
How to scrape @mails of Restaurants in Paris on TripAdvisor?
tl;dr
Let’s collect 100 Paris restaurants data — included mails — on TripAdvisor. With no code. For free.
In 2 minutes:
🍕
Overview
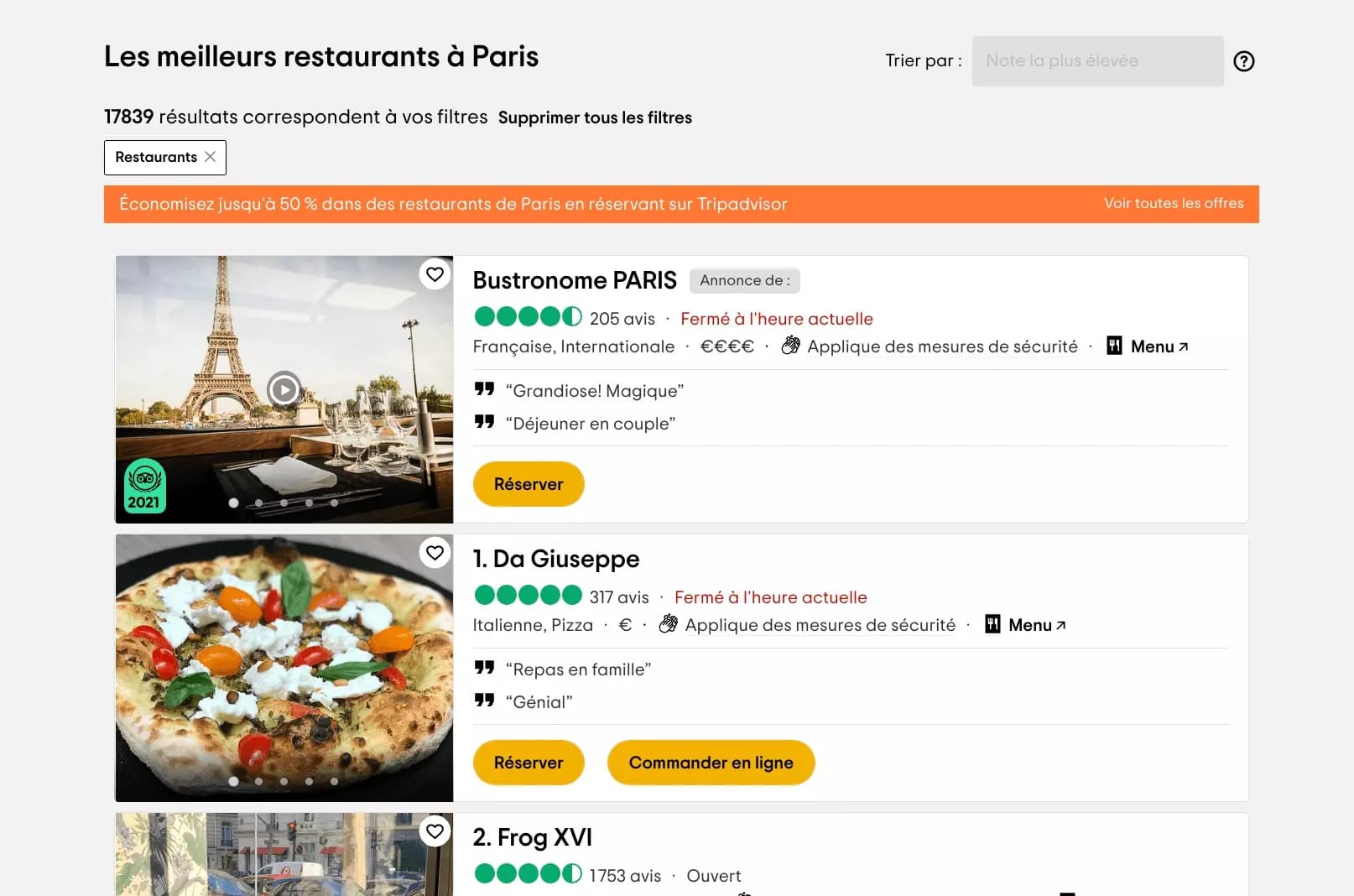
Such a tower, isn’t it?
🗼
On top of providing a large pool of exceptionally qualitative restaurants, the website provide high-quality datapoints. You’ll find of course all usual items — name, address, reviews — advanced items related to restaurants industry — food type, price, michelin stars (!!) — and highly-qualified contact datapoints — phones, and valid mails you’ll be able to leverage you lead acquisition and high-scale growth:
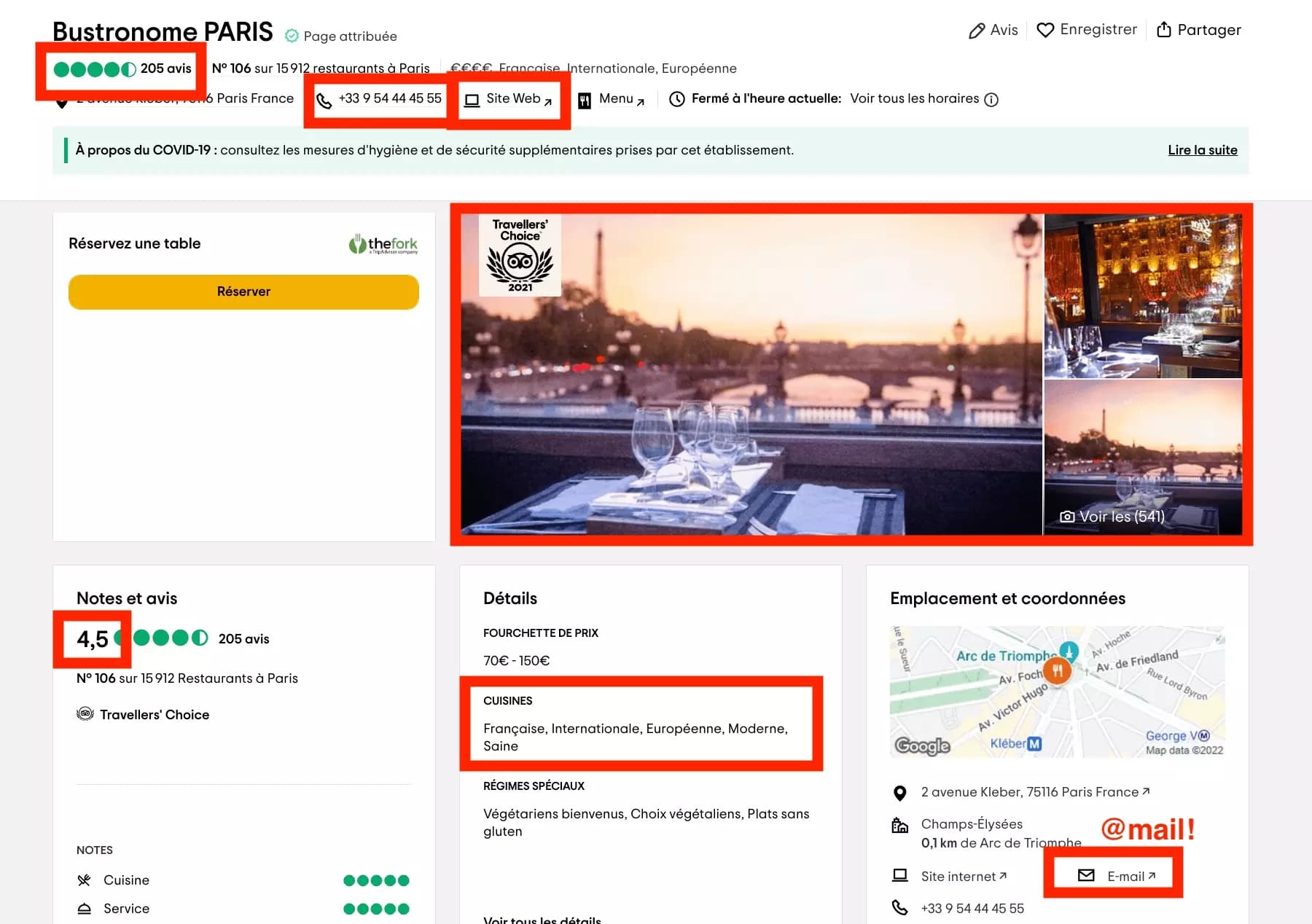
OK now let’s do quick math. Let’s say you copy past 1 mail every 10 seconds i.e. 6 mails every minute, you’ll need approx. 3000 minutes to collect all of it, or 50h. With totally no interruption. Copy-pasting like a bot. Day and night. Collecting only mail. Terrible.
🌝
In this tutorial, we will see how to scrape all datapoints, of all restaurants in Paris on TripAdvisor, at scale while bypassing DataDome. Without any line of code. In 2 minutes of setup. For free!
Target
First of all, let’s go on TripAdvisor, and let’s choose the Paris target, with all restaurants. Then, let’s symply copy-paste the URL which is in the browser:
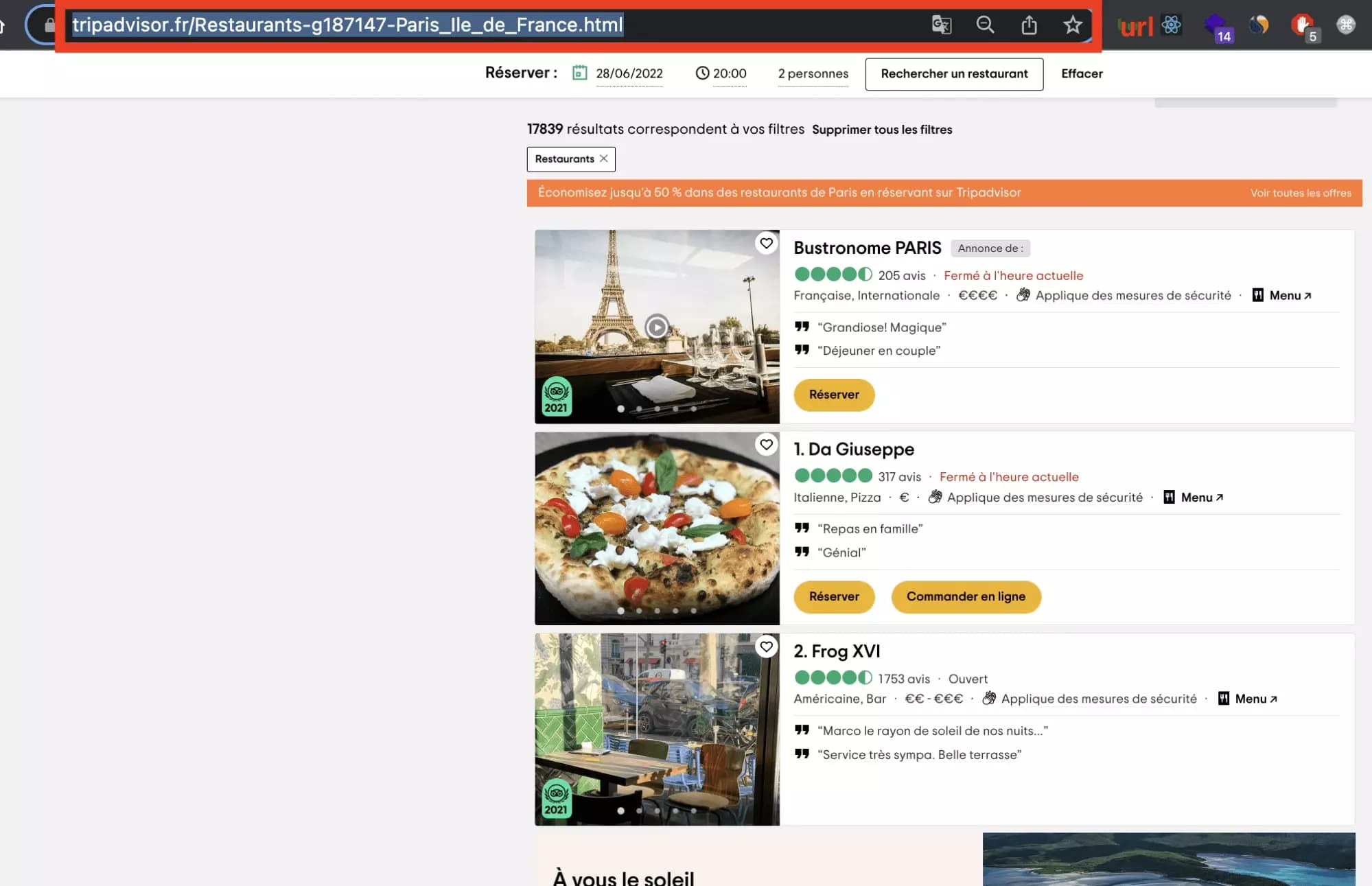
Here we go!
Setup
And we’ll simply click on ‘Start Now’:
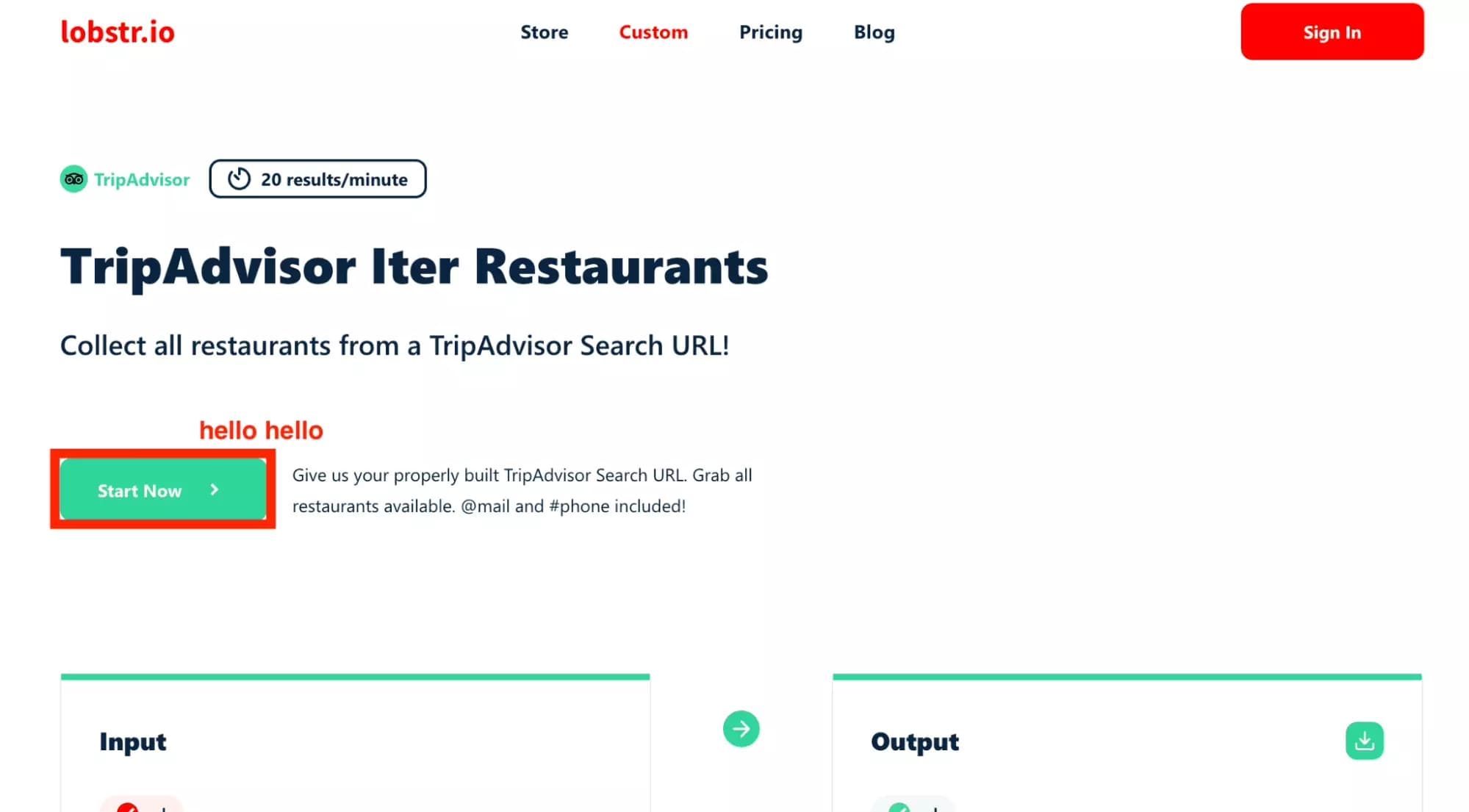
If you click on the cool arrow beside ‘Output’, you can download a sample for free! Just click. It’s totally free.
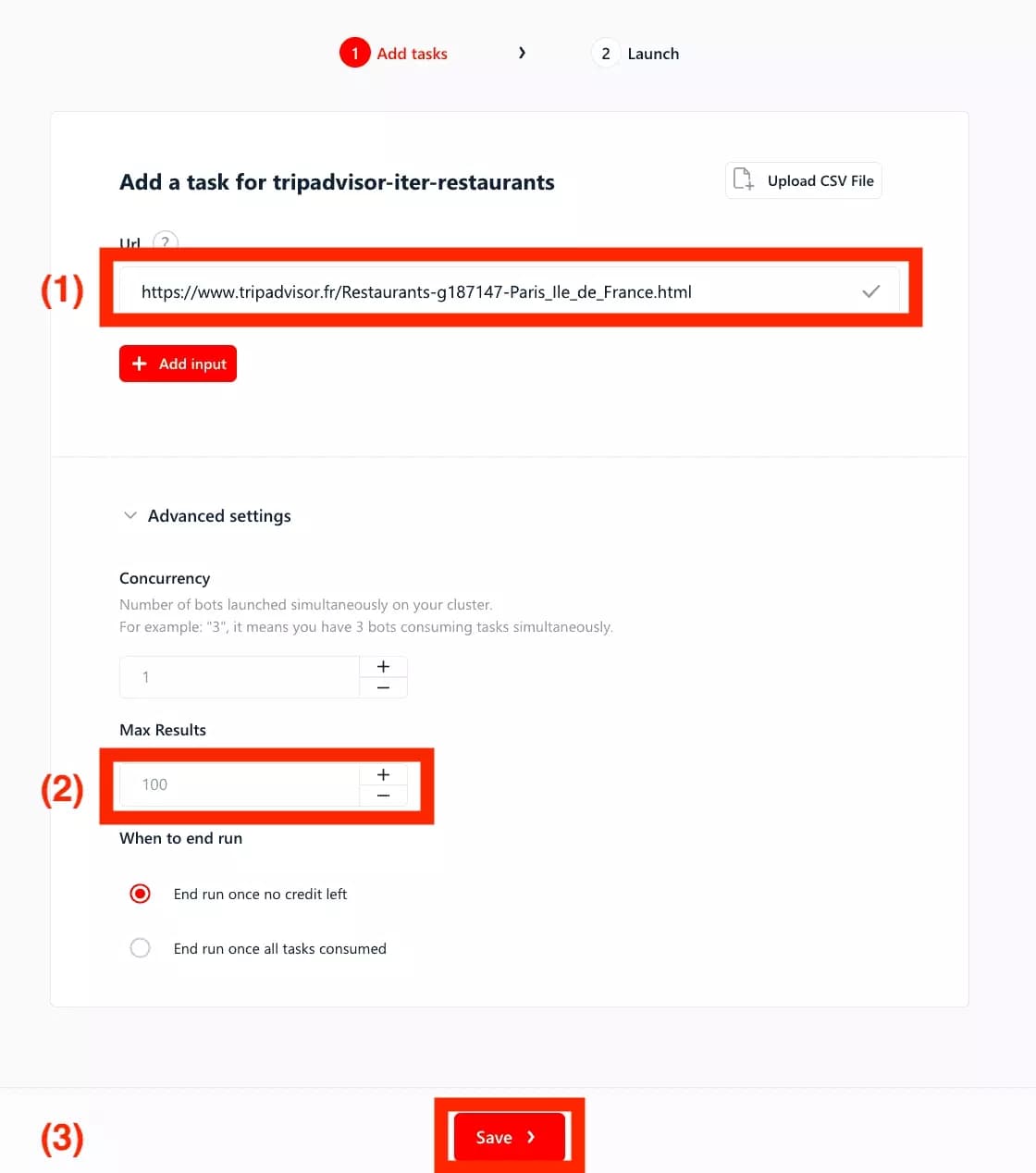
Here, simply paste the previously saved URL (1). Beside, for the purpose of the demonstration, let’s set ‘Max Results’ at 100 (2) i.e. we’ll collect only 100 results max. Let’s not be too greedy to start with.
Endly, let’s click on ‘Save’ (3) :
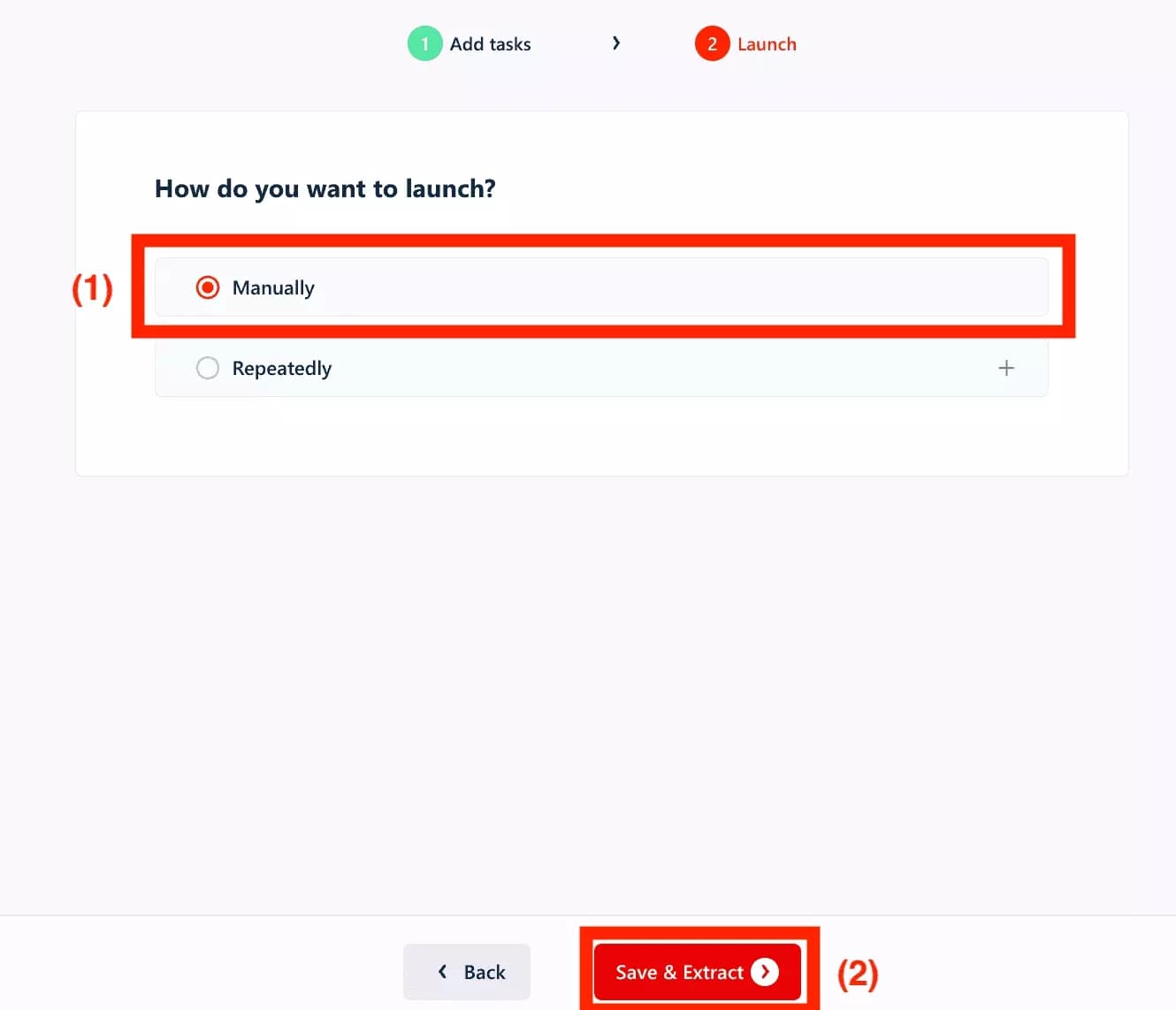
Finally, here we want to launch the crawler only once, manually - and not at regular frequency at a given time.
So we will choose 'Manually' (1) and click on 'Save & Extract' (2):
That’s simple and… that’s it!
Launch
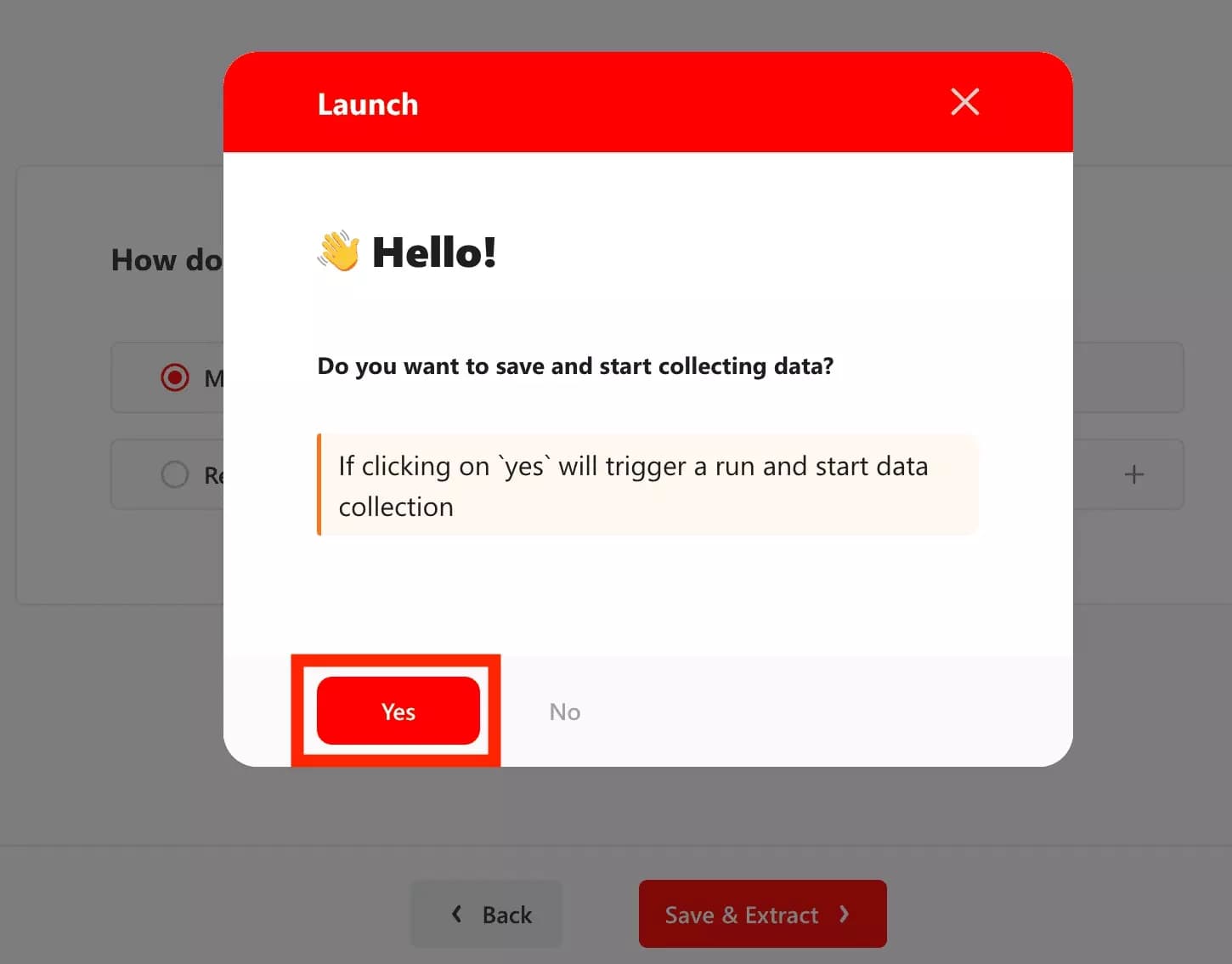
A final modal is raised
👋
Let’s press yes!
A run is automatically triggered:
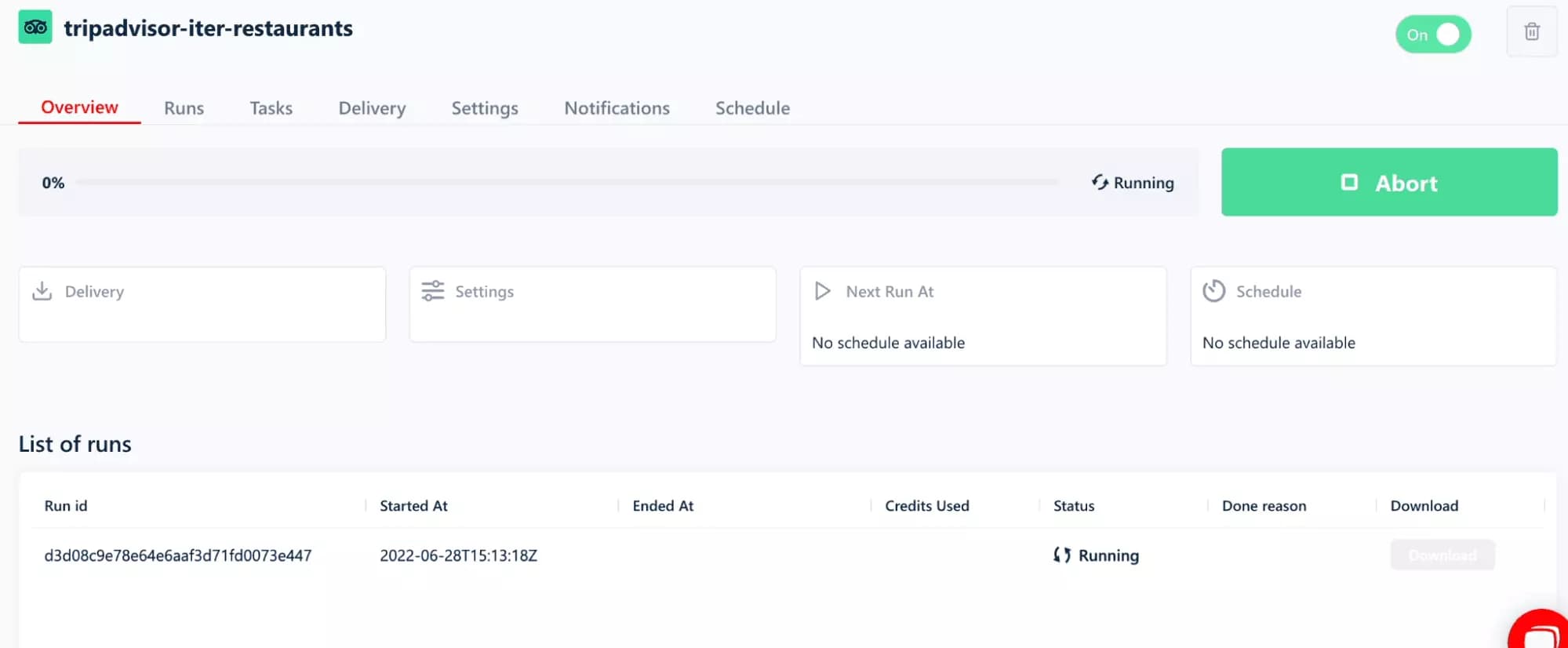
Time to wait relax while the machines are at work
👩🍳
Enjoy
The run has been successfully completed! Just click on the line that represents the run:
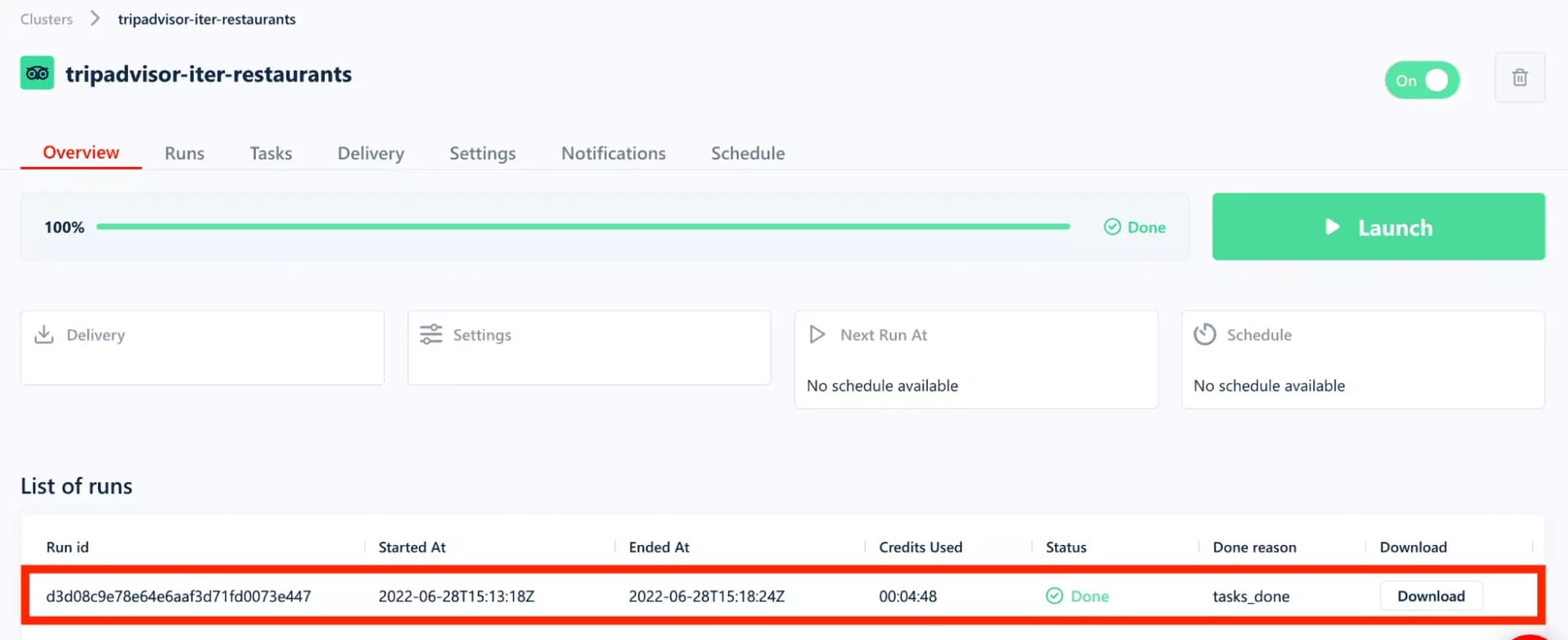
We get a detailed overview of what happened:
- 4 minutes of collection
- exactly 100 gorgeous results
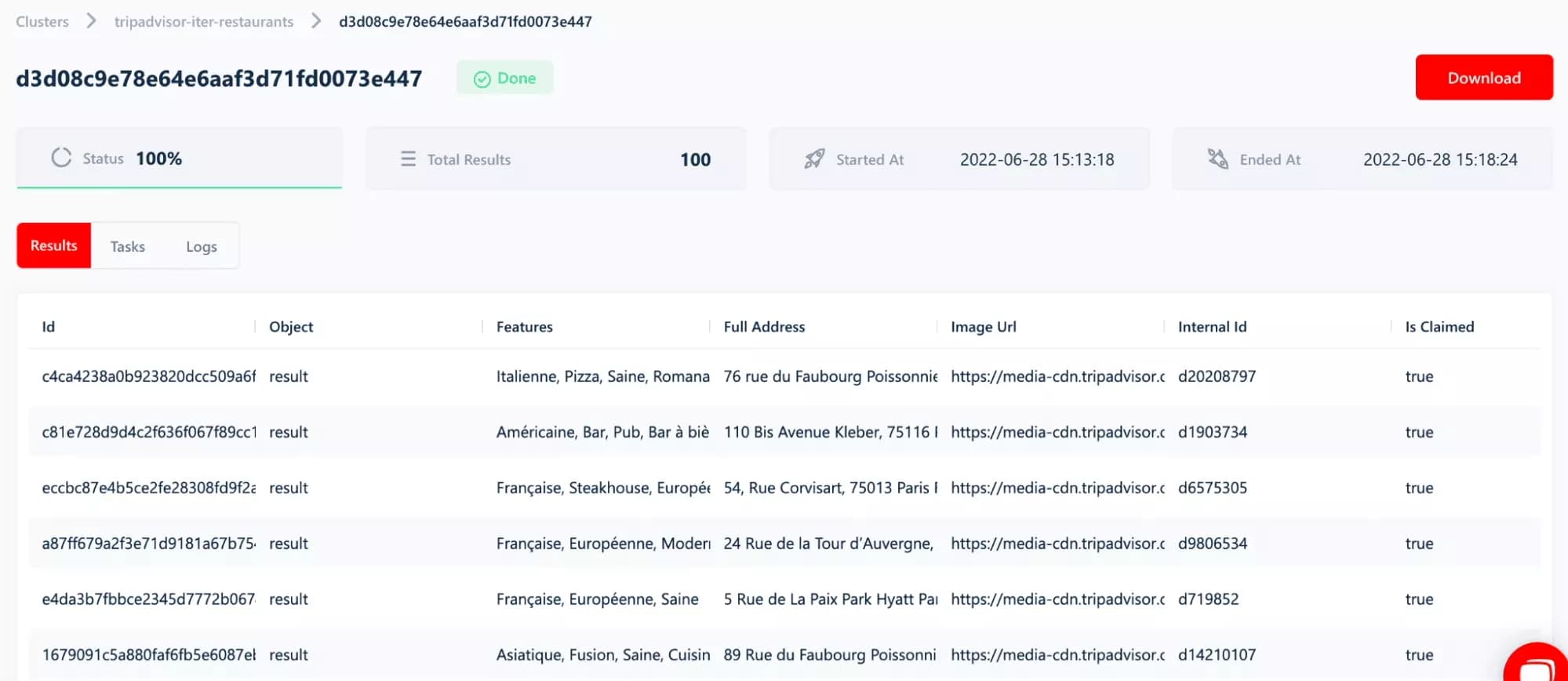
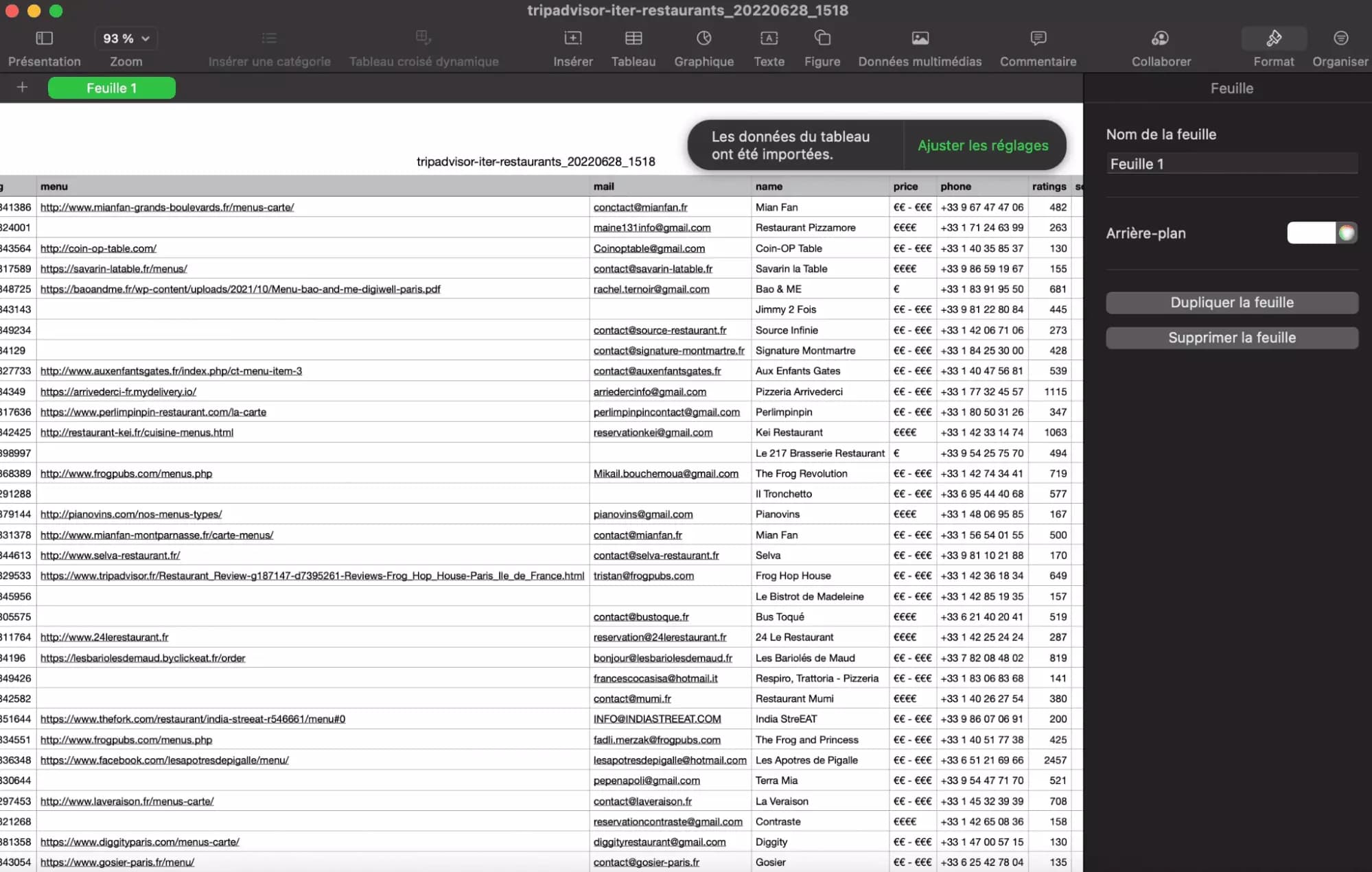
In total, we collected 100 establishments in 5 minutes i.e. 20 establishments per minute, including 100 phones and 82 @mail addresses (!!!). Awesome!
With a 20 EUR per month plan, you get 1 hour per day of collection - that's 1200 establishments per day, and 36000 establishments per month.
Conclusion
TripAdvisor is an exceptional source of data, with exhaustive and accurate datapoints. On top, it provides exceptional contact elements, such as mail and phone. Ideal for creating a list of highly qualified, comprehensive and quickly usable prospects.
Happy scraping!
🦞