Comment extraire les données Leboncoin via une API? [2024]
On va écrire un petit bout de code Python pour récupérer les annonces immobilières.
import requests s = requests.Session() r = s.get('https://www.leboncoin.fr/_immobilier_/offres') with open('response.html', 'w') as f: f.write(r.text)f
Et… on est immédiatement bloqués.

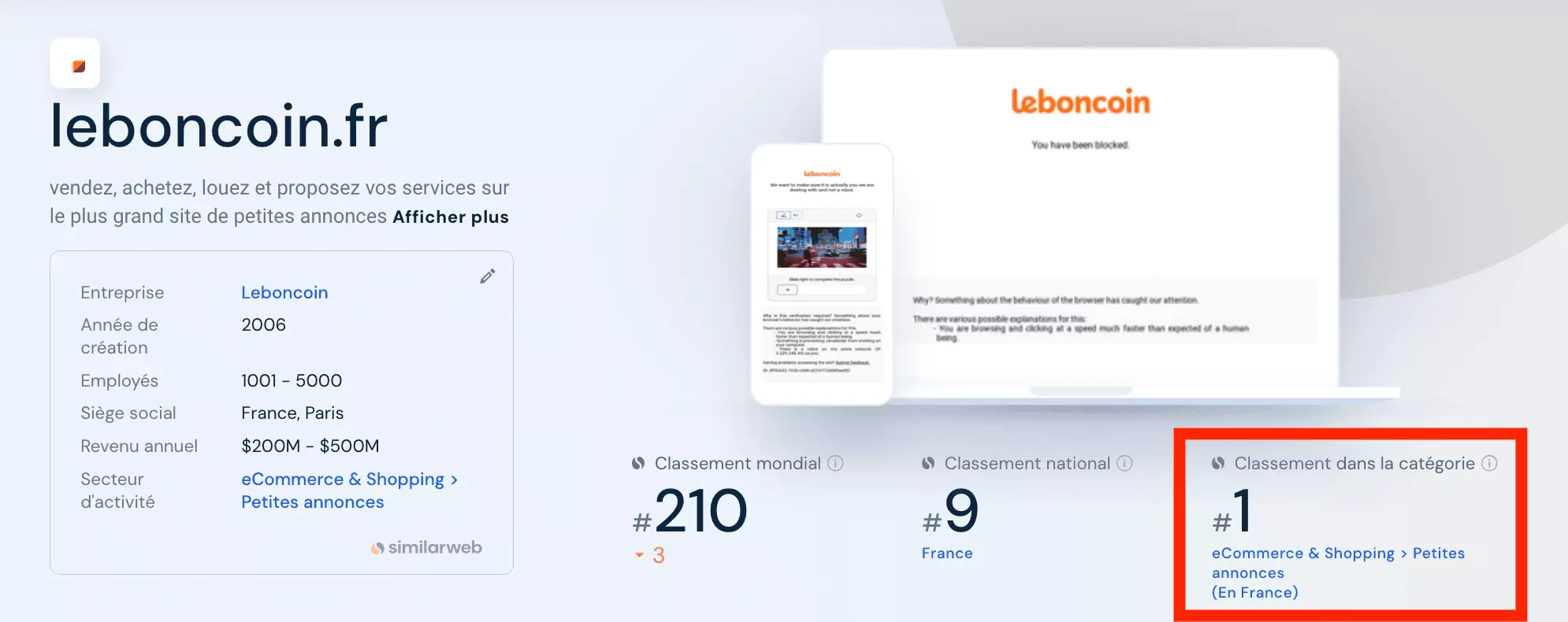
Dans cet article, on va voir comment récupérer les données du site leboncoin.fr en utilisant l'API de lobstr.io.
Des données exhaustives et rapidement accessibles, via une API fluide et documentée.
Fini les blocages intempestifs.
Features de l’API Leboncoin de lobstr.io
L’API Leboncoin de lobstr.io offre les fonctionnalitées suivantes:
- Récupérer les annonces à partir de n’importe quel URL de recherche leboncoin
- Pagination: naviguer de page en page
- Concurrency: récupérer les données avec 2 à 3 scrapers en même temps
- Navigation intelligente: arrêter la collecte une fois que vous avez récupéré un certain nombre d’annonces, atteint une certaine page, ou que les annonces récupérées sont trop vieilles
- Planificateur intégré: planifier une collecte tous les jours à la même heure
- Webhook: la collecte est terminée? Recevez une notification via webhook et récupérez vos données fraîches sans attendre
Tutoriel étape par étape pour récupérer les données Leboncoin via API
Le tutoriel est constitué de 8 étapes simples:
- Récupérer la clé d’API lobstr.io
- Récupérer un URL de recherche Leboncoin
- Créer un cluster
- Ajouter une tâche
- Spécifier les paramètres du scraper
- Lancer le run
- Vérifier l’état du run
- Récupérer les données
Allons-y.
1. Récupérer la clé d’API lobstr.io
D’abord, comme pour tout service-tiers, on va récupérer la clé d’API lobstr.io.
Commencez par vous inscrire gratuitement sur lobstr.io. Pour ce faire:
- Rendez-vous sur la page de Sign Up de lobstr.io.
- Remplissez votre email et votre futur mot de passe.
- Cliquez sur "Create an account".
- Rendez-vous dans votre boîte mail et cliquez sur "Verify Email".

Ça y est, vous êtes inscrit, bienvenue!
Ensuite, allez récupérer votre clé d’API.
- Rendez-vous dans la partie profil du dashboard en cliquant ici.
- Cliquez sur "API key details".
- Cliquez sur l’icône "Copier".
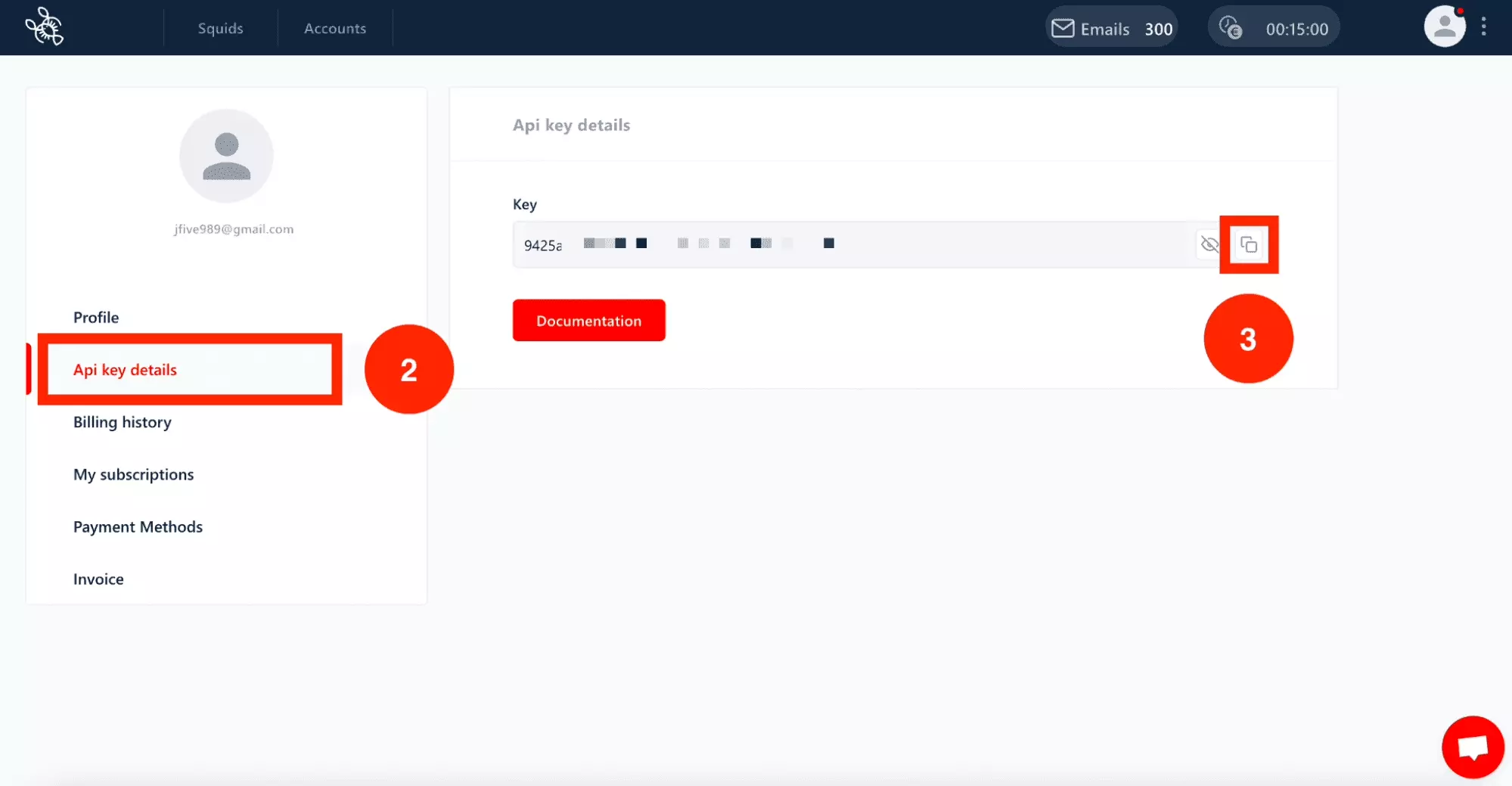
Et voilà, vous avez désormais votre clé d’API sous la main!
La clé d’API lobstr.io ressemble à ça:
9425a66eba999yh87d4b20078bob905r888o8dfv
Gardez la précieusement, on va en avoir besoin dans les étapes suivantes.
2. Récupérer un URL de recherche Leboncoin
Ensuite, on va aller récupérer un URL de recherche Leboncoin.
Qu’est-ce c’est?
Il s’agit de l’URL qui est généré par Leboncoin, après que vous avez réalisé une recherche complète sur le site. Cet URL contient tous les critères de recherche appliqués.
Dans le cadre de ce tutoriel, et puisque c’est l’été, on va aller chercher toutes les villas en vente, dans la région de Cassis.
On va donc sélectionner les critères suivants:
- Type de bien: Maison
- Type d’annonces: Offres
- Tri: Plus récentes
- Localisation: Cassis (13260) - 1 km
- Prix: Mini. 1000000 €
- Mot clé: "piscine"
Une fois tous les filtres sélectionnés, récupérer l’URL présent dans le navigateur.

Il ressemble à ça, et donne accès à 11 superbes villas de luxe.
https://www.leboncoin.fr/recherche?category=9&text=%22piscine%22&locations=Cassis_13260__43.21419_5.54296_4846_1000&real_estate_type=1&price=1000000-max
On va le garder pour la suite.
3. Créer un cluster Leboncoin Listings Search Export
On va maintenant créer un cluster Leboncoin.
Un cluster est une instance d’un scraper déjà développé par lobstr.io, que l’on va paramétrer pour qu’il récupère des données ou réalise une tâche en ligne.
Lequel choisir?
Voilà l’ID du scraper:
33db1ca85160105eeb84d5aa51cfad10
Et on va maintenant créer un premier cluster.
Code
curl 'https://api.lobstr.io/v1/clusters/save' \ -H 'Accept: application/json' \ -H 'Authorization: Token 9425a66eba999yh87d4b20078bob905r888o8dfv' \ --data-raw '{"crawler":"33db1ca85160105eeb84d5aa51cfad10"}'f
Réponse
{ "id": "4b1ba00657cd4e4798f49309c82fbb06", "account": [], "concurrency": 1, "crawler": "33db1ca85160105eeb84d5aa51cfad10", "created_at": "2024-05-16T23:28:10Z", "is_active": true, "name": "Leboncoin Listings Search Export (4)", "params": {}, "schedule": null, "to_complete": false }f
On retrouve dans la réponse l’ID du cluster:
4b1ba00657cd4e4798f49309c82fbb06
On va le conserver pour la suite.
4. Ajouter une tâche
Qu’est-ce que le scraper doit aller chercher?
C’est ce qu’on va préciser dans cette partie.
Une tâche est l’URL par laquelle le scraper va entrer sur le site, et commencer à récolter les données. C’est donc le point de départ, et ça définit le périmètre de la collecte.
Code
curl 'https://api.lobstr.io/v1/tasks' \ -H 'Accept: application/json' \ -H 'Authorization: Token 9425a66eba999yh87d4b20078bob905r888o8dfv' \ --data-raw '{"tasks":[{"url":"https://www.leboncoin.fr/recherche?category=9&text=%22piscine%22&locations=Cassis_13260__43.21419_5.54296_4846_1000&real_estate_type=1&price=1000000-max"}],"cluster":"4b1ba00657cd4e4798f49309c82fbb06"}'f
- url: l’URL de recherche récupéré précédemment
- cluster: l’identifiant du cluster récupéré plus haut
Réponse
{ "duplicated_count": 0, "tasks": [ { "id": "8cc2c42d68e3d34be75330ce31fe6d60", "created_at": "2024-05-16T23:45:35.902538", "is_active": true, "params": { "url": "https://www.leboncoin.fr/recherche?category=9&text=%22piscine%22&locations=Cassis_13260__43.21419_5.54296_4846_1000&real_estate_type=1&price=1000000-max" }, "object": "task" } ] }f
Une tâche bien ajoutée.
On veut maintenant que le scraper collecte les 10 premières annonces. Que faire?
5. Spécifier les paramètres du scraper
Dans l’état actuel des choses, le scraper va récupérer toutes les annonces, ce qui peut être ennuyeux si on est en temps limité.
On va paramétrer le scraper pour récupérer max. 10 annonces.
Code
curl 'https://api.lobstr.io/v1/clusters/4b1ba00657cd4e4798f49309c82fbb06' \ -H 'Accept: application/json' \ -H 'Authorization: Token 9425a66eba999yh87d4b20078bob905r888o8dfv' \ --data-raw '{"name":"Leboncoin Listings Search Export (4)","concurrency":1,"export_unique_results":true,"no_line_breaks":true,"to_complete":false,"params":{"max_date":null,"max_results":10,"max_pages":99,"hours_back":null,"online_shop":false},"accounts":null,"run_notify":"on_success"}'f
On retrouve:
- name: string, nom du scraper
- concurrency: entier, nombre de robots qui se déplacent simultanément pour aller récupérer des données, permet de multiplier la vitesse
- export_unique_results: booléen, récupère uniquement des annonces uniques
- no_line_breaks: booléen, si vrai supprime les sauts de ligne dans les descriptions
- to_complete: booléen, si vrai se met en pause une fois que les minutes journalières ont été consommées
- max_date: date, si le scraper récupère une annonce publiée auparavant, s’arrête
- max_results: entier, arrête la collecte une fois un nombre d’annonces collectées, ici 10
- max_pages: entier, le scraper s’arrête une fois les annonces de cette page récupérées, par défaut 99
- hours_back: entier, le scraper s’arrête si l’annonce récupérée a été postée avant le nombre d’heures renseigné, par exemple si 24 récupère les annonces des dernières 24h
- online_shop: booléen, si vrai récupère les infos vendeurs supplémentaires, e.g. le SIREN
- run_notify: string, 3 choix possibles, envoie un mail en cas de succès avec on_success, envoie un mail en cas d’erreur avec on_error ou n’envoie rien avec null, par défaut on_success
Réponse
{ "name": "Leboncoin Listings Search Export (4)", "no_line_breaks": true, "params": { "max_date": null, "max_results": 10, "max_pages": 99, "hours_back": null, "online_shop": false }, "to_complete": false, "accounts": null, "run_notify": "on_success", "export_unique_results": true, "id": "4b1ba00657cd4e4798f49309c82fbb06" }f
On retrouve bien tous les paramètres cités plus haut. Simple et lisible.
Le scraper est prêt!
Comment lancer la collecte?
6. Lancer le run
Notre scraper est prêt à être lancé.
Dans cette partie, on va voir comment lancer un run, c'est-à-dire une séquence pendant laquelle le scraper va réaliser toutes les tâches qui lui ont été assignées.
Code
curl 'https://api.lobstr.io/v1/runs' \ -H 'Accept: application/json' \ -H 'Authorization: Token 9425a66eba999yh87d4b20078bob905r888o8dfv' \ --data-raw '{"cluster":"4b1ba00657cd4e4798f49309c82fbb06"}'f
Réponse
{ "id": "1d66f25e6aef492e81bba0671fa77f2c", "object": "run", "cluster": "4b1ba00657cd4e4798f49309c82fbb06", "is_done": false, "started_at": "2024-05-17T00:22:42Z", "total_results": 0, "total_unique_results": 0, "next_launch_at": null, "ended_at": null, "duration": 0.0, "credit_used": 0.0, "origin": "user", "status": "pending", "export_done": null, "export_count": 0, "export_time": null, "email_done": null, "email_time": null, "created_at": "2024-05-17T00:22:42Z", "done_reason": null, "done_reason_desc": null }f
- id: string, l’identifiant unique du run qu’on va utiliser pour évaluer le statut du run ensuite
- object: string, ici run, la nature de l’objet
- cluster: string, l’identifiant du cluster auquel ce run est rattaché
- is_done: booléen, si vrai le run est terminé
- started_at: date, à laquelle le run a démarré
- total_results: entier, nombre total d’annonces récoltées
- total_unique_results: entier, nombre total d’annonces uniques récoltées
- next_launch_at: date, à laquelle le run va à nouveau se lancer, s’il était auparavant dans le statut paused si vous avez consommé tous vos crédits journaliers par exemple
- ended_at: date, à laquelle le run s’est terminé
- duration: float, durée du run exprimé secondes
- credit_used: float, crédit journalier utilisé exprimé en secondes
- origin: string, origine de la collecte, user si l’utilisateur a lancé la collecte via la route d’API ou l’interface, schedule si le run a été lancé via l’outil de programmation de runs de l’application
- status: string, statut du run, pending pendant la phase de lancement, running pendant le temps de collecte, et done une fois le run terminé
- export_done: booléen, si vrai l’export des données vers le s3 s’est fait avec succès
- export_count: entier, nombre d’exports vers le s3 réalisés
- export_time: date, à laquelle le dernier export a été réalisé
- email_done: booléen, si vrai un email a été envoyé à la fin du run
- email_time: date, à laquelle l’email a été envoyé
- created_at: date, à laquelle l’objet run a été créé
- done_reason: string, qui mentionne la raison pour laquelle le run s’est terminé
- done_reason_desc: string, qui donne plus d’informations sur le champ précédent
On va conserver l’ID du run à utiliser ensuite:
1d66f25e6aef492e81bba0671fa77f2c
Mais comment savoir si le run est terminé — afin d’aller récupérer les données?
Vérifier l’état du run
L’API est asynchrone, autrement dit une fois le run lancé, il faut attendre que celui-ci se termine avant d’aller récupérer les données.
L’API asynchrone permet de prendre en charge des tâches qui durent de plusieurs minutes à plusieurs heures.

Elle est essentielle ici, où les tâches de web scraping peuvent durer plusieurs heures.
Comment savoir si le run est terminé?
Code
On utilise une méthode GET la route /runs — plutôt que POST précédemment utilisé.
curl 'https://api.lobstr.io/v1/runs/1d66f25e6aef492e81bba0671fa77f2c' \ -H 'Accept: application/json' \ -H 'Authorization: Token 9425a66eba999yh87d4b20078bob905r888o8dfv'f
Réponse
{ "id":"1d66f25e6aef492e81bba0671fa77f2c", "object":"run", "created_at":"2024-05-17T00:22:42.480714", "started_at":"2024-05-17T00:22:42.480715", "next_launch_at":null, "ended_at":"2024-05-17T08:45:02.503641", "duration":74.13130000000001, "credit_used":74.13130000000001, "origin":"user", "status":"done", "export_time":"2024-05-17T08:46:48.323352", "export_done":true, "mail_done":null, "mail_time":null, "total_unique_results":10, "crawler_id":"33db1ca85160105eeb84d5aa51cfad10", "done_reason":"tasks_done", "done_reason_desc":null, "shared":false, "cluster":"4b1ba00657cd4e4798f49309c82fbb06" }f
On retrouve bien l’ensemble des attributs décrits précédemment:
- Le run a duré 74 secondes
- 10 résultats uniques collectés i.e. 7.5 seconde par résultat
✅
On garde l’ID du run:
1d66f25e6aef492e81bba0671fa77f2c
On va maintenant récupérer les données.
8. Récupérer les données de l’API Leboncoin
Les annonces Leboncoin ont été scrappées avec succès!
On va aller les récupérer.
Code
curl 'https://api.lobstr.io/v1/results?run=1d66f25e6aef492e81bba0671fa77f2c&page=1&page_size=100' \ -H 'Accept: application/json' \ -H 'Authorization: Token 9425a66eba999yh87d4b20078bob905r888o8dfv'f
On retrouve bien dans le cURL:
- /results: la route de l’API pour aller récupérer les données scrappées
- run: string, l’ID du run récupéré précédemment, ici 1d66f25e6aef492e81bba0671fa77f2c
- page: entier, le numéro de la page, qui permet de paginer d’une page de résultat à la suivante, ici 1
- page_size: entier, le nombre d’items par page, par défaut 100
Réponse
{ "count":10, "limit":100, "page":1, "total_pages":1, "result_from":1, "result_to":10, "data":[ { "id":"b5e79acc61d9d7771fe4ec9295bbc319", "object":"result", "run":"1d66f25e6aef492e81bba0671fa77f2c", "DPE":"b", "DPE_int":null, "DPE_string":"B", "GES":"a", "GES_int":null, "GES_string":"A", "ad_type":"offer", "annonce_id":"2634542542", "api_key":"54bb0281238b45a03f0ee695f73e704f", "area":200, "capacity":null, "category_name":"Ventes immobili\u00e8res", "charges_included":null, "city":"Cassis 13260", "currency":"EUR", "custom_ref":null, "department":"Bouches-du-Rh\u00f4ne", "description":"Proximit\u00e9 \"Plan d'olive\" , au calme, belle villa enti\u00e8rement r\u00e9nov\u00e9 avec piscine sans vis \u00e0 vis. \nElle se compose actuellement au rdc d'un vaste s\u00e9jour/ salle \u00e0 manger tr\u00e8s lumineux donnant sur un beau jardin arbor\u00e9 avec piscine d'environ 1000 m2 et d'une belle terrasse avec coin solarium expos\u00e9 sud/ouest. Une cuisine ind\u00e9pendante et une buanderie.\nA l'\u00e9tage, 5 chambres dont une suite parentales . Une salle de bain et 3 salle d'eau. Nombreux rangements.\nUn box double compl\u00e8te ce bien.\nRare \u00e0 la vente.\nDPE:B\nPrix: 1 100 000 euros. Honoraire \u00e0 la charge du vendeur", "detailed_time":null, "details":{ "GES":"A", "Type de bien":"Maison", "Classe \u00e9nergie":"B", "Honoraires inclus":"Oui", "Nombre de niveaux":"2", "Nombre de pi\u00e8ces":"7", "Places de parking":"2", "Surface habitable":"200 m\u00b2", "Nombre de chambres":"5 ch.", "Surface totale du terrain":"1000 m\u00b2" }, "district":null, "expiration_date":"2024-06-08T10:26:46Z", "filling_details":null, "first_publication_date":"2024-04-09T10:26:46Z", "floor":null, "furnished":null, "has_online_shop":false, "has_phone":true, "has_swimming_pool":null, "is_active":null, "is_deactivated":null, "is_detailed":null, "is_exclusive":null, "land_plot_area":1000, "last_publication_date":"2024-04-09T10:26:46Z", "last_scraping_time":null, "lat":"43.23561", "lng":"5.55112", "mail":null, "more_details":{ "ges":"A", "rooms":"7", "square":"200 m\u00b2", "bedrooms":"5 ch.", "is_import":"false", "lease_type":"sell", "district_id":"13022", "energy_rate":"B", "nb_parkings":"2", "fai_included":"Oui", "immo_sell_type":"old", "activity_sector":"2", "nb_floors_house":"2", "district_type_id":"2", "real_estate_type":"Maison", "land_plot_surface":"1000 m\u00b2", "district_visibility":"false", "price_per_square_meter":"5500", "district_resolution_type":"integration" }, "native_id":34546759, "no_salesmen":true, "online_shop_url":null, "owner_name":"GLOBAL IMMO", "owner_siren":"805095841", "owner_store_id":"11551628", "owner_type":"1", "phone":null, "phone_from_user":null, "picture":null, "pictures":"https://img.leboncoin.fr/api/v1/lbcpb1/images/c9/65/6f/c9656fbb1f9cbf6faaad1679856275f0b090c113.jpg?rule=ad-large|||https://img.leboncoin.fr/api/v1/lbcpb1/images/97/15/7c/97157c0300add614957e5678f7ba4727e01ffd03.jpg?rule=ad-large|||https://img.leboncoin.fr/api/v1/lbcpb1/images/94/42/c8/9442c8a8ae9af2bab3b8606ca2bdc3944ed9c5ce.jpg?rule=ad-large|||https://img.leboncoin.fr/api/v1/lbcpb1/images/96/7a/c8/967ac8190a1ce3eeee6916e777f8d5d7d40ac64a.jpg?rule=ad-large|||https://img.leboncoin.fr/api/v1/lbcpb1/images/c7/eb/a9/c7eba9590ce22072c38280dfbb2ad6ec289a735f.jpg?rule=ad-large|||https://img.leboncoin.fr/api/v1/lbcpb1/images/gh/42/7e/gh427eea696631ac81d04651f24c5703d0fbec4a.jpg?rule=ad-large|||https://img.leboncoin.fr/api/v1/lbcpb1/images/47/cd/db/47cddb0d4c8f5f899000d68ec1eb493a9e065804.jpg?rule=ad-large|||https://img.leboncoin.fr/api/v1/lbcpb1/images/63/8b/c4/638bc48732b3680ba819139c52ac9eac22eae653.jpg?rule=ad-large|||https://img.leboncoin.fr/api/v1/lbcpb1/images/06/48/9f/06489f9baaac3547ca933cd70eeb52eaaa916851.jpg?rule=ad-large|||https://img.leboncoin.fr/api/v1/lbcpb1/images/77/3f/40/773f402b9b6d61f02a101017afa64f1467e2527e.jpg?rule=ad-large", "postal_code":"13260", "price":1100000, "real_estate_type":"Maison", "ref":null, "region":"Provence-Alpes-C\u00f4te d'Azur", "room_count":7, "scraping_time":"2024-05-17T08:45:01.229Z", "sleepingroom_count":null, "square_metter_price":null, "status_code":null, "title":"Villa avec piscine sur 1000m2 de terrain", "urgent":false, "url":"https://www.leboncoin.fr/ad/ventes_immobilieres/2634542542", "user_id":"75529911-7f87-4991-a86f-274875920b62" }, ... ] }f
On retrouve bien une liste de dictionnaires. Chaque dictionnaire renvoie l’ensemble des informations concernant une annonce au format JSON.
80+ attributs par annonce au total.
Un set de données exhaustif, lisible, et facile à manipuler.
À nous les villas sous le soleil.
☀️
FAQ
Est-ce qu’il est légal de récupérer les données Leboncoin via l’API proposée par lobstr.io?
Oui, entièrement!
- L’utilisateur a un accès "licite" aux données, c’est le cas ici
- L’utilisateur récupère une partie non substantielle du contenu de la base

Veillez donc à récupérer la donnée, mais ne pas récupérer toute la donnée présente sur le site.
A ne pas faire:
❌ Récupérer toute la donnée du site ❌ Récupérer toute la donnée d’une sous catégorie du site, par exemple "Immobilier"

Un grand pouvoir exige de grandes responsabilités.
N’exagérez pas.
Si vous voulez aller plus loin sur la partie légale, consultez notre article dédié à ce sujet ici:
Est-ce qu’il existe une documentation d’API complète?
Oui, complètement, la doc est accessible ici!
L’API mise à disposition par lobstr.io peut être utilisée avec n’importe quel scraper, vous pourrez donc manipuler toutes les automatisations à partir de cette documentation.
Combien coûte l’API Leboncoin de lobstr.io?
Lobstr met à disposition des scrapers déjà développés, que vous pouvez lancer directement depuis votre ligne de commande via une API.
Le prix dépend de deux facteurs:
- Le type de scraper utilisé
- Le temps en minutes pendant lequel vous faites tourner le scraper
Dans le cas du scraper utilisé lors de ce tutoriel, il faut compter 1 minute pour 35 résultats.
- 50 EUR par mois, avec 5000+ annonces par jour
- 250 EUR par mois, avec 50000+ annonces par jour
- 500 EUR par mois, avec 100000+ annonces par jour
Vous voulez faire une simulation du prix à payer en fonction de vos besoins journaliers?
Utilisez le simulateur, situé en bas de la page produit de chaque scraper.

Est-ce qu’il est possible de recevoir une notification par webhook une fois le travail terminé?
Vous ne voulez pas vérifier tous les quatre matins le statut de votre run, et simplement recevoir une notification par webhook une fois que la collecte est terminée?
C’est normal, et c’est possible!
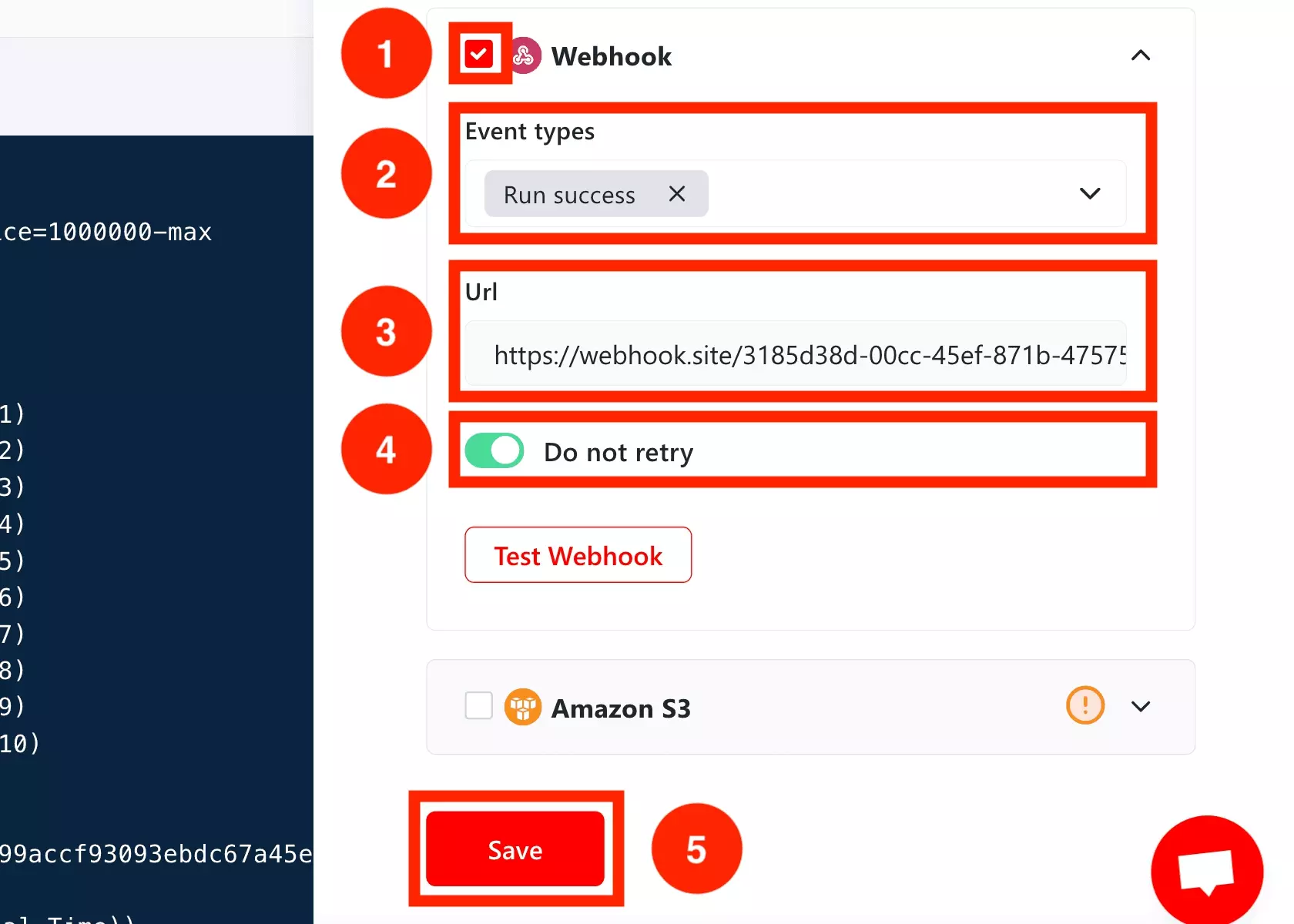
Depuis l’interface, cliquez sur l’icône "Delivery".
Puis procédez comme suit:
- Cliquez sur la check box à côté de "Webhook".
- Dans la partie "Event Types", choisissez le type d’event pour lequel vous recevez une notification. run success en cas de run terminé avec succès, run error si vous souhaitez recevoir une notification en cas de problème.
- Dans "Url", ajoutez l’URL de votre webhook.
- Cochez "Do not retry", si vous souhaitez que l’on ne relance pas une notification en cas d’erreur.
- Cliquez sur "Save" pour sauvegarder les paramètres de livraison choisis.
Et voilà la notification reçue en cas de succès:
{ "id": "1d66f25e6aef492e81bba0671fa77f2c", "event": "Run.export_done", "object": "webhook", "cluster": "Leboncoin Listings Search Export (4)", "ended_at": "2024-05-17T08:45:02.503641" }f
Et on retrouve:
- id: string, l’ID du run
- event: string, le type d’event notifié, soit Run.export_done ou Run.export_error
- cluster: string, le nom du cluster
- ended_at: date, à laquelle l’event a été notifié
Soyez notifié en temps réel.
Est-ce qu’il est possible de récupérer les numéros de téléphones des annonces Leboncoin via API?
Oui, c’est possible!
Il suffit de suivre les même étapes que présentées précédemment, en utilisant ce scraper:

Est-ce qu’il est possible de récupérer les données d’autres sites immobiliers via les APIs de lobstr.io?
Oui, complètement!
Voilà les scrapers déjà disponibles:
Vous avez d’autres idées?