
How to download ebooks from .onion with Python3 and requests?
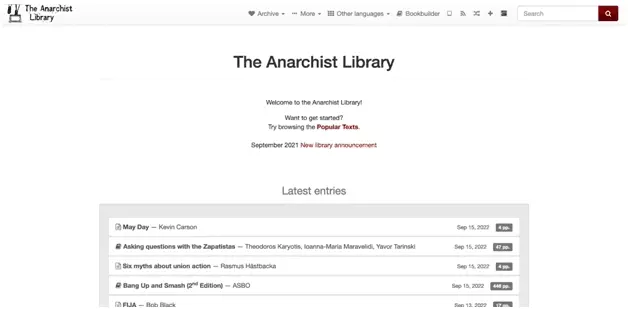
import requests r = requests.get('http://libraryqxxiqakubqv3dc2bend2koqsndbwox2johfywcatxie26bsad.onion/special/index') print(r.text)f
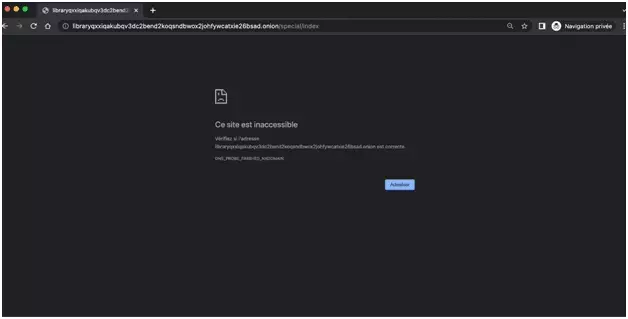
What to do?
Off to the dark places of the darknet!
🥷
Prerequisites
In order to complete this tutorial from start to finish, be sure to have the following installed on your computer.
You can click on the links below, which will take you either to an installation tutorial or to the site in question.
To clarify the purpose of each of the above: python3 is the computer language with which we will be scraping sites and downloading pdf's, and SublimeText is a text editor. Sublime.
Let's get to work.
Installation
We will proceed as follows:
- Install TorBrowser
- Install the tor package
Then download the browser that corresponds to your operating system. Here for me, Mac OS:
And then simply follow the installation instructions:

$ pip3 install requests $ pip3 install pysocks $ pip3 install lxmlf
Finally, we'll install Tor from the command line:
Mac OS
$ /usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"f
$ brew install torf
We check that tor is well installed:
$ brew info tor ==> tor: stable 0.4.7.10 (bottled)f
Finally, the service is launched:
$ brew services start torf
Linux
The package is installed:
$ sudo apt install torf
And we start the machine:
$ sudo /etc/init.d/tor startf
And now we're ready to scrape, with our requests browser directly connected to the Tor proxies.
🔥
Code
Here is the code in full:
import requests from lxml import html import time print('~~ start') anarchist_library_onion_link = "http://libraryqxxiqakubqv3dc2bend2koqsndbwox2johfywcatxie26bsad.onion/special/index" latest_books_library_onion_link = "http://libraryqxxiqakubqv3dc2bend2koqsndbwox2johfywcatxie26bsad.onion/latest?bare=1" session = requests.session() session.proxies = {'http': 'socks5h://localhost:9050', 'https': 'socks5h://localhost:9050'} tor_ip = session.get("https://api.ipify.org/").text local_ip = requests.get("https://api.ipify.org/").text assert all([tor_ip, local_ip]) assert tor_ip != local_ip response = session.get("http://libraryqxxiqakubqv3dc2bend2koqsndbwox2johfywcatxie26bsad.onion/latest?bare=1", timeout=100) doc = html.fromstring(response.text) items = doc.xpath('//div[@class="list-group"]//div[@class="amw-listing-item"]') for i, item in enumerate(items[:10]): link = "".join(item.xpath('./a/@href')) print(link) response = session.get(link, timeout=100) assert response.ok item_page_doc = html.fromstring(response.text) pdf_link = "".join(item_page_doc.xpath('//span[@id="download-format-pdf"]/a/@href')) assert pdf_link pdf_name = pdf_link.split('/')[-1] pdf_response = session.get(pdf_link, stream=True) with open(pdf_name, 'wb') as fd: for chunk in pdf_response.iter_content(2000): fd.write(chunk) print('✅ %s (%s)' % (pdf_name, i+1)) time.sleep(1) print('~~ success') print(""" _ _ _ | | | | | | | | ___ | |__ ___| |_ __ __ | |/ _ \| '_ \/ __| __/| '__| | | (_) | |_) \__ \ |_ | | |_|\___/|_.__/|___/\__||_| """)f
To execute the code:
- Download the .py code
- Run the script via the command line
And this is what will appear directly on your terminal:
$ python3 scraping-anarchists-library-darknet-requests-tor-tutorial.py ~~ start ✅ kevin-carson-may-day.pdf (1) ✅ theodoros-karyotis-ioanna-maria-maravelidi-yavor-tarinski-asking-questions-with-the-zapatistas.pdf (2) ✅ rasmus-hastbacka-six-myths-about-union-action.pdf (3) ✅ asbo-bang-up-and-smash-2nd-edition.pdf (4) ✅ bob-black-fija.pdf (5) ~~ success _ _ _ | | | | | | | | ___ | |__ ___| |_ __ __ | |/ _ \| '_ \/ __| __/| '__| | | (_) | |_) \__ \ |_ | | |_|\___/|_.__/|___/\__||_|f
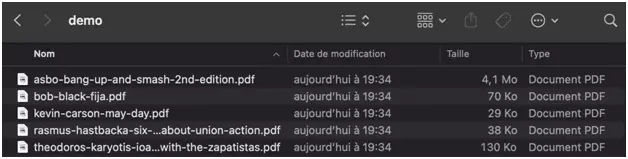
And the precious anarchist ebooks, downloaded for free from the darknet, directly saved on your computer:
🤓
Step-by-Step Guide
The guide will be broken down into 3 parts.
- Connecting to Tor proxies with requests and Python
- Browsing the site
- Downloading pdfs
Tor Proxies
First, let's connect to the Tor proxies with Python3 and requests, as follows:
session = requests.session() session.proxies = {'http': 'socks5h://localhost:9050', 'https': 'socks5h://localhost:9050'}f
tor_ip = session.get("https://api.ipify.org/").text local_ip = requests.get("https://api.ipify.org/").text print(tor_ip) print(local_ip)f
And the result is clear:
$ python3 scraping-anarchists-library-darknet-requests-tor-tutorial.py 5.45.106.207 80.125.29.188f
2 different IPs - we are well connected to the Tor proxies!
Now let's try to connect to the site:
response = session.get(latest_books_library_onion_link, timeout=100) print(response.status_code)f
And here again, when running the script, the message is clear:
$ python3 scraping-anarchists-library-darknet-requests-tor-tutorial.py 200f
No more inaccessible pages. We positively access this site present on the darknet programmatically, with requests and Python.
🐍
All Results Page
Now we will navigate the site.
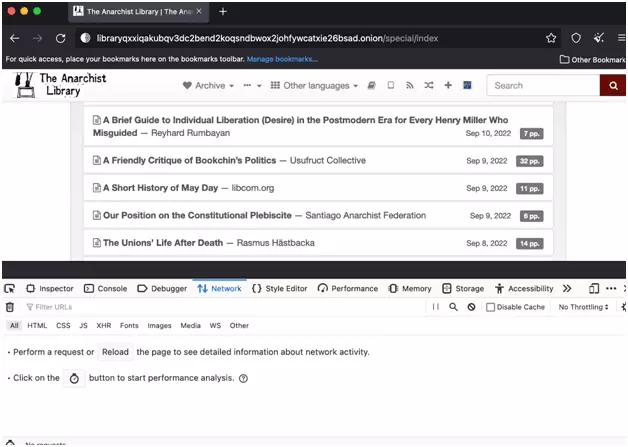
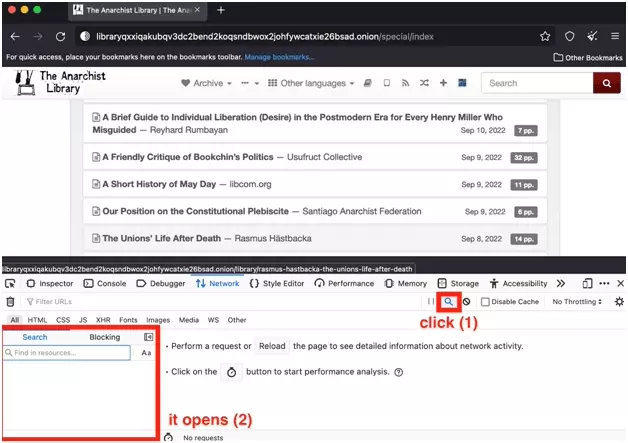
Reload the page, and in the search tool, select one of the words on the page, here "A short history of May Day":
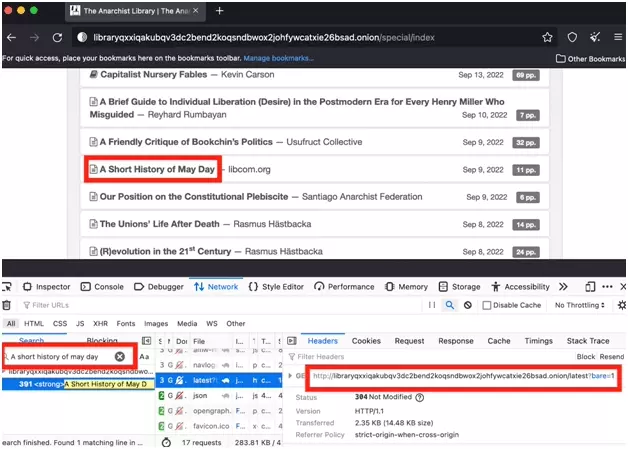
A query appears! It is the URL of this request that we will retrieve, and insert directly into our Python code:
response = session.get("http://libraryqxxiqakubqv3dc2bend2koqsndbwox2johfywcatxie26bsad.onion/latest?bare=1", timeout=100)f
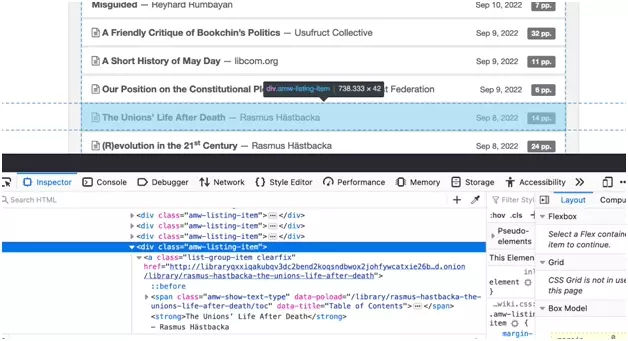
Now we will retrieve the URL of each of the pages of each book. When we open the 'Inspector' part of the inspection tool, we see that each book page is located in a div which has the class 'amw-listing-item':
Here is the code:
response = session.get("http://libraryqxxiqakubqv3dc2bend2koqsndbwox2johfywcatxie26bsad.onion/latest?bare=1", timeout=100) doc = html.fromstring(response.text) items = doc.xpath('//div[@class="list-group"]//div[@class="amw-listing-item"]') for i, item in enumerate(items[:10]): link = "".join(item.xpath('./a/@href')) print(link)f
And when you run it from the command line, the links appear clearly:
$ python3 scraping-anarchists-library-darknet-requests-tor-tutorial.py http://libraryqxxiqakubqv3dc2bend2koqsndbwox2johfywcatxie26bsad.onion/library/kevin-carson-may-day http://libraryqxxiqakubqv3dc2bend2koqsndbwox2johfywcatxie26bsad.onion/library/theodoros-karyotis-ioanna-maria-maravelidi-yavor-tarinski-asking-questions-with-the-zapatistas http://libraryqxxiqakubqv3dc2bend2koqsndbwox2johfywcatxie26bsad.onion/library/rasmus-hastbacka-six-myths-about-union-action http://libraryqxxiqakubqv3dc2bend2koqsndbwox2johfywcatxie26bsad.onion/library/asbo-bang-up-and-smash-2nd-edition http://libraryqxxiqakubqv3dc2bend2koqsndbwox2johfywcatxie26bsad.onion/library/bob-black-fijaf
Beautiful!
All we have to do now is:
- Go to the page of each book
- Download the book in .pdf format
One Result Page
First, we go to the book page with requests:
response = session.get(link)f
Then from the TorBrowser, once on the book page, inspect the area with the link to the pdf:
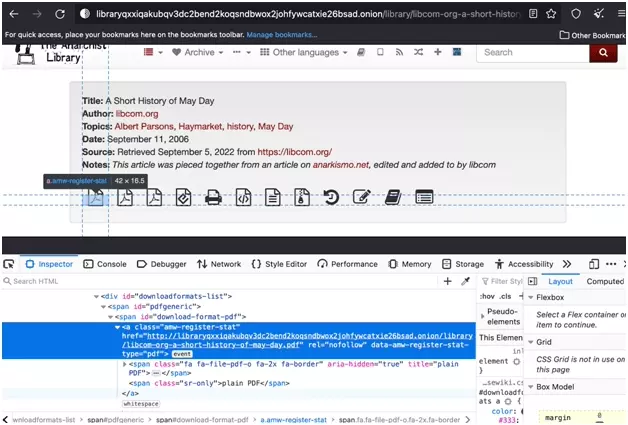
'//span[@id="download-format-pdf"]/a/@href'f
pdf_link = "".join(item_page_doc.xpath('//span[@id="download-format-pdf"]/a/@href')) assert pdf_link pdf_name = pdf_link.split('/')[-1] pdf_response = session.get(pdf_link, stream=True) with open(pdf_name, 'wb') as fd: for chunk in pdf_response.iter_content(2000): fd.write(chunk)f
And there you have it!
Benefits
Limitations
To access other data sources, you will have to modify the script together.
Beware, please note that this tutorial is for educational purposes only.
We therefore disclaim any responsibility for any immoderate use that may be made of it, particularly on sites linked to other types of services or other types of data. Furthermore, we would like to remind you that, according to the legislation of the country in which you operate, it is strictly forbidden to possess texts protected by copyright without offering the fair remuneration due to the author. We therefore strongly recommend that you consult the legislation in force in your country of practice before embarking on any IT development project as illustrated above.
Conclusion
And that's the end of the tutorial!
Happy scraping!
🦀