récupérer les données.
D’abord, on convertit le dictionnaire en format texte:
content = str(raw)
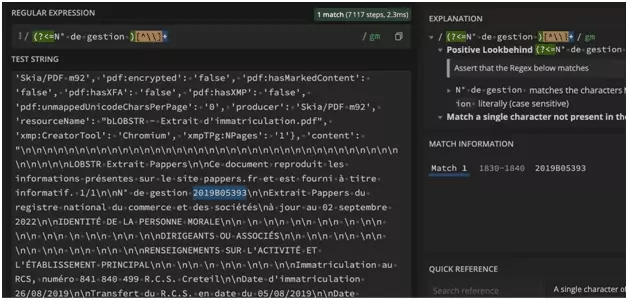
numero_gestion = "".join(re.findall(r'(?<=N° de gestion )[^\\]+', content))
a_jour_au = "".join(re.findall(r'(?<=à jour au )[^\\]+', content))
numero_rcs = "".join(re.findall(r'(?<=Immatriculation au RCS, numéro )[^\\]+', content))
date_immatriculation = "".join(re.findall(r'(?<=Date d\'immatriculation )[^\\]+', content))
raison_sociale = "".join(re.findall(r'(?<=Dénomination ou raison sociale )[^\\]+', content))
forme_juridique = "".join(re.findall(r'(?<=Forme juridique )[^\\]+', content))
capital_social = "".join(re.findall(r'(?<=Capital social )[^\\]+', content))
adresse_siege = "".join(re.findall(r'(?<=Adresse du siège )[^\\]+', content))
activites_principales = "".join(re.findall(r'(?<=Activités principales )[^\\]+', content))
Et voilà!
Nous avons récupérer 9 attributs dans chaque PDF:
- numero_gestion
- a_jour_au
- numero_rcs
- date_immatriculation
- raison_sociale
- forme_juridique
- capital_social
- adresse_siege
- activites_principales
Ne nous reste plus qu’à sauvegarder ces données dans un fichier .csv, et le tour est joué.
import csv
Puis on crée une fonction qui sauvegarde l’ensemble des données dans un fichier .csv:
def write_csv(rows):
# write csv
assert rows
with open('parsed_pdf.csv', 'w') as f:
writer = csv.DictWriter(f, fieldnames=HEADERS)
writer.writeheader()
for row in rows:
writer.writerow(row)
Et voilà, le tour est joué!
Le code
Pour exécuter le code:
- télécharger le code .py
- télécharger les 4 pdfs mentionnés dans le tutoriel
- placer le code est les pdfs dans le même dossier
- et lancer le script via la ligne de commande
Et voilà ce qui va apparaître directement sur votre terminal:
$ python3 pappers_pdf_parser_with_python_and_tika.py.py
1 LOBSTR
2 VostokInc
3 Captain Data
4 PHANTOMBUSTER
~~ success
_ _ _
| | | | | |
| | ___ | |__ ___| |_ __ __
| |/ _ \| '_ \/ __| __/| '__|
| | (_) | |_) \__ \ |_ | |
|_|\___/|_.__/|___/\__||_|
✨
Vous retrouverez, dans le même dossier que le script, un fichier au format CSV, parsed-pdf.csv, avec l’ensemble des données extraites. Les données sont proprement structurées, et directement exploitables.Voici un imprimé-écran ci-dessous:

Magnifique!
Limitations
En particulier, vous allez pouvoir transformer les PDFs des extraits d’entreprise depuis le site de référencement d’entreprise Pappers en données lisibles, structurées et exploitables.
Attention, il faut toutefois télécharger les fichiers à la main, et les placer dans le même dossier que le scraper Python. Par ailleurs, le parser ne récupère que 9 attributs — c’est déjà pas mal! certes, mais ça pourrait être mieux.
Enfin, ce scraper ne fonctionne qu’avec l’extrait d’entreprise Pappers, au format bien précis. On peut toutefois imaginer d’autres scrapers, avec d’autres formats de PDFs: extrait INPI, données financières, catalogue de vente etc.
Conclusion
Et c’est la fin du tutoriel!
Dans ce tutoriel, nous avons vu comment transformer un PDF en texte avec Python et la librairie tika, récupérer les données présentes en utilisant le regex, et insérer toutes ces données dans un fichier .csv proprement structuré et exploitable.
Happy scraping!
🦀
 Sasha Bouloudnine
Sasha Bouloudnine Co-founder @ lobstr.io depuis 2019. Fou de la data et amoureux zélé du lowercase. Je veille à ce que vous ayez toujours la donnée que vous voulez.