How to scrape Google Maps with Python? [2024 Edition]
In this tutorial, we will see how to retrieve this data with Python, requests, and the Google Maps API from lobstr.
What is a Google Maps Python Scraper?
A Google Maps Python Scraper is a robot which will move on Google Maps and automatically retrieve the information present.

As its name suggests, the web scraping bot is developed with the Python programming language.
Recovering data by hand is time-consuming and expensive.
The development of a Python scraper therefore has 3 advantages:
- Time saving
- Money saving
- Data robustness
This will allow you to collect data quickly and inexpensively.
What are the differences between a scraper and using the Google Maps API?
You can directly retrieve data from Google Maps, with clear code examples and comprehensive documentation.
All with the blessing of Google themselves.
What's the difference with a homemade scraper?
When you use a homemade scraper, you will create a robot that will move around Google Maps, like a human, and retrieve the data.
If you use the Google Maps API, Google Maps immediately gives you access to its internal database.
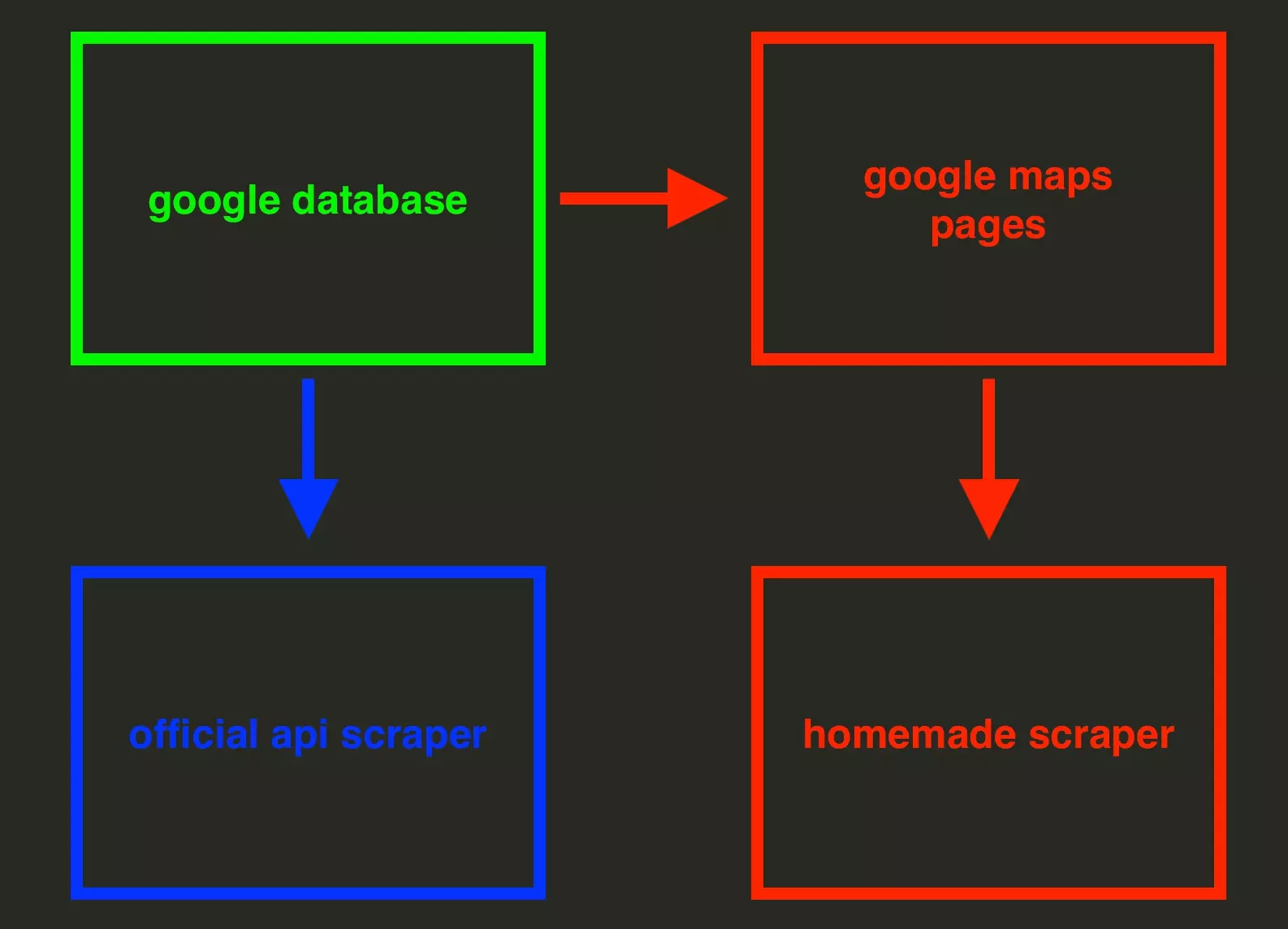
In other words:
- Retrieving from official API: 1 step
- Homemade scraper: 2 steps
Why bother using a homemade scraper?
Why not use the official Google Maps API?
The Google Maps API seems to have only advantages: quality of documentation, blessing from Google, number of steps to access the data.
Why not use the official API then?
These are the main reasons:
- Documentation complex
- Limited data access
- Crazy price
Documentation complex
First, the documentation is really really complex.
Here for example, the documentation gives us access to (we counted) 49 different sublinks.
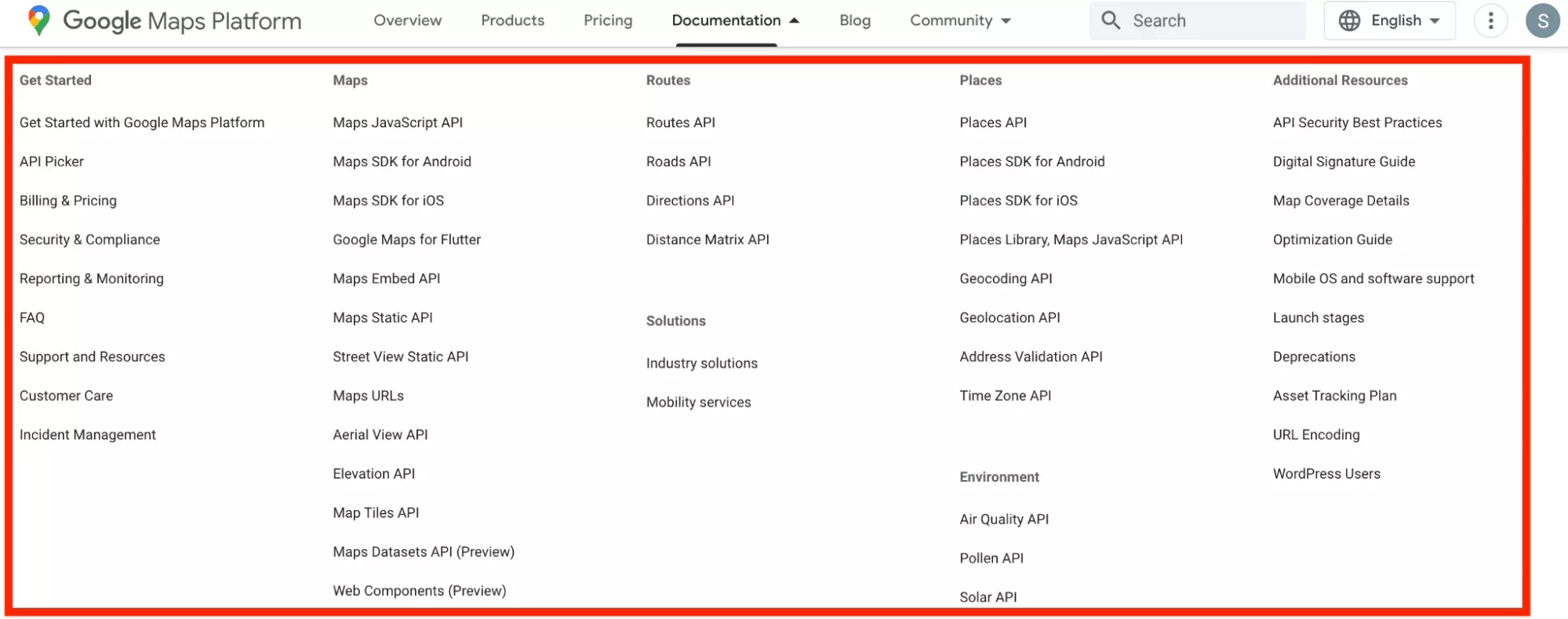
- Places API
- Places API (New)
And once we head towards Places API (New), lovers of progress that we are, there are still 5 distinct routes.
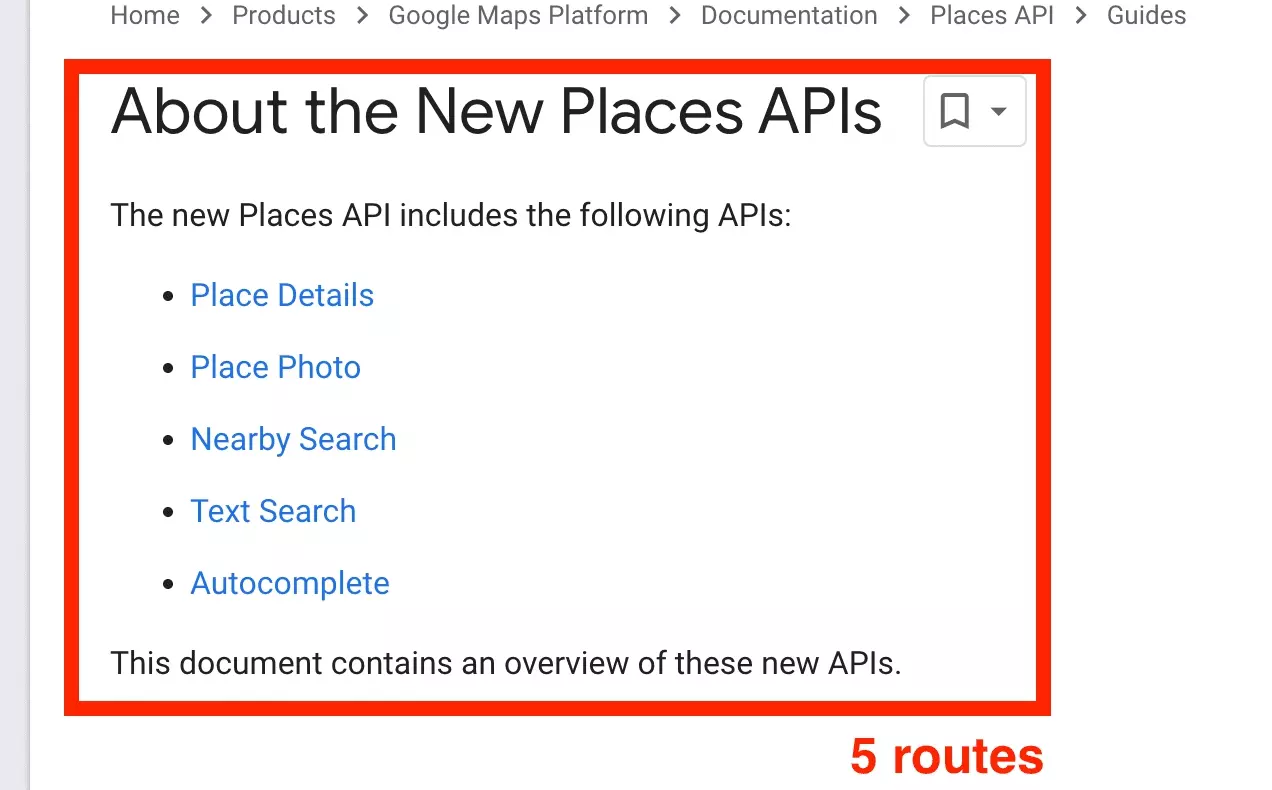
A real maze.
Limited data access
On Google Maps, when you search for a business in a given area, the search results show you up to 200 businesses.
On the Google Maps API, it’s simple, it’s 10 times less.
Max 20 establishments by location and type of business. Terrible.

Crazy price
Finally, the price is particularly high.
With lobstr.io for example, for 550 USD, you will be able to fetch approx. 1 million establishments. From 10 places per minute.
The Google Maps Places API equivalent is:
- Nearby Search
- Advanced — to have all attributes
- 50K requests
- 20 businesses per request
This gives us a total price of 1750 USD.
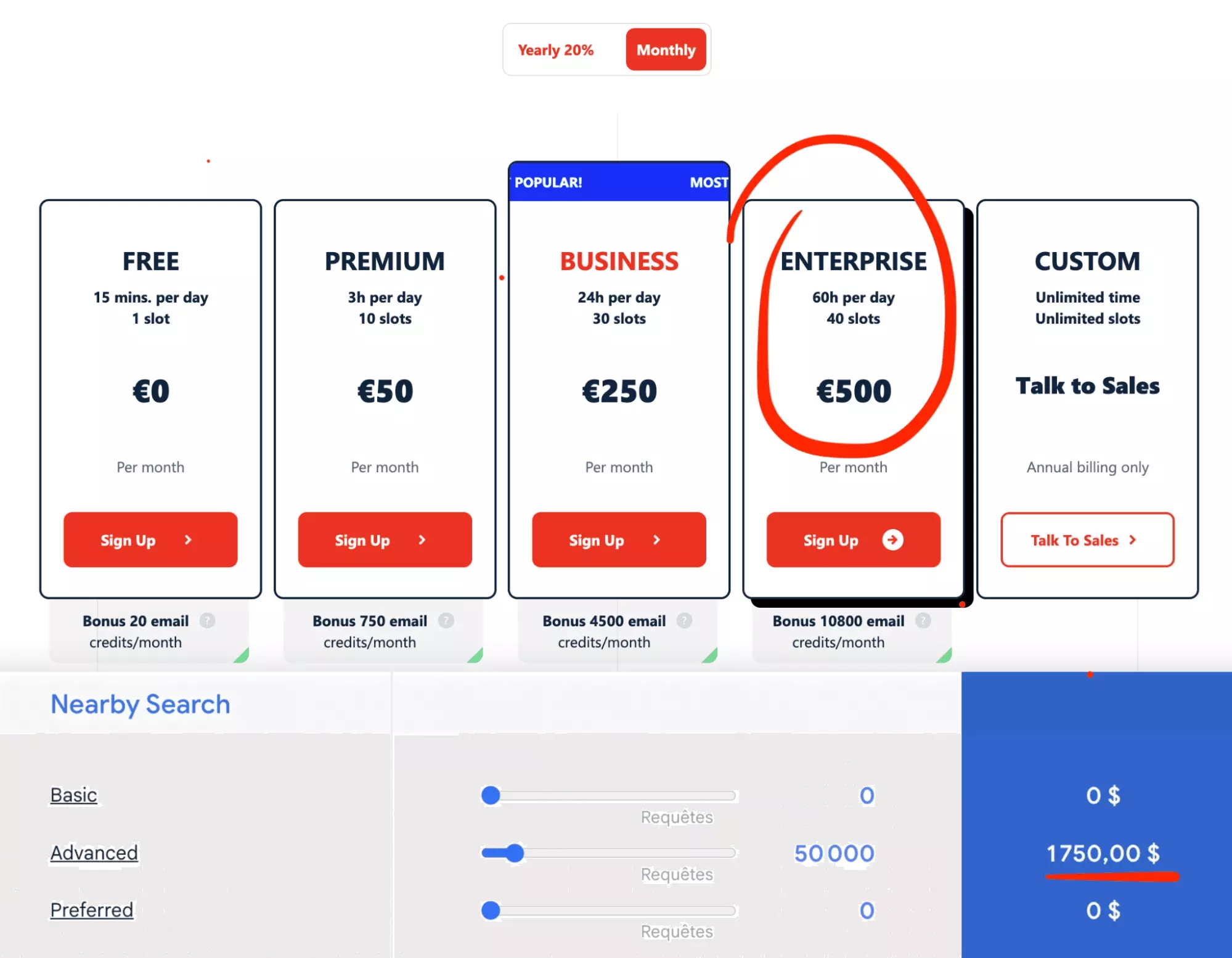
It is more than 3 times more expensive.
Why not use a homemade requests data scraper?
Only problem, you will have to go find these requests.
Let me explain: when you browse the Internet, your browser “exchanges” with the target site, and requests are made without you being aware of it.
If you build a scraper, you will have to find the query that allows you to access the data.
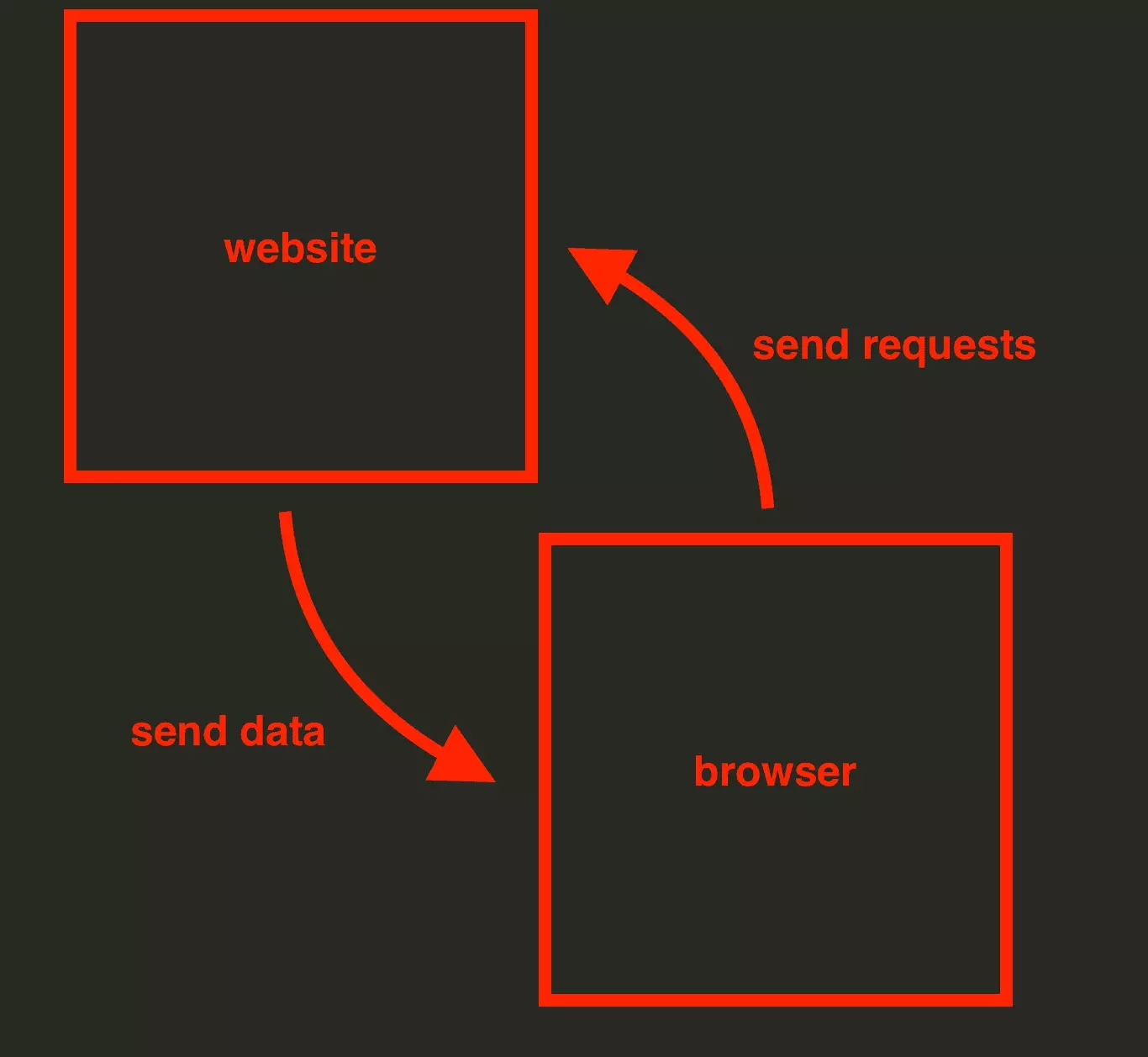
And in the case of Google Maps, the structure of this query is horribly complicated.
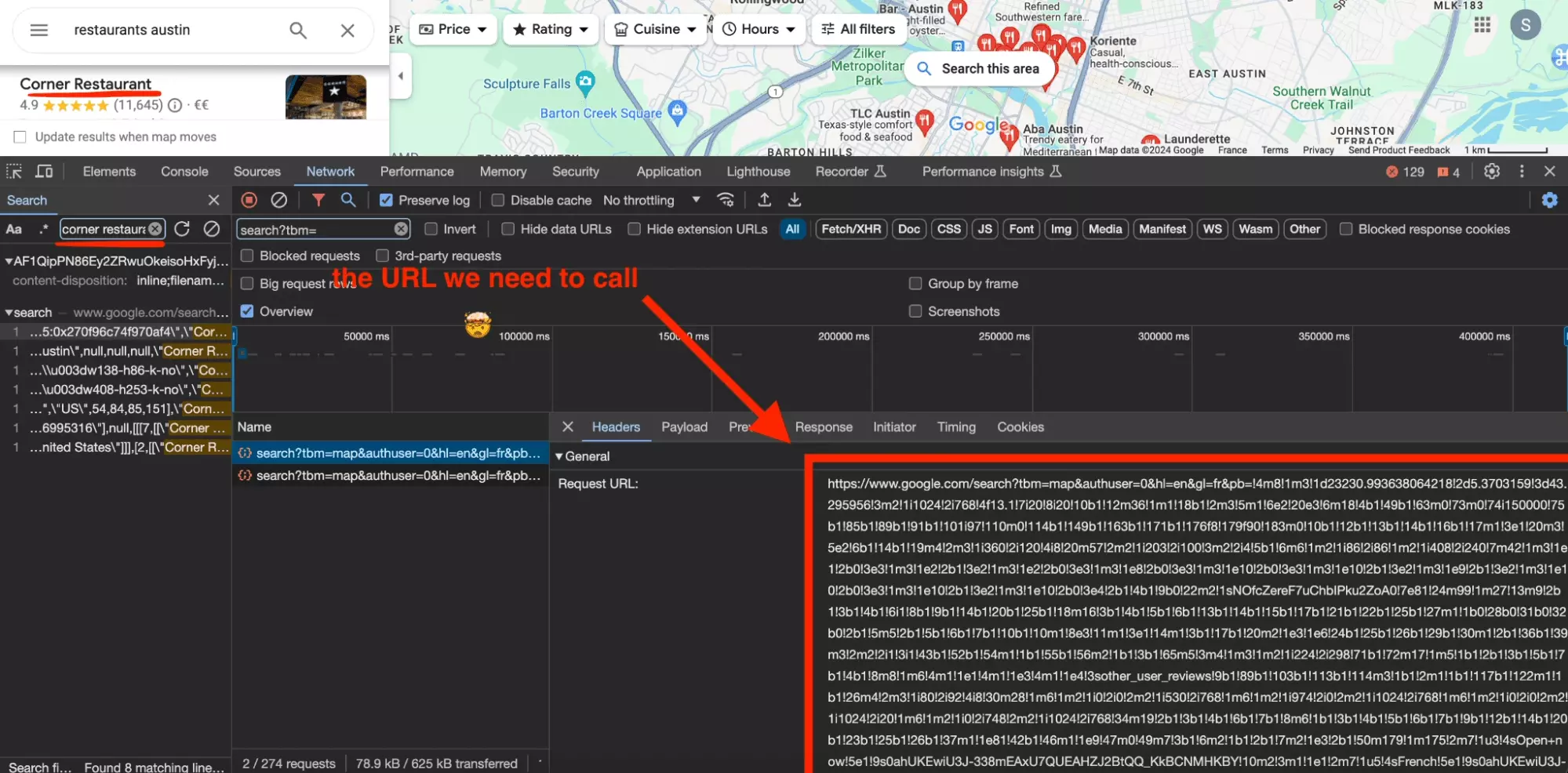
First, we will open our inspection tool, and go to the tabulation Network. This will allow us to observe the requests exchanged between the site and the browser.
We then use the search tool, and we look for the origin of the data Corner Restaurant.
We can find the URL. But it's incomprehensible.
And on the response side, it’s the same, the data structure is unreadable.
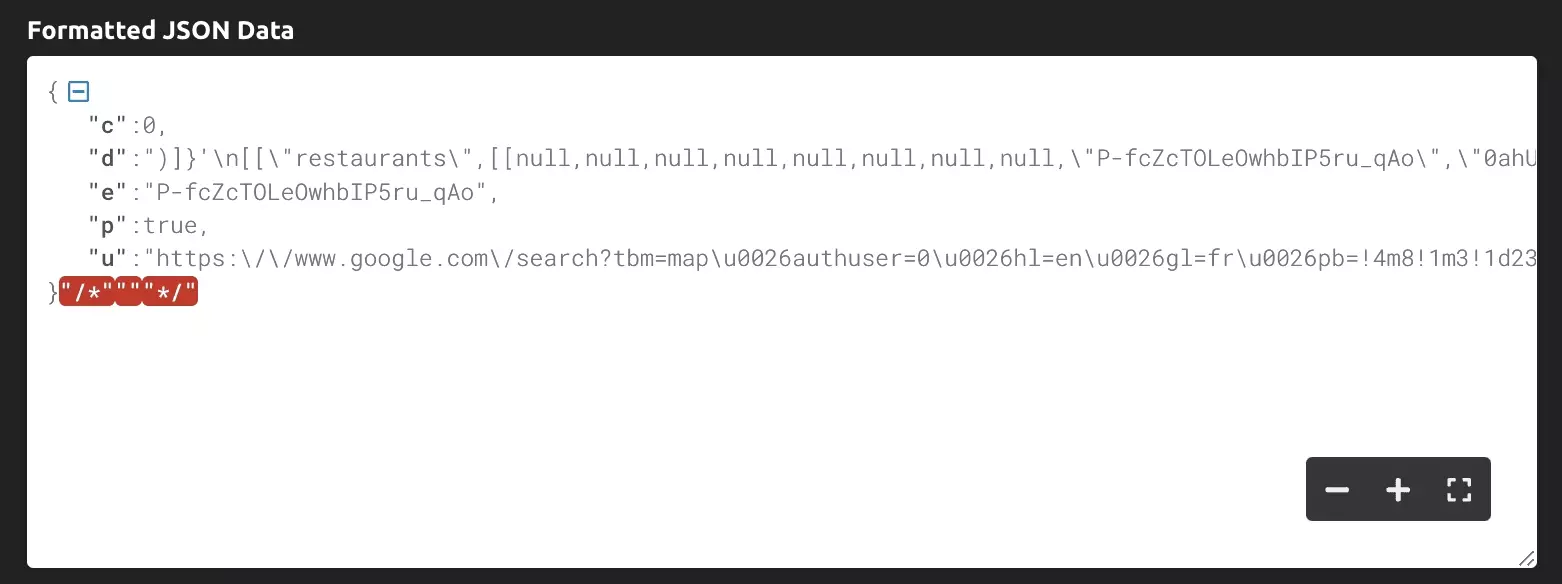
For a quick scraper, maybe we'll pass.
Why not use a homemade selenium scraper?
OK, fetching the original requests with requests is work beyond the scope of this quick tutorial.
But why not use selenium?
Indeed, selenium allows you to control a Chrome browser remotely.
No more searching for silent requests exchanged between the browser and the target site. Just let the browser do the work, and then parse the data.
But if everyone uses this tool, what's the problem?
Selenium is slow, that’s a fact. But above all, selenium is incredibly unstable.
OK it's very visual, and therefore still useful for a quick tutorial, where volume and speed requirements are limited.
But if you have to look for more than a dozen establishments it becomes hell.
How do I scrape Google Maps at scale with the Lobstr Google Maps Search Export API?
Step-by-step Tutorial
We will therefore use the Lobstr Google Maps Search Export API, which has all the following advantages:
- Simple to use
- Very competitive price
- Easy-to-read documentation
- Comprehensive data
And we're going to do this in 5 steps:
- Retrieve the API key
- Create a Cluster
- Add tasks
- Start the run
- Retrieve results
Let's go.
Prerequisites
$ pip3 install requestsf
It is quite simply the most used library on Python, with 51K+ stars on Github. It allows to browse the Internet quietly with Python.
Retrieve the API key
To use a third-party API, you must always use an API key. We're going to go get it!
First of all, create an account on lobstr.io:
Once on the Dashboard, click on the 3 points at the top right, then on the part Profile. Finally, in the part API key details, click on the icon Copier.
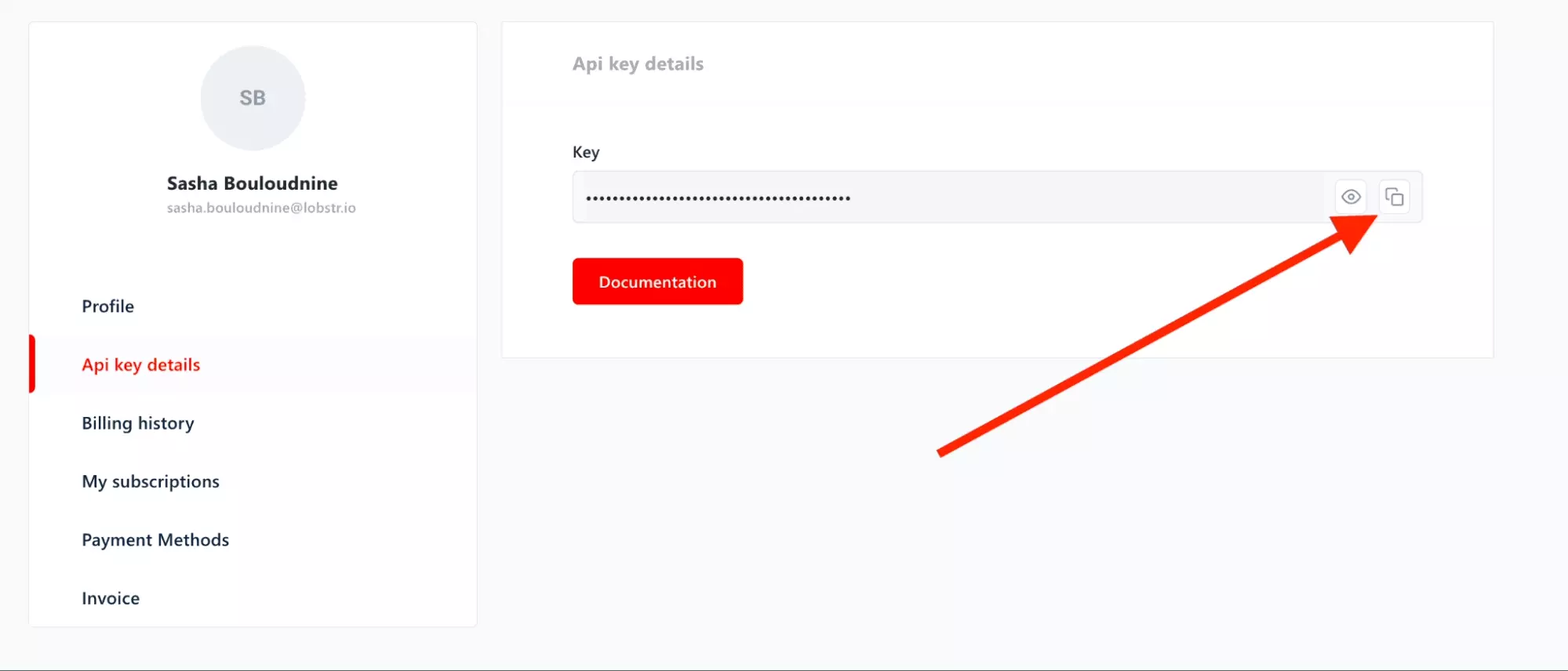
And there you go! Keep this value carefully, we will need it for the future.
In the rest of this tutorial, it will be marked as $TOKEN.
Create a Cluster
First, we will create a Cluster.
But what is a Cluster?
It’s a place where we are going to:
- Add all URLs or Tasks that we want to scrape
- Specify the settings of our scraper e.g. the language
- Specify launch frequency
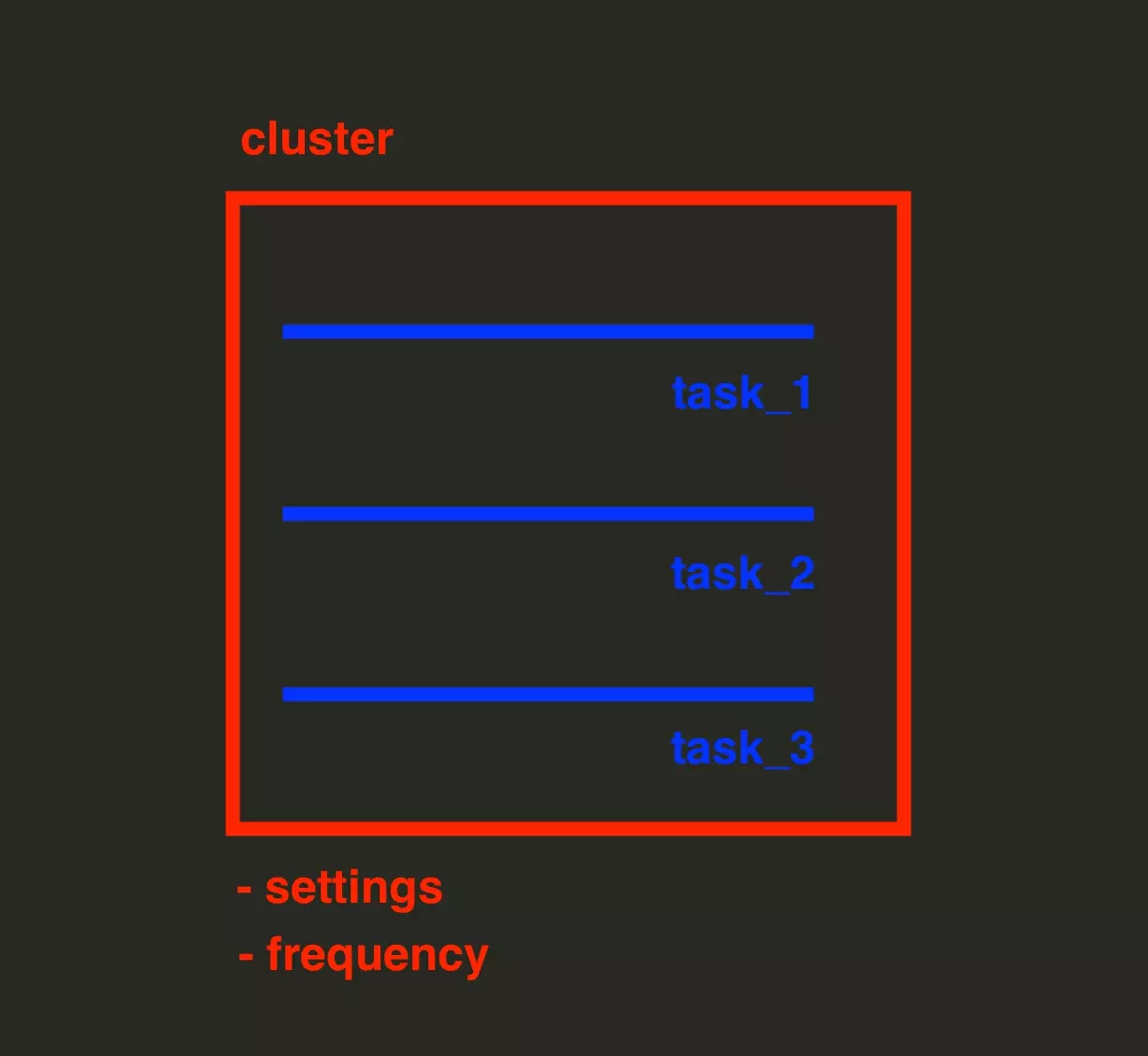
In other words, the Cluster is the bag that contains what we’re going to get.
Code
import requests headers = { 'Accept': 'application/json', 'Authorization': 'Token $TOKEN' } json_data = { 'crawler': '4734d096159ef05210e0e1677e8be823', } response = requests.post('https://api.lobstr.io/v1/clusters/save', headers=headers, json=json_data) print(response.json())f
Output
{ "id":"0b8e606cda1442789d84e3e7f4809506", "account":[ ], "concurrency":1, "crawler":"4734d096159ef05210e0e1677e8be823", "created_at":"2024-02-28T16:48:12Z", "is_active":true, "name":"Google Maps Search Export (1)", "params":{ }, "schedule":"None", "to_complete":false }f
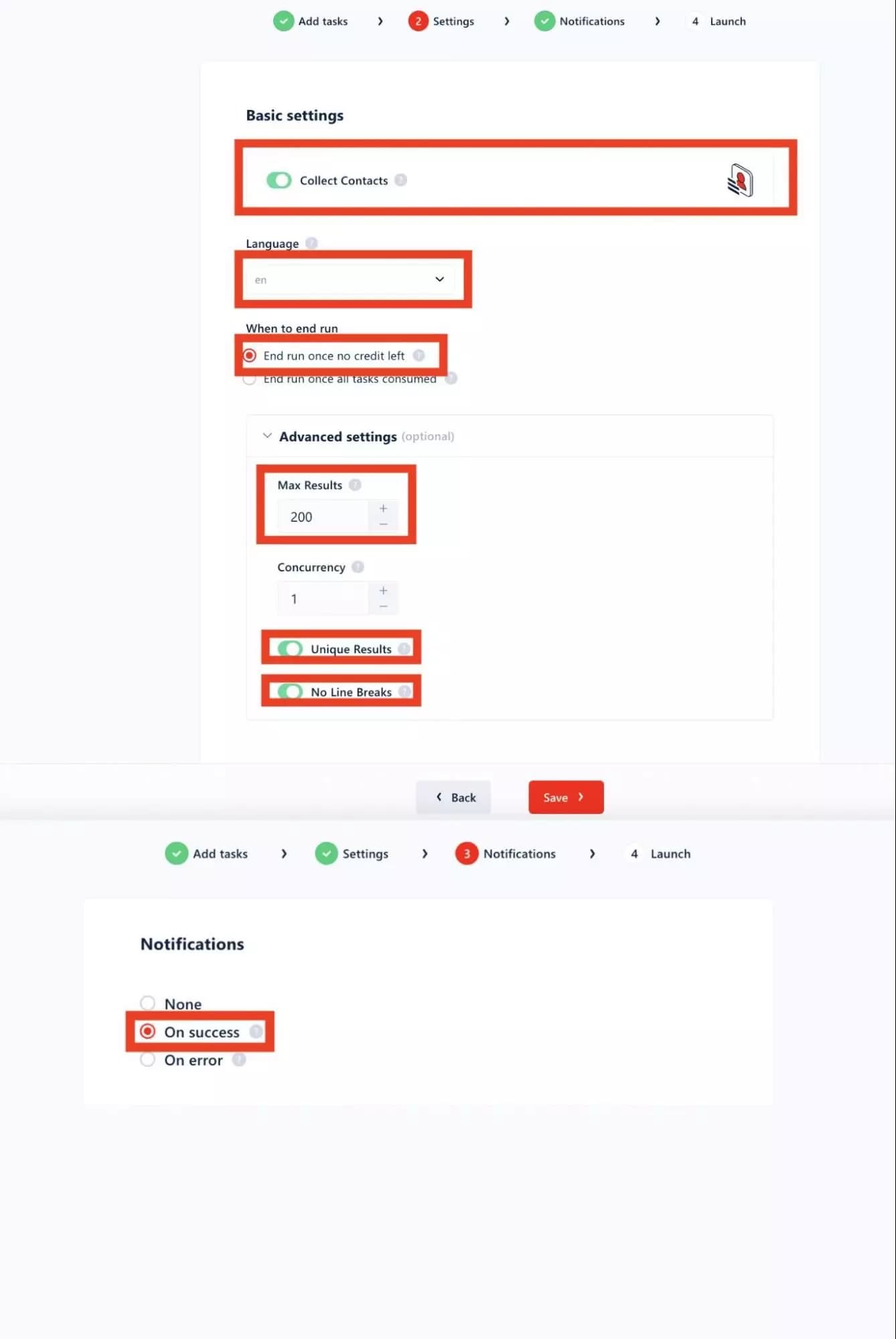
Specify Cluster Settings
In this second part, we will specify the Cluster parameters:
- Export of unique results
- Line break
- Collection of contacts on websites
- Language
- Maximum results to retrieve by URL
- Notifications
Visually this is what we find here and there:
Code
import requests headers = { 'Accept': 'application/json', 'Authorization': 'Token $TOKEN', } json_data = { 'name': 'Google Maps Search Export (1)', 'concurrency': 1, 'export_unique_results': True, 'no_line_breaks': True, 'to_complete': False, 'params': { 'language': 'in', 'max_results': 200, 'collect_contacts': True, }, 'accounts': None, 'run_notify': 'on_success', } response = requests.post('https://api.lobstr.io/v1/clusters/0b8e606cda1442789d84e3e7f4809506', headers=headers, json=json_data) print(response.json())f
Output
{ "name":"Google Maps Search Export (8)", "no_line_breaks":true, "params":{ "language":"in", "max_results":200, "collect_contacts":true }, "to_complete":false, "accounts":"None", "run_notify":"on_success", "export_unique_results":true, "id":"0b8e606cda1442789d84e3e7f4809506" }f
Add Tasks
Now it's time to go add tasks! The Task is the target from which the scraper will scrape the data.
Each task is a Google Maps search URL.
To fetch a task:
- Go on Google Maps
- Do a search
- Get URL from browser
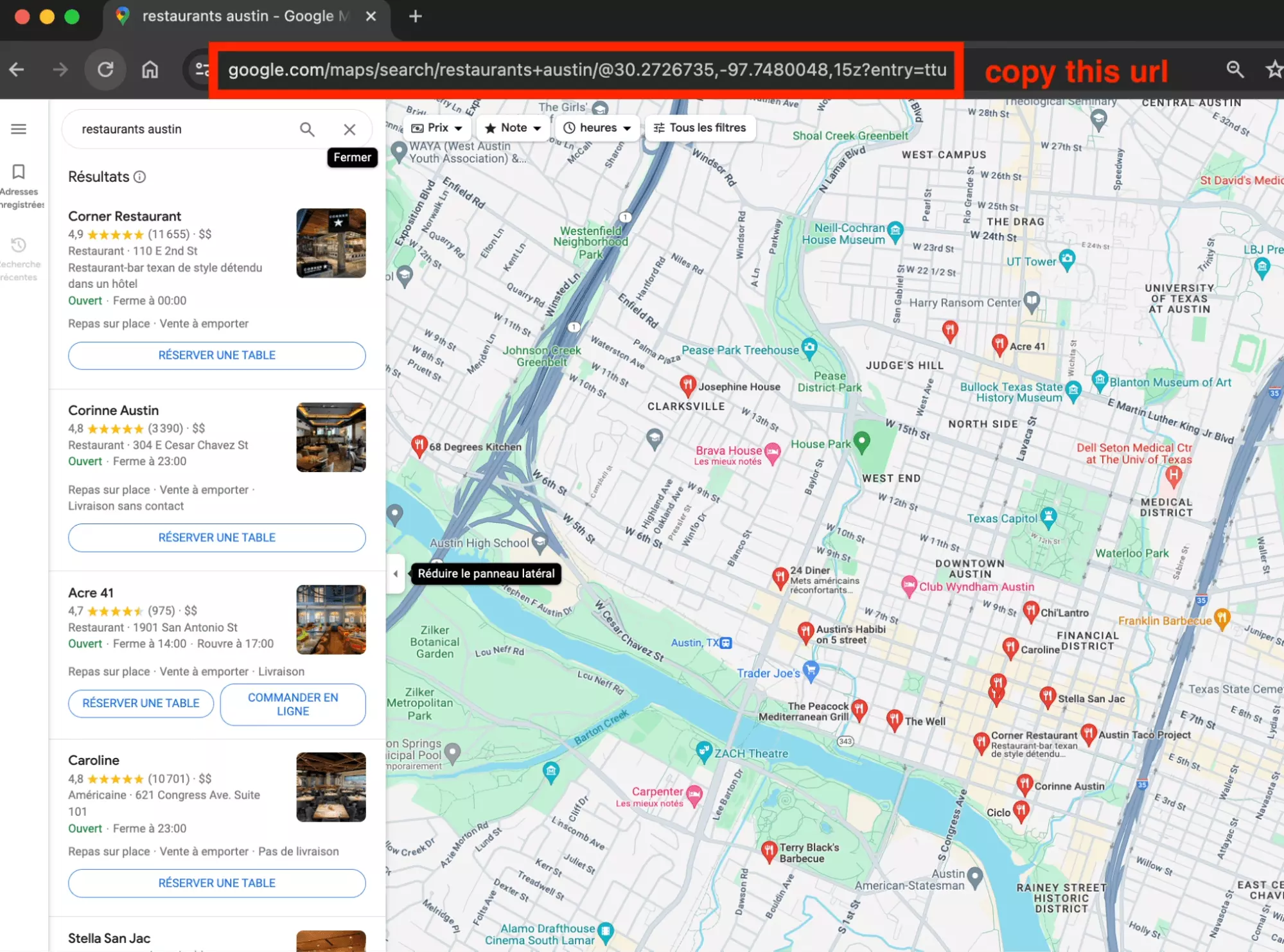
As part of this example, we will retrieve restaurants from Austin, and from New York.
Here are our two search URLs, or Tasks:
https://www.google.com/maps/search/restaurants+austin/@30.2685323,-97.7377576,15z https://www.google.com/maps/search/restaurants+new+york/@40.7345699,-74.0168744,14zf
We will now add Tasks to our Cluster.
Code
import requests headers = { 'Accept': 'application/json', 'Authorization': 'Token $TOKEN' } json_data = { 'tasks': [ { 'url': 'https://www.google.com/maps/search/restaurants+austin/@30.2685323,-97.7377576,15z?entry=ttu', }, { 'url': 'https://www.google.com/maps/search/restaurants+new+york/@40.7345699,-74.0168744,14z/data=!3m1!4b1?entry=ttu' } ], 'cluster': '0b8e606cda1442789d84e3e7f4809506', } response = requests.post('https://api.lobstr.io/v1/tasks', headers=headers, json=json_data) print(response.json())f
Output
{ "duplicated_count":0, "tasks":[ { "id":"51d62eee574a4c0f8f4d57a8733903da", "created_at":"2024-02-28T17:01:59.419166", "is_active":true, "params":{ "url":"https://www.google.com/maps/search/restaurants+austin/@30.2685323,-97.7377576,15z?entry=ttu" }, "object":"task" }, { "id":"b9f90d14135fa3d9b27595dfdb4969e3", "created_at":"2024-02-28T17:01:59.419281", "is_active":true, "params":{ "url":"https://www.google.com/maps/search/restaurants+new+york/@40.7345699,-74.0168744,14z/data=!3m1!4b1?entry=ttu" }, "object":"task" } ] }f
And there you have it, our tasks are added! Let's move on to the collection phase.
Start the run
Code
import requests headers = { 'Accept': 'application/json', 'Authorization': 'Token $TOKEN', } json_data = { 'cluster': '0b8e606cda1442789d84e3e7f4809506', } response = requests.post('https://api.lobstr.io/v1/runs', headers=headers, json=json_data) print(response.json())f
Output
{ "id":"d0c0d2548b8c4ad6ae0201b69ef0f787", "object":"run", "cluster":"0b8e606cda1442789d84e3e7f4809506", "is_done":false, "started_at":"2024-02-28T17:19:46Z", "total_results":0, "total_unique_results":0, "next_launch_at":"None", "ended_at":"None", "duration":0.0, "credit_used":0.0, "origin":"user", "status":"pending", "export_done":"None", "export_count":0, "export_time":"None", "email_done":"None", "email_time":"None", "created_at":"2024-02-28T17:19:46Z", "done_reason":"None", "done_reason_desc":"None" }f
Great, the run is on!
We will keep it carefully, we will need it for the future.
Retrieve results
And this is the last step, it’s time to collect our precious results!
Please note, by calling this route, we will display the last 100 results in JSON format. Now with 2 tasks, we can hope for approx. 400 results.
We will therefore set up a fast paging system with a for loop.
Finally, to easily visualize these results, we will insert the results into a CSV file.
Code
import requests import csv import time headers = { 'Accept': 'application/json', 'Authorization': 'Token $TOKEN' } fieldnames = None data = [] csv_file = "lobstr_google_maps_search_export_api.csv" for i in range(1, 5, 1): print('going page %s' % i) params = { 'run': 'd0c0d2548b8c4ad6ae0201b69ef0f787', 'page': '%i'%i, 'page_size': '100', } response = requests.get('https://api.lobstr.io/v1/results', params=params, headers=headers) assert response.ok time.sleep(1) items = response.json()["data"] for item in items: if not fieldnames: fieldnames = list(item.keys()) data.append(item) with open(csv_file, 'In') as f: writer = csv.DictWriter(f, fieldnames=fieldnames, delimiter='\t') writer.writeheader() for row in data: writer.writerow(row) print('success :°')f
Output
going page 1 going page 2 going page 3 going page 4 success :°f
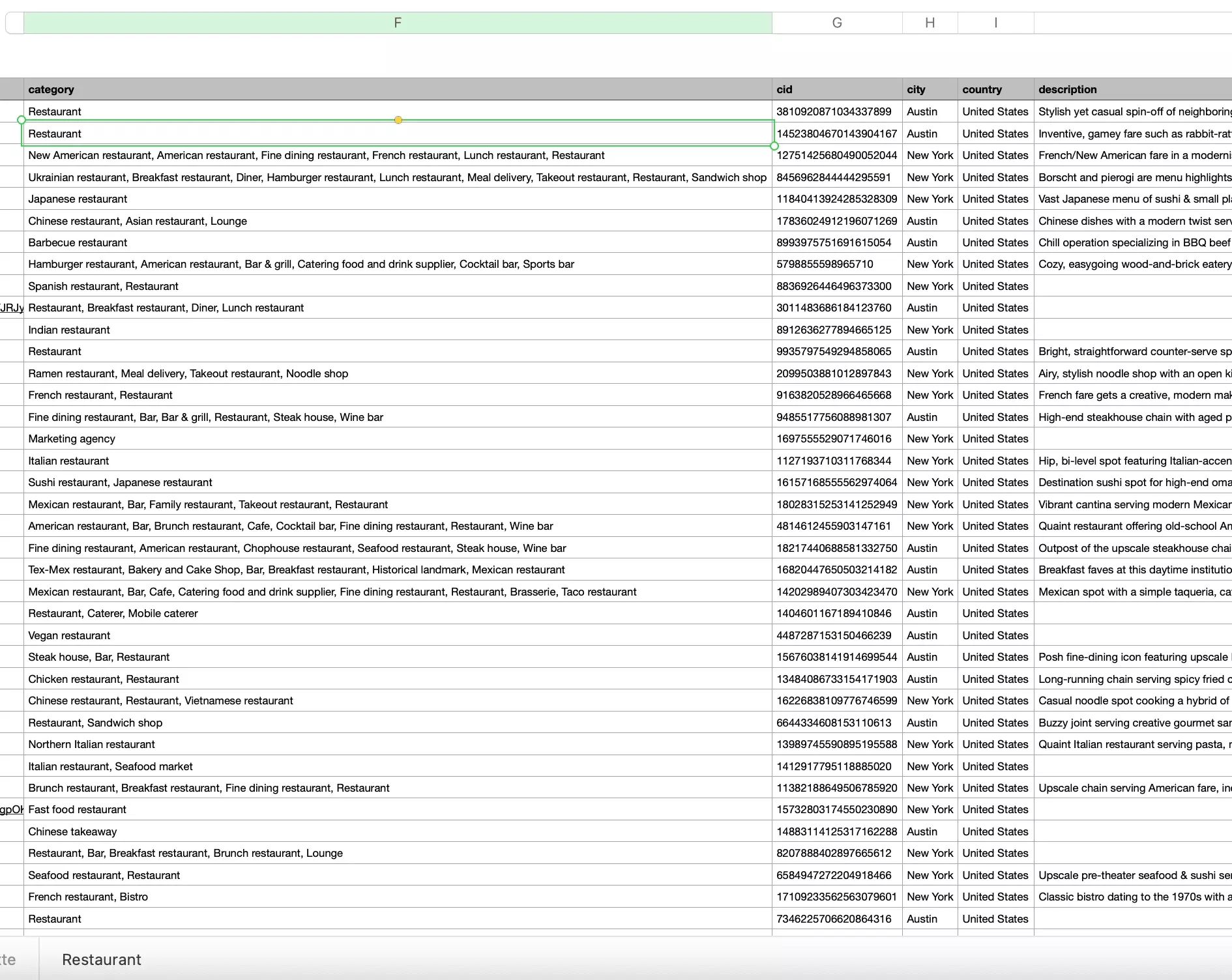
Include name, address, country and zip code, website, phone number, email…
Complete Code
And here is the complete code snippet, to directly extract local businesses from Google Maps, using the lobstr.io Google Maps Search Export API.
Google Maps data scraping with one straightforward Python script.
import requests import time import csv token = '$TOKEN' # <-- pick your API key from lobstr.io! print('creating cluster') headers = { 'Accept': 'application/json', 'Authorization': 'Token %s' % token } json_data = { 'crawler': '4734d096159ef05210e0e1677e8be823', } response = requests.post('https://api.lobstr.io/v1/clusters/save', headers=headers, json=json_data) time.sleep(1) assert response.ok cluster_id = response.json()["id"] assert cluster_id print('cluster_id: %s' % cluster_id) print('setting cluster up') json_data = { 'concurrency': 1, 'export_unique_results': True, 'no_line_breaks': True, 'to_complete': False, 'params': { 'language': 'in', 'max_results': 200, 'collect_contacts': True, }, 'accounts': None, 'run_notify': 'on_success', } response = requests.post('https://api.lobstr.io/v1/clusters/%s' % cluster_id, headers=headers, json=json_data) time.sleep(1) assert response.ok print('add tasks') json_data = { 'tasks': [ { 'url': 'https://www.google.com/maps/search/restaurants+austin/@30.2685323,-97.7377576,15z?entry=ttu', }, { 'url': 'https://www.google.com/maps/search/restaurants+new+york/@40.7345699,-74.0168744,14z/data=!3m1!4b1?entry=ttu' } ], 'cluster': '%s' % cluster_id, } response = requests.post('https://api.lobstr.io/v1/tasks', headers=headers, json=json_data) time.sleep(1) assert response.ok print('launch run') json_data = { 'cluster': '%s' % cluster_id, } response = requests.post('https://api.lobstr.io/v1/runs', headers=headers, json=json_data) time.sleep(1) assert response.ok run_id = response.json()["id"] assert run_id print('run_id: %s' % run_id) print('waiting for the run to complete') for _ in range(10): print('waiting for the run 10s') time.sleep(10) print('collecting results') fieldnames = None data = [] csv_file = "lobstr_google_maps_search_export_api.csv" for i in range(1, 5, 1): print('going page %s' % i) params = { 'run': '%s' % run_id, 'page': '%i'%i, 'page_size': '100', } response = requests.get('https://api.lobstr.io/v1/results', params=params, headers=headers) assert response.ok time.sleep(1) items = response.json()["data"] for item in items: if not fieldnames: fieldnames = list(item.keys()) data.append(item) with open(csv_file, 'In') as f: writer = csv.DictWriter(f, fieldnames=fieldnames, delimiter='\t') writer.writeheader() for row in data: writer.writerow(row) print('success :°')f
FAQ
Is it legal to scrape data from Google Maps?
Yes, absolutely!
Google Maps data is public data, so it is completely legal to scrape it. This is not a violation of the Computer Fraud and Abuse Act, or CFAA.
Can I be banned while scraping Google Maps with Python?
Yes, completely. Google Maps also specifies this in its terms of use. To avoid an IP ban or account deletion, use our API. We take care of everything.
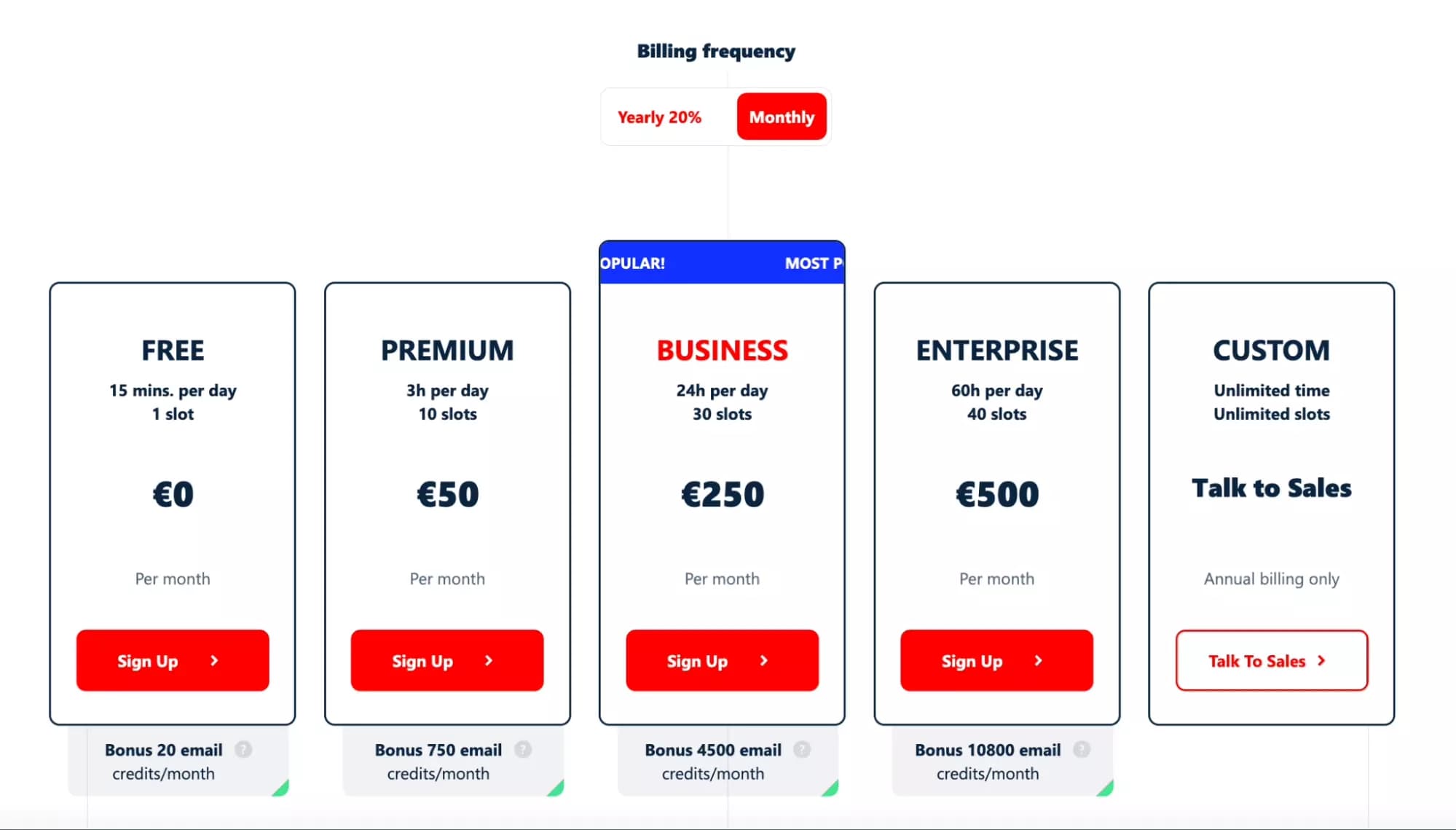
How much does the Google Maps Search Export API from lobstr.io cost?
There is a free plan, with up to 150 local businesses per day, or 4,500 establishments per month.
Beyond that, it goes like this:
- 50 EUR / month with 50K establishments
- 250 EUR / month with 400K establishments
- 500 EUR / month with 1M establishments (!!)
Is there a no-code Google Maps scraper?
Yes, and ours is the best!
And if you search for the best no-code scraper? Well it’s still ours.
Is it possible to scrape reviews from Google Maps?
Yes, it’s absolutely possible!

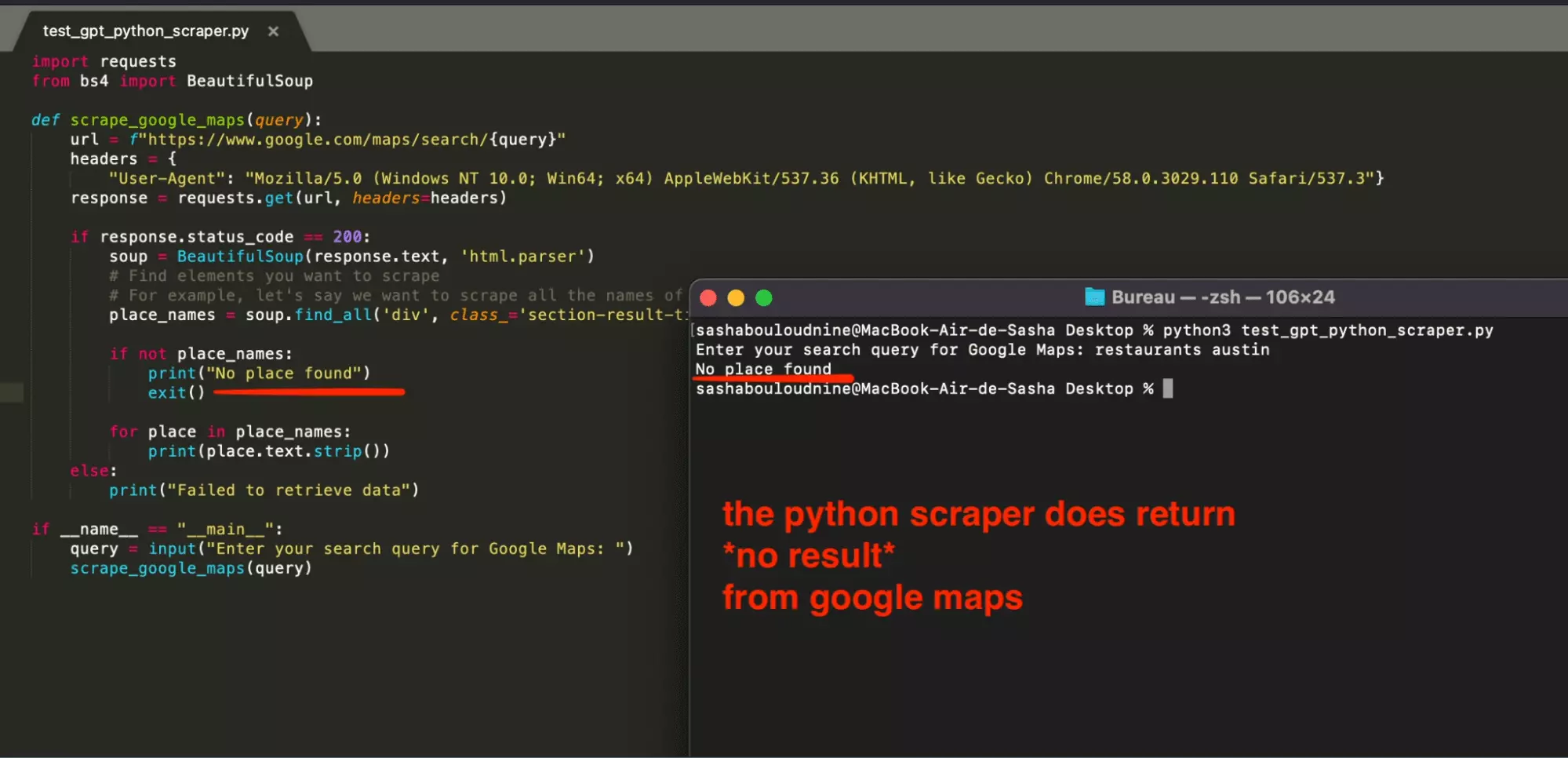
Can I use ChatGPT to build my Google Maps Python scraper?
Yes, you can ask ChatGPT to provide support with a Python scraper. But it will not work.
But endly, the piece of code does not return anything.