
How to scrape PDFs with Python3 and Tika library?
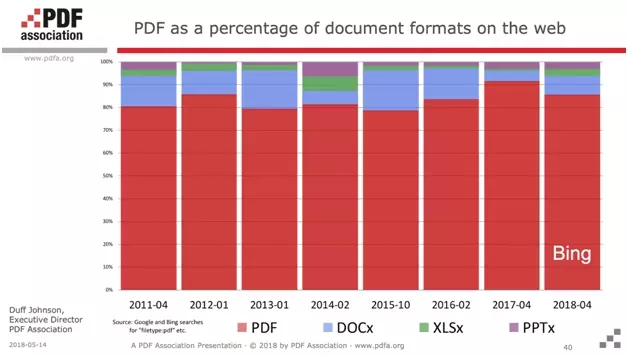
Moreover, more than 85% of the documents indexed on the net are recognized as PDFs. PDF reigns supreme.
The code is available on GitHub here in full: https://gist.github.com/lobstrio/5fc088d44bba8383bf3f91acb11ebd3b
Prerequisites
In order to complete this tutorial from start to finish, be sure to have the following items installed on your computer.
You can click on the links below, which will take you either to an installation tutorial or to the site in question.
To clarify the purpose of each of the above: python3 is the computer language with which we will scrape the pdf, and SublimeText is a text editor. Sublime.
Let's play!
Installation
$ pip3 install tika
NB: be careful, if you work on Mac OS, don't forget to install the Java compiler first
$ brew install --cask adoptopenjdk8
And there you have it, we are set up and ready!
🤖
Step-by-Step Guide
1. Download
Just go to the site, type in the name of the company, and retrieve what is called the "Pappers extract":
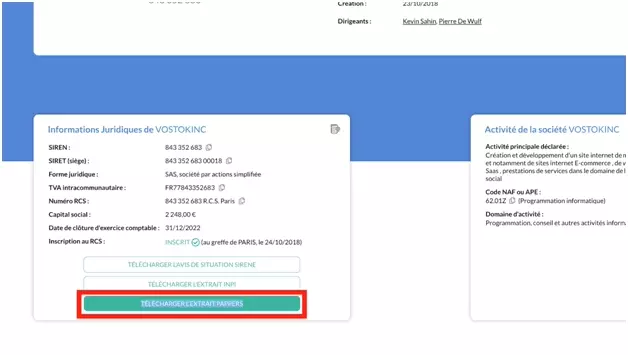
Here is the link to the PDFs of the 4 companies:
With PDFs that all have a similar format, as follows:

Then, remember to save them in the same folder as your Python file.
Now it's time to recover the data!
2. Conversion
In this second part, once the PDFs are recovered, we will convert these PDFs documents into a text document. This will then allow us to easily recover the data.
from tika import parser
raw = parser.from_file(filename)
print(raw)
The result is a properly structured dictionary - and this is what makes this library particularly powerful! - with all the data of the PDF in text format, but also rich metadata: conversion status, publication date, last modification date, PDF version etc.

And here is the code in raw format:
sashabouloudnine@mbp-de-sasha dev % python3
Python 3.10.6 (main, Aug 11 2022, 13:37:17) [Clang 13.0.0 (clang-1300.0.29.30)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> from tika import parser
>>> raw = parser.from_file(/Users/sashabouloudnine/Desktop/LOBSTR - Extrait d'immatriculation.pdf)
KeyboardInterrupt
>>> raw = parser.from_file("/Users/sashabouloudnine/Desktop/LOBSTR - Extrait d'immatriculation.pdf")
>>> print(raw)
{'metadata': {'Content-Type': 'application/pdf', 'Creation-Date': '2022-09-02T17:16:09Z', 'Last-Modified': '2022-09-02T17:16:09Z', 'Last-Save-Date': '2022-09-02T17:16:09Z', 'X-Parsed-By': ['org.apache.tika.parser.DefaultParser', 'org.apache.tika.parser.pdf.PDFParser'], 'X-TIKA:content_handler': 'ToTextContentHandler', 'X-TIKA:embedded_depth': '0', 'X-TIKA:parse_time_millis': '89', 'access_permission:assemble_document': 'true', 'access_permission:can_modify': 'true', 'access_permission:can_print': 'true', 'access_permission:can_print_degraded': 'true', 'access_permission:extract_content': 'true', 'access_permission:extract_for_accessibility': 'true', 'access_permission:fill_in_form': 'true', 'access_permission:modify_annotations': 'true', 'created': '2022-09-02T17:16:09Z', 'date': '2022-09-02T17:16:09Z', 'dc:format': 'application/pdf; version=1.4', 'dcterms:created': '2022-09-02T17:16:09Z', 'dcterms:modified': '2022-09-02T17:16:09Z', 'meta:creation-date': '2022-09-02T17:16:09Z', 'meta:save-date': '2022-09-02T17:16:09Z', 'modified': '2022-09-02T17:16:09Z', 'pdf:PDFVersion': '1.4', 'pdf:charsPerPage': '1603', 'pdf:docinfo:created': '2022-09-02T17:16:09Z', 'pdf:docinfo:creator_tool': 'Chromium', 'pdf:docinfo:modified': '2022-09-02T17:16:09Z', 'pdf:docinfo:producer': 'Skia/PDF m92', 'pdf:encrypted': 'false', 'pdf:hasMarkedContent': 'false', 'pdf:hasXFA': 'false', 'pdf:hasXMP': 'false', 'pdf:unmappedUnicodeCharsPerPage': '0', 'producer': 'Skia/PDF m92', 'resourceName': "bLOBSTR - Extrait d'immatriculation.pdf", 'xmp:CreatorTool': 'Chromium', 'xmpTPg:NPages': '1'}, 'content': "\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\nLOBSTR Extrait Pappers\n\nCe document reproduit les informations présentes sur le site pappers.fr et est fourni à titre informatif. 1/1\n\nN° de gestion 2019B05393\n\nExtrait Pappers du registre national du commerce et des sociétés\nà jour au 02 septembre 2022\n\nIDENTITÉ DE LA PERSONNE MORALE\n\n \n \n\n \n\n \n\n \n \n\n \n\n \n\n \n \n\n \n\n \n\nDIRIGEANTS OU ASSOCIÉS\n\n \n\n \n\n \n\n \n\n \n\n \n\n \n\n \n\nRENSEIGNEMENTS SUR L'ACTIVITÉ ET L'ÉTABLISSEMENT PRINCIPAL\n\n \n\n \n \n\n \n\n \n\nImmatriculation au RCS, numéro 841
840 499 R.C.S. Creteil\n\nDate d'immatriculation 26/08/2019\n\nTransfert du R.C.S. en date du 05/08/2019\n\nDate d'immatriculation d'origine 21/08/2018\n\nDénomination ou raison sociale LOBSTR\n\nForme juridique Société par actions simpli'ée\n\nCapital social 2,00 Euros\n\nAdresse du siège 5 Avenue du Général de Gaulle 94160 Saint-Mandé\n\nActivités principales Collecte et analyse de données à haute fréquence sur internet\n\nDurée de la personne morale Jusqu'au 26/08/2118\n\nDate de clôture de l'exercice social 31 Décembre\n\nDate de clôture du 1er exercice social 31/12/2019\n\nPrésident\n\nNom, prénoms BOULOUDNINE Sasha\n\nDate et lieu de naissance Le 04/10/1993 à Marseille (13)\n\nNationalité Française\n\nDomicile personnel 6 Avenue de Corinthe 13006 Marseille 6e Arrondissement\n\nDirecteur général\n\nNom, prénoms ROCHWERG Simon\n\nDate et lieu de naissance Le 06/12/1990 à Vincennes (94)\n\nNationalité Française\n\nDomicile personnel la Garenne Colombes 42 Rue de Plaisance 92250 La Garenne-\nColombes\n\nAdresse de l'établissement 5 Avenue du Général de Gaulle 94160 Saint-Mandé\n\nActivité(s) exercée(s) Collecte et analyse de données à haute fréquence sur internet\n\nDate de commencement d'activité 24/07/2018\n\nOrigine du fonds ou de l'activité Création\n\nMode d'exploitation Exploitation directe\n\n\n", 'status': 200}
Now that these data are present in text format, we have one last step: retrieving the data, and saving it in a .csv file.
3. Extraction
We have the data in text format. This is much more convenient than PDF, which is a rigid document that is difficult to alter. Now we will retrieve the data.
First, we convert the dictionary into text format:
content = str(raw)
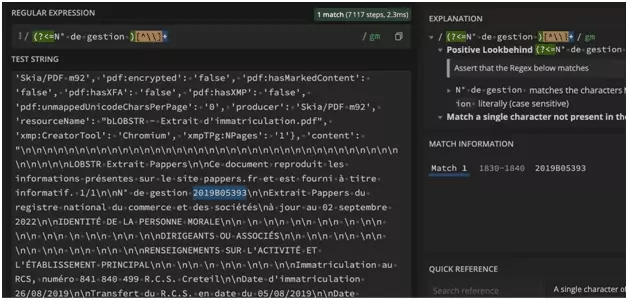
numero_gestion = "".join(re.findall(r'(?<=N° de gestion )[^\]+', content))
a_jour_au = "".join(re.findall(r'(?<=à jour au )[^\]+', content))
numero_rcs = "".join(re.findall(r'(?<=Immatriculation au RCS, numéro )[^\]+', content))
date_immatriculation = "".join(re.findall(r'(?<=Date d'immatriculation )[^\]+', content))
raison_sociale = "".join(re.findall(r'(?<=Dénomination ou raison sociale )[^\]+', content))
forme_juridique = "".join(re.findall(r'(?<=Forme juridique )[^\]+', content))
capital_social = "".join(re.findall(r'(?<=Capital social )[^\]+', content))
adresse_siege = "".join(re.findall(r'(?<=Adresse du siège )[^\]+', content))
activites_principales = "".join(re.findall(r'(?<=Activités principales )[^\]+', content))
And that's it!
We have retrieved 9 attributes in each PDF:
- numero_gestion
- ajourau
- numero_rcs
- date_immatriculation
- raison_sociale
- forme_juridique
- capital_social
- adresse_siege
- activites_principales
All we have to do is save the data in a .csv file, and that's it.
import csv
Then we create a function that saves all the data in a .csv file:
def write_csv(rows):
# write csv
assert rows
with open('parsed_pdf.csv', 'w') as f:
writer = csv.DictWriter(f, fieldnames=HEADERS)
writer.writeheader()
for row in rows:
writer.writerow(row)
And there you have it!
Code
You can find the full code right here, directly available from our github: https://gist.github.com/lobstrio/5fc088d44bba8383bf3f91acb11ebd3b.
To execute the code:
- download the .py code
- download the 4 pdfs mentioned in the tutorial
- put the code and the pdfs in the same folder
- and launch the script via the command line
And this is what will appear directly on your terminal:
$ python3 pappers_pdf_parser_with_python_and_tika.py
1 LOBSTR
2 VostokInc
3 Captain Data
4 PHANTOMBUSTER
~~ success
_ _ _
| | | | | |
| | ___ | |__ ___| |_ __ __
| |/ _ | '_ / __| __/| '__|
| | (_) | |_) __ \ |_ | |
|_|___/|_.__/|___/__||_|
✨
You will find, in the same folder as the script, a CSV file, parsed-pdf.csv, with all the extracted data. The data is cleanly structured, and directly usable:

Wonderful!
Limitations
In particular, you will be able to transform PDFs of company extracts from the Pappers company listing site into readable, structured and usable data.
Beware, however, that you have to download the files by hand, and place them in the same folder as the Python scraper. Moreover, the parser only retrieves 9 attributes - not bad, but it could be better.
Finally, this scraper only works with the Pappers company extract, in a very specific format. We can however imagine other scrapers, with other PDF formats: INPI extract, financial data, sales catalog etc.
Conclusion
And that's the end of the tutorial!
In this tutorial, we have seen how to transform a PDF into text with Python and the tika library, retrieve the data present using regex, and insert all this data into a cleanly structured and usable .csv file.
Happy scraping!
🦀