
How to scrape Yelp listings using Python and requests in 2023
Prerequisites
Before we scrape Yelp restaurant listings, we need to ensure that we have the necessary tools in place. The two essential components we require are Python and Sublime Text.
- Python: Make sure you have Python installed on your system. If you don't have Python installed, you can download and install it from the official Python website. Choose the appropriate version based on your operating system.
- Sublime Text: Sublime Text is a popular and lightweight text editor that provides a simple and efficient environment for writing Python code. You can download Sublime Text from the official website and install it on your computer.
Once you have Python and Sublime Text set up, you'll be ready to proceed with creating a Yelp scraper using Python and writing the necessary code.
Requirements
To successfully scrape Yelp listings using Python, we will need to install and import several libraries that provide the necessary functionalities. Here are the key libraries we will be using:
- requests: a powerful and user-friendly HTTP library for Python. It simplifies the process of making HTTP requests and handling responses, allowing us to fetch the HTML content of web pages.
- csv: provides functionality for reading from and writing to CSV (Comma-Separated Values) files. We will utilize this library to store the data into a CSV file for further analysis and processing.
- lxml: a robust and efficient library for parsing HTML and XML documents. It offers easy navigation and extraction of data using xPath or CSS selectors, which will be crucial for extracting specific elements from Yelp's HTML pages. lxml is generally faster than bs4, and it can parse more complex HTML. However, it is also more complex to use, and it requires an external C dependency.
- argparse: allows us to handle command-line arguments with ease. It simplifies the process of specifying options and parameters when running the Yelp scraper, enabling us to customize the search URL and the maximum number of pages to scrape.
- time: provides functions for time-related operations. We will use it to introduce delays between successive requests to avoid overwhelming the server.
pip install requests lxml requestsf
Full Code
And just below:
import requests import csv from lxml import html import argparse import time class YelpSearchScraper: def iter_listings(self, url): response = requests.get(url) if response.status_code != 200: print("Error: Failed to fetch the URL") return None with open('response.html', 'w') as f: f.write(response.text) tree = html.fromstring(response.content) scraped_data = [] businesses = tree.xpath('//div[contains(@class, "container__09f24__mpR8_") and contains(@class, "hoverable__09f24__wQ_on") and contains(@class, "border-color--default__09f24__NPAKY")]') for business in businesses: data = {} name_element = business.xpath('.//h3[contains(@class, "css-1agk4wl")]/span/a') if name_element: data['Name'] = name_element[0].text.strip() data['URL'] = "https://www.yelp.com" + name_element[0].get('href') rating_element = business.xpath('.//div[contains(@aria-label, "star rating")]') if rating_element: rating_value = rating_element[0].get('aria-label').split()[0] if rating_value != 'Slideshow': data['Rating'] = float(rating_value) else: data['Rating'] = None reviews_element = business.xpath('.//span[contains(@class, "css-chan6m")]') if reviews_element: reviews_text = reviews_element[0].text if reviews_text: reviews_text = reviews_text.strip().split()[0] if reviews_text.isnumeric(): data['Reviews'] = int(reviews_text) else: data['Reviews'] = None price_element = business.xpath('.//span[contains(@class, "priceRange__09f24__mmOuH")]') if price_element: data['Price Range'] = price_element[0].text.strip() # ok getting proper xpath categories_element = business.xpath('.//span[contains(@class, "css-11bijt4")]') if categories_element: data['Categories'] = ", ".join([c.text for c in categories_element]) neighborhood_element = business.xpath('.//p[@class="css-dzq7l1"]/span[contains(@class, "css-chan6m")]') if neighborhood_element: neighborhood_text = neighborhood_element[0].text if neighborhood_text: data['Neighborhood'] = neighborhood_text.strip() assert data scraped_data.append(data) return scraped_data def save_to_csv(self, data, filename): keys = data[0].keys() with open(filename, 'w', newline='', encoding='utf-8-sig') as csvfile: writer = csv.DictWriter(csvfile, fieldnames=keys, extrasaction='ignore') writer.writeheader() writer.writerows(data) print("Success! \nData written to CSV file:", filename) def scrape_results(self, search_url, max_page): all_results = [] for page in range(1, max_page): page_url = search_url + f'&start={(page-1)*10}' print(f"Scraping Page {page}") results = self.iter_listings(page_url) if results: all_results.extend(results) time.sleep(2) return all_results def main(): s = time.perf_counter() argparser = argparse.ArgumentParser() argparser.add_argument('--search-url', '-u', type=str, required=False, help='Yelp search URL', default='https://www.yelp.com/search?find_desc=Burgers&find_loc=London') argparser.add_argument('--max-page', '-p', type=int, required=False, help='Max page to visit', default=5) args = argparser.parse_args() search_url = args.search_url max_page = args.max_page assert all([search_url, max_page]) scraper = YelpSearchScraper() results = scraper.scrape_results(search_url, max_page) if results: scraper.save_to_csv(results, 'yelp_search_results.csv') else: print("No results to save to CSV") elapsed = time.perf_counter() - s elapsed_formatted = "{:.2f}".format(elapsed) print("Elapsed time:", elapsed_formatted, "seconds") print('''~~ success _ _ _ | | | | | | | | ___ | |__ ___| |_ __ __ | |/ _ \| '_ \/ __| __/| '__| | | (_) | |_) \__ \ |_ | | |_|\___/|_.__/|___/\__||_| ''') if __name__ == '__main__': main()f
Step by step code explanation
Importing the Required Libraries
To begin coding our Yelp scraper, we first need to import the libraries. By importing these libraries, we ensure that we have access to the required tools and functionalities for our Yelp scraper.
import requests import csv from lxml import html import argparse import timef
Creating the YelpSearchScraper Class
Gathering Yelp business listings data
class YelpSearchScraper: def iter_listings(self, url): response = requests.get(url) if response.status_code != 200: print("Error: Failed to fetch the URL") return Nonef
Here's what happens in this method:
- It sends an HTTP GET request to the specified url using the requests.get() function and assigns the response to the response variable.
- The code then checks the status_code attribute of the response object. A status code of 200 indicates a successful response. If the status code is not 200, it means there was an error in fetching the URL.
- If the status code is not 200, the code prints an error message indicating the failure to fetch the URL and returns None.
After fetching the HTML content of the Yelp page, we want to save it for reference. To do this, we can use the following code snippet:
with open('response.html', 'w') as f: f.write(response.text)f
Once we have fetched the HTML content of the Yelp page, the next step is to parse it and extract the relevant information. Let's examine the following code snippet:
tree = html.fromstring(response.content) scraped_data = []f
- We use the fromstring() function from the html module in lxml to create a tree object called tree. This function takes the response.content as input, which contains the HTML content retrieved from Yelp.
- The response.content represents the raw HTML content in bytes. By passing it to fromstring(), we convert it into a structured tree object that we can traverse and extract data from.
- We initialize an empty list called scraped_data to store the extracted data from the Yelp restaurant listings.
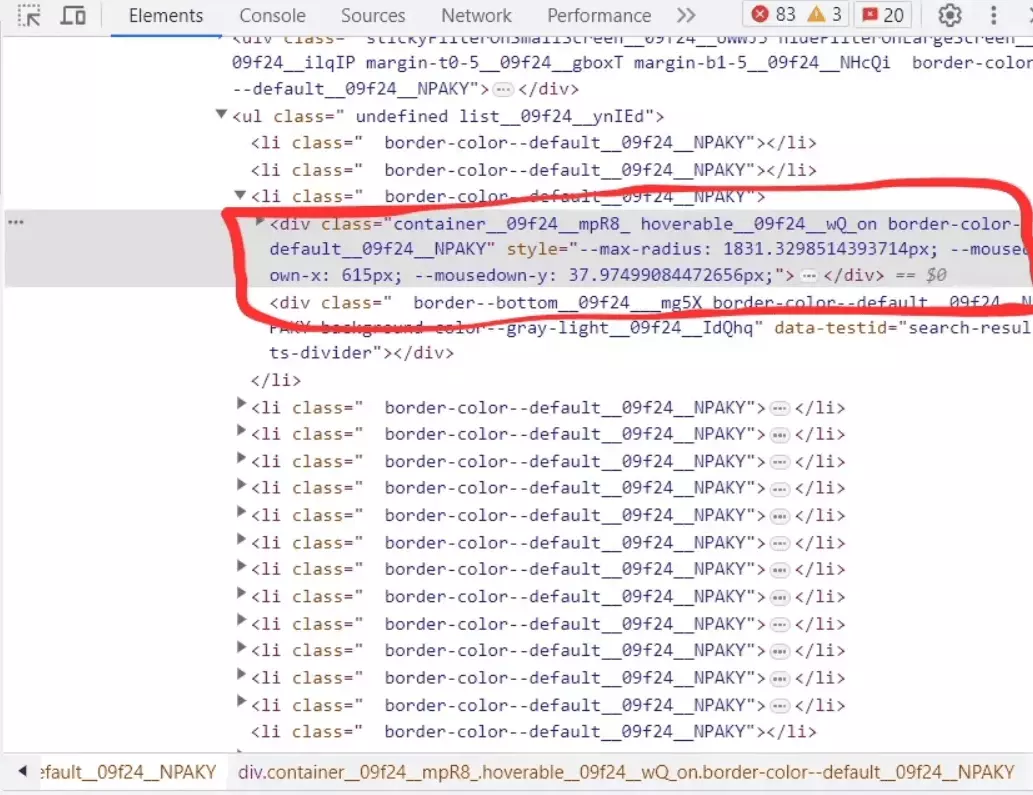
businesses = tree.xpath('//div[contains(@class, "container__09f24__mpR8_") and contains(@class, "hoverable__09f24__wQ_on") and contains(@class, "border-color--default__09f24__NPAKY")')f
- The xpath() method is called on the tree object, and it takes an xPath expression as an argument. The xPath expression used here is
'//div[contains(@class, "container__09f24__mpR8_") and contains(@class, "hoverable__09f24__wQ_on") and contains(@class, "border-color--default__09f24__NPAKY")]'.
- The xPath expression targets <div> elements that contain certain classes. By using the contains() function, we specify that the element must contain all three classes mentioned in the expression. This helps us locate the specific elements that represent the business listings on the Yelp page.
- The xpath() method returns a list of matching elements, which is assigned to the businesses variable.
Extracting business name and listing URL
Now that we have the extracted business listing elements stored in the businesses list, we can proceed to extract specific details for each listing.
for business in businesses: data = {} name_element = business.xpath('.//h3[contains(@class, "css-1agk4wl")]/span/a') if name_element: data['Name'] = name_element[0].text.strip() data['URL'] = "https://www.yelp.com" + name_element[0].get('href')f
- For each business element, we initialize an empty dictionary called data to store the extracted details for that particular business.
- We use the xpath() method on the business element to find the name of the restaurant. The xPath expression:
'.//h3[contains(@class, "css-1agk4wl")]/span/a'
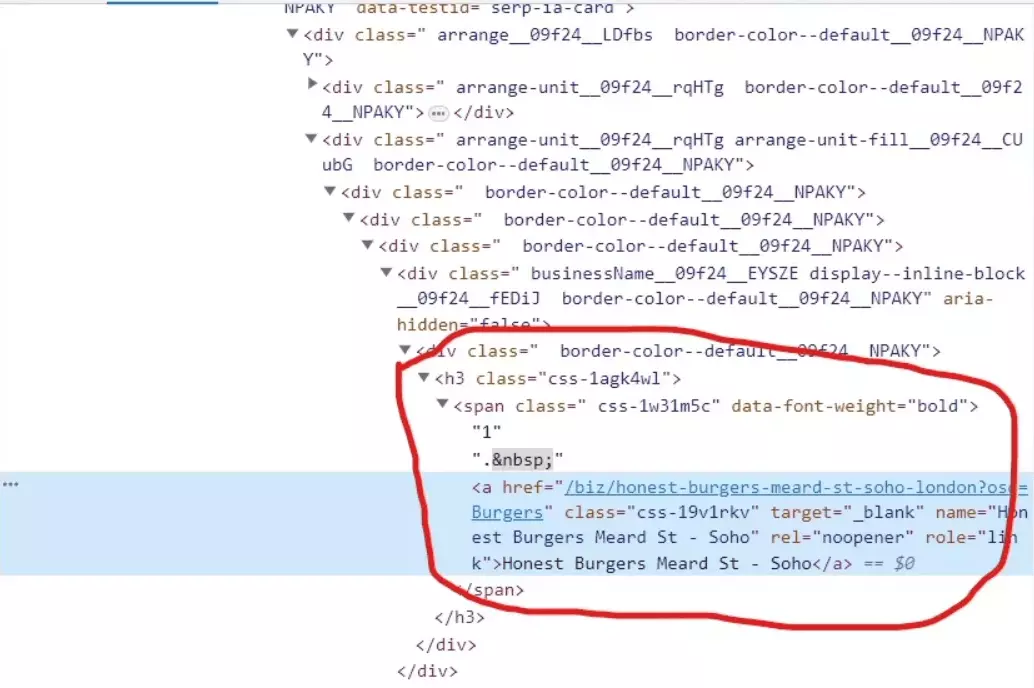
- If the name_element is found, we extract the text of the element using .text.strip() and assign it to data['Name']. We also construct the URL of the restaurant by concatenating "https://www.yelp.com" with the href attribute of the <a> element using .get('href'). This URL is assigned to data['URL'].
That's how this snippet will scrape Yelp business names and listing URLs.
Extracting business rating
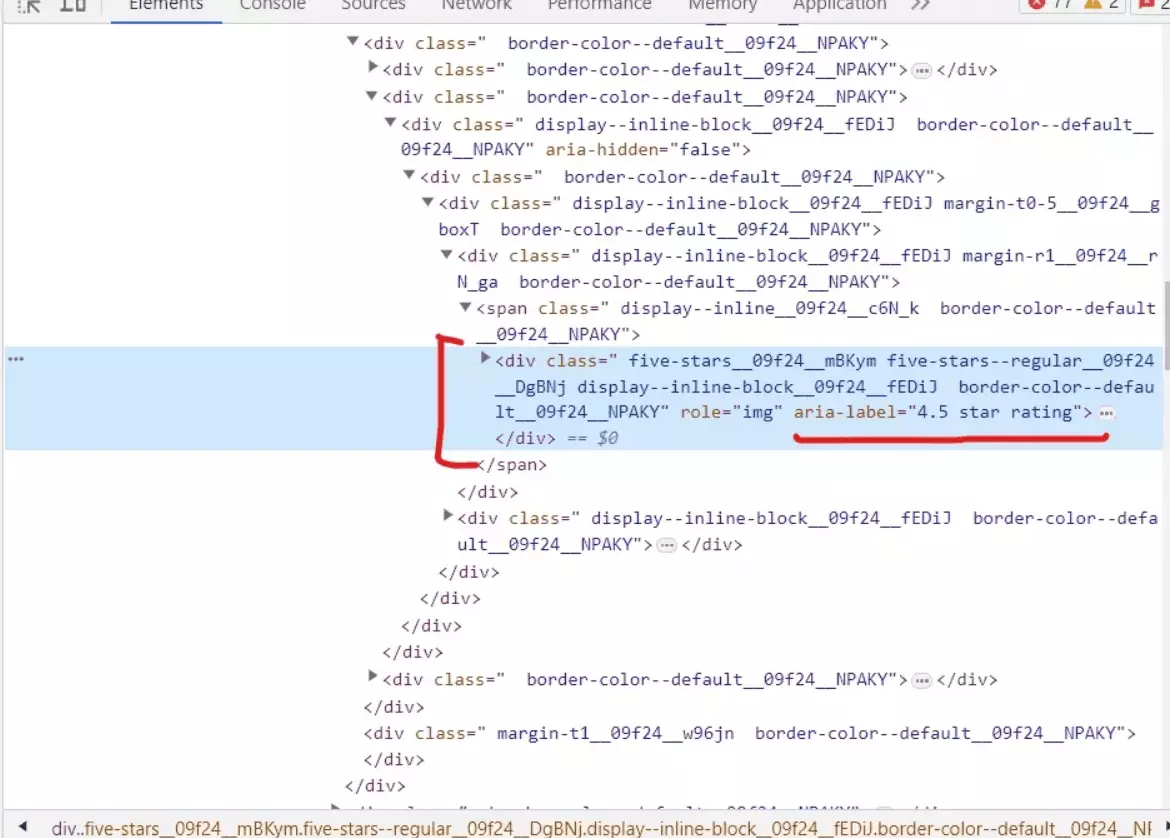
rating_element = business.xpath('.//div[contains(@aria-label, "star rating")]') if rating_element: rating_value = rating_element[0].get('aria-label').split()[0] if rating_value != 'Slideshow': data['Rating'] = float(rating_value) else: data['Rating'] = Nonef
In this snippet, we extract the rating information for each business listing. Here's how it works:
- Again we’ve used the xpath() method on the business element to locate the <div> element that contains the rating information. The xPath expression:
'.//div[contains(@aria-label, "star rating")]'
- If the rating_element is found, we extract the rating value from the aria-label attribute of the element. We retrieve the aria-label attribute using .get('aria-label') and split it into a list of words using .split(). The rating value is the first element of this list, representing the numeric rating value.
- We’ll check if the extracted rating value is not equal to 'Slideshow' (a special case where Yelp displays a dynamic slideshow instead of a numeric rating). If it's not 'Slideshow', we convert the rating value to a float using float(rating_value) and assign it to data['Rating']. Otherwise, if it is 'Slideshow', we assign None to data['Rating'].
Extracting number of reviews
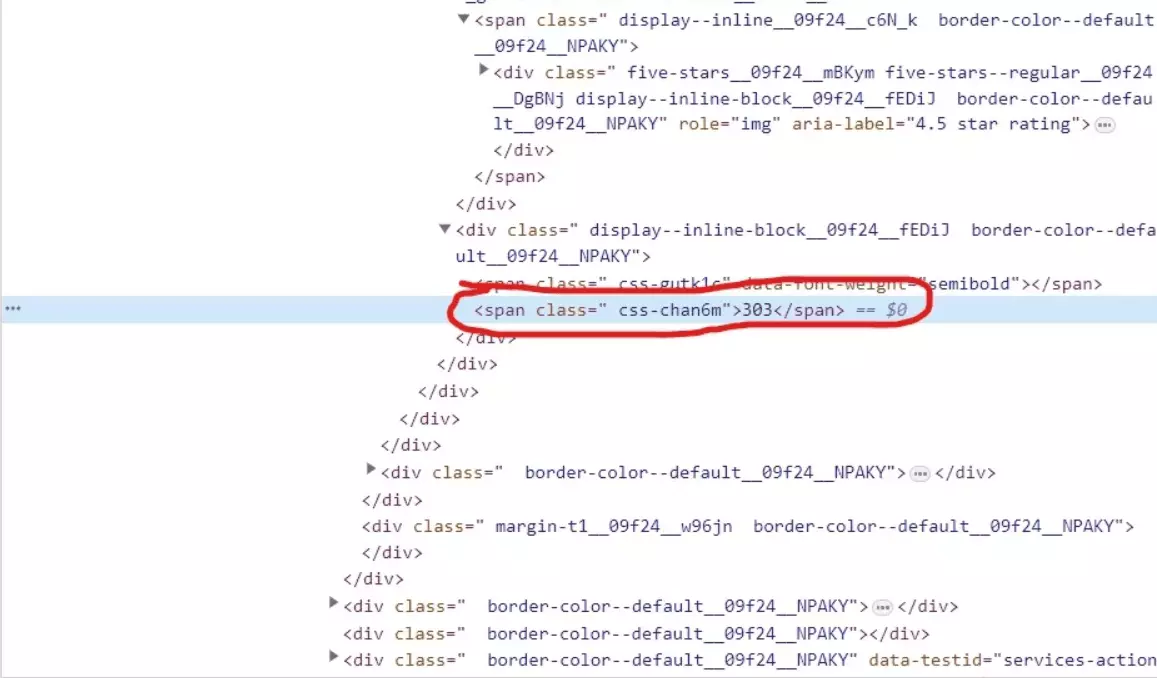
reviews_element = business.xpath('.//span[contains(@class, "css-chan6m")]') if reviews_element: reviews_text = reviews_element[0].text if reviews_text: reviews_text = reviews_text.strip().split()[0] if reviews_text.isnumeric(): data['Reviews'] = int(reviews_text) else: data['Reviews'] = Nonef
Here's a breakdown of this code snippet:
- We use the xpath() method to locate the element to extract the number of reviews.
- If the reviews_element exists, we extract the text content of the element using .text. The extracted text represents the number of reviews.
- We ensure that reviews_text is not empty or None. If it contains a value, we’ll extract the numeric part of the text by removing any whitespaces and taking the first word.
- After extracting the numeric portion, we’ll check if it is a valid number using .isnumeric(). If it is, convert it to an integer and assign it to data['Reviews']. Otherwise, if it is not a valid number, assign None to data['Reviews'].
Extracting price range
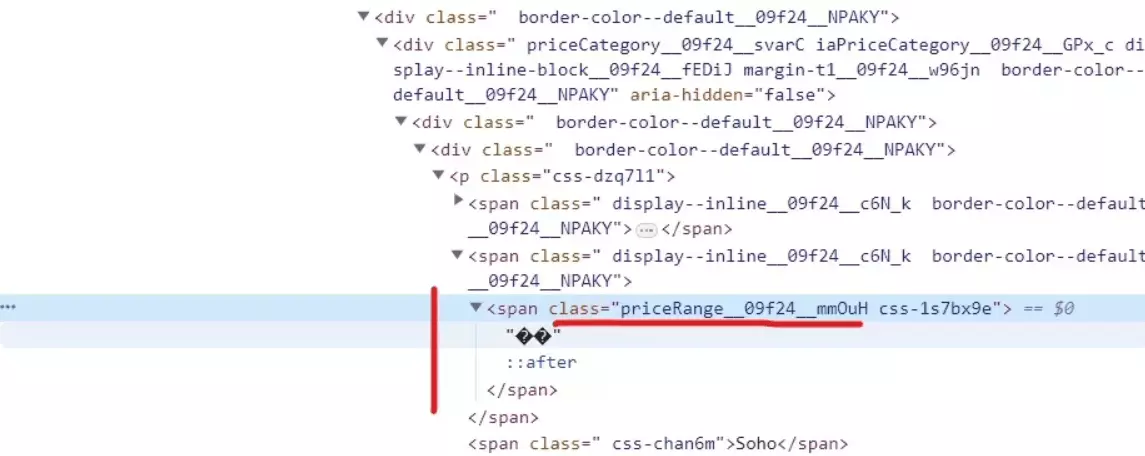
price_element = business.xpath('.//span[contains(@class, "priceRange__09f24__mmOuH")]') if price_element: data['Price Range'] = price_element[0].text.strip()f
This simple snippet will extract the price range from the listings.
Extracting restaurant category
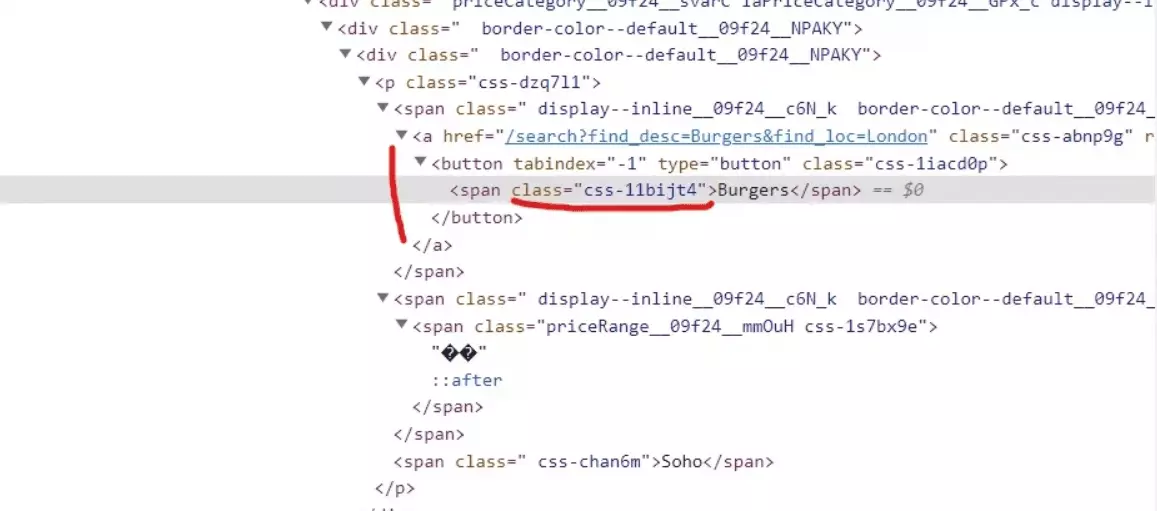
To retrieve the categories associated with each business listing, we use the following code snippet:
categories_element = business.xpath('.//span[contains(@class, "css-11bijt4")]') if categories_element: data['Categories'] = ", ".join([c.text for c in categories_elemenf
Here’s how what this snippet does:
- We search for <span> elements that contains a class named "css-11bijt4" using the xpath()
- If categories_element exists, we extract the text content of each <span> element using a list comprehension: [c.text for c in categories_element]. This creates a list of the category names.
- Then join the elements of the list into a single string, separated by commas, using ", ".join(...). This consolidates the category names into a formatted string.
Extracting neighborhood
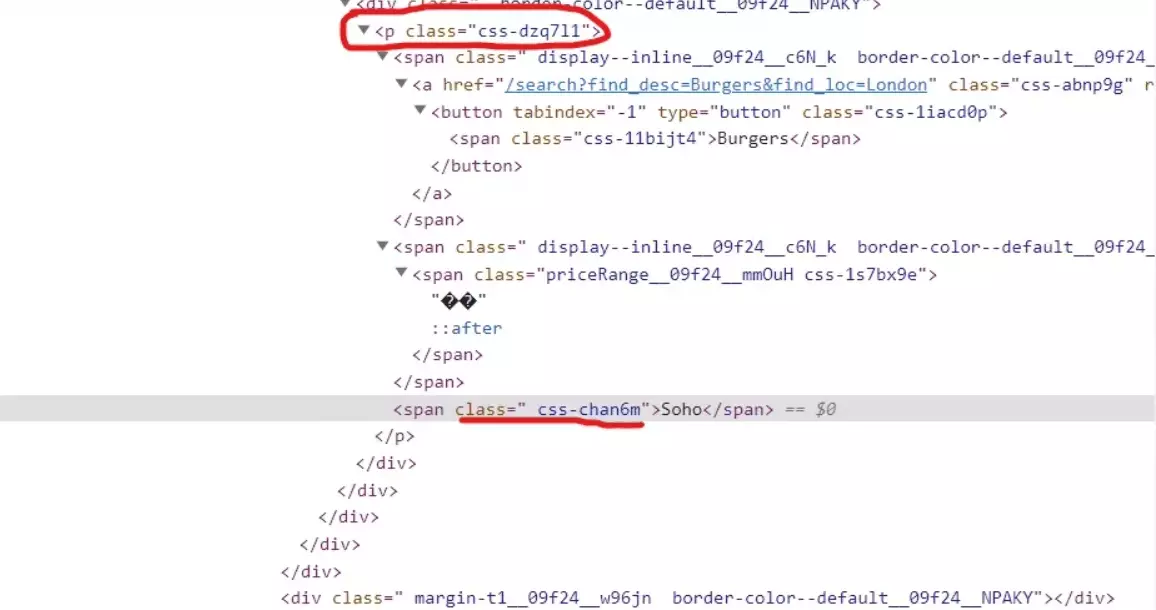
neighborhood_element = business.xpath('.//p[@class="css-dzq7l1"]/span[contains(@class, "css-chan6m")]') if neighborhood_element: neighborhood_text = neighborhood_element[0].text if neighborhood_text: data['Neighborhood'] = neighborhood_text.strip()f
We’ve already learned how this code works so no need to explain it once again. Let’s move to the next part of our code.
After extracting the relevant details from each business listing, we need to store them. Here’s how we do it:
assert data scraped_data.append(data) return scraped_dataf
This code snippet makes sure that the data dictionary contains valid information before storing it in the scraped_data list. Let’s breakdown the code:
- The assert statement is used to validate a condition. In this case, we assert that data is not empty or None. If the condition evaluates to False, an AssertionError is raised, indicating that something unexpected occurred during the scraping process.
- After the assertion, we append the data dictionary to the scraped_data list. This adds the extracted details for a particular business listing to the list of all scraped data.
- Finally, we return the scraped_data list, which contains dictionaries representing the extracted information for each business listing.
Now our Python script is functional and to scrape Yelp listings with 6 data attributes. Let’s save the yelp listings we extracted to a CSV file.
Saving data to CSV
def save_to_csv(self, data, filename): keys = data[0].keys() with open(filename, 'w', newline='', encoding='utf-8-sig') as csvfile: writer = csv.DictWriter(csvfile, fieldnames=keys, extrasaction='ignore') writer.writeheader() writer.writerows(data) print("Success!\nData written to CSV file:", filename)f
def save_to_csv(self, data, filename):f
keys = data[0].keys()f
with open(filename, 'w', newline='', encoding='utf-8-sig') as csvfile:f
writer = csv.DictWriter(csvfile, fieldnames=keys, extrasaction='ignore')f
writer.writeheader() writer.writerows(data)f
Finally, the line prints a success message, confirming that the data has been successfully written to the CSV file.
Scraping multiple pages
While scraping Yelp search results, we don’t want to scrape the first page only. There are only 10 results per page and yelp shows you 24 pages per search URL. Which means you can scrape up to 240 results per search URL. Until now, our code is able to scrape only the first page. Let’s enhance its capabilities and deal with Yelp’s pagination.
def scrape_results(self, search_url, max_page): all_results = [] for page in range(1, max_page): page_url = search_url + f'&start={(page-1)*10}' print(f"Scraping Page {page}") results = self.iter_listings(page_url) if results: all_results.extend(results) time.sleep(2) return all_resultsf
Let’s breakdown this code snippet for better understanding:
def scrape_results(self, search_url, max_page):f
all_results = []f
for page in range(1, max_page):f
page_url = search_url + f'&start={(page-1)*10}'f
results = self.iter_listings(page_url)f
if results: all_results.extend(results)f
time.sleep(2)f
return all_resultsf
Finalizing the Yelp Scraper
def main(): s = time.perf_counter() argparser = argparse.ArgumentParser() argparser.add_argument('--search-url', '-u', type=str, required=False, help='Yelp search URL', default='https://www.yelp.com/search?find_desc=Burgers&find_loc=London') argparser.add_argument('--max-page', '-p', type=int, required=False, help='Max page to visit', default=5) args = argparser.parse_args() search_url = args.search_url max_page = args.max_page assert all([search_url, max_page]) scraper = YelpSearchScraper() results = scraper.scrape_results(search_url, max_page) if results: scraper.save_to_csv(results, 'yelp_search_results.csv') else: print("No results to save to CSV") elapsed = time.perf_counter() - s elapsed_formatted = "{:.2f}".format(elapsed) print("Elapsed time:", elapsed_formatted, "seconds") print('''~~ success _ _ _ | | | | | | | | ___ | |__ ___| |_ __ __ | |/ _ \| '_ \/ __| __/| '__| | | (_) | |_) \__ \ |_ | | |_|\___/|_.__/|___/\__||_| ''') if __name__ == '__main__': main()f
Let’s do a quick breakdown of our main function:
def main(): s = time.perf_counter()f
argparser = argparse.ArgumentParser() argparser.add_argument('--search-url', '-u', type=str, required=False, help='Yelp search URL', default='https://www.yelp.com/search?find_desc=Burgers&find_loc=London') argparser.add_argument('--max-page', '-p', type=int, required=False, help='Max page to visit', default=5) args = argparser.parse_args()f
search_url = args.search_url max_page = args.max_pagef
assert all([search_url, max_page])f
scraper = YelpSearchScraper() results = scraper.scrape_results(search_url, max_page)f
if results: scraper.save_to_csv(results, 'yelp_search_results.csv') else: print("No results to save to CSV")f
elapsed = time.perf_counter() - s elapsed_formatted = "{:.2f}".format(elapsed) print("Elapsed time:", elapsed_formatted, "seconds")f
Scraping Yelp restaurant listings from a search URL
It’s time to test our Yelp scraper. We’ll scrape Yelp to gather details of 30 Chinese restaurants located in London. The first step is to get the URL. Visit yelp.com, search the keyword, and select the location. Now all we have to do is copy the URL from the address bar.
Let’s launch our python based yelp scraper. Go to the folder where you’ve saved the python script. Press shift and right click on an empty area of your screen. From the menu, select “open Powershell window here”.
In your console, type the following command:
python {your_script_name.py} -u {url} -p {max number of pages to scrape}f
python yelpscraper.py -u "https://www.yelp.com/search?find_desc=Chinese&find_loc=London" -p 3f
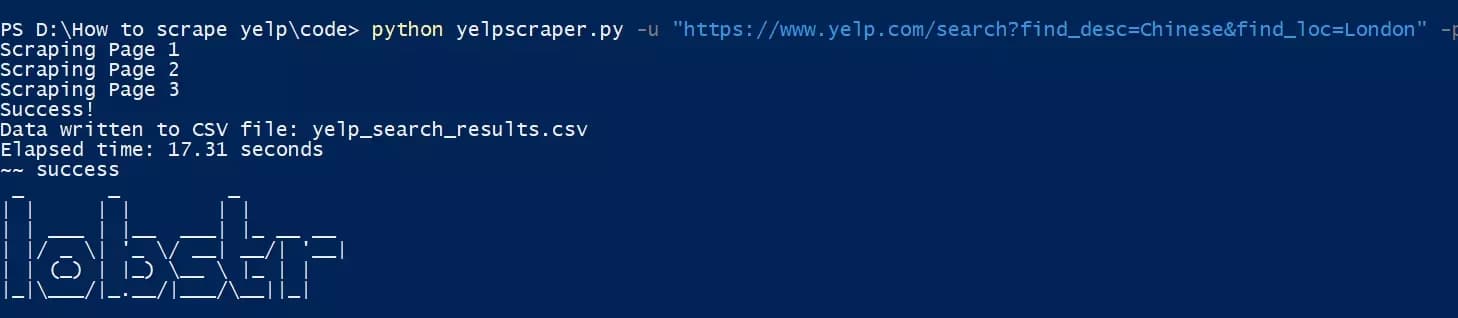
Here we go. We just extracted 30 restaurant listings with 6 data attributes from Yelp. Let’s see how the output file looks like:
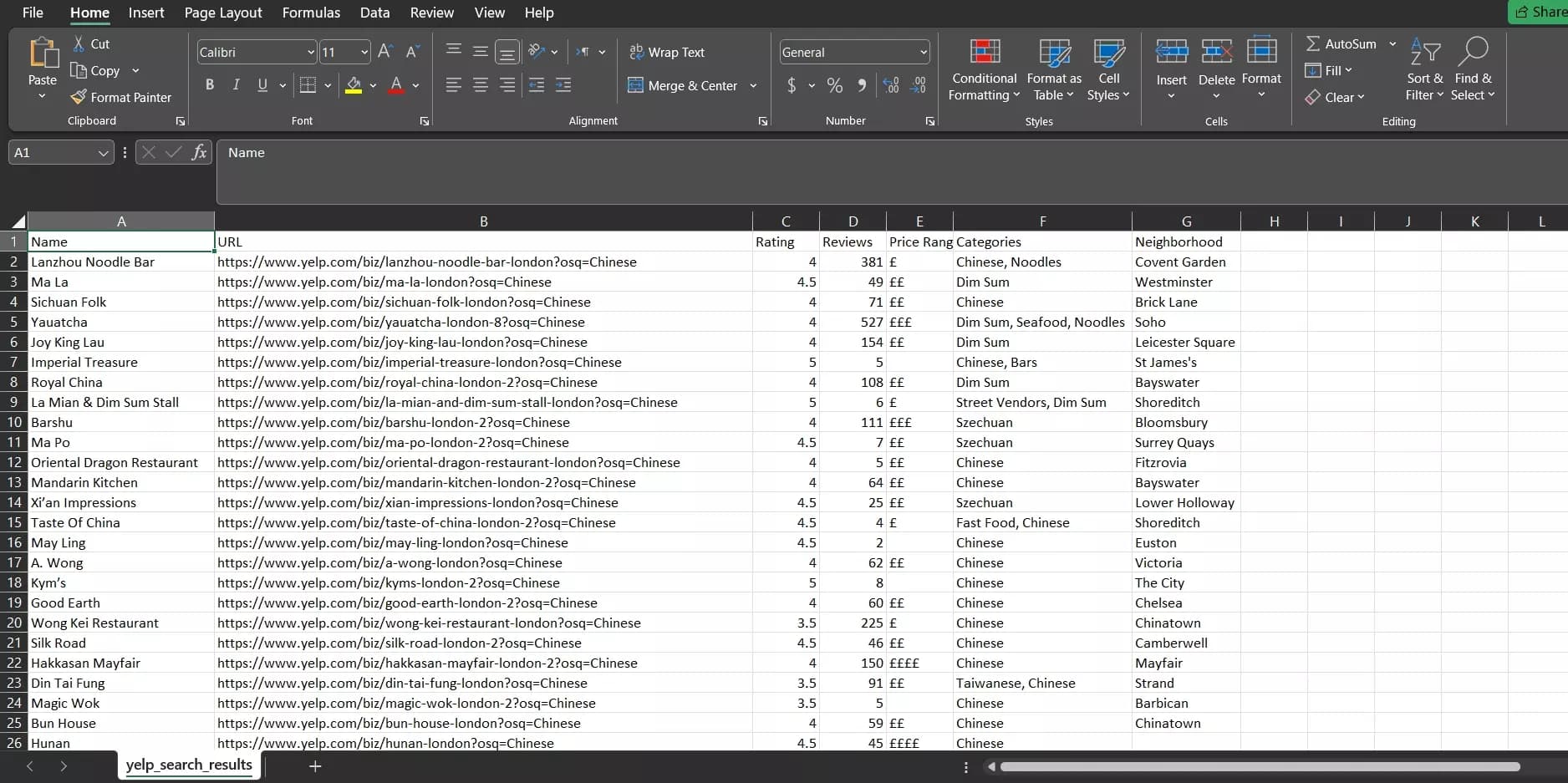
And here they are. 30 Chinese restaurants located in London extracted with name, URL, rating, reviews, categories, and neighborhood. All in just 17 seconds.
Limitations
While our Python-based Yelp scraper offers convenience in extracting restaurant listings from Yelp, it does have some limitations that should be considered. These limitations revolve around the scope of data extraction and the absence of anti-bot bypass measures.
Firstly, the scraper is unable to extract data from individual listing pages, which restricts the depth and breadth of information obtained. While it successfully captures essential attributes such as name, rating, neighborhood, and other basic details, it lacks the capability to navigate to individual listing pages and extract more comprehensive information like contact details, opening hours, or menu items.
Furthermore, the absence of anti-bot bypass measures exposes the scraper to detection by Yelp's security mechanisms. This can lead to potential IP banning, hindering the scraping process and preventing access to Yelp's data. Without anti-bot measures in place, the scraper's reliability and scalability may be compromised, posing limitations for large-scale scraping operations or frequent data extraction.
Conclusion
In conclusion, this article has provided a starting point for scraping restaurant listings from Yelp using Python and the requests library. We've walked through the code, explaining its functionality and limitations. If you're curious about web scraping or looking to learn web scraping with Python, we hope this article has been helpful in introducing you to the process.
Happy scraping 🦞